1. Course content
Today's main contents include:
1,ZooKeeper Core functions of-ZNode data model
2,ZooKeeper Core functions of-Watcher
3,Zookeeper actual combat
Application scenario
Implementation of actual enterprise case
Purpose of enterprise application case:
1,I will realize these needs 2,You should know that some commonly used popular distributed technologies are used at the bottom zk What the hell did you do
HBase and Spark implement HA based on ZK. When you look at the source code, a relatively simple introduction is OK.!
2. ZooKeeper core functions
ZK is a distributed coordination service, persuader and arbitration institution. If there is disagreement among multiple nodes, an intermediate mechanism is needed to mediate!
zk is a small parliament! When multiple nodes in a distributed system are inconsistent, write the inconsistency to zk. zk will give you a successful response. Whenever you receive a successful response, it means zk helps you reach an agreement!
But in fact, if you need to synchronize data in multiple nodes, you can write the data to zk. Writing successfully means reaching an agreement!
ZK has a data system inside! It's a tree. The node in the tree is the result of a transaction!
2.1. ZNode data model
File system class file system (each node is either directory or file)
znode system / ZooKeeper data model (the node only has the name znode (implementation class: DataNode), but it has the ability of both folders and files)
Two aspects:
1. Znode constraints (the maximum data stored in znode nodes is 1M, preferably not more than 1kb) why?
Each node has the same data view: each node stores this zk The data status of each node is the same as leader bring into correspondence with 1,Synchronous pressure 2,Stored pressure
2. Classification of znode
1,According to the life cycle Persistent type (display creation and display deletion. Only when the display command is used to delete a node, otherwise the node will always exist until it is successfully created) Temporary type/Transient type (bound to the session, the node created by the session. If the session is disconnected, all temporary nodes created by the session will be deleted by the system) 2,Each node maintains a sequence number according to whether it has a sequence number. The sequence number of the current node is maintained by its parent node, and the number is a self incrementing sequence number, and mysql The self increasing primary key is the same belt No
3. Little knowledge of znode
Child nodes cannot be mounted under temporary nodes
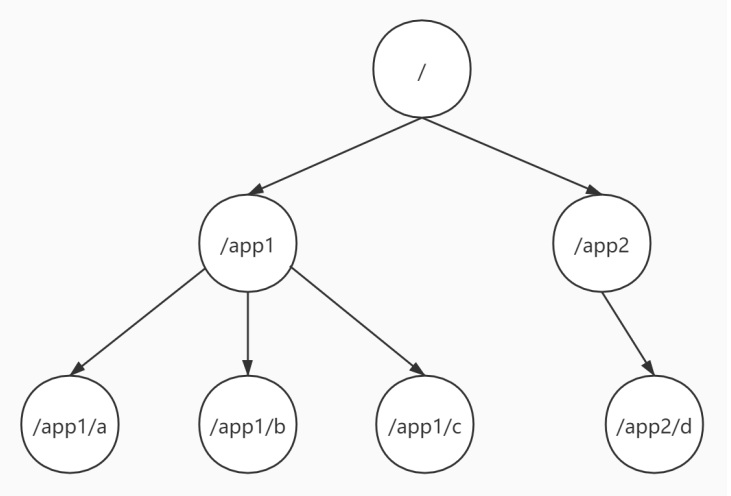
If you want to realize a tree
class DataNode{
// Storage node data
private Object data;
// You can mount a bunch of child nodes
private List<DataNode> children;
// The current node has a unique parent node, except the root node
private DataNode parent;
}
Several important API s for data model implementation in ZooKeeper
1,ZKDatabase Abstracted for management zk There are two important member variables in the whole data model system:
1,FileTxnSnapLog For operation log related
It also has two important member variables:
1,TxnLog
2,SnapShot
2,DataTree Data model for maintaining tree structure
2,DataTree The data model of tree structure is completely abstract and exists in memory
3,DataNode Nodes in the tree
Consider why the maximum storage capacity of each znode is 1M, and it is recommended not to exceed 1KB?
Since the data stored in each node is the same, all nodes need to be synchronized successfully when the write operation is successful 1,The data stored in each node is the same: If the size of all data exceeds the storage capacity of a single server 2,In the writing process, at least more than half of the nodes must write successfully before the data is considered to be written successfully
Classification:
Lifecycle: temporary nodes EPHEMERAL Permanent node PERSISTENT
A permanent node is created by default and exists until manually deleted
each znode Nodes must be composed of one session Created. If the current session Disconnect, then znode The node is automatically deleted
Does it have its own serialization SEQUENTIAL
With serial number
Without serial number
The above two classification methods are combined to produce four types:
1,CreateMode.PERSISTENT 2,CreateMode.PERSISTENT_SEQUENTIAL 3,CreateMode.EPHEMERAL 4,CreateMode.EPHEMERAL_SEQUENTIAL
2.2. Watcher monitoring mechanism
Working principle of ZooKeeper's monitoring mechanism:
1,ZooKeeper Linked object session object client
ZooKeeper zk = new ZooKeeper("bigdata02", 5000, null);
zk.create()
zk.delete()
zk.setData()
zk.getChildren() + zk.getData()
Register listening:
zk.getData(znodePath, watcher); Two things: get the data of the node + A listener is registered for the current node.
Common words: I execute this sentence code, which means that I am right zk In the system znodePath I was interested in the changes of node data, so I registered a listener (I told you) zk System, if this znode The node data has changed, I hope you can tell me).
If another client really changes this znode Node data, then zk The system will really notify me of an event: WatchedEvent
2,WatchedEvent Event notification object
KeeperState state zk Link status
String znodePath Of the event znode node
EventType type Type of event
3,When receiving this WatchedEvent When responding, you should do some logical processing for the response, and the code for this logical processing is written in the callback method
4,In the client, there is also one WatchManager Management service: at present, the monitoring of the nodes registered by the client are managed by categories. When this client receives zk System event notification: WatchedEvent, that WatchManager Will be based on the internal of the event object znodePath + type + state To determine what to do next
Listening object:
interface Watcher{
// Callback method
void process(WatchedEvent envet);
}
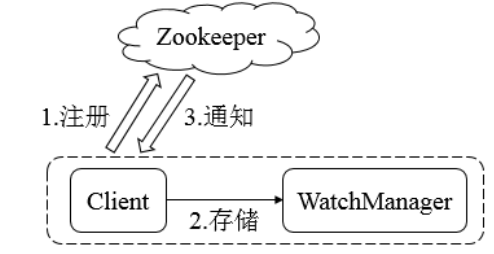
Several important knowledge in application:
1,How to register for listening 2,Trigger listening/How to trigger the event 3,Type of event
1. There are three ways to register for listening:
1,zk.getData() Pay attention to the data changes of nodes 2,zk.exists() Pay attention to the state change of whether the node exists or not 3,zk.getChildren() The number of child nodes of the concerned node changes
2. How to trigger listening:
1,zk.setData Change node data to trigger listening 2,zk.create() Create node 3,zk.delete() Delete node
3. There are four types of events to respond to:
1,NodeCreated The node is created 2,NodeDeleted Node deleted 3,NodeDataChanged Node data changes 4,NodeChildrenChanged The number of child nodes of a node changes
To sum up, this is the following figure:

Last little question: how to realize circular monitoring / continuous monitoring? Because ZooKeeper listens only once
2.3. Session mechanism
In ZK system, there is still the concept of session!
Every time a DataNode(ZNode) is created, there is a property in the znode object: State
There is also an attribute in the State: owner, who created the znode node, then the owner is who stored it!
Who: session (if the node is a temporary node or a persistent node, the owner attribute of the state attribute of this znode is: 0)
When the owner is stored as a sessionID, if the session is disconnected, all znode s corresponding to the sessionID will be deleted by zk system
When you create a temporary node, you will save the ID of the session that created the node in the owner in the state attribute of the znode object.
ZooKeeper instance: link, session, client (easy for everyone to understand)
zookeeper When instantiated, two objects will be created: 1,Client object for network communication (existing on client: ClientCnxn) 2,Session object (exists on the server)
ZK's network communication system:
1,Implementation of server communication components for network communication: ServerCnxn 2,Client communication component implementation of network communication: ClientCnxn
2.4. ZK programming model
Some details about zk programming:
1,Instantiate a client first
Zookeeper zk = new Zookeeper("bigdata02:2181,bigdata03:2181", 5000, null){
ClientCnxn client = new ClientCnxn()
client.send(ConnectRequest) // Send link request to zk system
}
2,adopt zk Instance to perform various operations
zk.create()
zk.delete()
zk.getData()
zk.exists()
zk.getChildren()
3,One server: QuorumPeer
During startup, a QuorumPeer An instance will be created inside this instance: ServerCnxn
ServerCnxn Received ConnectRequest ,The link processing is performed and then created Session
4,Implementation of communication components:
Server: ServerCnxn
client: ClientCnxn
5,About initialization Zookeeper Instance, which server is linked to?
1,The first parameter will be parsed inside this Code: bigdata02:2181,bigdata03:2181 Get a random list of multiple servers. The specific rules are as follows: Collectoins.shuffle(adresses)[0]
2,each Zookeeper The creation of this instance will only link one node. If this node cannot be linked, how can I try again?
When Zookeeper If you disconnect from the previous node, the client will try to establish a connection with another node
About the abstraction of API
1,HDFS
Configuratioin + FileSystem
2,MapReduce
InputFormat + RecordReader + Mapper + Partitioiner + Combiner + Reducer +
OutputFormat + RecoredWriter + Writable + Comparable + Comparator
3,ZooKeeper
ZooKeeper + Watcher
4,Spark Great(Programming entry, data abstraction, operator)
sparkContext sqlContext streamingContext
rdd, dataFrame, dataset
map, filter
5,HBase As a very complex data system, the abstraction of corresponding concepts is also done well
1,Configuration object: Coniguratioin
2,Linked objects: Connection
3,Management object: Admin(DDL) HTable(DML)
4,Operation object: Put Delete Get Scan
5,Result object: ResultSet Result KeyValue/Cell
...
3. ZooKeeper actual combat
3.1. Application scenario of zookeeper
zk: distributed coordination service, persuader and arbitration organization. Based on its two core functions: it can realize all kinds of difficult and miscellaneous problems in distributed scenarios! The most classic distributed lock problem. It is easy to implement as long as it is based on zk!
1,release/subscribe = Immediate perception 2,Naming service 3,configuration management 4,Cluster management 5,Distributed lock 6,queue management 7,load balancing
Don't come across some difficult problems, just ask zk! Don't do that!
Classic usage: write data to zk as little as possible, and the written data should not be too large! It is only suitable for storing a small amount of key data! Who is the real active leader in a cluster
1,Because each node will synchronize, when executing a write request, it is actually atomic broadcasting. 2,All requests are executed in strict sequence, this zk The cluster can only execute one transaction at a time 3,zk There is one inside leader,There are a few follower,There may be some observer, When observer and follower If a write request is received, it will be forwarded to leader To handle read requests, each node can handle them. So when there are a lot of read requests, just expand observer Just!
3.1.1. Publish and subscribe
For example:
1,System Tencent News App(Provide many news channels) 100 channel news categories 2,Publisher editor (producer) 3,Subscriber reader (consumer)
There may be two problems in the application server cluster: 1. Because there are many machines in the cluster, how can the configuration of all servers automatically take effect after a general configuration changes? 2. When a node in the cluster goes down, how can other nodes in the cluster know? In order to solve these two problems, zk introduces the watcher mechanism to implement the publish / subscribe function, which enables multiple subscribers to listen to a topic object at the same time. When the state of the topic object changes, it will notify all subscribers.
Data publish / subscribe is the so-called configuration center: the publisher publishes the data to one or some column nodes of zk. The subscriber subscribes to the data and can be notified of the change of the data immediately.
There are two design modes for publish / subscribe, push and Pull. In push mode, the server sends all data updates to the subscribed client, and Pull is initiated by the client to obtain the latest data. Round search is usually used.
zk adopts push-pull combination. The client registers the node that needs attention with the server. Once the data of the node changes, the server sends a Watcher event notification to the client and actively obtains the latest data from the server after receiving the message. This mode is mainly used for configuration information acquisition synchronization.
A has a message to let B know: a takes the initiative to tell B, and B keeps asking if there is any new news: if there is, a will tell him
Publisher.java
**
* Description: Publisher program
* Implementation idea: Publisher The program is only responsible for publishing messages
**/
public class Publisher {
// zookeeper server address
private static final String CONNECT_INFO = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
private static final int TIME_OUT = 4000;
// Alternate parent-child node
private static final String PARENT_NODE = "/publish_parent";
private static final String SUB_NODE = PARENT_NODE + "/publish_info14";
private static final String PUBLISH_INFO = "bigdata03,8457,com.mazh.nx.Service03,getName,xuzheng";
// Session object
private static ZooKeeper zookeeper = null;
// Latch is equivalent to an object lock. When the latch.await() method is executed, the thread where the method is located will wait
// When the count of latch is reduced to 0, the waiting thread will wake up
private static CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
// Please start your performance!!!
// Step 1: get session
zookeeper = new ZooKeeper(CONNECT_INFO, TIME_OUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
// Make sure the link is established
if (countDownLatch.getCount() > 0 && event.getState() == Event.KeeperState.SyncConnected) {
System.out.println("Session link created successfully");
countDownLatch.countDown();
}
// Publishers don't have to do anything
}
});
// Step 2: first ensure that the parent node exists
ArrayList<ACL> acls = ZooDefs.Ids.OPEN_ACL_UNSAFE;
CreateMode mode = CreateMode.PERSISTENT;
// Determine whether the parent node exists
Stat exists_parent = zookeeper.exists(PARENT_NODE, false);
if (exists_parent == null) {
zookeeper.create(PARENT_NODE, PARENT_NODE.getBytes(), acls, mode);
}
// Step 3: publish news
zookeeper.create(SUB_NODE, PUBLISH_INFO.getBytes(), acls, mode);
// Step 4: close the session link
zookeeper.close();
}
}
Subscriber.java
/**
* Description: subscriber
* Design idea: the Subscriber is scheduled for a certain channel, and if a publisher publishes a message under the channel, the Subscriber will receive it
**/
public class Subscriber {
// zookeeper server address
private static final String CONNECT_INFO = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
private static final int TIME_OUT = 4000;
// Alternate parent-child node
private static final String PARENT_NODE = "/publish_parent";
// Session object
private static ZooKeeper zookeeper = null;
// Latch is equivalent to an object lock. When the latch.await() method is executed, the thread where the method is located will wait
// When the count of latch is reduced to 0, the waiting thread will wake up
private static CountDownLatch countDownLatch = new CountDownLatch(1);
private static List<String> oldNews = null;
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
// Please start your performance!!!
// Step 1: get session
zookeeper = new ZooKeeper(CONNECT_INFO, TIME_OUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
// Make sure the link is established
if (countDownLatch.getCount() > 0 && event.getState() == Event.KeeperState.SyncConnected) {
System.out.println("Session link created successfully");
try {
// Get old service list
oldNews = zookeeper.getChildren(PARENT_NODE, false);
System.out.println("oldNews.size() = " + oldNews.size());
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
}
// Process listening
String listen_path = event.getPath();
Event.EventType eventType = event.getType();
// If it's test_ NodeChildrenChanged on node
if (listen_path.equals(PARENT_NODE) && eventType == Event.EventType.NodeChildrenChanged) {
System.out.println(PARENT_NODE + " It happened " + eventType + " event");
// Logical processing
try {
// All the latest published messages.
List<String> newNews = zookeeper.getChildren(PARENT_NODE, false);
System.out.println("newNews.size() = " + newNews.size());
// Find out the latest news
// If the publisher deletes a message, it doesn't mean much to the user, but it publishes a message. Then all subscribers and users need to be notified
for (String node : newNews) {
if (!oldNews.contains(node)) {
byte[] data = zookeeper.getData(PARENT_NODE + "/" + node, false, null);
System.out.println("New services announced:" + new String(data));
}
}
oldNews = newNews;
zookeeper.getChildren(PARENT_NODE, true);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
// Step 2: after the zookeeper session is established successfully, the main thread resumes execution
countDownLatch.await();
// Step 3: ensure that the parent service node exists
ArrayList<ACL> acls = ZooDefs.Ids.OPEN_ACL_UNSAFE;
CreateMode mode = CreateMode.PERSISTENT;
// Determine whether the parent node exists
Stat exists_parent = zookeeper.exists(PARENT_NODE, false);
if (exists_parent == null) {
zookeeper.create(PARENT_NODE, PARENT_NODE.getBytes(), acls, mode);
}
// Step 3: register to listen
zookeeper.getChildren(PARENT_NODE, true);
Thread.sleep(Integer.MAX_VALUE);
// Step 4: close the connection
zookeeper.close();
}
}
3.1.2. Naming service
Each znode in the zookeeper system has an absolutely unique path! So as long as you successfully create a znode node, it means that you have named a globally unique name!
Naming service is a common scenario in distributed systems. In distributed systems, the named entity can usually be a machine in the cluster, a service address provided or a remote object. Through naming service, the client can obtain the information of the resource entity, service address and provider according to the specified name. ZooKeeper can also help the application system locate and use resources through resource reference. In a broad sense, the resource location of naming service is not a real entity resource. In a distributed environment, the upper application only needs a globally unique name. ZooKeeper can implement a set of distributed globally unique ID allocation mechanism.
zk can create sequential nodes to ensure that the child nodes of the same node are unique. Therefore, set the nodes directly according to the method of storing files. For example, there cannot be two identical file names under one path. This definition creates a node, which is a globally unique ID
An algorithm specially used for naming services: SnowFlake snowflake algorithm
3.1.3. Cluster management
If the datanode in HDFS dies, naemndoe needs a default time of at least 630s before it is considered dead!
The so-called cluster management does not care about two points: whether a machine exits and joins, and electing a master.
For the first point, all machines agree to create temporary directory nodes under the parent directory GroupMembers, and then listen to the child node change messages of the parent directory node. Once a machine hangs up, the connection between the machine and ZooKeeper is disconnected, the temporary directory node created by the machine representing the survival status of the node is deleted, and all other machines will receive a notification that a brother directory is deleted. Therefore, everyone knows that a brother node hangs up. The addition of new machines is similar. All machines receive a notification that a new brother directory is added and another new brother node is added.
For the second point, let's change it a little. All machines create a temporary sequence number directory node. Each time, just select the machine with the lowest number as the master. Of course, this is only one of the strategies. The election strategy can be formulated by the administrator himself. In a distributed environment, the same business applications are distributed on different machines. Some business logic (such as some time-consuming computing and network I/O processing) often only needs to be executed by one machine in the whole cluster, and the other machines can share this result, which can greatly reduce duplication of labor and improve performance.
The strong consistency of ZooKeeper can ensure the global uniqueness of node creation in the case of distributed high concurrency, that is, if multiple clients request to create / currentMaster nodes at the same time, only one client request can be created successfully in the end. Using this feature, you can easily select clusters in a distributed environment. (in fact, as long as data uniqueness is realized, elections can be achieved, as can relational databases, but the performance is poor and the design is complex)
MasterHA.java
/**
* This is the server master node
*
* Core business:
* If A is the first online master, it will automatically become active
* If B is the second online master, it will automatically become standby
* If C is the third online master, it will automatically become standby
* If A goes down, B and C run for who is active
* Then A goes online and should automatically become standby
* Then, if any node in the standby goes down, the active and standby states of the remaining nodes do not need to be changed
* Then, if any node in active goes down, the remaining standby nodes will run for active status
*
* HFDS ZKFC MasterHA = ZKFC
*/
public class MasterHA {
private static ZooKeeper zk = null;
private static final String CONNECT_STRING = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
private static final int Session_TimeOut = 4000;
private static final String PARENT = "/cluster_ha";
private static final String ACTIVE = PARENT + "/active";
private static final String STANDBY = PARENT + "/standby";
private static final String LOCK = PARENT + "/lock";
/**
* Test sequence:
* 1,Start Hadoop 03 first and become active
* 2,Then start Hadoop 04 to become standby
* 3,Then start Hadoop 05 to become standby
* 4,Then start Hadoop 06 to become standby
* 5,Stop the active node Hadoop 03, then Hadoop 04, Hadoop 05 and Hadoop 06 will run for election. The winner is active, if it is Hadoop 4
* Then Hadoop 05 and Hadoop 06 will become standby
* 6,Kill the active node Hadoop 04 again, then Hadoop 05 and Hadoop 06 will run for election. If Hadoop 05 wins, then Hadoop 06 is still standing
* 7,Then go online Hadoop 03, and of course it will automatically become standby
* 8,Kill Hadoop 05 again, then Hadoop 03 and Hadoop 06 campaign
* ........
*/
private static final String HOSTNAME = "hadoop07";
private static final String activeMasterPath = ACTIVE + "/" + HOSTNAME;
private static final String standByMasterPath = STANDBY + "/" + HOSTNAME;
private static final CreateMode CME = CreateMode.EPHEMERAL;
private static final CreateMode CMP = CreateMode.PERSISTENT;
public static void main(String[] args) throws Exception {
// ---------------------Code execution sequence ID: 1-----------------------------
zk = new ZooKeeper(CONNECT_STRING, Session_TimeOut, new Watcher() {
@Override
public void process(WatchedEvent event) {
String path = event.getPath();
EventType type = event.getType();
if (path.equals(ACTIVE) && type == EventType.NodeChildrenChanged) {
// ---------------------Code execution sequence ID: 4-----------------------------
// If you find that the active master node under the active node has been deleted, you should run for active
if (getChildrenNumber(ACTIVE) == 0) {
// First register an exclusive lock and multiple standby roles. Whoever registers successfully should switch to the active state
try {
zk.exists(LOCK, true);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
// Create nodes and store data as their own information to facilitate judgment at that time
createZNode(LOCK, HOSTNAME, CME, "lock");
} else {
// getChildrenNumber(ACTIVE) == 1, indicating that an active node has just been generated and no operation is required
}
// Circular monitoring
try {
zk.getChildren(ACTIVE, true);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else if (path.equals(LOCK) && type == EventType.NodeCreated) {
// ---------------------Code execution sequence ID: 5-----------------------------
// ---------------------Code execution sequence identification: 3-1-1-----------------------------
// Get node data
String trueData = null;
try {
byte[] data = zk.getData(LOCK, false, null);
trueData = new String(data);
} catch (Exception e) {
}
// Judge whether it is created by the current node. If so, switch your state to active, otherwise no operation will be done
if (trueData.equals(HOSTNAME)) {
// It's yourself
createZNode(activeMasterPath, HOSTNAME, CME);
if (exists(standByMasterPath)) {
System.out.println(HOSTNAME + " Successfully switch your status to active");
deleteZNode(standByMasterPath);
} else {
System.out.println(HOSTNAME + " Campaign to become active state");
}
} else {
// Not yourself
}
}
}
});
// ---------------------Code execution sequence ID: 2-----------------------------
// Ensure that PARENT must exist
if (!exists(PARENT)) {
createZNode(PARENT, PARENT, CMP);
}
// Ensure that ACTIVE exists
if (!exists(ACTIVE)) {
createZNode(ACTIVE, ACTIVE, CMP);
}
// Ensure that STANDBY must exist
if (!exists(STANDBY)) {
createZNode(STANDBY, STANDBY, CMP);
}
// ---------------------Code execution sequence ID: 3-----------------------------
// First, judge whether there are child nodes under the active node. If so, there must be active nodes
// If not, register a lock first and let yourself run for active
if (getChildrenNumber(ACTIVE) == 0) {
// ---------------------Code execution sequence identification: 3-1-----------------------------
// Register listening
zk.exists(LOCK, true);
// Create a scramble lock
createZNode(LOCK, HOSTNAME, CME);
} else {
// ---------------------Code execution sequence identification: 3-2-----------------------------
// It automatically becomes a standby state
createZNode(standByMasterPath, HOSTNAME, CME);
System.out.println(HOSTNAME + " find active Exists, so it automatically becomes standby");
// Register to listen for changes in the number of active child nodes
zk.getChildren(ACTIVE, true);
}
// Keep the program running
Thread.sleep(Long.MAX_VALUE);
}
private static void deleteZNode(String standbymasterpath) {
try {
zk.delete(standbymasterpath, -1);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static int getChildrenNumber(String path) {
int number = 0;
try {
number = zk.getChildren(path, null).size();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return number;
}
public static boolean exists(String path) {
Stat exists = null;
try {
exists = zk.exists(path, null);
} catch (KeeperException e) {
} catch (InterruptedException e) {
}
if (exists == null) {
return false;
} else {
return true;
}
}
public static void createZNode(String path, String data, CreateMode cm) {
try {
zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, cm);
} catch (Exception e) {
System.out.println("Failed to create node or node already exists");
}
}
public static void createZNode(String path, String data, CreateMode cm, String message) {
try {
zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, cm);
} catch (Exception e) {
if (message.equals("lock")) {
System.out.println("I didn't grab the lock. Wait for the next wave");
}
}
}
}
3.1.4. Distributed lock
Lock: concurrent programming. Ensure thread safety (the safety of concurrent execution of multiple business logic within a JVM)! Lock critical resources directly. Whoever operates it needs to get the key first! Get the operation permit! This operation permit can only be obtained by one person at the same time.
Security of concurrent execution of multiple nodes in a distributed system
With ZooKeeper's consistent file system, the problem of locking becomes easy.
Lock services can be divided into two or three categories: exclusive lock, shared lock and sequential lock
1,Write lock: lock the write and keep it exclusive, or exclusive lock 2,Read lock: a lock is added to a read to share access. Transaction operations can be performed only after the lock is released. It is also called a shared lock 3,Timing lock: control timing
For the first type, we regard a znode on ZooKeeper as a lock, which is implemented by createznode(). All clients create / distribute_ The lock node, the client that is successfully created in the end, owns the lock. Delete the self created / distribution after use_ The lock node releases the lock.
For the second category, / distribute_ The lock already exists in advance. All clients create temporary sequential numbered directory nodes under it. Like the selected Master, the one with the smallest number obtains the lock, deletes it after use, and is in order.
Distributed synchronous lock
/**
* Description: Exclusive / exclusive lock implementation
*
* Requirement analysis: multiple roles compete for a lock.
* For example: many people carry out paper cutting activities together, but only one pair of scissors. Lock!
* Implementation idea: multiple roles compete for an exclusive lock at the same time. Whoever successfully writes the znode node has the execution right
**/
public class ZooKeeperDistributeSyncLock {
// zookeeper server address
private static final String CONNECT_INFO = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
private static final int TIME_OUT = 4000;
// Alternate parent-child node
private static final String LOCK_PARENT_NODE = "/parent_synclock";
private static final String LOCK_SUB_NODE = LOCK_PARENT_NODE + "/sub_sync_lock";
private static final String CURRENT_NODE = "bigdata03";
private static final Random random = new Random();
// Session object
private static ZooKeeper zookeeper = null;
private static ArrayList<ACL> acls = ZooDefs.Ids.OPEN_ACL_UNSAFE;
private static CreateMode mode = CreateMode.PERSISTENT;
// Latch is equivalent to an object lock. When the latch.await() method is executed, the thread where the method is located will wait
// When the count of latch is reduced to 0, the waiting thread will wake up
private static CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
// Please start your performance!!!
// Step 1: get the session link
zookeeper = new ZooKeeper(CONNECT_INFO, TIME_OUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
// Make sure the link is established
if (countDownLatch.getCount() > 0 && event.getState() == Event.KeeperState.SyncConnected) {
System.out.println("Session link created successfully");
countDownLatch.countDown();
}
String listen_path = event.getPath();
Event.EventType eventType = event.getType();
System.out.println(listen_path + "\t" + eventType);
// If the synchronization lock is deleted after a task is completed, all waiting tasks must receive a notification, and then compete for the registration lock
if (listen_path.equals(LOCK_SUB_NODE) && eventType.equals(Event.EventType.NodeDeleted)) {
try {
// Simulate to rob the resource lock, and create a temporary node. The advantage is that the task drops and the lock is automatically released
String node = zookeeper
.create(LOCK_SUB_NODE, LOCK_SUB_NODE.getBytes(), acls, CreateMode.EPHEMERAL);
// Continue to register for listening
try {
zookeeper.exists(LOCK_SUB_NODE, true);
} catch (KeeperException ex) {
ex.printStackTrace();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
// Execute business logic
handleBusiness(zookeeper, CURRENT_NODE);
} catch (Exception e) {
System.out.println("I didn't grab the exclusive lock. Let's wait another time");
}
} else if (listen_path.equals(LOCK_SUB_NODE) && eventType.equals(Event.EventType.NodeCreated)) {
}
// Continue to register for listening
try {
zookeeper.exists(LOCK_SUB_NODE, true);
} catch (KeeperException ex) {
ex.printStackTrace();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
});
// Step 2: after the zookeeper session is established successfully, the main thread resumes execution
countDownLatch.await();
// Step 3: ensure that the parent node exists
// Determine whether the parent node exists
Stat exists_parent = zookeeper.exists(LOCK_PARENT_NODE, false);
if (exists_parent == null) {
zookeeper.create(LOCK_PARENT_NODE, LOCK_PARENT_NODE.getBytes(), acls, mode);
}
// Step 4: register to listen
zookeeper.exists(LOCK_SUB_NODE, true);
// Step 5: compete for lock
// Simulate to rob the resource lock, and create a temporary node. The advantage is that the task drops and the lock is automatically released
try{
zookeeper.create(LOCK_SUB_NODE, LOCK_SUB_NODE.getBytes(), acls, CreateMode.EPHEMERAL);
// Step 6: execute business logic
handleBusiness(zookeeper, CURRENT_NODE);
} catch (Exception e){
System.out.println("The lock has been held by someone else. Wait for the next one");
}
// Step 7: keep the program running all the time
Thread.sleep(Integer.MAX_VALUE);
}
public static void handleBusiness(ZooKeeper zooKeeper, String server) {
int sleepTime = 10000;
System.out.println(server + " is working .......... " + System.currentTimeMillis());
try {
// Threads sleep for 0-4 seconds, which is the time consumed by simulating business code processing
Thread.sleep(random.nextInt(sleepTime));
// Simulation service processing completed
zooKeeper.delete(LOCK_SUB_NODE, -1);
System.out.println(server + " is done --------" + + System.currentTimeMillis());
// The thread sleeps for 0-4 seconds to simulate a time interval when the client processes the business again after each processing,
// The ultimate goal is to disrupt the order in which multiple servers running you rush to register the child nodes
Thread.sleep(random.nextInt(sleepTime));
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}
Distributed timing lock
/**
* Description: Timing lock implementation
*
* Requirement Description: multiple clients need to access the same resource at the same time, but only one client is allowed to access at the same time.
* Design idea: multiple clients write a child znode under the parent znode. If they can write successfully, they will wait. When the previous task is completed,
* The task with the smallest ID in the waiting queue can continue to execute!
**/
public class ZooKeeperDistributeSequenceLock {
private static final String connectStr = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
private static final int sessionTimeout = 4000;
private static final String PARENT_NODE = "/parent_locks";
private static final String SUB_NODE = "/sub_sequence_lock";
private static String currentPath = "";
static ZooKeeper zookeeper = null;
public static void main(String[] args) throws Exception {
ZooKeeperDistributeSequenceLock mdc = new ZooKeeperDistributeSequenceLock();
// 1. Get the zookeeper link
mdc.getZookeeperConnect();
// 2. Check whether the parent node exists. If it does not exist, create it
Stat exists = zookeeper.exists(PARENT_NODE, false);
if (exists == null) {
zookeeper.create(PARENT_NODE, PARENT_NODE.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 3. Listen to parent node
zookeeper.getChildren(PARENT_NODE, true);
// 4. Register a node under the parent node and register a temporary node. The advantage is that the node will be automatically deleted when it is down or disconnected
currentPath = zookeeper.create(PARENT_NODE + SUB_NODE, SUB_NODE.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
Thread.sleep(Long.MAX_VALUE);
// 5. Close zk link
zookeeper.close();
}
// Get the link to the zookeeper cluster
public void getZookeeperConnect() throws Exception {
zookeeper = new ZooKeeper(connectStr, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType() + "\t" + event.getPath());
// Match to see if the child nodes change, and the listening path should also be correct
if (event.getType() == EventType.NodeChildrenChanged && event.getPath().equals(PARENT_NODE)) {
try {
// Get all child nodes of the parent node and continue listening
List<String> childrenNodes = zookeeper.getChildren(PARENT_NODE, true);
// Matches whether the currently created znode is the smallest znode
Collections.sort(childrenNodes);
if ((PARENT_NODE + "/" + childrenNodes.get(0)).equals(currentPath)) {
// Processing business
handleBusiness(zookeeper, currentPath);
} else {
System.out.println("not me");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
}
public void handleBusiness(ZooKeeper zk, String create) throws Exception {
Random random = new Random();
int sleepTime = 4000;
System.out.println(create + " is working .......... ");
// Threads sleep for 0-4 seconds, which is the time consumed by simulating business code processing
Thread.sleep(random.nextInt(sleepTime));
// Simulation service processing completed
zk.delete(currentPath, -1);
System.out.println(create + " is done --------");
// The thread sleeps for 0-4 seconds to simulate a time interval when the client processes the business again after each processing,
// The ultimate goal is to disrupt the order in which multiple servers running you rush to register the child nodes
Thread.sleep(random.nextInt(sleepTime));
// Simulate robbing resource lock
currentPath = zk.create(PARENT_NODE + SUB_NODE, SUB_NODE.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
}
3.1.5. Queue management
There are two types of queues:
1,Synchronization queue/Distributed barrier: when the members of a queue gather, the queue is available, otherwise it will wait for all members to arrive. 2,First in first out queue FIFO Enter and exit the team.
First, create temporary directory nodes in the agreed directory and listen to whether the number of nodes is the number we require.
The second category is consistent with the basic principle of the control timing scenario in the distributed lock service. There are numbers in the column and numbers in the column
SyncQueueServer.java
/**
* Description: Synchronous queue, distributed fence
*
* Function: used to record each online server
* Specific measures: write the information of our online server under a znode in zookeeper's file system
**/
public class SyncQueueServer {
private static final String CONNECT_STRING = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
private static final int sessionTimeout = 4000;
private static final String PARENT_NODE = "/syncQueue";
private static final String HOSTNAME = "bigdata02";
public static void main(String[] args) throws Exception {
// 1. Get a link to zookeeper
ZooKeeper zk = new ZooKeeper(CONNECT_STRING, sessionTimeout, new Watcher() {
// Note: this listener will listen for all zookeeper events
@Override
public void process(WatchedEvent event) {
// TODO Auto-generated method stub
}
});
// 2. First judge whether the parent node exists
Stat exists = zk.exists(PARENT_NODE, false);
if (exists == null) {
zk.create(PARENT_NODE, PARENT_NODE.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} else {
System.out.println(PARENT_NODE + " Already exists, do not need me to create");
}
// 3. Record the information of a newly launched server under the parent node. Node name: / syncQueue/hadoop01
String path = zk.create(PARENT_NODE + "/" + HOSTNAME, HOSTNAME.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("The servers currently online are:" + HOSTNAME + ", The child nodes registered by the current server are:" + path);
Thread.sleep(Long.MAX_VALUE);
zk.close();
}
}
SyncQueueClient.java
/**
* Description: Synchronous queue, distributed fence
*
* Function: we execute the business class of the business method and listen to parent_ Number of child nodes under node
* Because we implement synchronous queues, our business methods can only be executed when a certain number of queue members are reached
**/
public class SyncQueueClient {
private static final String CONNECT_STRING = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
private static final int sessionTimeout = 4000;
private static final String PARENT_NODE = "/syncQueue";
private static final int NEED_QUEUE = 3;
static ZooKeeper zk = null;
static int count = 0;
public static void main(String[] args) throws Exception {
// 1. Get zookeeper link
zk = new ZooKeeper(CONNECT_STRING, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
String path = event.getPath();
EventType et = event.getType();
// Judge whether the monitored nodes and events meet the requirements for the first time
if (path.equals(PARENT_NODE) && et == EventType.NodeChildrenChanged) {
// The second step is to judge whether all the members of the queue have reached. If so, the business method can be executed
try {
List<String> children = zk.getChildren(PARENT_NODE, true);
int queueNumber = children.size();
if (queueNumber == NEED_QUEUE) {
handleBusiness(true);
} else if (queueNumber < NEED_QUEUE) {
if (count == NEED_QUEUE) {
handleBusiness(false);
} else {
System.out.println("Waiting for other brothers to go online.......");
}
}
count = queueNumber;
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
// 2. First judge whether the parent node exists
Stat exists = zk.exists(PARENT_NODE, false);
if (exists == null) {
zk.create(PARENT_NODE, PARENT_NODE.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} else {
System.out.println(PARENT_NODE + " Already exists, do not need me to create");
}
// 3. Listen to the znode that the program should listen to
zk.getChildren(PARENT_NODE, true);
Thread.sleep(Long.MAX_VALUE);
zk.close();
}
/**
* First, our program will always listen to PARENT_NODE, wait for all queue members under the monitored node to arrive. If the conditions are met, the business method will be executed
* This condition is:
* 1,An event of a node received by the business program must meet the requirements of the node we are listening to
* 2,All members of the queue have reached
*/
public static void handleBusiness(boolean flag) throws Exception {
if (flag) {
System.out.println("Processing business method........");
} else {
System.out.println("Business processing stopped");
}
}
}
3.1.6. Load balancing
ZooKeeper's load balancing is essentially the steps to realize load balancing by using zk's configuration management function:
1,Service providers put their domain names and IP Port mapping registered to zk Yes. 2,Service consumers from zk Get the corresponding IP And ports, here IP There may be multiple and ports, just get one of them. 3,When the service provider goes down, the corresponding domain name and IP The correspondence will be reduced by one mapping. 4,Ali's dubbo Service framework is based on zk Implement service routing and load.
3.2. Zookeeper best enterprise application
3.2.1. Election
See the code, including the implementation idea!
/cluster_ha
/active
/hadoop01
/lock
/standby
/hadoop02
/hadoop03
/cluster_ha
/active
/hadoop02
/lock
/standby
/hadoop03
Idea realization:
early stage: zk Status of: Yes/active Node and/standby Node, but there is no information below,/lock The node does not exist 1,hadoop01 Once online, discovery automatically becomes standby Role, so register your information to /standby Under node 2,hadoop01 Go online and find it again/active Whether there are child nodes under the node. If so, it is proved that there are active If not, compete for distributed locks 3,If you don't get it, it means that others get it and others become active,If you get it, put your information in/standby Delete it and update it to /active Under node 4,hadoop02 Once online, I found/active There are child nodes under the node active, Will automatically become standby Role, can listen /active znode monitor: NodeChildrenChagended. Equivalent to telling zk System, as long as /active When the number of child nodes changes, the system will tell me. /active There can only be one child node below. Since it is reduced, then hadoop02 You'll be notified 5,hadoop03 Online, behavioral and hadoop02 coincident 6,hypothesis hadoop01 Downtime, hadoop01 Follow zk The session maintained by the system is disconnected due to the created lock and /active The following child nodes are temporary nodes hadoop01 As soon as the machine goes down, the two nodes are automatically shut down zk The system deleted because hadoop02 and hadoop03 After listening to this event, they will be notified, and then they all know active leader No, they're all fighting to become active Grab it first /lock Lock. Finally create this lock Only one server will succeed in locking, so whoever creates it successfully will become a server active, No lock node was created /lock Success is still standby.
Recommendation: use zookeeper's API framework: curator to implement HA: LeaderLatch LeaderSelector to reduce the complexity of coding
3.2.2. Distributed lock
See the code, including the implementation idea!
Using distributed locks, we can achieve: election. The implementation of HDFS HA mechanism is the same logic as my code!
But this is not the difficulty for HDFS to implement HA: the real difficulty: active and keeping the data state consistent!
3.2.3. Configuration management
Requirement: there are multiple nodes in a cluster. If you change a parameter, each node must know.
Common methods:
1,Write a shell Script to notify all nodes 2,Manually, change to each node 3,be based on zk The role of changing the configuration is called the client, and the role of registering the monitoring parameters is called the server
See the code, including the implementation idea!
4. Summary
Today's main content is to explain how to use the two core functions of Zookeeper to realize some common enterprise needs. Focus on understanding the working principle of ZK, and then summarize the routine:
- zookeeper is a peer-to-peer architecture. When working, elections will be held and become a leader + follower architecture.
- A complete copy of all data in zookeeper is saved in all nodes.
- All transaction operations of zookeeper are executed in zk system strictly and orderly.
- The leader role in the zookeeper system can perform read and write operations.
- The follower role in the zookeeper system can perform read operations, but after receiving write operations, it will be forwarded to the leader for execution.
- The leader of the zookeeper system is equivalent to a globally unique distributed transaction initiator. All other follower s are transaction participants and have the right to vote.
- Another role in the zookeeper system is called observer. The biggest difference between this role and follower is that observer is exactly the same as follower except that it has no right to vote and stand for election.
- The function of observer is to share the data reading pressure of the whole cluster, but not to increase the execution pressure of distributed transactions, because the execution of distributed transactions will only be performed in the leader and follower. Observer just keeps synchronization with the leader, and then helps provide external data reading services.
- Although the zookeeper system provides a storage system, this storage is only prepared for realizing some functions, not provided to store a large amount of data for users.
- zookeeper provides the regular operations of adding, deleting, modifying and querying znode nodes. Using these operations, you can simulate the corresponding business operations. Using the listening mechanism, you can make the client immediately perceive this change.
- The biggest difference between zookeeper cluster and other distributed clusters is that zk cannot be linearly expanded. Because the cluster service capability of HDFS is directly proportional to the number of nodes in the cluster, but the more nodes in zk system, the worse the performance.
- The best configuration of zookeeper cluster: for example, 9, 11, 13 such follower nodes and several observer s! Remember not to follow too much!
- If the zookeeper system has such a situation: the data of a znode changes very fast, and each change triggers a process callback! When zk executes a transaction, it is executed strictly and orderly by a serial single node. The leader is responsible for the sequential execution of this transaction. Multiple events are too late to execute. The previous event has not been executed. The next trigger action will be ignored by zk! Little impact!