problem
(1) How does zookeeper implement distributed locks?
(2) What are the advantages of zookeeper distributed locks?
(3) What are the disadvantages of zookeeper distributed lock?
brief introduction
zooKeeper is a distributed, open source distributed application coordination service. It can provide consistent services for distributed applications. It is an important component of Hadoop and Hbase. It can also be used as a configuration center and registry in the micro-service system.
In this chapter, we will introduce how zookeeper implements the application of distributed locks in distributed systems.
Basic knowledge
What is znode?
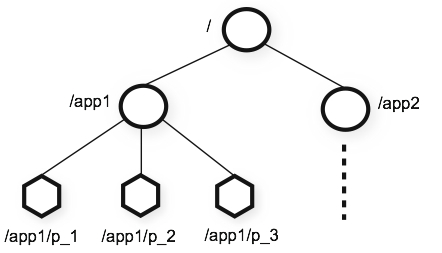
zooKeeper operates and maintains one data node, called znode, which is managed by a hierarchical tree structure similar to the file system. If the znode contains data, it is stored as a byte array.
Moreover, multiple customers are created at the same node. This article is written by the public number "Tong Ge read the source code" original. Only one client will succeed, and the other clients will fail when it is created.
Node type
There are four types of znode:
Persistence (disorder)
Persistent order
Temporary (disorder)
Provisional order
If the persistent node is not manually deleted, it will always exist, and the temporary node will automatically delete the node when the client session fails.
What is watcher?
watcher is an important feature of zookeeper.
Zookeeper allows users to register watcher s on specified nodes, and when certain events are triggered, the zooKeeper server notifies interested clients of events. This mechanism is an important feature of Zookeeper to implement distributed coordination services.
| KeeperState | EventType | Trigger condition | Explain | operation |
|---|---|---|---|---|
| SyncConnected(3) | None(-1) | Successful connection between client and server | At this point the client and server are connected | - |
| Ditto | NodeCreated(1) | The corresponding data node that Watcher listens on is created | Ditto | Create |
| Ditto | NodeDeleted(2) | The corresponding data node Watcher monitors is deleted | Ditto | Delete/znode |
| Ditto | NodeDataChanged(3) | The data content of the corresponding data node monitored by Watcher changes | Ditto | setDate/znode |
| Ditto | NodeChildChanged(4) | The list of child nodes of the corresponding data node monitored by Wather has changed | Ditto | Create/child |
| Disconnected(0) | None(-1) | Client disconnects from ZooKeeper server | At this point, the client and server are disconnected | - |
| Expired(-112) | None(-1) | session time out | At this point, the client session fails and is usually subject to Session Expired Exception exceptions as well. | - |
| AuthFailed(4) | None(-1) | Usually there are two cases: 1: using the wrong schema for permission checking 2: SASL permission checking failed | Usually you also receive AuthFailedException exceptions | - |
Principle analysis
Scheme 1
Since the same node can only be created once, it can detect whether the node exists while locking, create it if it does not exist, and listen for deletion events when it exists or fails to create. Thus, when the lock is released, the client listens to compete again to create the node, and if it succeeds, the lock is acquired, and if it fails, listen for the node again.
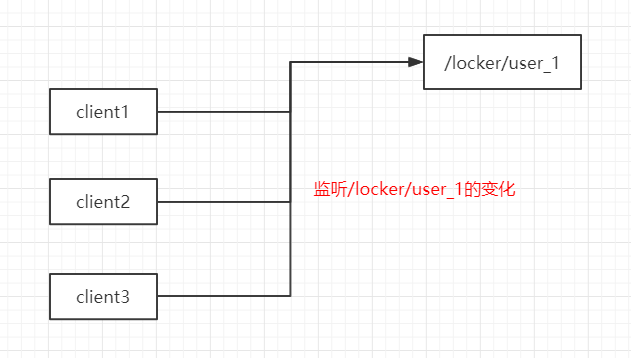
For example, three clients client1, client2 and client3 simultaneously acquire the lock / locker/user_1. They will run as follows:
(1) The three try to create / locker/user_1 node at the same time;
(2) client1 was created successfully, and it acquired the lock;
(3) client2 and client3 failed to create, and they listened for deletion events in / locker/user_1;
(4) client1 executes in-lock business logic;
(5) client1 releases the lock and deletes the node/locker/user_1;
(6) client2 and client3 capture events deleted by node/locker/user_1, both of which are awakened;
(7) client2 and client3 simultaneously create / locker/user_1 nodes;
(8) go back to the second step and follow the analogy.
However, this scheme has a serious drawback - shock effect.
If the concurrency is very high, multiple clients monitor the same node at the same time, when releasing the lock, wake up so many clients at the same time, and then compete, and finally only one can get the lock, and the other clients are sleeping. The wake-up of these clients is meaningless and wastes system resources greatly, then is there a better solution? The answer is yes, see Plan 2.
Option two
In order to solve the surprise effect in scheme 1, we can use ordered sub-nodes to implement distributed locking, and in order to avoid the risk of sudden disconnection after the client acquires the lock, it is necessary to use temporary ordered nodes.
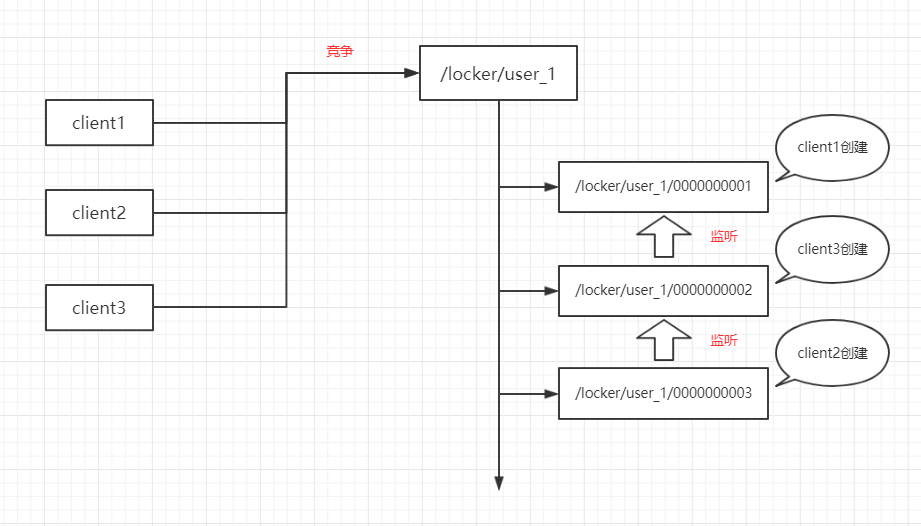
For example, three clients client1, client2 and client3 simultaneously acquire the lock / locker/user_1. They will run as follows:
(1) They create temporarily ordered sub-nodes under / locker/user_1/ at the same time.
(2) All three were successfully created, respectively, / locker/user_1/0000001, / locker/user_1/0000003, / locker/user_1/0000000002;
(3) Check whether the node you create is the smallest of the sub-nodes.
(4) client1 finds itself the smallest node, which acquires the lock;
(5) client2 and client3 find themselves not the smallest nodes, they can not get locks;
(6) client2 creates a node, / locker/user_1/0000000003, which listens for deletion events of its last node, / locker/user_1/0000000002;
(7) client3 creates a node, / locker/user_1/0000000002, which listens for deletion events of its last node, / locker/user_1/0000000001;
(8) client1 executes in-lock business logic;
(9) client1 releases the lock and deletes the node/locker/user_1/0000000001;
(10) client3 wakes up when it hears the deletion event of node/locker/user_1/0000001;
(11) client3 checks again whether it is the smallest node, and finds that it is, it gets the lock.
(12) client3 implements the business logic of the lock.
(13) client3 releases the lock and deletes the node/locker/user_1/0000002;
(14) client2 wakes up when it hears deletion events of node/locker/user_1/0000000002;
(15) client2 executes in-lock business logic;
(16) client2 releases the lock and deletes the node/locker/user_1/0000000003;
(17) client2 checks if there are any child nodes under / locker/user_1 / and deletes / locker/user_1 node if there are none.
(18) Process completion;
Compared with scheme one, this scheme only wakes up one client each time the lock is released, which reduces the cost of thread wake-up and improves the efficiency.
Implementation of zookeeper native API
pom file
The following jar packages are introduced into pom:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.5</version>
</dependency>Locker interface
Define a Locker interface that uses the same interface as the mysql distributed lock in the previous chapter.
public interface Locker {
void lock(String key, Runnable command);
}Implementation of zookeeper Distributed Lock
Here, the internal class ZkLockerWatcher is used to handle the operation of zookeeper. The following points need to be noted:
(1) Do not perform any related operations before the zk connection is established, otherwise the ConnectionLoss exception will be reported, where the connection thread is blocked and waked up in the listening thread through LockSupport.park();
(2) The client thread and the listener thread are not the same thread, so they can be handled by LockSupport.park(); and LockSupport.unpark(thread);
(3) Many of the steps in the middle are not atomic (pits), so it needs to be detected again, as detailed in the comments in the code;
@Slf4j
@Component
public class ZkLocker implements Locker {
@Override
public void lock(String key, Runnable command) {
ZkLockerWatcher watcher = ZkLockerWatcher.conn(key);
try {
if (watcher.getLock()) {
command.run();
}
} finally {
watcher.releaseLock();
}
}
private static class ZkLockerWatcher implements Watcher {
public static final String connAddr = "127.0.0.1:2181";
public static final int timeout = 6000;
public static final String LOCKER_ROOT = "/locker";
ZooKeeper zooKeeper;
String parentLockPath;
String childLockPath;
Thread thread;
public static ZkLockerWatcher conn(String key) {
ZkLockerWatcher watcher = new ZkLockerWatcher();
try {
ZooKeeper zooKeeper = watcher.zooKeeper = new ZooKeeper(connAddr, timeout, watcher);
watcher.thread = Thread.currentThread();
// Blocking waits for the connection to be established
LockSupport.park();
// If the root node does not exist, create one (concurrency problem, if two threads detect the non-existence at the same time, one of them must fail to create at the same time)
if (zooKeeper.exists(LOCKER_ROOT, false) == null) {
try {
zooKeeper.create(LOCKER_ROOT, "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} catch (KeeperException e) {
// If the node already exists, the creation fails, where exceptions are caught and the normal operation of the program is not blocked.
log.info("Create node {} fail", LOCKER_ROOT);
}
}
// Does the currently locked node exist?
watcher.parentLockPath = LOCKER_ROOT + "/" + key;
if (zooKeeper.exists(watcher.parentLockPath, false) == null) {
try {
zooKeeper.create(watcher.parentLockPath, "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} catch (KeeperException e) {
// If the node already exists, the creation fails, where exceptions are caught and the normal operation of the program is not blocked.
log.info("Create node {} fail", watcher.parentLockPath);
}
}
} catch (Exception e) {
log.error("conn to zk error", e);
throw new RuntimeException("conn to zk error");
}
return watcher;
}
public boolean getLock() {
try {
// Create a child node [this article is written by the public number "Tong Ge read the source code" original).
this.childLockPath = zooKeeper.create(parentLockPath + "/", "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// Check to see if you are the smallest node, if you are successful, not if you are listening on the last node
return getLockOrWatchLast();
} catch (Exception e) {
log.error("get lock error", e);
throw new RuntimeException("get lock error");
} finally {
// System.out.println("getLock: " + childLockPath);
}
}
public void releaseLock() {
try {
if (childLockPath != null) {
// Release locks and delete nodes
zooKeeper.delete(childLockPath, -1);
}
// Last Released Delete Lock Node
List<String> children = zooKeeper.getChildren(parentLockPath, false);
if (children.isEmpty()) {
try {
zooKeeper.delete(parentLockPath, -1);
} catch (KeeperException e) {
// If a new child node is added before deletion, the deletion will fail.
log.info("Delete node {} fail", parentLockPath);
}
}
// Close zk connection
if (zooKeeper != null) {
zooKeeper.close();
}
} catch (Exception e) {
log.error("release lock error", e);
throw new RuntimeException("release lock error");
} finally {
// System.out.println("releaseLock: " + childLockPath);
}
}
private boolean getLockOrWatchLast() throws KeeperException, InterruptedException {
List<String> children = zooKeeper.getChildren(parentLockPath, false);
// It has to be sorted. The order taken out here may be messy.
Collections.sort(children);
// If the current node is the first child, the lock is successful
if ((parentLockPath + "/" + children.get(0)).equals(childLockPath)) {
return true;
}
// If it's not the first child, listen on the previous node
String last = "";
for (String child : children) {
if ((parentLockPath + "/" + child).equals(childLockPath)) {
break;
}
last = child;
}
if (zooKeeper.exists(parentLockPath + "/" + last, true) != null) {
this.thread = Thread.currentThread();
// Blocking the current thread
LockSupport.park();
// After waking up, re-check whether you are the smallest node, because it is possible that the last node is disconnected.
return getLockOrWatchLast();
} else {
// If the last node does not exist, it is released before it is too late to listen. Check again
return getLockOrWatchLast();
}
}
@Override
public void process(WatchedEvent event) {
if (this.thread != null) {
// Wake up blocked threads (this is a listening thread, not the same thread as the thread that gets the lock)
LockSupport.unpark(this.thread);
this.thread = null;
}
}
}
}Test code
We have two batches of threads here, one to get the user_1 lock and the other to get the user_2 lock.
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class ZkLockerTest {
@Autowired
private Locker locker;
@Test
public void testZkLocker() throws IOException {
for (int i = 0; i < 1000; i++) {
new Thread(()->{
locker.lock("user_1", ()-> {
try {
System.out.println(String.format("user_1 time: %d, threadName: %s", System.currentTimeMillis(), Thread.currentThread().getName()));
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}, "Thread-"+i).start();
}
for (int i = 1000; i < 2000; i++) {
new Thread(()->{
locker.lock("user_2", ()-> {
try {
System.out.println(String.format("user_2 time: %d, threadName: %s", System.currentTimeMillis(), Thread.currentThread().getName()));
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}, "Thread-"+i).start();
}
System.in.read();
}
}Operation results:
You can see the result of printing two locks stabilized around 500 ms.
user_1 time: 1568973299578, threadName: Thread-10 user_2 time: 1568973299579, threadName: Thread-1780 user_1 time: 1568973300091, threadName: Thread-887 user_2 time: 1568973300091, threadName: Thread-1542 user_1 time: 1568973300594, threadName: Thread-882 user_2 time: 1568973300594, threadName: Thread-1539 user_2 time: 1568973301098, threadName: Thread-1592 user_1 time: 1568973301098, threadName: Thread-799 user_1 time: 1568973301601, threadName: Thread-444 user_2 time: 1568973301601, threadName: Thread-1096 user_1 time: 1568973302104, threadName: Thread-908 user_2 time: 1568973302104, threadName: Thread-1574 user_2 time: 1568973302607, threadName: Thread-1515 user_1 time: 1568973302607, threadName: Thread-80 user_1 time: 1568973303110, threadName: Thread-274 user_2 time: 1568973303110, threadName: Thread-1774 user_1 time: 1568973303615, threadName: Thread-324 user_2 time: 1568973303615, threadName: Thread-1621
curator implementation
The native API implementation above makes it easier to understand the logic of zookeeper implementing distributed locks, but it is guaranteed that there is no problem, for example, no reentry locks, no support for read and write locks, etc.
Let's take a look at how the existing wheel curler is implemented.
pom file
The following jar packages are introduced into the pom file:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>code implementation
The following is an implementation of mutex:
@Component
@Slf4j
public class ZkCuratorLocker implements Locker {
public static final String connAddr = "127.0.0.1:2181";
public static final int timeout = 6000;
public static final String LOCKER_ROOT = "/locker";
private CuratorFramework cf;
@PostConstruct
public void init() {
this.cf = CuratorFrameworkFactory.builder()
.connectString(connAddr)
.sessionTimeoutMs(timeout)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
cf.start();
}
@Override
public void lock(String key, Runnable command) {
String path = LOCKER_ROOT + "/" + key;
InterProcessLock lock = new InterProcessMutex(cf, path);
try {
// This article is from the public number "Tong Ge read the source code" original.
lock.acquire();
command.run();
} catch (Exception e) {
log.error("get lock error", e);
throw new RuntimeException("get lock error", e);
} finally {
try {
lock.release();
} catch (Exception e) {
log.error("release lock error", e);
throw new RuntimeException("release lock error", e);
}
}
}
}In addition to mutually exclusive locks, curator also provides read-write locks, multiple locks, semaphores and other implementations, and they are re-accessible locks.
summary
(1) There are four types of nodes in zookeeper: persistent, persistent, temporary and temporary.
(2) zookeeper provides a very important feature - monitoring mechanism, which can be used to monitor the changes of nodes.
(3) zookeeper distributed lock is based on temporary ordered node + monitoring mechanism.
(4) zookeeper creates temporary ordered nodes under lock paths in distributed locking.
(5) If you are the first node, you get the lock.
(6) If it is not the first node, it monitors the previous node and blocks the current thread.
(7) When the deletion event of the previous node is monitored, the thread of the current node is awakened and the first node is checked again.
(8) Temporary ordered nodes are used instead of persistent ordered nodes in order to release locks automatically when the client disconnects without any reason.
Egg
What are the advantages of zookeeper distributed locks?
Answer: 1) zookeeper itself can be deployed in clusters, which is more reliable than mysql's single point.
2) It will not occupy the number of connections of mysql, and will not increase the pressure of mysql.
3) Use the monitoring mechanism to reduce the number of context switching;
4) Client disconnection can release locks automatically, which is very safe.
5) Existing wheel curator can be used;
6) The curator implementation is reentrant, and the cost of revamping the existing code is small.
What are the disadvantages of zookeeper distributed lock?
Answer: 1) Locking will frequently "write" zookeeper, increasing the pressure of zookeeper;
2) When writing zookeeper, it synchronizes in the cluster. The more nodes, the slower synchronization, the slower the process of acquiring locks.
3) We need to rely on zookeeper, but most services do not use zookeeper, which increases the complexity of the system.
4) Compared with redis distributed locks, the performance is slightly worse.
Recommended reading
1,The Beginning of the Dead java Synchronization Series
2,Unsafe Analysis of Dead java Magic
3,JMM (Java Memory Model) of Dead java Synchronization Series
4,volatile analysis of dead java synchronization series
5,synchronized analysis of dead-end java synchronization series
6,Do it yourself to write a Lock
7,AQS Beginning of the Dead java Synchronization Series
9,ReentrantLock Source Code Resolution of Dead java Synchronization Series (2) - Conditional Lock
10,ReentrantLock VS synchronized
11,ReentrantReadWriteLock Source Parsing of Dead java Synchronization Series
12,Semaphore Source Parsing of Dead java Synchronization Series
13,CountDownLatch Source Parsing of Dead java Synchronization Series
14,The Final AQS of the Dead java Synchronization Series
15,StampedLock Source Parsing of Dead java Synchronization Series
16,Cyclic Barrier Source Parsing of Dead java Synchronization Series
17,Phaser Source Parsing of Dead java Synchronization Series
18,mysql distributed lock of deadly java synchronization series
Welcome to pay attention to my public number "Tong Ge read the source code", see more source series articles, and swim together with brother Tong's source ocean.
