What is a distributed lock
For example, when "process 1" uses the resource, it will first obtain the lock. After "process 1" obtains the lock, it will maintain exclusive access to the resource, so that other processes cannot access the resource. After "process 1" uses up the resource, it will release the lock and let other processes obtain the lock. Then through this lock mechanism, We can ensure that multiple processes in the distributed system can access the critical resource orderly. Then we call this lock in the distributed environment distributed lock.
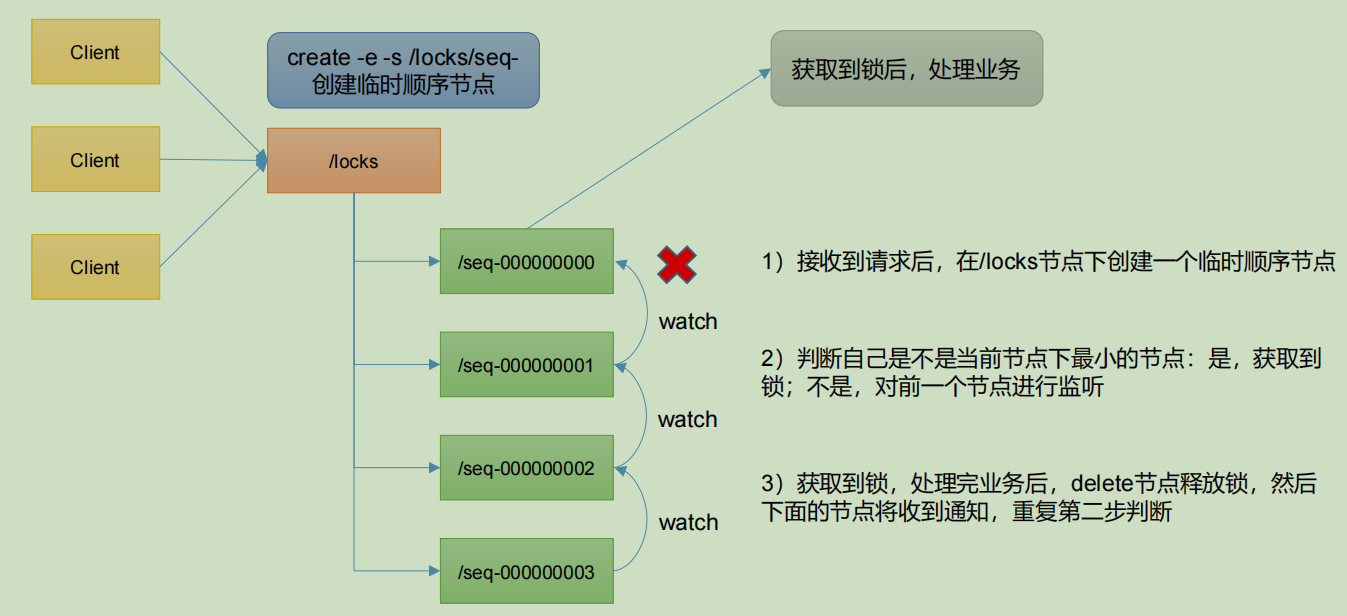
Distributed lock case implemented by native Zookeeper
1) Distributed lock implementation
//The distributed lock is realized through the counter mechanism of CountDownLatch
public class DistributedLock {
// zookeeper server list
private String connectString =
"hadoop102:2181,hadoop103:2181,hadoop104:2181";
// Timeout
private int sessionTimeout = 2000;
private ZooKeeper zk;
//Root node
private String rootNode = "locks";
//Root node lower face sub node
private String subNode = "seq-";
// The ordered sequence number of the child nodes that the current client is waiting for
private String waitPath;
//ZooKeeper connection
private CountDownLatch connectLatch = new CountDownLatch(1);
//ZooKeeper node waiting
private CountDownLatch waitLatch = new CountDownLatch(1);
// Child nodes created by the current client
private String currentNode;
// Establish a connection with the zk service and create a root node
public DistributedLock() throws IOException,
InterruptedException, KeeperException {
zk = new ZooKeeper(connectString, sessionTimeout, new
Watcher() {
@Override
public void process(WatchedEvent event) {
// When the connection is established, open the latch to wake up the wait thread on the latch
if (event.getState() ==
Event.KeeperState.SyncConnected) {
connectLatch.countDown();
}
// A delete event of waitPath occurred
if (event.getType() ==
Event.EventType.NodeDeleted && event.getPath().equals(waitPath)) {
waitLatch.countDown();
}
}
});
// Waiting for connection to be established
connectLatch.await();
//Get root node status
Stat stat = zk.exists("/" + rootNode, false);
//If the root node does not exist, a root node is created. The root node type is permanent
if (stat == null) {
System.out.println("The root node does not exist");
zk.create("/" + rootNode, new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
// Locking method
public void zkLock() {
try {
//Create a temporary order node under the root node, and the return value is the created node path
currentNode = zk.create("/" + rootNode + "/" + subNode,
null, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// wait a minute to make the result clearer
Thread.sleep(10);
// Note that it is not necessary to listen to the changes of the child nodes of "/ locks"
List<String> childrenNodes = zk.getChildren("/" +
rootNode, false);
// There is only one child node in the list, which must be currentNode, indicating that the client obtains the lock
if (childrenNodes.size() == 1) {
return;
} else {
//Sort all temporary order nodes under the root node from small to large
Collections.sort(childrenNodes);
//Current node name
String thisNode = currentNode.substring(("/" +
rootNode + "/").length());
//Gets the location of the current node
int index = childrenNodes.indexOf(thisNode);
if (index == -1) {
System.out.println("Data exception");
} else if (index == 0) {
// index == 0 indicates that thisNode is the smallest in the list, and the current client obtains the lock
return;
} else {
// Obtain the node ranking 1 higher than currentNode
this.waitPath = "/" + rootNode + "/" +
childrenNodes.get(index - 1);
// Register the listener on the waitPath. When the waitPath is deleted, zookeeper will call back the listener's process method
zk.getData(waitPath, true, new Stat());
//Enter the waiting lock state
waitLatch.await();
return;
}
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// Unlocking method
public void zkUnlock() {
try {
zk.delete(this.currentNode, -1);
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
}
2) Distributed lock test
(1) Create two threads
public class DistributedLockTest {
public static void main(String[] args) throws
InterruptedException, IOException, KeeperException {
// Create distributed lock 1
final DistributedLock lock1 = new DistributedLock();
// Create distributed lock 2
final DistributedLock lock2 = new DistributedLock();
new Thread(new Runnable() {
@Override
public void run() {
// Get lock object
try {
lock1.zkLock();
System.out.println("Thread 1 acquire lock");
Thread.sleep(5 * 1000);
lock1.zkUnlock();
System.out.println("Thread 1 release lock");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
// Get lock object
try {
lock2.zkLock();
System.out.println("Thread 2 acquire lock");
Thread.sleep(5 * 1000);
lock2.zkUnlock();
System.out.println("Thread 2 releases the lock");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
} }
(2) Observe console changes:
Thread 1 acquire lock Thread 1 release lock Thread 2 acquire lock Thread 2 releases the lock
The case of implementing distributed lock with cursor framework
1) Problems in native Java API development
(1) The session connection is asynchronous and needs to be handled by yourself. For example, use CountDownLatch
(2) The Watch needs to be registered repeatedly, otherwise it will not take effect
(3) The complexity of development is still relatively high
(4) Multi node deletion and creation are not supported. You need to recurse yourself
2) Cursor is a special framework for solving distributed locks, which solves the problems encountered in the development of native Java APIs.
For details, please check the official documents: https://curator.apache.org/index.html
3) Curator case practice
(1) Add dependency
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.3.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.3.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-client</artifactId> <version>4.3.0</version> </dependency>
(2) Code implementation
public class CuratorLockTest {
private String rootNode = "/locks";
// zookeeper server list
private String connectString =
"hadoop102:2181,hadoop103:2181,hadoop104:2181";
// connection timeout
private int connectionTimeout = 2000;
// session timeout
private int sessionTimeout = 2000;
public static void main(String[] args) {
new CuratorLockTest().test();
}
// test
private void test() {
// Create distributed lock 1
final InterProcessLock lock1 = new
InterProcessMutex(getCuratorFramework(), rootNode);
// Create distributed lock 2
final InterProcessLock lock2 = new
InterProcessMutex(getCuratorFramework(), rootNode);
new Thread(new Runnable() {
@Override
public void run() {
// Get lock object
try {
lock1.acquire();
System.out.println("Thread 1 acquire lock");
// Test lock reentry
lock1.acquire();
System.out.println("Thread 1 acquires the lock again");
Thread.sleep(5 * 1000);
lock1.release();
System.out.println("Thread 1 release lock");
lock1.release();
System.out.println("Thread 1 releases the lock again");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
// Get lock object
try {
lock2.acquire();
System.out.println("Thread 2 acquire lock");
// Test lock reentry
lock2.acquire();
System.out.println("Thread 2 acquires the lock again");
Thread.sleep(5 * 1000);
lock2.release();
System.out.println("Thread 2 releases the lock");
lock2.release();
System.out.println("Thread 2 releases the lock again");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
// Distributed lock initialization
public CuratorFramework getCuratorFramework (){
//Retry strategy, initial test time 3 seconds, retry 3 times
RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);
//Create a cursor from a factory
CuratorFramework client =
CuratorFrameworkFactory.builder()
.connectString(connectString)
.connectionTimeoutMs(connectionTimeout)
.sessionTimeoutMs(sessionTimeout)
.retryPolicy(policy).build();
//Open connection
client.start();
System.out.println("zookeeper Initialization complete...");
return client;
} }
(3) Observe console changes:
Thread 1 acquire lock
Thread 1 acquires the lock again
Thread 1 release lock
Thread 1 releases the lock again
Thread 2 acquire lock
Thread 2 acquires the lock again
Thread 2 releases the lock
Thread 2 releases the lock again
zk knowledge summary
1. Electoral mechanisms
Half of the mechanism, more than half of the votes passed, that is, passed.
(1) First start of election rules:
When more than half of the votes are cast, the server with a large id wins
(2) Second start of election rules:
① EPOCH big direct winner
② The same as EPOCH, the one with a large transaction id wins
③ If the transaction id is the same and the server id is larger, the winner will win
2. How many zk suitable production clusters are installed?
Install an odd number.
Production experience:
⚫ 10 servers: 3 zk;
⚫ 20 servers: 5 zk;
⚫ 100 servers: 11 zk;
⚫ 200 servers: 11 zk
Large number of servers: benefits and improved reliability; Disadvantages: improve communication delay
3. Common commands
ls,get,create,delete