Preface
Implement a handwritten WC program and package it to run on the cluster.
Create a Maven project and import pom
Engineering catalogue
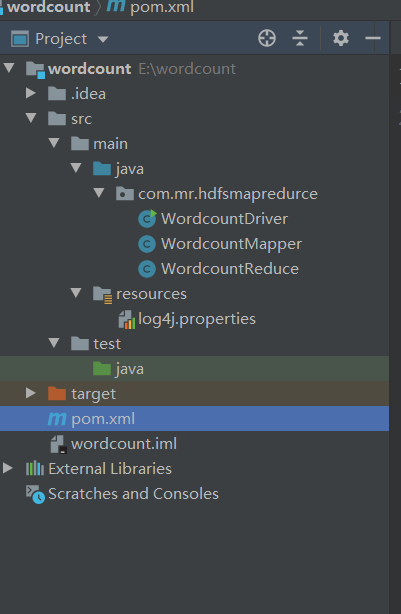
Import pom
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.zhengkw</groupId> <artifactId>wordcount</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> <!-- <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency>--> </dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <!--Packaging tools, using maven Total package jar --> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>com.atguigu.mapreduce.WordcountDriver</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
Mapper
package com.mr.hdfsmapredurce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @ClassName:WordcountMapper * @author: zhengkw * @description: mapper * @date: 20/02/24 Forenoon 8:42 am * @version:1.0 * @since: jdk 1.8 */ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text(); IntWritable v = new IntWritable(1); /** * @param key * @param value * @param context * @descrption:Rewrite map to realize wordcount * @return: void * @date: 20/02/24 Forenoon 8:47 am * @author: zhengkw */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 get a row String line = value.toString().trim(); // 2 cutting String[] words = line.split(" "); // 3 output for (String word : words ) { k.set(word); //Expected output is < Hadoop, 1 > -- > < string, int > context.write(k, v); } } }
Reduce
package com.mr.hdfsmapredurce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @ClassName:WordcountRedurce * @author: zhengkw * @description: redurce * @date: 20/02/24 Forenoon 8:42 am * @version:1.0 * @since: jdk 1.8 */ public class WordcountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { int sum; IntWritable v = new IntWritable(); /** * @param key * @param values * @param context * @descrption: * @return: void * @date: 20/02/24 Forenoon 8:51 am * @author: zhengkw */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 1 summation by accumulation for (IntWritable value : values ) { sum += value.get(); } // 2 output v.set(sum); context.write(key, v); } }
Driver
package com.mr.hdfsmapredurce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @descrption: * @return: * @date: 20/02/24 Forenoon 8:53 am * @author: zhengkw */ public class WordcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //1 get configuration information and encapsulation tasks Configuration configuration = new Configuration(); //Instantiate job object with profile reflection Job job = Job.getInstance(configuration); // 2. Set the jar loading path job.setJarByClass(WordcountDriver.class); // 3. Set map and reduce classes job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReduce.class); // 4 set map output job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 set final output kv type job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 set input and output paths FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 submission boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
be careful!!!
Parameter is received by args [] in main! When testing, you need to pass in parameters during running, which are Pathin and pathout!!
Package to run on Cluster
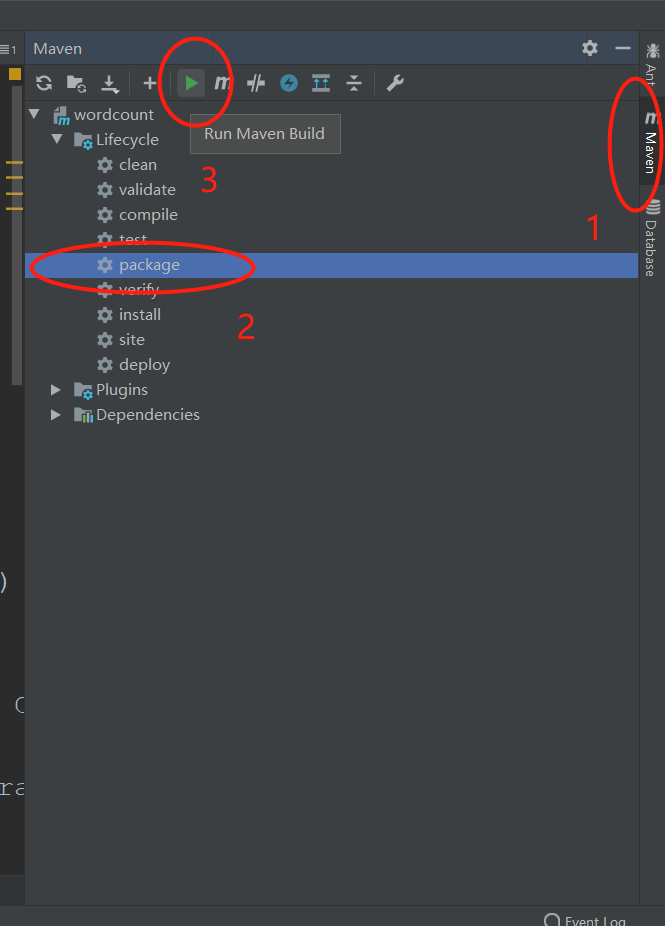 Two kinds of jar s are produced after packaging
Two kinds of jar s are produced after packaging
Select jar
Jar selection depends on whether there is dependency in the jar running environment. It is executed on the cluster, and there are various dependencies on the cluster, so you can choose jar without dependency!
Upload jar to cluster and run
Running handwritten WCjar requires bin/hadoop jar to follow the full class name of the driver class!!!!
Preparation data

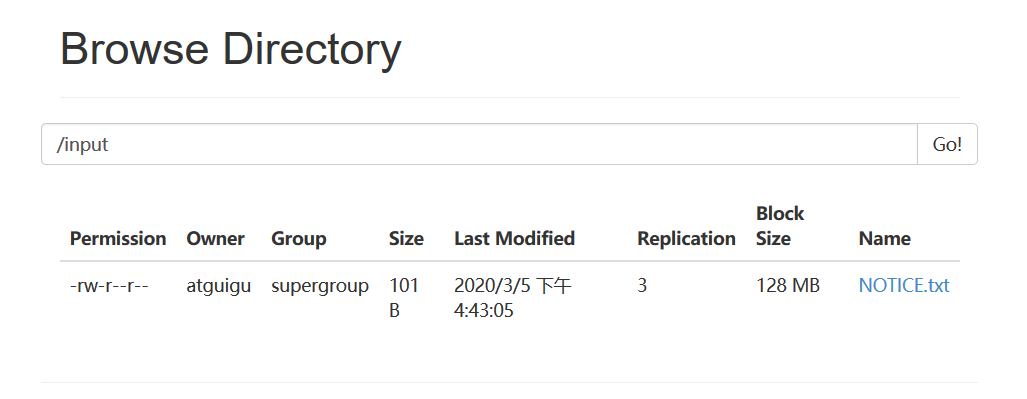
test
Running handwritten WCjar requires bin/hadoop jar to follow the full class name of the driver class!!!!
Running handwritten WCjar requires bin/hadoop jar to follow the full class name of the driver class!!!!
Running handwritten WCjar requires bin/hadoop jar to follow the full class name of the driver class!!!!
Successful operation
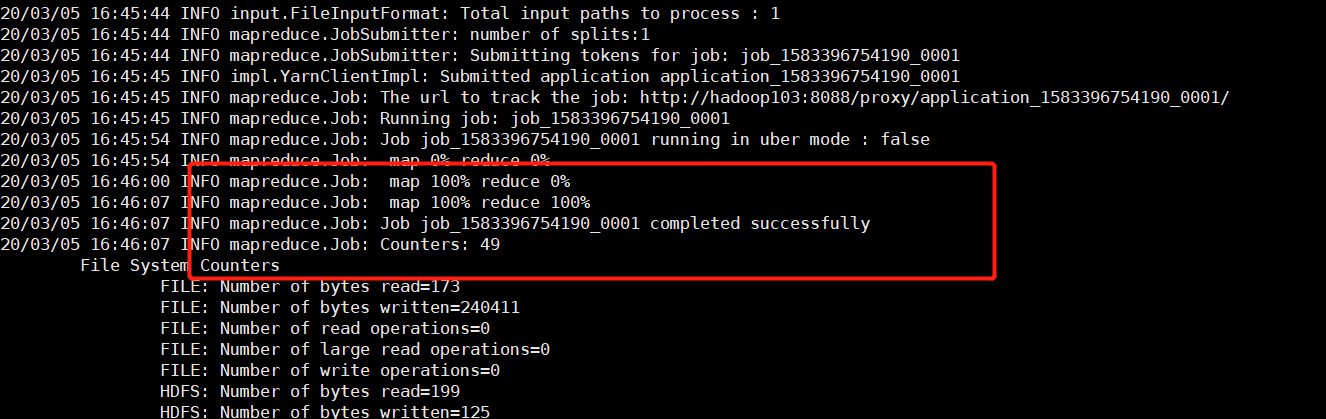
test
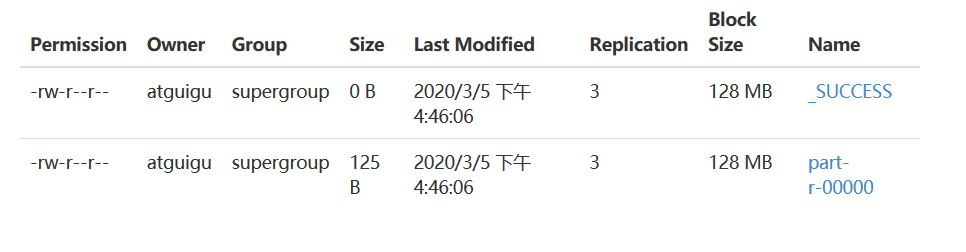
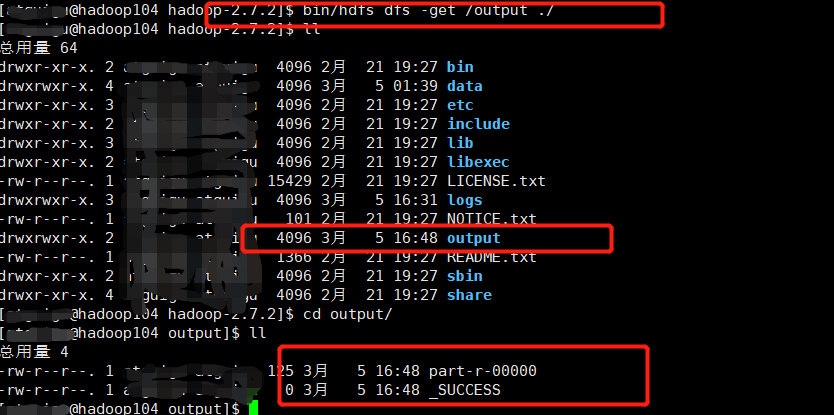
View results
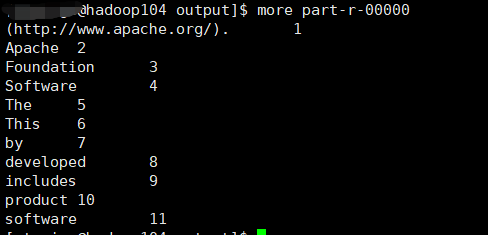
summary
- The package jar can run on the cluster without selecting the dependent jar package.
- When running the jar package, the hadoop jar is followed by the full class name of its driver class!! It is very important, otherwise it will report an error, and the class cannot be found!
- The parameters of the program must be passed by args array and cannot be written to death!

