What are Cgroups?
Cgroups is the abbreviation of control groups. It is a mechanism provided by the Linux kernel that can limit, record and isolate the physical resources (such as cpu,memory,IO, etc.) used by process groups. Originally proposed by google engineers, it was later integrated into the Linux kernel.
What can Cgroups do?
The initial goal of cgroups is to provide a unified framework for resource management, which not only integrates the required cpuset and other subsystems, but also provides interfaces for the development of new subsystems in the future. Cgroups are now applicable to a variety of application scenarios, from resource control of a single process to OS Level Virtualization.
cgroups subsystem
Its implementation principle is to set the parameters of various Linux subsystem s, and then bind the process with these subsystems.
Linux subsystem has the following types:
- blkio
- cpu
- cpuacct counts the CPU usage of processes in cgroup
- cpuset
- devices
- freezer user suspends and resumes processes from the group
- memeory controls the memory usage of processes in cgroup
- net_cls
- net_prio
- ns
By installing the cgroup tool
$ apt-get install cgroup-tools $ lssubsys -a cpuset cpu,cpuacct blkio memory devices freezer net_cls,net_prio perf_event hugetlb pids rdma
cgroups hierarchy
The function of hierarchy is to organize a group of cgroups into a tree structure so that cgroups can inherit
A cgroup1 limits the CPU utilization frequency of the processes (P1, P2, P3) under it. If you want to limit the memory of process P2, you can create cgroup2 under cgroup1 to inherit from cgroup1, which can limit the CPU utilization, and set the memory limit without affecting other processes.
The kernel uses cgroups structure to express the resource constraints on one or several cgroups subsystems. It is organized in the form of a tree, which is called hierarchy
cgroups and processes
Relationship among hierarchy, subsystem and cgroup process group
hierarchy only implements the inheritance relationship, and the real resource restriction still depends on the subsystem
By attaching the subsystem to the hierarchy,
Add the process group to the hierarchy (task) to realize resource restriction
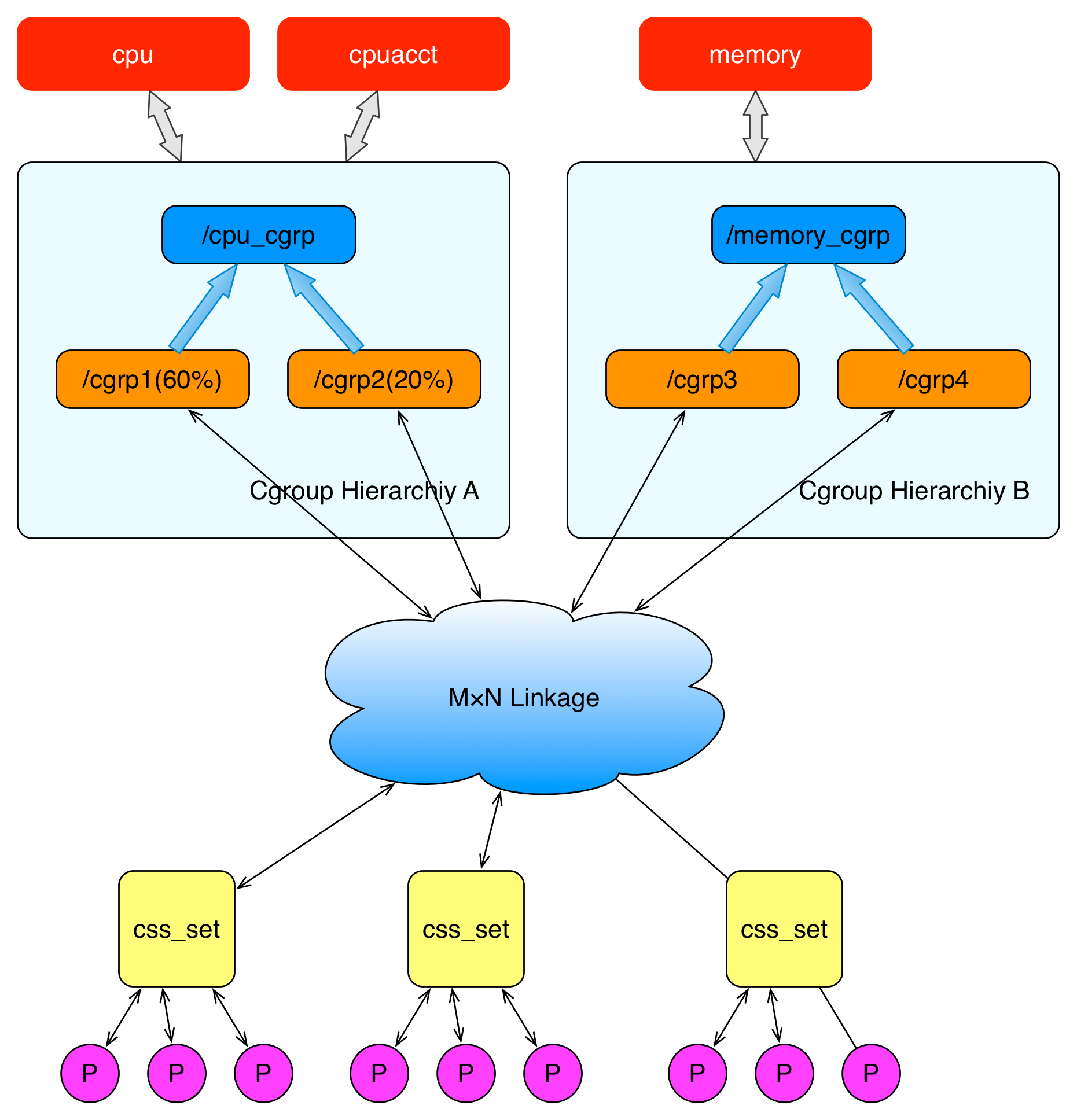
As can be seen from this figure:
- A subsystem can only be attached to a hierarchy
- A hierarchy can attach multiple subsystem s
- A process can be a member of multiple cgroups, but these cgroups must be in different hierarchies.
- When a process fork s out a child process, the child process is in the same cgroup as the parent process, or it can be moved to other cgroups as needed.
cgroups file system
The underlying implementation of cgroups is hidden by the VFS (Virtual File System) of the Linux kernel, exposing a unified file system API excuse to the user state. Let's experience the use of this file system:
- First, create and mount a hierarchy (cgroup tree)
$ mkdir cgroup-test $ sudo mount -t cgroup -o none,name=cgroup-test cgrout-test ./cgroup-test $ ls ./cgrpup-test cgroup.clone_children cgroup.sane_behavior release_agent cgroup.procs notify_on_release tasks
These files are the configuration items of the cgroup root node in the hierarchy
cgroup.clone_children will be read by the cpuset subsystem. If it is 1, the child CGroup will inherit the cpuset configuration of the parent CGroup.
notify_on_release and release_agent is used to manage some operations when the last process exits
tasks identifies the process ID under the cgroup and associates the process members of the cgroup with the hierarchy
2. Create two more child hierarchies. Create two child cgroups expanded from the cgroup root node of the newly created hierarchy
$ cd cgroup-test $ sudo mkdir cgroup-1 $ sudo mkdir cgroup-2 $ tree . ├── cgroup-1 │ ├── cgroup.clone_children │ ├── cgroup.procs │ ├── notify_on_release │ └── tasks ├── cgroup-2 │ ├── cgroup.clone_children │ ├── cgroup.procs │ ├── notify_on_release │ └── tasks ├── cgroup.clone_children ├── cgroup.procs ├── cgroup.sane_behavior ├── notify_on_release ├── release_agent └── tasks 2 directories, 14 files
You can see that when creating a folder in a cgroup directory, the Kernel will mark the folder as the child cgroup of the cgroup, and they will inherit the properties of the parent cgroup.
- Adding and moving processes to cgroup
In the hierarchy of a cgroup, a process can only exist on one cgroup node. All processes of the system exist on the root node by default. You can move the process to other cgroup nodes. You only need to write the process ID to the tasks file of the cgroup node.
# cgroup-test $ ehco $$ 3444 $ cat /proc/3444/cgroup 13:name=cgroup-test:/ 12:cpuset:/ 11:rdma:/ 10:devices:/user.slice 9:perf_event:/ 8:net_cls,net_prio:/ 7:pids:/user.slice/user-1000.slice/user@1000.service 6:memory:/user.slice/user-1000.slice/user@1000.service ...
You can see that the process of the current terminal is under the root cgroup. Now we move it to the child cgroup
$ cd cgroup-1 $ sudo sh -c "echo $$ >> tasks" $ cat /proc/3444/cgroup 13:name=cgroup-test:/cgroup-1 12:cpuset:/ 11:rdma:/ 10:devices:/user.slice 9:perf_event:/ 8:net_cls,net_prio:/ 7:pids:/user.slice/user-1000.slice/user@1000.service 6:memory:/user.slice/user-1000.slice/user@1000.service ...
You can see that the CGroup to which the terminal process belongs has changed to cgroup-1. Look at the tasks of the parent CGroup. There is no ID of the terminal process
$ cd cgroup-test $ cat tasks | grep "3444" # Return empty
- Restrict the resources of processes in cgroup through subsystem.
By default, the operating system has created a default hierarchy for each subsystem in the sys/fs/cgroup / directory
$ ls /sys/fs/cgroup blkio cpu,cpuacct freezer net_cls perf_event systemd cpu cpuset hugetlb net_cls,net_prio pids unified cpuacct devices memory net_prio rdma
You can see that the hierarchy of the memory subsystem also creates a cgroup in it
$ cd /sys/fs/cgroup/memory $ sudo mkdir test-limit-memory && cd test-limit-memorysudo # Set the maximum memory usage to 100MB $ sudo sh -c "echo "100m" > memory.limit_in_bytes"sudo sh -c "echo $$ > tasks" sudo sh -c "echo $$ > tasks" $ sudo sh -c "echo $$ > tasks" # Running stress that occupies 200MB of memory often $ stress --vm-bytes 200m --vm-keep -m 1
You can compare the remaining memory before and after running, which is only reduced by 100MB
# Before operation $ top top - 12:04:12 up 6:45, 1 user, load average: 1.87, 1.29, 1.06 task: 348 total, 1 running, 346 sleeping, 0 stopped, 1 zombie %Cpu(s): 1.3 us, 0.9 sy, 0.0 ni, 97.7 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st MiB Mem : 5973.4 total, 210.8 free, 2820.9 used, 2941.8 buff/cache MiB Swap: 923.3 total, 921.9 free, 1.3 used. 2746.3 avail Mem # After operation $ top top - 12:04:57 up 6:45, 1 user, load average: 2.25, 1.44, 1.12 task: 351 total, 3 running, 347 sleeping, 0 stopped, 1 zombie %Cpu(s): 34.3 us, 32.8 sy, 0.0 ni, 21.1 id, 4.9 wa, 0.0 hi, 6.9 si, 0.0 st MiB Mem : 5973.4 total, 118.6 free, 2956.7 used, 2898.1 buff/cache MiB Swap: 923.3 total, 817.7 free, 105.5 used. 2604.5 avail Mem
This indicates that the cgroup restriction is in effect
How to restrict cgroup in docker
First run a restricted memory container
$ sudo docker pull redis:4 $ sudo docker run -tid -m 100m redis:4 d79f22eb11d22c56a90f88e0aeb3cfda7cbe9639e2ab0e8532003a695e375e8d
Check the cgroup bound to the original memory subsystem, and you will see that there are more cgroups and dockers in it
$ ls /sys/fs/cgroup/memory ... docker ... $ ls /sys/fs/cgroup/memory/docker cgroup.clone_children memory.max_usage_in_bytes cgroup.event_control memory.memsw.failcnt cgroup.procs memory.memsw.limit_in_bytes d79f22eb11d22c56a90f88e0aeb3cfda7cbe9639e2ab0e8532003a695e375e8d memory.memsw.max_usage_in_bytes memory.failcnt memory.memsw.usage_in_bytes memory.force_empty memory.move_charge_at_immigrate memory.kmem.failcnt memory.numa_stat memory.kmem.limit_in_bytes memory.oom_control memory.kmem.max_usage_in_bytes memory.pressure_level memory.kmem.slabinfo memory.soft_limit_in_bytes memory.kmem.tcp.failcnt memory.stat memory.kmem.tcp.limit_in_bytes memory.swappiness memory.kmem.tcp.max_usage_in_bytes memory.usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.use_hierarchy memory.kmem.usage_in_bytes notify_on_release memory.limit_in_bytes tasks
You can see that the d79f22eb11d22c56a90f88e0aeb3cfda7cbe9639e2ab0e8532003a695e375e8dcgroup in the docker CGroup is just us
The container ID just created. Let's take a look inside
$ cd /sys/fs/cgroup/memory/docker/d79f22eb11d22c56a90f88e0aeb3cfda7cbe9639e2ab0e8532003a695e375e8d $ cat memory.limit_in_bytes 104857600cat # Exactly 100MB
summary
This paper describes the principle of cgroups, which is organized and related through three concepts (cgroup, subsystem and hierarchy)
3-tier structure, associate the process in cgroup, then associate cgroup with hierarchy, and then associate subsystem with hierarchy, so as to achieve a certain goal on the basis of limiting process resources
Reuse capability.
This paper describes the specific implementation of docker. When using docker, you can also know how to limit the resources used by containers.