First install Docker:
$ sudo apt-get install apt-transport-https
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9
$ sudo bash -c "echo deb https://get.docker.io/ubuntu docker main > /etc/apt/sources.list.d/docker.list"
$ sudo apt-get update
$ sudo apt-get install lxc-dockerAfter the installation is complete, you can use the command docker-v or docker version to see if the installation is successful.
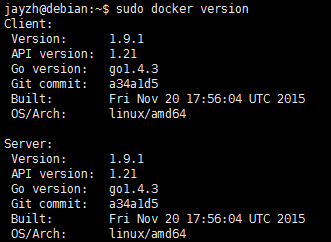
Download the ubuntu image:
$ sudo docker pull ubuntu:14.04View the mirror using the docker images command 
Create a JDK environment image based on the original image:
Create a container using the previously downloaded ubuntu image
$ sudo docker run -ti ubuntu:14.04
Configuring the environment in the startup container
Install JDK first (or choose to install openjdk)
# apt-get install software-properties-common python-software-properties
# add-apt-repository ppa:webupd8team/java
# apt-get update
# apt-get install oracle-java8-installerUse the command java-version to verify that the installation was successful 
Here you can package the container s of the jdk environment as a mirror for easy use
root@809e08c54981:/# exit
jayzh@debian:~$ sudo docker commit -m "jdk8 env" 809e08c54981 ubuntu:javaNote that 809e08c54981 here is the container_id of the container just created 
Create Hadoop image based on JDK image:
Start a container from the image you just created
$ sudo docker run -ti ubuntu:javaInstall wget first
# apt-get update
# apt-get install wgetDownload Hadoop
root@b2cc1876211d:cd ~
root@b2cc1876211d:~# mkdir soft
root@b2cc1876211d:~# cd soft/
root@b2cc1876211d:~/soft# mkdir apache
root@b2cc1876211d:~/soft# cd apache/
root@b2cc1876211d:~/soft/apache# mkdir hadoop
root@b2cc1876211d:~/soft/apache# cd hadoop/
root@b2cc1876211d:~/soft/apache/hadoop# wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
root@b2cc1876211d:~/soft/apache/hadoop# tar xvzf hadoop-2.7.3.tar.gz
Configure environment variables:
root@b2cc1876211d:/# cd ~
root@b2cc1876211d:~# vim .bashrc Add at the end of the file 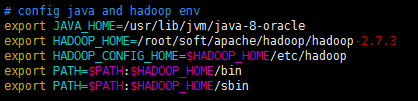
Create the required directories for Hadoop:
root@b2cc1876211d:~# cd $HADOOP_HOME/
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3# mkdir tmp
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3# mkdir namenode
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3# mkdir datanode
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3# cd $HADOOP_CONFIG_HOME/
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3/etc/hadoop# cp mapred-site.xml.template mapred-site.xmlModify the Hadoop configuration file:
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3/etc/hadoop# vim core-site.xml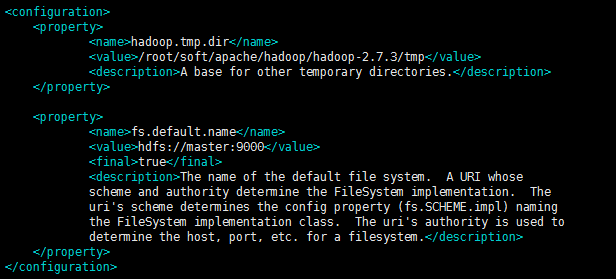
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3/etc/hadoop# vim hdfs-site.xml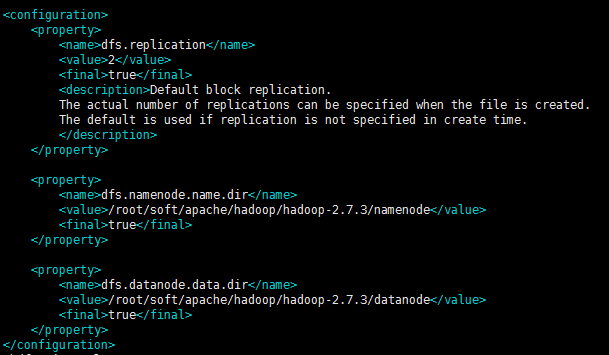
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3/etc/hadoop# vim mapred-site.xml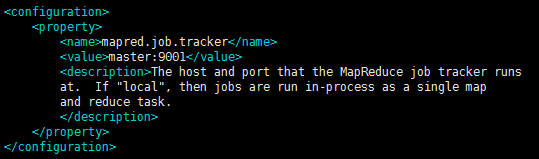
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3/etc/hadoop# vim hadoop-env.sh
Format namenode
root@b2cc1876211d:~/soft/apache/hadoop/hadoop-2.7.3/etc/hadoop# hadoop namenode -formatThe hadoop cluster environment relies on ssh, so install SSH first and configure automatic startup
# apt-get update
# apt-get install sshEdit the. bashrc file to add the following configuration:
# cd ~
# vim .bashrc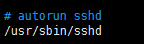
Generate key:
# cd ~/
# ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
# cd .ssh
# cat id_dsa.pub >> authorized_keysIf a directory cannot be found when starting sshd, create a new directory as shown in the figure. 
Once the Hadoop environment is configured, a mirror save can be generated again
root@b2cc1876211d:~# exit
jayzh@debian:~$ sudo docker commit -m "hadoop env" b2cc1876211d ubuntu:hadoopCreate containers through Hadoop mirrors:
container creation is done through the previously created Hadoop image, where you need to create three containers, one master, and two slave s
jayzh@debian:~$ sudo docker run -h master --name master -tid -p 9000:9000 -p 9001:9001 -p 50070:50070 ubuntu:hadoop
jayzh@debian:~$ sudo docker run -h slave1 --name slave1 -tid ubuntu:hadoop
jayzh@debian:~$ sudo docker run -h slave2 --name slave2 -tid ubuntu:hadoop* Adding port mapping from host to container to enable access to container applications or services over an extranet
* Note that after creating the container, exit using CTRL+P+Q, the container will continue to run as a daemon, but exit using commands such as CTRL+C/exit will stop the container.
* The docker attach container id/name can be attached to the running container.
View the IP of each container through the ifconfig command and write it into the hosts configuration file of each container: 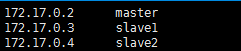
After the configuration is completed, login to the master container and modify the slaves file:
root@master:~# cd $HADOOP_CONFIG_HOME
root@master:~/soft/apache/hadoop/hadoop-2.7.3/etc/hadoop# vim slaves 
Hadoop can be started when all configuration is complete
root@master:~# cd $HADOOP_HOME/
root@master:~/soft/apache/hadoop/hadoop-2.7.3# cd sbin/
root@master:~/soft/apache/hadoop/hadoop-2.7.3/sbin# ./start-all.sh
After startup, you can view the status of hadoop through a Web page( http://your-server-ip-or-domain:50070/) 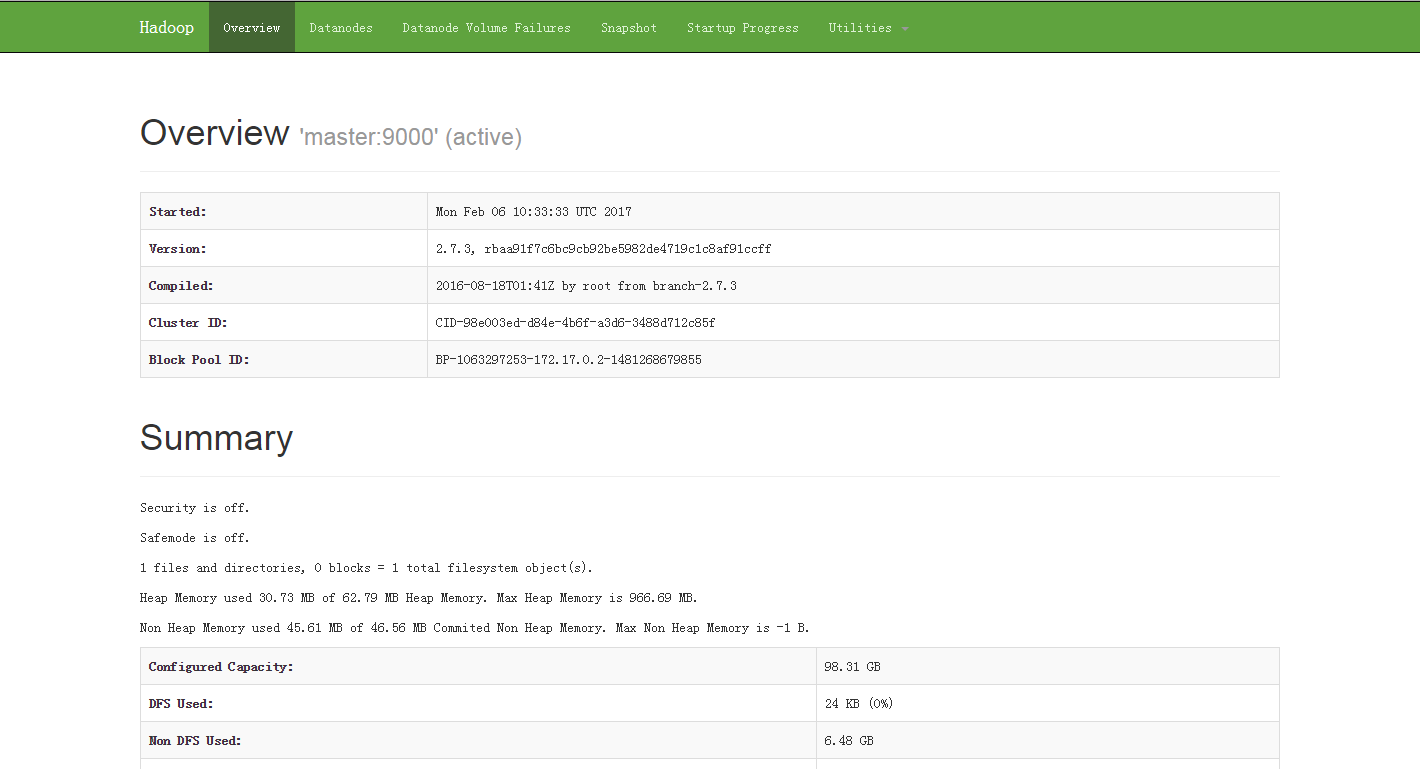
PS: The code style of CSDN MARKDOWN is really ugly--#
Reference material:
Common Docker commands
Using Docker to Build Hadoop Distributed Cluster Locally