HashMap Source Analysis
Previous articles analyzed the source code of the ArrayList, LinkedList, Vector, Stack List collections. In addition to the List collections, the Java container contains Set and Map as two important collection types.HashMap is the most representative and the collection of Maps we use most often.This article tries to analyze the source code of HashMap. Since there are so many aspects at the bottom of HashMap that an article can't cover all of them, we can look at the source code with a few questions that interviewers often ask:
- Understanding how the underlying layer stores data
- Several main methods of HashMap
- How HashMap determines where elements are stored and how hash conflicts are handled
- What is the mechanism of HashMap expansion
- What changes have JDK 1.8 made to the HashMap source code to expand capacity and resolve hash conflicts?What are the benefits?
This article will also expand the description from the above aspects:
Since the Nugget Background Audit may cause posting delays or omissions for some reason, if you feel I've written a good source analysis article, you can follow me and I can receive a push every time I update the article.In addition, the blogger is also making progress. If you have any questions about all articles, please leave a message for me.I will correct it in time.We all make progress together.
Summary
To facilitate the following narrative, here is an overview of several common points of knowledge about HashMap:
-
HashMap stores data based on key-value pairs, and when storing multiple data, the keys of the data cannot be the same, and the corresponding values before the same key will be overwritten.Note that if you want to ensure that HashMap stores data correctly, make sure that the equals() method has been correctly overridden for the class as the key.
-
The location where HashMap stores data is related to the hashCode () return value of the key that added the data.So when using HashMap storage for elements, make sure you have rewritten the hashCode() method as required.This means that the relationship representing the final storage location may not necessarily be the return value of hashCode.
-
HashMap allows at most one key to store data to be null, and multiple data values to be null.
-
HashMap stores data in an indeterminate order and may change the storage location of elements due to expansion.Therefore, the traversal order is uncertain.
-
HashMap is thread-insecure and can be made thread-safe by using the Collections.synchronizedMap(Map map) method if multiple threads are needed, or by using ConcurrentHashMap.
Learn how the underlying HashMap stores data
To analyze HashMap source code, you must divide a line between JDK1.8 and JDK1.7 because the underlying implementation of HashMap has changed since JDK 1.8.
Storage structure before JDK 1.7
Through the previous article Understanding Java equals and hashCode methods As we know about the hash table, we know that the timely hashCode() method has been written perfectly and may eventually result in a "hash collision". HashMap, as a collection that uses hash values to determine where elements are stored, also needs to handle hash conflicts.Prior to 1.7, JDK used zipper method to store data, which is the combination of arrays and chains:
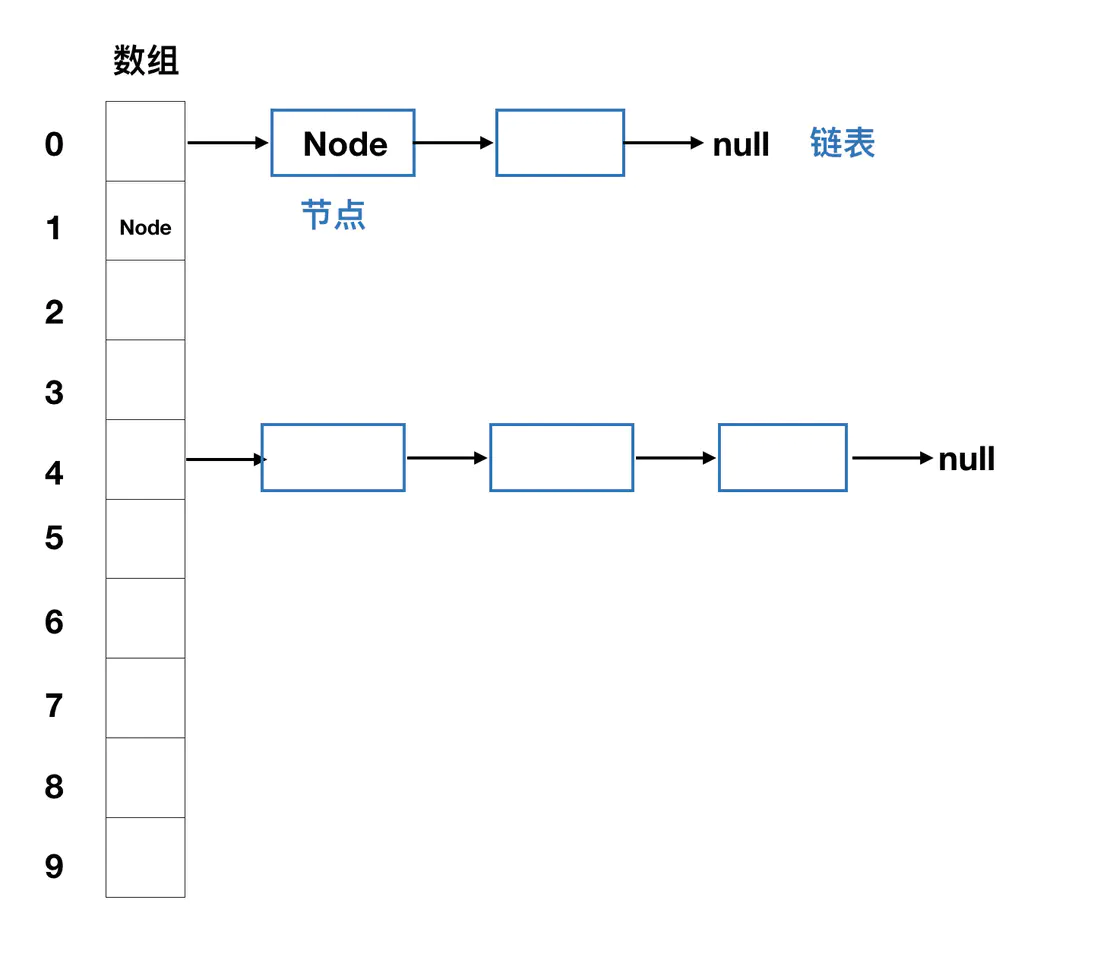
The term zipper is used to refer to a professional point as a chain address method.Simply put, it's a combination of arrays and chained lists.Each array element stores a list of chains.
We mentioned earlier that different keys may get the same address by hash operation, but only one element can be stored in an array unit. After chain address, if we encounter a key with the same hash value, we can put it in the chain table as an array element.When we retrieve the elements, we find the list by hash operation, and then find the same node as the key in the list, we can find the corresponding value of the key.
The newly added elements in JDK1.7 are always placed at the corresponding corner position of the array, whereas the node that was originally at that corner position is placed behind the new node as the next node.We can see this later by analyzing the source code.
Storage structure in JDK1.8.
For HashMap underlying layer after JDK1.8, when resolving hash conflicts, it is not simply a combination of arrays and single-chain lists, because when dealing with cases where hash values conflict a lot, the length of the chain list becomes longer and longer, when looking for the corresponding Value of the Key through the single-chain list, the time complexity reaches O(n), so after JDK1.8When a new node in the list causes the length of the list to exceed TREEIFY_THRESHOLD = 8, the original single-chain list will be converted to a red-black tree while adding elements.
Readers who are knowledgeable about data structure should know that red-black trees are binary trees that are easy to add, delete, and alter. Their time complexity for querying data is at the O(logn) level, so elements in HashMap can be manipulated more efficiently using the characteristics of red-black trees.
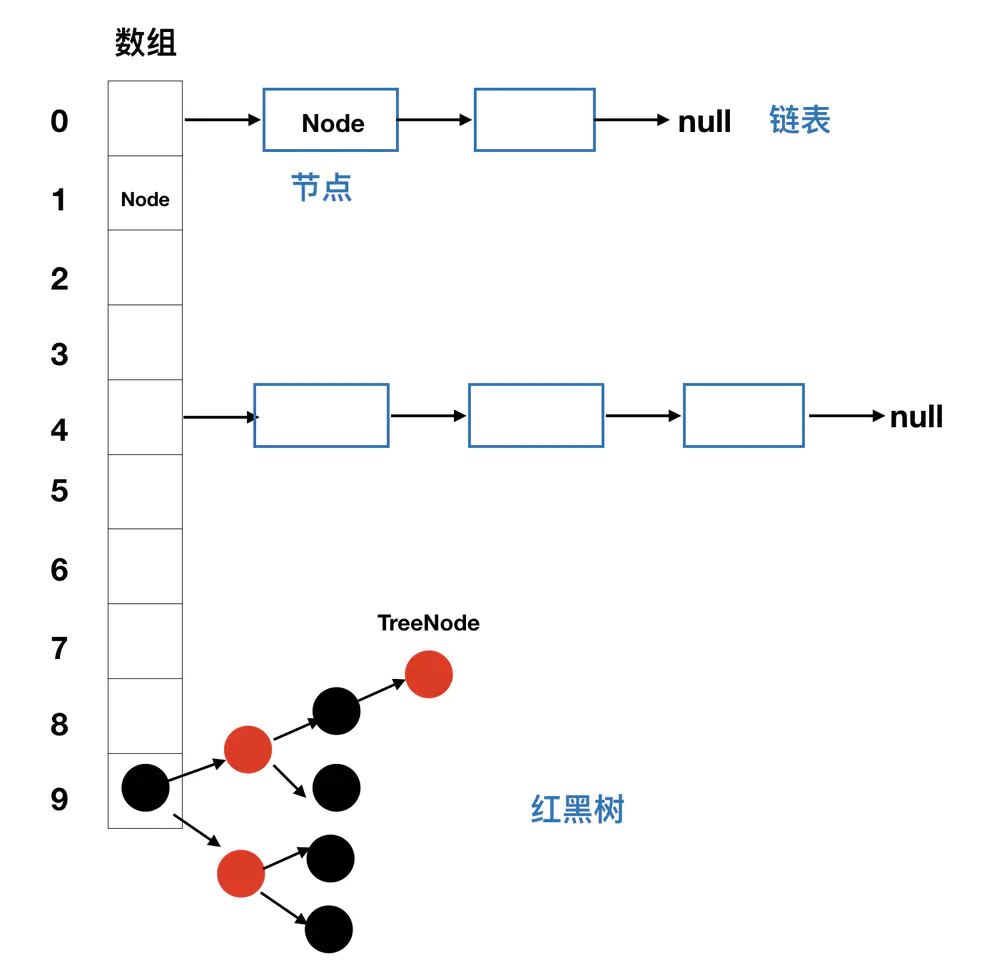
JDK1.8 optimizes the underlying storage structure of HashMap by converting the original chain table to a red-black tree to store data when a new node in the chain table causes the chain table to be longer than 8.
Some important concepts mentioned in the HashMap source code
Articles about analysis in HashMap source code generally mention several important concepts:
Important parameters
-
buckets: Use the hash bucket in HashMap's comments to graphically represent each address location in the array.Note that this is not the array itself, it is a hash bucket, and it can be called a hash table.
-
Initial capacity: This is easily understood as the initial number of hash buckets in the hash table.If we do not modify this capacity value through the construction method, the default is DEFAULT_INITIAL_CAPACITY = 1< 4, or 16.It is worth noting that the capacity of HashMap is always in the form of 2^n to ensure the efficiency of adding and finding HashMaps.
-
Load factor: Load factor is the maximum number of measures a hash table is allowed to obtain before its capacity automatically increases.When the number of entries in a hash table exceeds the product of the load factor and the current capacity, the Hash list is remapped (that is, rebuilding the internal data structure) to approximately double the number of hash buckets previously created.The default load factor (0.75) provides a good trade-off between time and space costs.Loading factors that are too large can easily lead to long chains, small load factors, and frequent expansion.Don't try to change this default easily.
-
Threshold for expansion: In fact, the threshold for expansion has already been mentioned when referring to the load factor. Threshold for expansion = hash table capacity * load factor.The total number of key-value pairs of a hash table = the sum of all the list nodes in all the hash buckets. The expansion threshold compares the number of key-value pairs rather than how many positions in the hash table's array are occupied.
-
Tree threshold (TREEIFY_THRESHOLD): This parameter concept was added after JDK1.8, meaning that when the number of nodes in a hash bucket is greater than that value (default is 8), it will be converted to a red-black tree row storage structure.
-
Untree threshold (UNTREEIFY_THRESHOLD): Corresponds to the tree threshold, indicating that when the number of nodes in a hash bucket that has been converted to a number storage structure is less than that value (default is 6), it will be re-stored as a single-chain table.This may be due to node deletion or expansion.
-
Minimum tree capacity (MIN_TREEIFY_CAPACITY): As mentioned above, we only know that when the number of nodes in the chain table exceeds 8, it will be converted to tree storage. In fact, another requirement for conversion is that the number of hash tables exceeds the minimum tree capacity requirement (default requirement is 64), and this value cannot be less than 4 * to avoid conflict between expansion and tree selection.TREEIFY_THRESHOLD; preferred expansion before meeting this requirement.Expansion can change the length of single-chain lists because of capacity changes.
Corresponding to these concepts, there are several constant bright quantities in HashMap, and since the above description is more detailed, only a few variable declarations are listed below:
/*Default initial capacity*/ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 /*Maximum storage capacity*/ static final int MAXIMUM_CAPACITY = 1 << 30; /*Default Load Factor*/ static final float DEFAULT_LOAD_FACTOR = 0.75f; /*Default Treing Threshold*/ static final int TREEIFY_THRESHOLD = 8; /*Default non-tree threshold*/ static final int UNTREEIFY_THRESHOLD = 6; /*Default minimum tree capacity*/ static final int MIN_TREEIFY_CAPACITY = 64; //Copy Code
There are also several global variables:
// Expansion Threshold=Capacity x Loading Factor int threshold; //An array storing a hash bucket containing a single-chain list or a red-black tree, which must be 2^n in length transient Node<K,V>[] table; // Number of key-value pairs stored in HashMap Note that this is the number of key-value pairs, not the length of the array transient int size; //Set sets for all key-value pairs are distinct from table s and can be obtained by calling entrySet() transient Set<Map.Entry<K,V>> entrySet; //Fast-fail mechanism when operands are recorded for multithreaded operations transient int modCount; //Copy Code
Basic storage unit
HashMap has only one storage unit for Entry in JDK 1.7, whereas in JDK 1.8 there is an additional storage unit for Red-Black Tree, and Entry has been renamed Node accordingly.Let's first look at the representation of single-chain table nodes:
/** * The internal class Node implements the internal interface Map.Entry<K,V>of the base class * */ static class Node<K,V> implements Map.Entry<K,V> { //This value is at the array index position final int hash; //Key of node final K key; //Value of node V value; //Next Node in Single Chain List Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } //The hashCode value of the node is either obtained by the hash value of the key or by the hash value of the value, and is not found to be useful in the source code. public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } //Update the Value value corresponding to the same key public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } //equals method, key values are the same before nodes are the same public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } } //Copy Code
For JDK1.8's new black and red tree node, there is no description here. Interested friends can view it HashMap Added Red-Black Tree Structure after JDK 1.8 This article takes a look at how JDK1.8 works with red and black trees.
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; TreeNode(int hash, K key, V val, Node<K,V> next) { super(hash, key, val, next); } ········· } //Copy Code
HashMap construction method
There are three HashMap construction methods:
- You can specify the constructor for the desired initial capacity and load factor, and with these two values we can calculate the threshold load factor mentioned above.It is not stipulated that the load factor should not be less than 0 and not greater than 1, but not equal to infinity.
You might wonder that Float.isNaN() is actually an abbreviation for not a number. We know that we throw an exception when we run 1/0, but we won't throw an exception if our divisor is specified as 1/0.0f of a floating point number.The result calculated by the calculator can be treated as an extreme value, that is, infinity, which is not a number, so 1/0.0f returns Infinity infinity, and Float.isNaN() returns true.
public HashMap(int initialCapacity, float loadFactor) { // Specifying an expected initial capacity of less than 0 will throw an illegal parameter exception if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); // Expecting an initial capacity not to be greater than the maximum of 2^30 Actually we won't use that much capacity either if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // Load factor must be greater than 0 and cannot be infinite if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor;//Initialize global load factor variable this.threshold = tableSizeFor(initialCapacity);//Calculating expansion threshold based on initial capacity } //Copy Code
Huh?Didn't you say the expansion threshold = hash table capacity * load factor?Why use the method below?As we mentioned earlier, the initial Capacity parameter only expects capacity. I don't know you find that Node<K, V>[] table is not initialized without our constructor. In fact, specifying the capacity of a hash table is always the first time an element is added, which is different from the mechanism of ArrayList.We'll see the code when we talk about the expansion mechanism.
//Returns an extension threshold >= cap based on the expected capacity, and the threshold must be 2^n static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; //After the sum and sum displacement operations above, n ends up being 1 for each of you //The final result + 1 also guarantees a return of 2^n return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } //Copy Code
- Constructor specifying only initial capacity
This is simpler, passing the specified expected initial capacity and default load factor to two parameter construction methods.That's not to be repeated here.
public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } //Copy Code
- Parameterless constructor
This is also one of our most common constructors, which initializes the load factor to the default value without invoking other construction methods. As we mentioned earlier, the size of the hash table and other parameters are initialized to the default value in the first call to the expansion function.
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted } //Copy Code
- Construct parameters passed into a Map collection
This method is more cumbersome to interpret because it involves adding elements and expanding these two important methods when initializing.Hang it up here first, and then we'll finish the expansion mechanism and come back.
public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); } //Copy Code
How HashMap determines where to add elements
Before analyzing how HashMap adds elements, we need to understand how to determine the location of elements in HashMap.We know that the bottom layer of HashMap is a hash table, which relies on hash values to determine where elements are stored.HashMap does not use the same hash method in JDK 1.7 and JDK 1.8.Now let's see
Implementation of hash method in JDK 1.7:
A conceptual perturbation function is proposed here. We know that the location where key-value pairs are stored in Map text is determined by the hash value of the key, but the return value of the hashCode function of the key does not necessarily meet the requirements of the length of the hash table, so one step of perturbation processing is required for the hash value of the key before storing the element.Here is our perturbation function in JDK1.7:
//4th bit operation + 5th exclusive OR operation //This algorithm prevents hash conflicts when low bits are unchanged and high bits are changed static final int hash(Object k) { int h = 0; h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } //Copy Code
Implementation of hash function in JDK1.8
This hash function is optimized again in JDK1.8, which shifts the return value of the key's hashCode method to the right by 16 bits, i.e. discarding the low 16 bits and the high 16 bits are all zero, and then doing the exclusive OR operation on the hashCode return value, i.e., the high 16 bits and the low 16 bits. This way, when the length of the array table is small, it can also be guaranteed that both high and low Bits will participate in the hash calculation.It also reduces the number of disturbance handling operations from 4 Bit operations + 5 exclusive OR operations to 1 Bit operation + 1 exclusive OR operation.
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } //Copy Code
The perturbation function described above only yields the appropriate hash value, but the angular scales in the Node[] array have not yet been determined. There is a function in JDK1.7, which JDK1.8 does not, but merely places this operation in the put function.Let's look at this function implementation:
static int indexFor(int h, int length) { return h & (length-1); // Modular operation } //Copy Code
In order for the hash value to correspond to the position in the existing array, we have mentioned in the previous article that a method is the modular operation, hash% length, to get the result as the corner position.But HashMap is so powerful that even this step of modularization is optimized.We need to know that a computer can operate faster on binary than 10, modeled as 10, and bit and operation are more efficient.
We know that the length of the underlying array in HashMap is always 2^n, and the conversion to binary is always 1000 or more than 0 behind 1.In this case, a number modular to 2^n is equivalent to a number and 2^n-1 bits and operations.The H & (length-1) operation replaces the length modulus in JDK.Let's look at a specific example from the picture:

Picture from: https://tech.meituan.com/java-hashmap.html hacking.
Summary
From the analysis above, we can draw the following conclusions:
- HashMap further processes the hashCode return value of the key before storing the element. In 1.7, the perturbation function uses 4 bit operations + 5 exclusive OR operations, and in 1.8 it decreases to 1 bit operation + 1 exclusive OR operation
- The hash and hash table array length-1 bits and operations after the perturbation process result in the hash bucket label positions stored by the final element.
Additional elements of HashMap
Knock on the blackboard. Here's the point.Understanding the HashMap source requires understanding both the structure of the stored data and how elements are added.Let's look at the put(K key, V value) function.
// You can see that the specific add behavior occurs in the putVal method public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } //Copy Code
With a good understanding of the first three putVal parameters, the fourth parameter, onlyIfAbsent, indicates that elements are replaced only when the corresponding key position is empty, typically passing false, the new method public V putIfAbsent(K key, V value) passing true in JDK1.8, and the fifth parameter evict if false.That means it was called at initialization:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //Expansion is required if table = null is the first added element if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;// n represents the length of the expanded array // I = (n - 1) & hash is the calculation of array corners where elements are stored i n the map // Assign directly to the index position in the corresponding array if no elements have hash collisions if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else {// hash collision occurred Node<K,V> e; K k; //Override elements if there are already elements in the corresponding location and key s are the same if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode)//If you add a node that is already a red-black tree, you need to change to a node in a red-black tree e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else {// hash values compute the same array index, but different key s, //loop through the entire single-chain table for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) {//Traverse to tail // Create a new node and stitch it to the end of the list p.next = newNode(hash, key, value, null); // If the bitCount after adding is greater than or equal to the tree threshold, the hash bucket tree operation is performed if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //If the key of a node in the list is found to be the same as the key of the element being inserted during traversal, the node referred to by e is the node that needs to replace the Value and ends the loop if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //Move Pointer p = e; } } //If e!=null after the loop is finished, it means the node Value referred to by e needs to be replaced if (e != null) { // existing mapping for key V oldValue = e.value//Save original Value as return value // onlyIfAbsent is usually false so it replaces the original Value if (!onlyIfAbsent || oldValue == null) e.value = value; //This method is an empty implementation in HashMap and has a relationship in LinkedHashMap afterNodeAccess(e); return oldValue; } } //Operand increase ++modCount; //If the size is greater than the expansion threshold, the expansion is required if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } //Copy Code
Due to the complexity of the design logic in adding elements, here is a diagram to illustrate and understand
Picture from: https://tech.meituan.com/java-hashmap.html
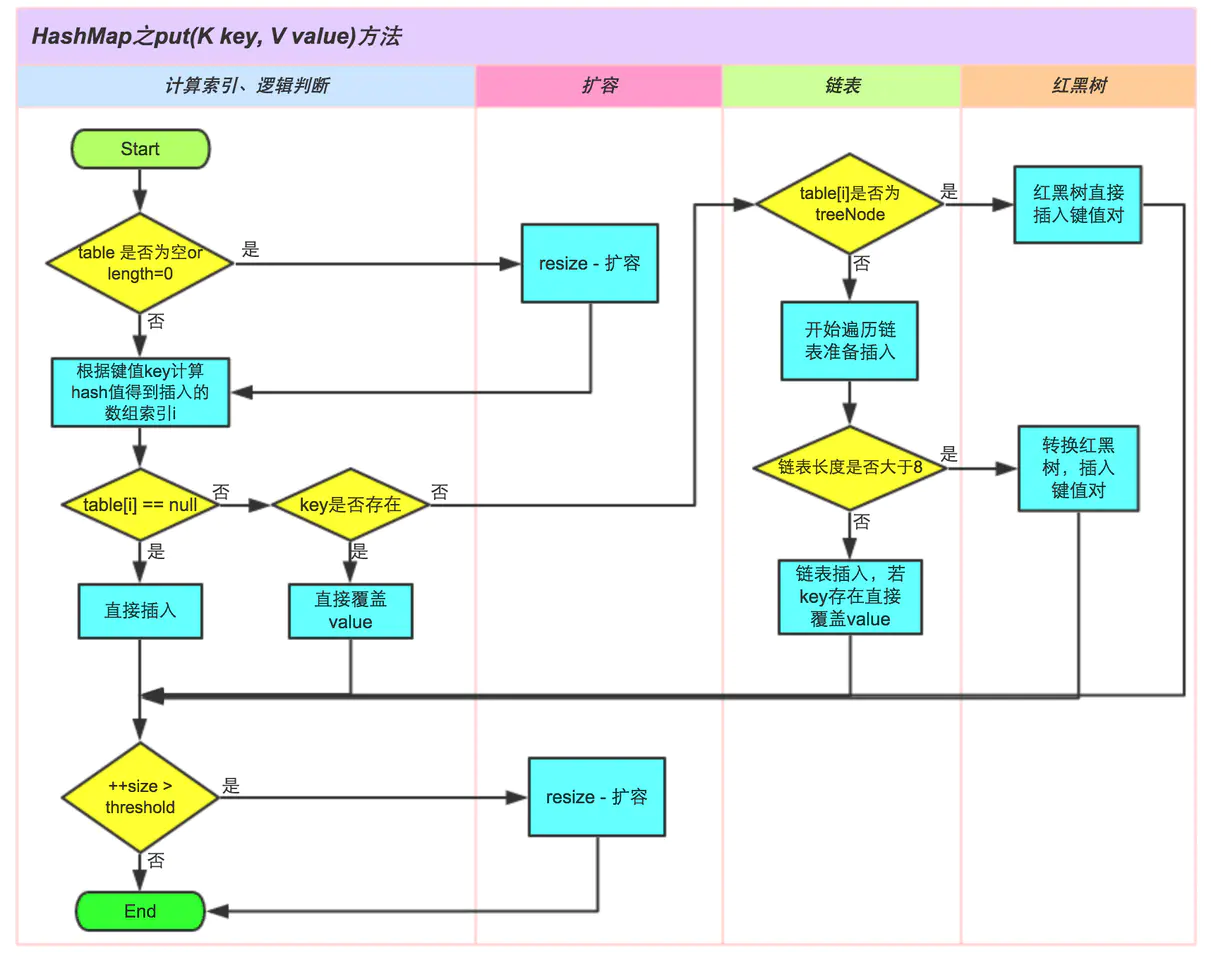
Add element process:
- If the Node[] table table is null, it means that the element was added for the first time. As mentioned in the constructor, the timely constructor specifies the expected initial capacity and is empty the first time the element is added.This is when the first capacity expansion process is required.
- Calculates the index position of the corresponding key-value pair i n the table table table, obtained by I = (n - 1) & hash.
- Determines if an element exists at the index position and inserts it directly into the array if no element exists.If there are elements and the keys are the same, then the value is overridden. This means that to store the elements correctly, you must override the equals method of the key as required by your business. We also mentioned the importance of this method in the previous article.
- If the keys at the index locations are different, you need to traverse the single-chain table, save the index and replace the Value if there are nodes that are the same as the key, and insert a new node at the end of the single-chain table if there are no same nodes.Unlike 1.7, where a new 1.7 node is always in the array index position, the previous element is stitched to the end of the new node as the next node.
- If the length of the chain table after inserting a node is greater than the tree threshold, the single-chain table needs to be converted to a red-black tree.
- After successfully inserting a node, determine if the number of key-value pairs is greater than the expansion threshold, and if it is greater, it needs to be expanded again.The whole insertion process is over.
Extension process for HashMap
When describing HashMap's putVal method above, the expansion function has been mentioned several times, and it is also the most important thing for us to understand HashMap's source code.So tap the blackboard again~
final Node<K,V>[] resize() { // oldTab points to the old table table table Node<K,V>[] oldTab = table; // oldCap represents the array length of the table table table before expansion, and oldTab is null when it first adds elements int oldCap = (oldTab == null) ? 0 : oldTab.length; // Old Expansion Threshold int oldThr = threshold; // Initialize new thresholds and capacities int newCap, newThr = 0; // If oldCap > 0, the new capacity will be doubled and the expansion threshold will be doubled. if (oldCap > 0) { // Setting the expansion threshold to Integer.MAX_VALUE does not mean that new elements cannot be installed, only that the array length will not change if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; }//When the new capacity is doubled, the expansion threshold will be doubled. else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } //oldThr is not empty, which means we specified the load factor and calculated it using a parameterized construction method //The initial initial threshold assigns the expansion threshold to the initial capacity, which is no longer the desired capacity. //But >=Specified Expected Capacity else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // Empty parameter construction takes you here to initialize capacity, and expansion thresholds are 16 and 12, respectively. newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } //If the new expansion threshold is 0, the current table is empty, but there are thresholds if (newThr == 0) { //Calculate new expansion threshold float ft = (float)newCap * loadFactor; // Assign to newThr if the new capacity is not greater than 2^30 and ft is not greater than 2^30 //Otherwise, use Integer.MAX_VALUE newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } //Update Global Expansion Threshold threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) //Array to create a new hash table with new capacity Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; //If the old array is not empty it will be reinserted or returned directly if (oldTab != null) { //Recalculate node positions by traversing a chain table or a red-black tree at each location in the old array and insert a new array for (int j = 0; j < oldCap; ++j) { Node<K,V> e;//Used to store the corresponding array location chain header node //If there are elements in the current array position if ((e = oldTab[j]) != null) { // Release the corresponding space in the original array oldTab[j] = null; // If the list has only one node, //Then use the new array length to calculate the corner label of the node in the new array and insert it if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode)//If the current node is a red-black tree, you need to further determine where the node in the tree is in the new array. ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order //Because expansion is twice capacity, //Each node in the original list may now be stored in the original subscript, the low bit. //Or the expanded subscript, the high bit //Head and End Nodes of Low Chain List Node<K,V> loHead = null, loTail = null; //Head and tail nodes of high-bit chain list Node<K,V> hiHead = null, hiTail = null; Node<K,V> next;//Used to store nodes in the original chain table do { next = e.next; // With hash value-old capacity, the hash value can be modeled. //Is it greater than or equal to oldCap or less than oldCap, //Equal to 0 means less than oldCap and should be stored in low position. //Otherwise, store it in a high position (with picture instructions later) if ((e.hash & oldCap) == 0) { //Assigning values to the pointer of the head and end nodes if (loTail == null) loHead = e; else loTail.next = e; loTail = e; }//High bits are the same logic else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; }//Loop until end of list } while ((e = next) != null); //Store the low-level list in the original index. if (loTail != null) { loTail.next = null; newTab[j] = loHead; } //Store the high-order list at the new index if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } return newTab; } //Copy Code
It is believed that you will have a better understanding of the expansion mechanism after you see the whole function of expansion. It is divided into two parts as a whole: 1. Find the size of the expanded array and the new expansion threshold; 2. Copy the original hash table into the new hash table.
I didn't say that in the first part, but in the second part I was a bit confused, but it's always easier to step on a giant's shoulder. The Big Brothers of America have written some source analysis articles about HashMap, which has helped me a lot.I'll put out a reference link at the end of the article.Here's my understanding:
Unlike JDK 1.7, which recalculates the location of each node in the new hash table, JDK 1.8 can determine the location of the node in the original chain table in the new hash table by (e.hash & oldCap) == 0 or not.Why can new locations be created so efficiently?
Since capacity doubles, each node on the original chain table may store the new hash table in its original subscript position, or the expanded in-situ offset is oldCap's position. Below is an example picture and description from https://tech.meituan.com/java-hashmap.html:
Figure (a) shows an example of key1 and key2 determining the index position before expansion, and figure (b) shows an example of key1 and key2 determining the index position after expansion, where hash1 is the result of a hash and high-bit operation corresponding to key1.

After the element recalculates hash, because n becomes twice as large, the mask range of n-1 is 1 bit more high (red), so the new index changes as follows:
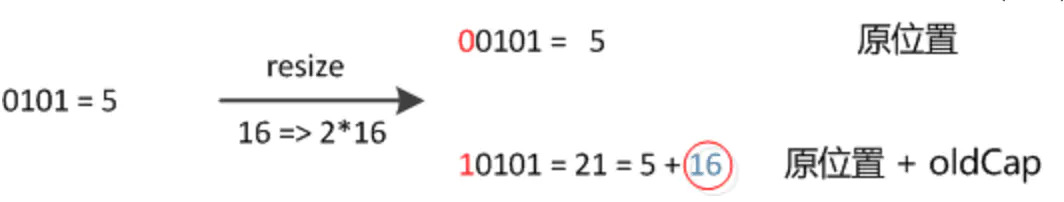
So after expanding in JDK1.8, just look to see if the new bit added to the original hash value is 1 or 0. If it is 0, the index does not change. If it is 1, the index becomes "original index + oldCap"
It is also important to note that when HashMap is expanded at 1.7, the order of nodes in the chain table is inverted, which is not the case at 1.8.
Other ways HashMap adds elements
The top buries a hole when you use the constructor:
public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); } //Copy Code
When the constructor builds HashMap, in this method, HashMap is constructed by putMapEntries, a method that adds elements in batch, instead of invoking other construction methods, except that the default load factor is assigned.This method is private and the real bulk-added method is putAll
public void putAll(Map<? extends K, ? extends V> m) { putMapEntries(m, true); } //Copy Code
//The same second parameter indicates whether the table was first created final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) { int s = m.size(); if (s > 0) { //Initialization parameter expansion threshold if hash table is empty if (table == null) { // pre-size float ft = ((float)s / loadFactor) + 1.0F; int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY); if (t > threshold) threshold = tableSizeFor(t); } else if (s > threshold)//The construction method does not calculate the threshold, which defaults to 0, so it takes the expansion function resize(); //Add map key-value pairs from parameters to HashMap once for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) { K key = e.getKey(); V value = e.getValue(); putVal(hash(key), key, value, false, evict); } } } //Copy Code
JDK1.8 also added an add method that calls putVal and passes true for the fourth parameter, meaning that only if the element at the location of the corresponding key in the hash table is empty, it will return the Value corresponding to the original key.
@Override public V putIfAbsent(K key, V value) { return putVal(hash(key), key, value, true, true); } //Copy Code
HashMap Query Elements
Now that you have analyzed the put function, let's look at the get function. Of course, the get method is much easier when the put function calculates the key-value pairs that pave the way for the index method analysis of the location in the hash table.
- Get the corresponding Value based on the key of the key-value pair
public V get(Object key) { Node<K,V> e; //Find the corresponding Value for the key by getNode If it is not found, or if the result is null, it will return null otherwise it will return the corresponding Value return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; //The corresponding chain list or red-black tree is now found based on the hash value of the key if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // Return directly if the first node is if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; //If the corresponding location is a red-black tree, call the red-black tree method to find the node if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); //Traverse the single-chain table to find the corresponding key and Value do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; } //Copy Code
- JDK 1.8 adds a get method that returns the specified default Value when looking for the key corresponding Value
@Override public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? defaultValue : e.value; } //Copy Code
Deletion of HashMap
HashMap does not have a set method, and if you want to modify the Value of the corresponding key map, you only need to call the put method again.Let's see how to remove the corresponding node in HashMap:
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } //Copy Code
@Override public boolean remove(Object key, Object value) { //value is passed in here and matchValue is true return removeNode(hash(key), key, value, true, true) != null; } //Copy Code
There are two parameters that need our attention:
- matchValue If this value is true, it means that a node is deleted only if the Value is the same as the third parameter Value
- movable is a parameter that uses true to denote the deletion of a node in a red-black tree and the number of other nodes.
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; //Determine if the hash table is empty and if there are elements in a position with a length greater than 0 if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { // Node is used to store the nodes to be removed, e represents the key value of the next node k, v for each node Node<K,V> node = null, e; K k; V v; //If the first node is the direct assignment we are looking for to the node if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { // Traverse the red-black tree to find the corresponding node if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { //Traverse the corresponding list to find the corresponding node do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } // If a node is found // !matchValue does not delete nodes // (v = node.value) == value || (value != null && value.equals(v))) Whether the node values are the same, if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { //Delete Node if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; } //Copy Code
Iterator for HashMap
We all know that Map and Set have multiple iterations. We won't expand on Map iteration here because we're going to analyze the source code of the iterator, so here's a way to use it:
public void test(){ Map<String, Integer> map = new HashMap<>(); ... Set<Map.Entry<String, Integer>> entrySet = map.entrySet(); //By iterator: first get the Iterator of the key-value pair (Entry), then loop through it Iterator iter1 = entrySet.iterator(); while (iter1.hasNext()) { // When traversing, you need to get entry first, then key, value respectively Map.Entry entry = (Map.Entry) iter1.next(); System.out.print((String) entry.getKey()); System.out.println((Integer) entry.getValue()); } } //Copy Code
Using the traversal described above, we can use map.entrySet() to get the entrySet we mentioned earlier
public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; return (es = entrySet) == null ? (entrySet = new EntrySet()) : es; } //Copy Code
// Let's see that EntrySet is a set-stored element that is a key-value pair for Map final class EntrySet extends AbstractSet<Map.Entry<K,V>> { // The number of key-value pairs that size puts back in Map public final int size() { return size; } //Clear key-value pairs public final void clear() { HashMap.this.clear(); } // Get Iterator public final Iterator<Map.Entry<K,V>> iterator() { return new EntryIterator(); } //Getting a node corresponding to a corresponding key by the getNode method must be passed in here // Map.Entry key-value pair type object otherwise returns false directly public final boolean contains(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Node<K,V> candidate = getNode(hash(key), key); return candidate != null && candidate.equals(e); } // Drop Oop deletes nodes using the removeNode method described earlier public final boolean remove(Object o) { if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Object value = e.getValue(); return removeNode(hash(key), key, value, true, true) != null; } return false; } ... } //Copy Code
//EntryIterator inherits from HashIterator final class EntryIterator extends HashIterator implements Iterator<Map.Entry<K,V>> { // Perhaps this is because the habit of using the adapter has added this next method public final Map.Entry<K,V> next() { return nextNode(); } } abstract class HashIterator { Node<K,V> next; // next entry to return Node<K,V> current; // current entry int expectedModCount; // for fast-fail int index; // current slot HashIterator() { //Initialization operand Fast-fail expectedModCount = modCount; // Assign a hash table in Map to t Node<K,V>[] t = table; current = next = null; index = 0; //Get entry from the first non-empty index of the table if (t != null && size > 0) { // advance to first entry do {} while (index < t.length && (next = t[index++]) == null); } } public final boolean hasNext() { return next != null; } final Node<K,V> nextNode() { Node<K,V>[] t; Node<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); //If the current list node has been traversed, take the next non-null list header in the hash bucket if ((next = (current = e).next) == null && (t = table) != null) { do {} while (index < t.length && (next = t[index++]) == null); } return e; } //The call to the removeNode function is not covered here public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; removeNode(hash(key), key, null, false, false); expectedModCount = modCount; } } //Copy Code
In addition to EntryIterator, KeyIterator and ValueIterator also inherit HashIterator, which represents three different iterator traversals of HashMap.
final class KeyIterator extends HashIterator implements Iterator<K> { public final K next() { return nextNode().key; } } final class ValueIterator extends HashIterator implements Iterator<V> { public final V next() { return nextNode().value; } } //Copy Code
You can see that either iterator traverses the table table table to get the next node to traverse, which can be interpreted as a depth-first traversal, i.e., traversing the chain table node (or the red-black tree) first, then traversing other array locations.
Differences between HashTable s
When interviewing, the interviewer always asks HashTables after they finish HashMap. HashTables are actually an older class.Looking at the source code of HashTable, you can see the following differences:
-
HashMap is thread-insecure, HashTable is thread-safe.
-
HashMap allows keys and Vale s to be null, but only one key is allowed to be null, and this element is stored in the hash table 0 corner position.HashTable does not allow key, value to be null
-
HashMap uses the hash(Object key) perturbation function to perturb the hashCode of the key as a hash value.HashTable is a hash value that uses the hashCode() return value of the key directly.
-
HashMap has a default capacity of 2^4 and must have a capacity of 2^n; HashTable has a default capacity of 11, not necessarily 2^n
-
HashTable takes the hash bucket subscript directly by modular operation, and the new capacity is double+1 when expanding capacity.HashMap doubles its capacity when expanding, and the subscript to the hash bucket uses the &operation instead of the modulus.
Reference resources
- JDK 1.7 & 1.8 HashMap & HashTable Source
- Meituan Technical Team Blog: Recognition of HashMap in the Java 8 Series
- Zhang Xutong, the American League leader: Interview Requirements: HashMap Source Parsing (JDK8)
- Zhang Xuxin CSDN Blog Java Collection in-depth understanding (16): Source interpretation of the main features and key methods of HashMap
- Carson_Ho CSDN Blog Java Source Analysis: A Major Update on HashMap 1.8
- HashMap Source Detailed Analysis (JDK1.8)
- Collection Fan@HashMap Yiwentong (version 1.7)
Last
The process of writing HashMap source analysis is arguably less than a level of ArrayList or LinkedList source code.Personal ability is limited, so in the process of learning, I have consulted a lot of analysis from my predecessors, and learned a lot.This is very useful, and after this analysis I feel that my answers to the HashMap interview questions in the interview are much stronger than before.Interview questions about HashMap Collection Fan@HashMap Yiwentong (version 1.7) A more comprehensive summary at the end of this article.Additionally, multiple threads in HashMap can cause looping chains, which you can refer to Recognition of HashMap in the Java 8 Series Very good writing.You can check the original blog.