HashTable Source Analysis
For more resources and tutorials, please pay attention to the Public Number: Non-subject classes.
If you think I can write, please give me a compliment. Thank you, your encouragement is the power of my creation.
####1. Preface
Hashtable is an old-fashioned collection class that was born as early as JDK 1.0
####1.1. Summary
In the first chapter of the collection series, we learned that the implementation classes of Map are HashMap, LinkedHashMap, TreeMap, IdentityHashMap, WeakHashMap, HashTable, Properties, and so on.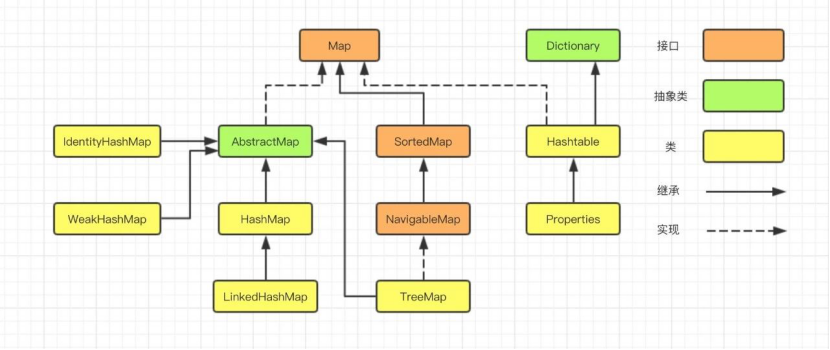
####1.2. Introduction
Hashtable is an old-fashioned collection class, which was born as early as JDK 1.0. HashMap was born as JDK 1.2. In implementation, HashMap absorbs a lot of Hashtable's ideas. Although the underlying data structure of Hashtable and Hashtable is array + chain table structure, which has the characteristics of fast query, insertion and deletion, there are many differences between them.
Open the source code for Hashtable to see that Hashtable inherits from Dictionary and HashMap inherits from AbstractMap.
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
.....
}HashMap inherits from AbstractMap, and the HashMap class is defined as follows:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
.....
}The bottom level of Hashtable and HashMap is to store the data in arrays, and hash algorithms are the main ones when storing the data to calculate array subscripts via key, so the possibility of hash conflicts may arise.
It is common to say that different key s may produce the same array subscript when calculating. How do you put two objects in an array at this time?
There are two ways to resolve hash conflicts, one is by opening the address (when a hash conflict occurs, continue to look for hash values that do not conflict) and the other is by zipping (by placing conflicting elements in the list).
Java Hashtable uses the second method, zipper method!
Thus, when different key s obtain the same array subscript through a series of hash algorithm calculations, the object is placed in an array container, and then stored as a one-way chain table in the same array subscript container, like a chain, on a node, as shown below: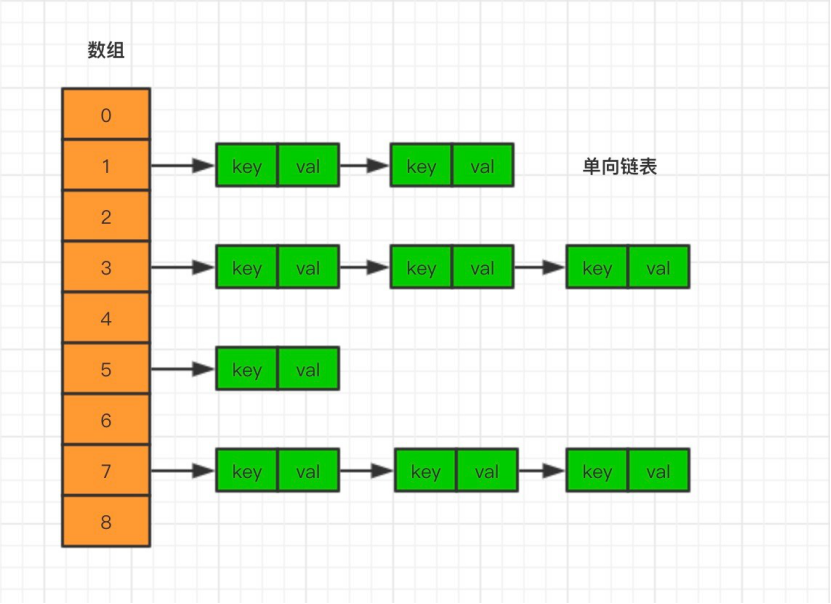
Like HashMap, Hashtable includes five member variables: /** Array of Entry objects*/ private transient Entry[] table; /**Number of Entry objects in Hashtable*/ private transient int count; /**Threshold for Hashtable expansion*/ private int threshold; /** Load factor, default 0.75*/ private float loadFactor; /**Record the number of modifications*/ private transient int modCount = 0;
Variables have the following meanings:
table: Represents an array of linked lists made up of Entry objects. Entry is a one-way linked list. The key-value pairs of hash tables are stored in the Entry array.
count: Represents the size of a Hashtable used to record the number of key-value pairs saved;
_threshold: A threshold representing the Hashtable value, which is used to determine whether the capacity of Hashtable needs to be adjusted. The threshold is equal to the capacity*load factor;
Load Factor: Represents a load factor, defaulting to 0.75;
modCount: Represents the number of Hashtable modifications recorded to enable fast fail throw exception handling;
Next, look at Entry, an internal class that stores linked list data and implements the Map.Entry interface, essentially a map (key-value pair) with the following source code:
private static class Entry<K,V> implements Map.Entry<K,V> {
/**hash value*/
final int hash;
/**key Representation key*/
final K key;
/**value Representation value*/
V value;
/**Next element of node*/
Entry<K,V> next;
......
}Next we'll look at the Hashtable initialization process with the following core sources:
public Hashtable() {
this(11, 0.75f);
}this calls its own construction method with the following core sources:
public Hashtable(int initialCapacity, float loadFactor) {
.....
//The default initial size is 11
//And calculates the threshold for expansion
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}You can see that the default initial size of the HashTable is 11. If you initialize a given capacity size, the HashTable will use the size you give it directly.
The threshold for expansion is equal to initialCapacity * loadFactor. Let's look at HashTable expansion by:
protected void rehash() {
int oldCapacity = table.length;
//Bitwise the length of the old array, then + 1
//Equivalent to 2n+1 expansion at a time
int newCapacity = (oldCapacity << 1) + 1;
//Omit some code...
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
}You can see that HashTable expands to the original 2n+1 at a time.
Let's take a look at HashMap again. If you execute the default construction method, it initializes the size at the expansion step, with the core source code as follows:
final Node<K,V>[] resize() {
int newCap = 0;
//Part of the code is omitted...
newCap = DEFAULT_INITIAL_CAPACITY;//Default capacity is 16
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
}You can see that the default initialization size of HashMap is 16. Let's take a look at the HashMap extension method with the following core sources:
final Node<K,V>[] resize() {
//Get the length of the old array
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int newCap = 0;
//Part of the code is omitted...
//When expanding capacity, capacity is a multiple of 2
newCap = oldCap << 1;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
}You can see that HashMap has twice as many expanded arrays as it used to.
That is, HashTable tries to use prime and odd numbers as its capacity, whereas HashMap always uses a power of 2 as its capacity.
We know that simple modular hashing results are more uniform when the hash table size is a prime number, so the hash table size selection for HashTable seems clearer from this point of view alone.
Hashtable's hash algorithm, the core code is as follows:
//Calculate key.hashCode() directly int hash = key.hashCode(); //Calculate the array by dividing the remainder to store Subscripts // 0x7FFFFFFF is the binary representation of the largest int number int index = (hash & 0x7FFFFFFF) % tab.length;
From the source part, we can see that the key of HashTable cannot be empty, otherwise the null pointer error is reported!
On the other hand, we also know that if the modulus is a power of 2 in the modular calculation, we can use the bitwise operation directly to get the result, which is much more efficient than dividing.HashMap is much more efficient at calculating array subscripts, but it also introduces the problem of uneven hash distribution. HashMap has made some changes to hash algorithm to solve this problem, let's see.
HashMap hash algorithm, the core code is as follows:
/**Get hash value method*/
static final int hash(Object key) {
int h;
// h = key.hashCode() takes the hashCode value for the first step (jdk1.7)
// H ^ (h >>>> 16) is the second high-bit participation operation (jdk1.7)
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//jdk1.8
}
/**Get Array Subscript Method*/
static int indexFor(int h, int length) {
//Source for jdk1.7, jdk1.8 does not have this method, but the implementation works the same way
return h & (length-1); //Step 3 Modular Operation
}
HashMap uses a power of 2, so there is no division required in modulo operations, just bits and operations.However, due to the increased hash conflict introduced by HashMap, after calling the object's hashCode method, HashMap does some high-bit operations, the second step, to scatter the data and make the hash results more even.
####1.3. Introduction to common methods
#####1.3.1.put method
The put method adds the specified key, value pair to the map.
The put flowchart is as follows: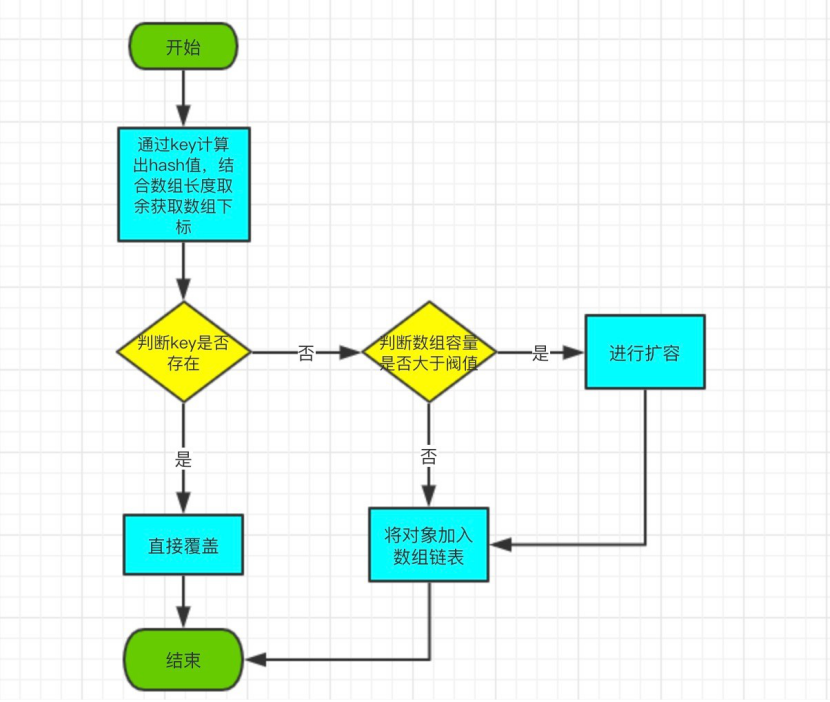
Open HashTable's put method with the following source code:
public synchronized V put(K key, V value) {
//When the value is empty, throw an exception!
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
//Store subscripts by key calculation
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//Loop through the list of arrays
//Override if there is the same key and hash
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//Add to Array Chain List
addEntry(hash, key, value, index);
return null;
}The addEntry method in the put method has the following source code:
private void addEntry(int hash, K key, V value, int index) {
//Number of New Modifications
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
//Array capacity is larger than expansion threshold for expansion
rehash();
tab = table;
//Recalculate Object Storage Subscript
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
//Store objects in an array
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
The rehash method in the addEntry method, with the following source code:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
//Each expansion to 2n+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
//Greater than maximum threshold, no more expansion
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
//Recalculate Expansion Threshold
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
//Copy data from old arrays to new arrays
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}The summary process is as follows:
_1. Calculate subscripts stored in arrays by key;
_2. If there is a key in the chain table, overwrite the old and new values directly;
_3. If there is no key in the chain list, determine if expansion is needed. If expansion is needed, expand first, and then insert data;
One notable thing is that the put method adds the synchronized keyword, so it is thread safe when synchronizing operations.
#####1.3.2.get method
The get method returns the corresponding value based on the specified key value.
The get flowchart is as follows: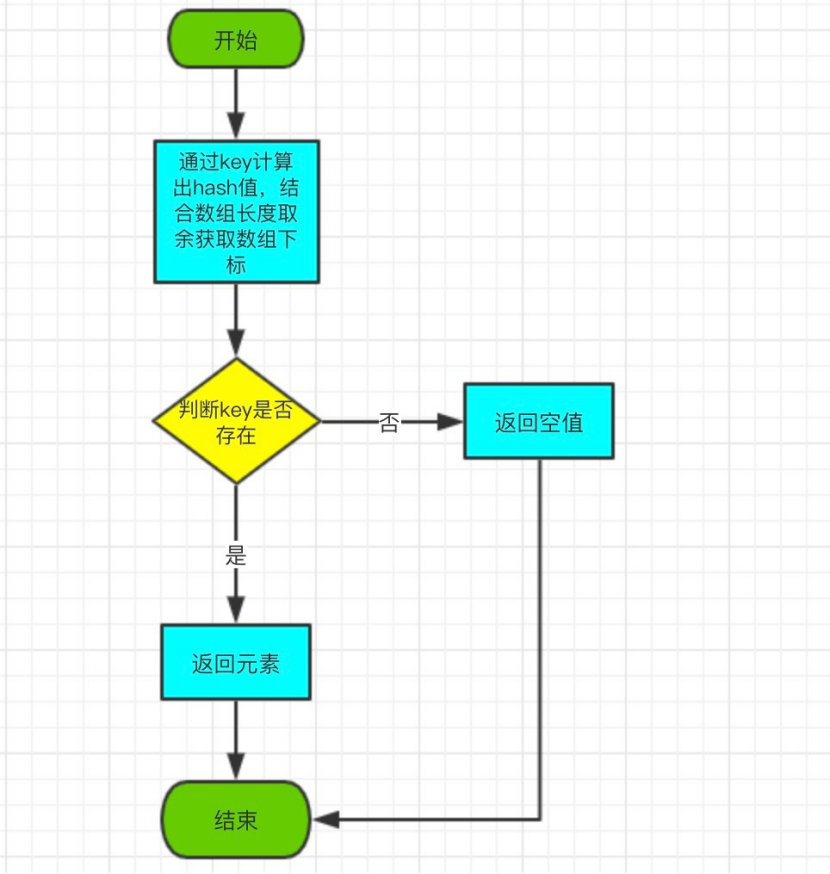
Open the get method of HashTable with the following source code:
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
//Store subscripts for nodes by key calculation
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
Similarly, one notable thing is that the get method adds the synchronized keyword, so it is thread safe when synchronizing operations.
#####1.3.3.remove method
The purpose of remove is to delete the corresponding element by key.
The remove flowchart is as follows: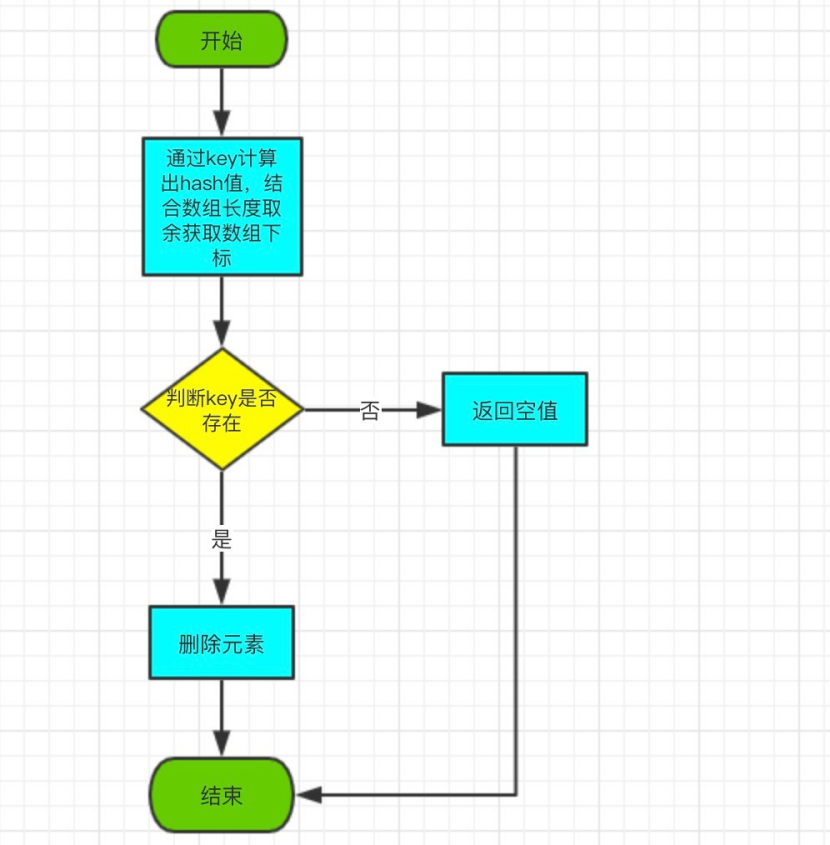
Open the remove method of HashTable with the following source code:
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
//Store subscripts for nodes by key calculation
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
Entry<K,V> e = (Entry<K,V>)tab[index];
//Loop through the list of chains, hash and key to determine if a key exists
//If present, set the change node to null directly and remove it from the list of chains
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
Similarly, one notable thing is that the remove method adds the synchronized keyword, so it is thread safe when synchronizing operations.
#####1..3.4. Summary
Summarize the connections and differences between Hashtable and HashMap as follows:
1. Although HashMap and Hashtable both implement the Map interface, Hashtable inherits from the Dictionary class, while HashMap inherits from AbstractMap;
_2, HashMap can allow one null key and any null value, but neither key nor value in HashTable can be null;
3, Hashtable's method is synchronous because a synchronized synchronized lock is added to the method, and HashMap is non-thread safe;
Although Hashtable is thread safe, it is generally not recommended because ConcurrentHashMap is a more efficient and better choice than it, as we will discuss later.
Finally, a note description from HashTable is introduced:
If a thread-safe implementation is not needed, it is recommended to use HashMap in place of Hashtable. If a thread-safe highly-concurrent implementation is desired, then it is recommended to use java.util.concurrent.ConcurrentHashMap in place of Hashtable.
Simply put, if you don't need thread security, use HashMap, and if you need thread security, use ConcurrentHashMap.
Finally, share a wave of Java resources, including a complete set of videos from beginning to development of java, and 26 projects of java. The resources are relatively large, the size is about 290g, the links are easy to fail, and the way to get them is to focus on the public number: non-class classes, let later reply: Java projects will be available, I wish you all a pleasant learning