Previously, we learned how to use ArrayList and LinkedList by analyzing the source code.However, in addition to analyzing the source code, it is always necessary to go online to look for some relevant information, stand on the shoulders of previous people, and find that there are more or less omissions in the first two articles, such as Vector, which is very similar to ArrayList, has not mentioned them yet, so this article would like to start from the interview for List-related issues, fill in the previous pit, and implement class members in the List family.Try to summarize the similarities and differences.
- Introduction to Vector and Differences from ArrayList
- Differences between ArrayList and LinkedList
- Introduction and implementation of a simple Stack class
- Differences between SynchronizedList and Vector
Introduction to Vector
Vector is a fairly old Java container class that began with JDK 1.0 and was modified in the JDK 1.2 era to implement List and Collection.Functionally, Vector and Array List are similar, both maintaining an internal array that dynamically transforms length.But their scaling mechanisms are different.Most of the source code for Vector is similar to Array List, so here's a quick look at Vector's constructor and Vector's extension mechanism.
Vector's constructor specifies the initial capacity and expansion factor of an internal array. If you do not specify an initial capacity, the default initial capacity is 10, but unlike ArrayList, which allocates 10 memory space when it is created, ArrayList generates a 10-capacity array the first time add is called.
public Vector() { this(10);//Create an array with a capacity of 10. } public Vector(int initialCapacity) { this(initialCapacity, 0); } public Vector(int initialCapacity, int capacityIncrement) { super(); if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); this.elementData = new Object[initialCapacity]; this.capacityIncrement = capacityIncrement; } // This method is added after JDK 1.2 public Vector(Collection<? extends E> c) { elementData = c.toArray();//Create an array of the same length as the parameter set elementCount = elementData.length; // c.toArray might (incorrectly) not return Object[] (see 6260652) if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, elementCount, Object[].class); } //Copy Code
For Vector's extension mechanism, we just need to look at the internal group method source:
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; // If we do not specify an expansion factor, newCapacity = 2 * oldCapacity // If we specify a capacity expansion factor, increase the specified capacity each time int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); } //Copy Code
By combining the above method with our constructor, we can see that when a Vector needs to be expanded, capacityIncrement is first judged to specify the expansion factor at the time the Vector is constructed. If specified, the capacity is expanded by the specified factor. When expanded, the new capacity is oldCapacity + capacityIncrement, and if not, capacityIncrement.By default, it doubles the original capacity, which is different from the 0.5 times length of the ArrayList.
The most important difference between Vector and ArrayList is that all methods of accessing internal arrays by Vector have synchronized, which means that Vector is thread-safe and ArrayList does not have this feature.
For Vector, in addition to for loops, advanced for loops, and iteration methods, elements() can also be called to return an Enumeration.
Enumeration is an interface with only two methods, hasMoreElements and nextElement s, that look similar to an iterator, but without an iterator's add remove, it only works on traversal.
public interface Enumeration<E> { boolean hasMoreElements(); E nextElement(); } // Vector's elements method. public Enumeration<E> elements() { return new Enumeration<E>() { int count = 0; public boolean hasMoreElements() { return count < elementCount; } public E nextElement() { synchronized (Vector.this) { if (count < elementCount) { return elementData(count++); } } throw new NoSuchElementException("Vector Enumeration"); } }; } //Copy Code
Usage method:
Vector<String> vector = new Vector<>(); vector.add("1"); vector.add("2"); vector.add("3"); Enumeration<String> elements = vector.elements(); while (elements.hasMoreElements()){ System.out.print(elements.nextElement() + " "); } //Copy Code
In fact, this interface is also an old one. To accommodate older versions of JDK, we can call something like Enumeration <String> enumeration = Collections.enumeration (list); to return an Enumeration.The principle is to call the method of the corresponding iterator.
// Collections.enumeration method public static <T> Enumeration<T> enumeration(final Collection<T> c) { return new Enumeration<T>() { // An iterator that constructs a corresponding set private final Iterator<T> i = c.iterator(); // hasNext calling iterator public boolean hasMoreElements() { return i.hasNext(); } // Call next of iterator public T nextElement() { return i.next(); } }; } //Copy Code
Comparison of Vector and ArrayList
- At the bottom of Vector and ArrayList are array data structures that maintain a dynamic length array.
- Vector defaults to double the length of an existing array when the expansion mechanism does not specify an expansion factor by constructing it.ArrayList is half the length of an existing array.
- Vectors are thread-safe, while ArrayList s are not thread-safe and are more efficient than Vectors when multithreaded operations are not involved
- For Vector, in addition to for loops, advanced for loops, and iterator iteration methods, elements() can also be called to return an Enumeration to traverse internal elements.
Differences between ArrayList and LinkedList
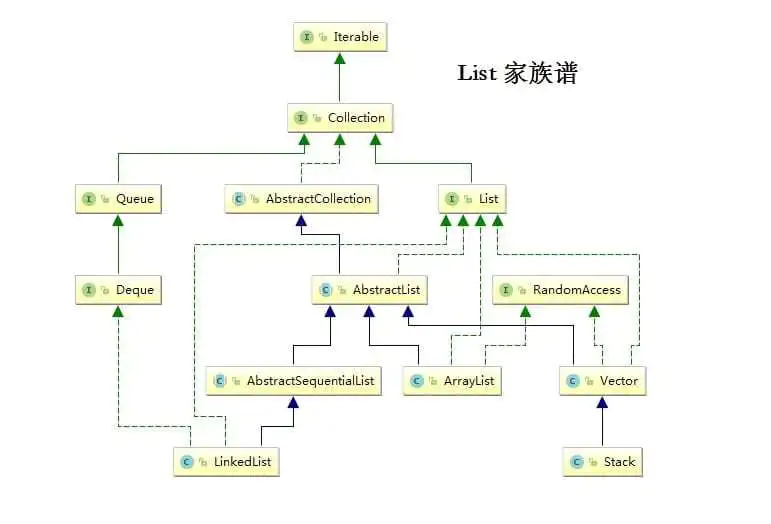
Let's go back and see how the inheritance systems of these two lists differ:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable //Copy Code
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable //Copy Code
You can see that LinkedList does not implement the RandomAccess interface, and we know that RandomAccess is an empty tag interface, marking the implementation class as having random, fast access.Then it is necessary to recognize this interface again, according to the Java API instructions of RandomAccess:
The common interface RandomAccess tag interfaces are used for List implementations to indicate that they support fast (usually constant time) random access.The primary purpose of this interface is to allow generic algorithms to change their behavior to provide good performance when applied to random or sequential access lists.
We can realize that the difference between random access and sequential access is often blurred.For example, if the list is large, some List implementations provide incremental access time, but are actually fixed access time, such a List implementation should generally implement this interface.As a rule of thumb, the List implementation should implement this interface for a typical class instance:
for(int i = 0,n = list.size(); i <n; i ++) list.get(ⅰ); //Copy Code
Faster than this loop:
for(Iterator i = list.iterator(); i.hasNext();) i.next(); //Copy Code
The API above states that there is a rule of thumb that if for traverses a List implementation class faster than iterator traversal, you need to implement the RandomAccess random quick access interface, identifying that this container supports random quick access.From this theory, we can guess that LinkedList does not have the property of random and fast access; in other words, LinkedList's for loop traversal is slower than iterator traversal.Let's test this:
private static void loopList(List<Integer> list) { long startTime = System.currentTimeMillis(); for (int i = 0; i < list.size(); i++) { list.get(i); } System.out.println(list.getClass().getSimpleName() + "Use Normal for Loop traversal time is" + (System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis(); Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()) { iterator.next(); } System.out.println(list.getClass().getSimpleName() + "Use iterator Loop traversal time is" + (System.currentTimeMillis() - startTime) + "ms"); } public static void main(String[] args){ //Test access speed for 10,000 integers List<Integer> arrayList = new ArrayList<Integer>(10000); List<Integer> linkedList = new LinkedList<Integer>(); for (int i = 0; i < 10000; i++){ arrayList.add(i); linkedList.add(i); } loopList(arrayList); loopList(linkedList); System.out.println(); } //Copy Code
Let's look at the output:
ArrayList traverses for 6ms using a normal for loop ArrayList traverses 4 ms using iterator loops LinkedList traverses 133 MS using a normal for loop LinkedList traverses 2 MS using iterator loop Copy Code
You can see that the for loop of LinkedList really takes a long time, which is not difficult to understand. In conjunction with the get (int index) method we saw in the previous article when we analyzed the source code of LinkedList:
public E get(int index) { checkElementIndex(index); return node(index).item; } //Copy Code
The node method compares index and size/2 internally to distinguish whether it starts from the head node of a double-linked list or from the tail. It is still a for loop internally, whereas ArrayList based on array data structure is different. When an array is created, it is easy to obtain elements at a specified location by indexing.So ArrayList has random quick access, whereas LinkedList does not.So we should try to avoid traversing with a for loop when using LinkedList.
Here we can summarize the differences between LinkedList and Array List:
-
ArrayList is an array structure at the bottom and has continuous storage space.Queries are fast, additions and deletions require a copy process of array elements, which results in lower performance when deletion element locations are higher.
-
At the bottom of the LinkedList is a two-way linked list data structure, where each node contains its own information about the previous and the next node, and the storage space can be non-contiguous.Add or delete blocks, slow query.
-
Both ArrayList and LinkedList are thread insecure.Vector is thread-safe
-
Try not to use a for loop to iterate over a LinkedList collection, but an iterator or advanced for.
Introduction to Stack
From the beginning of the inheritance system, you can know that Stack inherits from Vector, that is, Stack owns all the ways Vector adds and deletes changes.But when we say Stack, we definitely mean the data interface in the stack.
Let's first look at the definition of a stack:
A stack, also known as a stack, is a linear table with limited operations.The limitation is that insertion and deletion operations are only allowed at one end of the table.This end is called the top of the stack, while the other end is called the bottom.Inserting a new element into a stack, also known as a stack, a stack, or a stack, places the new element on top of the stack to make it a new top element; deleting an element from a stack, also known as a stack-out or a stack-down, deletes the top element and makes its adjacent elements a new top element.
Simply put, there is a convention in stack data structure that adding and removing elements from a stack are only allowed at the top of the stack, and elements that are first put on the stack are always taken out later.Arrays and lists can be used to manipulate this data structure of the stack.
Generally speaking, there are several operations for a stack:
- push stacking
- pop out of stack
- peek query stack top
- Is empty stack empty
Stack containers in Java implement stack operations using arrays as the underlying structure, and inbound and outbound operations are implemented by calling Vector's corresponding add and delete methods.
// Push public E push(E item) { addElement(item);//Call the addElement method defined by Vector return item; } // Stack Out public synchronized E pop() { E obj; int len = size(); obj = peek(); removeElementAt(len - 1);//Method to call the element at the end of the removeElementAt array defined by Vector return obj; } // Query top element public synchronized E peek() { int len = size(); if (len == 0) throw new EmptyStackException(); return elementAt(len - 1);//Query last element of array. } //Copy Code
The Stack implementation in Java containers is briefly described above, but these obsolete collection container classes are not officially recommended.In terms of stack data structure, relative to linear tables, there are implementations of stack, such as sequential storage (array) and discontinuous storage (chain table).The LinkedList we last saw in our previous article is a replacement for Stack for stacking.
Recently, in a technical group, a fellow American League champion said he interviewed an Android developer and examined the Android developer's understanding of the stack. The title of the survey was to implement a simple stack of basic peek, push, pop operations. The result did not know why the interviewer did not write it out and was eventually dropped by pass.So after analyzing Stack, I decided to try to write this interview by hand.I think I'm an interviewer. If the respondent only writes out how to stack, it should be considered as a failure. The interviewer should be concerned about whether he has considered StackOverFlow when writing push.
public class SimpleStack<E> { //Default capacity private static final int DEFAULT_CAPACITY = 10; //Array of elements on the stack private Object[] elements; //Number of elements on the stack private int size = 0; //top of stack private int top; public SimpleStack() { this(DEFAULT_CAPACITY); } public SimpleStack(int initialCapacity) { elements = new Object[initialCapacity]; top = -1; } public boolean isEmpty() { return size == 0; } public int size() { return size; } @SuppressWarnings("unchecked") public E pop() throws Exception { if (isEmpty()) { throw new EmptyStackException(); } E element = (E) elements[top]; elements[top--] = null; size--; return element; } @SuppressWarnings("unchecked") public E peek() throws Exception { if (isEmpty()) { throw new Exception("The current stack is empty"); } return (E) elements[top]; } public void push(E element) throws Exception { //Ensure capacity meets criteria before adding ensureCapacity(size + 1); elements[size++] = element; top++; } private void ensureCapacity(int minSize) { if (minSize - elements.length > 0) { grow(); } } private void grow() { int oldLength = elements.length; // Update capacity operation expanded to 1.5 times its original size Here you can choose another option int newLength = oldLength + (oldLength >> 1); elements = Arrays.copyOf(elements, newLength); } } //Copy Code
Synchronous vs asynchronous
For Vector and Stack, they both use the synchronized keyword to modify the method from the source code, which also means the method is synchronous and thread-safe.ArrayList and LinkedList are not thread-safe.However, when we introduced ArrayList and LinkedList, we mentioned that we can use Collections'static method to convert a List into a Thread Synchronized List:
List<Integer> synchronizedArrayList = Collections.synchronizedList(arrayList); List<Integer> synchronizedLinkedList = Collections.synchronizedList(linkedList); //Copy Code
So here's another interview question:
Briefly describe the differences between Vector and SynchronizedList.
SynchronizedList is Collections.synchronizedList(arrayList); the type of List that is generated after that is an internal class of Collections itself.
Let's look at his source code:
static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> { private static final long serialVersionUID = -7754090372962971524L; final List<E> list; SynchronizedList(List<E> list) { super(list); this.list = list; } SynchronizedList(List<E> list, Object mutex) { super(list, mutex); this.list = list; } ..... } //Copy Code
For the SynchronizedList construct, you can see that there is an Object parameter, but when you look at the word mutex, you should understand the meaning of this parameter: synchronous lock. In fact, when you click on the super method, you can see that the constructor lock for a single parameter is its object itself.
SynchronizedCollection(Collection<E> c) { this.c = Objects.requireNonNull(c); mutex = this; } SynchronizedCollection(Collection<E> c, Object mutex) { this.c = Objects.requireNonNull(c); this.mutex = Objects.requireNonNull(mutex); } //Copy Code
Next let's look at ways to add or delete changes:
public E get(int index) { synchronized (mutex) {return list.get(index);} } public E set(int index, E element) { synchronized (mutex) {return list.set(index, element);} } public void add(int index, E element) { synchronized (mutex) {list.add(index, element);} } public E remove(int index) { synchronized (mutex) {return list.remove(index);} } public int indexOf(Object o) { synchronized (mutex) {return list.indexOf(o);} } public int lastIndexOf(Object o) { synchronized (mutex) {return list.lastIndexOf(o);} } public boolean addAll(int index, Collection<? extends E> c) { synchronized (mutex) {return list.addAll(index, c);} } //Note that synchronized (mutex) is not added here public ListIterator<E> listIterator() { return list.listIterator(); // Must be manually synched by user } public ListIterator<E> listIterator(int index) { return list.listIterator(index); // Must be manually synched by user } //Copy Code
It is clear that, to make a collection thread-safe, Collocations simply wraps up the add-delete checking of parameter collections with synchronization constraints.As you can see from Vector, the first difference between them is whether they are synchronization methods or synchronization code blocks, for which the following are the differences:
- Synchronization code blocks may have a smaller range of locks than synchronization methods, and generally the size and performance of locks are inversely proportional.
- Synchronization blocks can more precisely control the scope of a lock (the scope of a lock is the time it is acquired and released), and the scope of a lock for a synchronization method is the entire method.
As you can see from the two methods above, ``Collections.synchronizedList(arrayList); the resulting synchronized collection looks more efficient, but this difference is not obvious on Vector and Array List because their add s methods have roughly the same internal implementation.Vectors cannot specify lock objects like SynchronizedList` in terms of construction parameters.
We also see that the SynchronizedList does not lock the iterator, but looking at Vector's iterator method is really chained, so we need to do synchronization manually when using SynchronizedList's iterator:
synchronized (list) { Iterator i = list.iterator(); // Must be in synchronized block while (i.hasNext()) foo(i.next()); } //Copy Code
Here we can summarize three differences between SynchronizedList and Vector:
- As a wrapper class, SynchronizedList has good extensibility and compatibility.All List subclasses can be converted to thread-safe classes.
- Use SynchronizedList's Get Iterator to manually synchronize traversal without Vector.
- SynchronizedList can specify the locked object by parameter, while Vector can only be the object itself.
summary
This article is a supplement to the List family, following the source analysis of ArrayList and LinkedList.We analyzed
- The difference between Vector and Array List.
- The difference between ArrayList and LinkedList leads to the definition of RandomAccess, which demonstrates that traversing LinkedList using a for loop is inefficient.
- Stack inherits from Vector and is thread safe, but it's also older.An interview question implementing a simple Stack class is then analyzed.
- Finally, we summarize three differences between SynchronizedList and Vector in terms of thread security.
These knowledge seem to be questions that interviewers like to ask, but also issues that are easy to ignore in normal work.Through this article, make a corresponding summary in case of a rainy day.