Source code analysis of HashMap (JDK1.8)
This is one of the series that I forgot to read again. Today I have time to write a document and record it. I hope I can slowly understand their excellent ideas from the JDK source code. This paper mainly records the following aspects.
1. Inheritance and implementation structure of HashMap
2. Constructors and properties of HashMap
3. Core methods of HashMap
1. Inheritance and implementation structure of HashMap
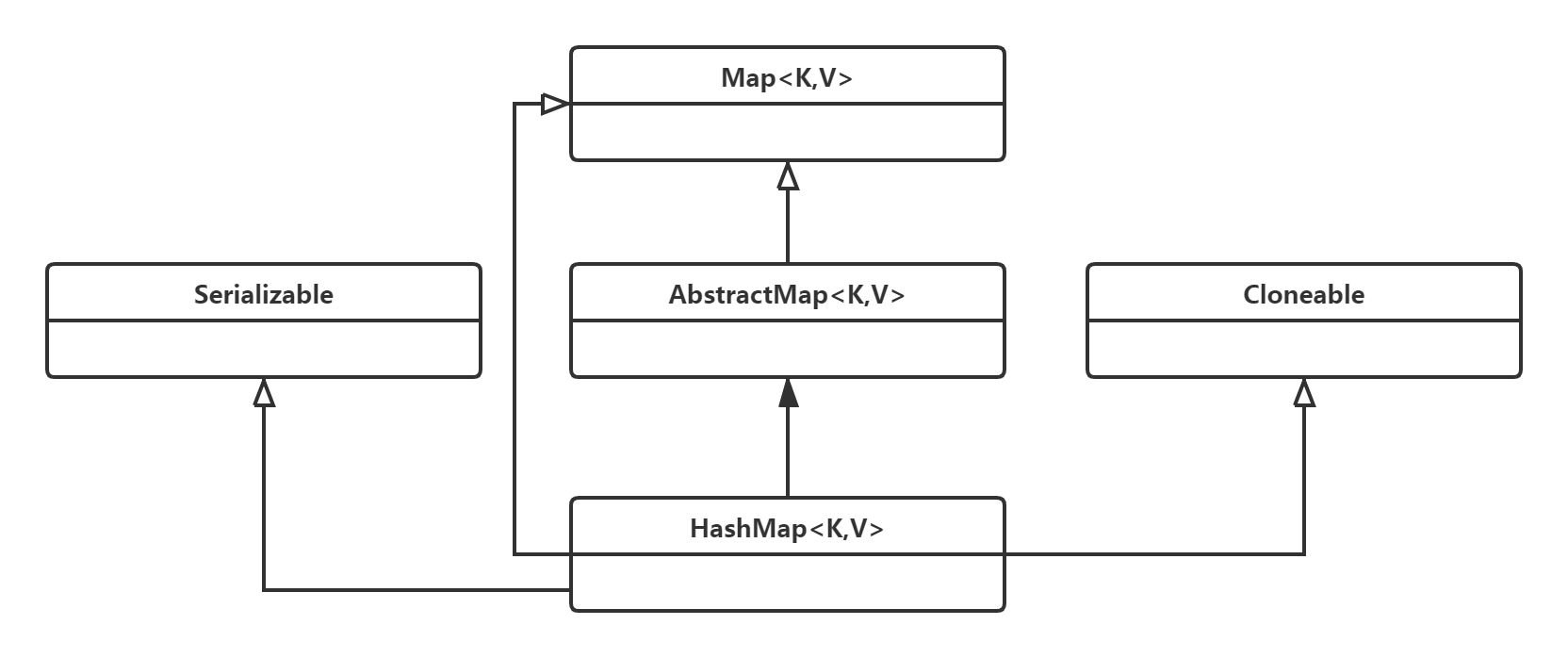
The above is the inheritance structure diagram of HashMap, which is relatively simple. The following is the concept map of HashMap.
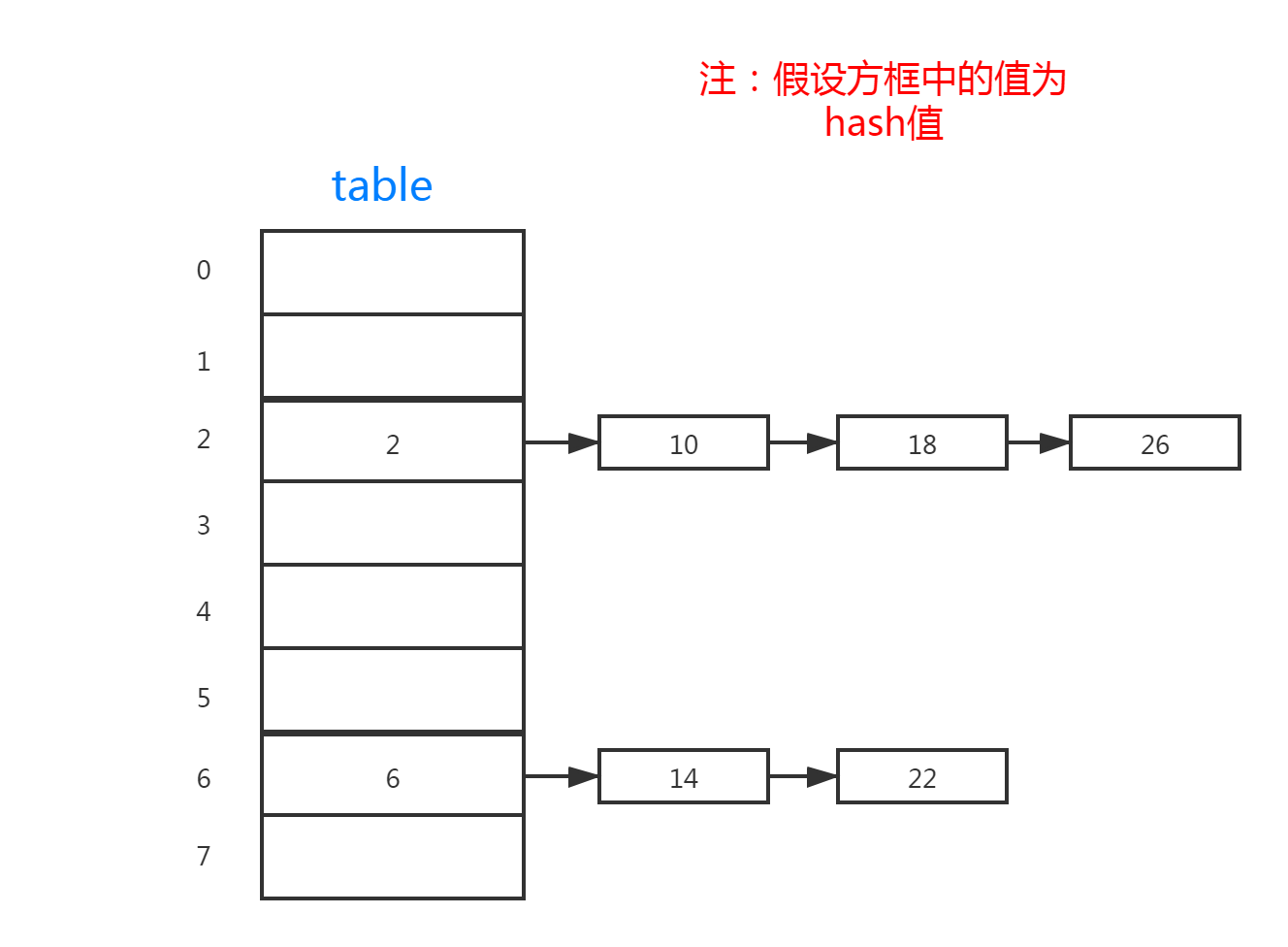
2. Constructors and properties of HashMap
2.1 attribute
Let's take a look at the property variables of HashMap
// If no capacity is specified when creating a HashMap, the default capacity is 16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 // 30 power with a maximum capacity of 2 static final int MAXIMUM_CAPACITY = 1 << 30; // Default capacity factor according to Poisson distribution static final float DEFAULT_LOAD_FACTOR = 0.75f; // Tree the threshold value of a slot. If the number of nodes in a slot is greater than this value and the capacity is greater than the minimum capacity, tree it static final int TREEIFY_THRESHOLD = 8; // Tree restore threshold static final int UNTREEIFY_THRESHOLD = 6; // Minimum tree capacity value static final int MIN_TREEIFY_CAPACITY = 64; // table of the actual storage node transient Node<K,V>[] table; // Easy to traverse the entrySet of all nodes transient Set<Map.Entry<K,V>> entrySet; // Actual number of nodes transient int size; // The number of structure changes and deleting new nodes will result in structure modification transient int modCount; // When the size is greater than this value, the capacity is expanded, which ensures the efficiency of HashMap int threshold; // Capacity factor, can be specified manually, default is 0.75f final float loadFactor;
2.2 constructor
Take a look at the constructor of HashMap
// The most commonly used constructor public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted } // Constructor with capacity parameter public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } // With capacity parameter and capacity factor public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; // Threshold based on capacity this.threshold = tableSizeFor(initialCapacity); } // Construction method with other Map set parameters public HashMap(Map<? extends K, ? extends V> m) { // Capacity factor set to default 0.75f this.loadFactor = DEFAULT_LOAD_FACTOR; // Put all nodes of other maps into table putMapEntries(m, false); }
3. The core methods of HashMap
I'll give you a common example of HashMap, and follow the example step by step to all the methods of HashMap.
public class MainTest { public static void main(String[] args){ HashMap<String,String> keyValues = new HashMap<>(); final String name = "name"; keyValues.put(name,"fuhang"); keyValues.get(name); keyValues.remove(name); } }
The above is a simple use example, because the constructor has been analyzed in section (2.2), it can be seen that the above use construction only initializes the lower capacity factor. Let's analyze each method in depth. Note: the operation of red black tree will not be analyzed temporarily, and the data structure of red black tree will be specially recorded when available.
3.1 put(K key,V value)
// This is the put method we call most often public V put(K key, V value) { // Internal call to putVal method return putVal(hash(key), key, value, false, true); }
3.2 hash(Object key)
// This method is a static tool method inside the HashMap. It makes exclusive or operation between the hashCode of the key and the value after its absolute right shift of 16 bits static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }

HashMap uses the key's hashcode and the key's hashcode to move 16 bits absolutely to the right for exclusive or operation, and then the new hash value is used as the key to reduce the key's collision optimization, and moves the high-level data to the status to participate in the operation.
3.3 tableSizeFor()
// This method is to expand the given capacity to an integer power of exactly 2, which is just larger than the given capacity, so as to facilitate the location of elements in the future static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
The figure is as follows:

3.4 putVal(...args)
putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict){ Node<K,V>[] tab; Node<K,V> p; int n, i; // If the table is empty or there are no elements in the table, the table structure will have a graphic example later if ((tab = table) == null || (n = tab.length) == 0) // Call resize() method to expand the capacity of table, and assign table.length to n n = (tab = resize()).length; // If the element on the position calculated according to the length of hashcode and table of key is empty, // Then put the element directly here if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { // Otherwise, there are already elements colliding in the calculated position. Use zipper method to add elements Node<K,V> e; K k; // Determine whether the first element has the same hash or value as the key // If equal, assign p to e if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // After the first element is unequal, judge whether the first element is a tree node // If so, node insertion tree structure else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // The first element is not a tree node, and the comparison between the first element key and the key we want to add is not equal to // Then perform the following logic // Loop the chain node at i position, similar to traversing the chain list for (int binCount = 0; ; ++binCount) { // If p.next is empty at the end of traversal, add nodes directly at the end of the chain p.next if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // If the number of iterations in i position is greater than 8, then try to tree all nodes in i position if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // If p.next is not empty, then judge whether the key of this node is equal to our put // If equal, jump out of the loop if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; // If none of the above is true, continue to traverse backward p = e; } } // If e is not empty, the same key value has been saved in table. If onlyIfAbsent is false // Then overwrite the old value with the new value and return the old value if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } // If the execution has not returned, a new node has been added to the table // Modify record auto increase, size auto increase and judge whether it is greater than the threshold value. If it is greater than, expand the capacity ++modCount; if (++size > threshold) resize(); // This method is empty in HashMap. It can make some response after the node is inserted afterNodeInsertion(evict); return null; } // Callbacks to allow LinkedHashMap post-actions void afterNodeAccess(Node<K,V> p) { } void afterNodeInsertion(boolean evict) { } void afterNodeRemoval(Node<K,V> p) { }
The above is the analysis of put method. There are several small points to explain as follows:
① the equation I = (n - 1) - hash is equivalent to I = hash% N, but the former is more efficient. HashMap is to optimize the details in order to be efficient. Note: the premise of the above equation is that n must be an integer power of 2.

② when the onlyIfAbsent flag is true, if the value corresponding to the key already exists, the old value will not be overwritten with the new value. If it is false, the old value will be overwritten with the new value
When bincount > = treeify ﹣ treehold - 1, only the chain corresponding to the table[i] position may be treelized, and the method must meet the internal requirements of tab. Length > = min﹣ treeify ﹣ capacity
3.5 get(Object key)
// The get method of HashMap exposure public V get(Object key) { Node<K,V> e; // Internal call getNode to get return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; // First of all, it must be determined that table is not empty, table length is greater than 0, and the first element corresponding to key is not empty if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // Determine whether the first element is the element we are looking for. If the first element is returned directly if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; // If first is not, you are going to traverse the linked list of corresponding positions if ((e = first.next) != null) { // If the element of the first location is a tree node, the location has been treelized // Then call getTreeNode of red black tree to find if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); // If it is not a tree, and the first node is not the node to be found, it will traverse the chain structure data of the corresponding location to find one by one do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
3.6 remove(Object key)
// Remove the node corresponding to a key from the HashMap public V remove(Object key) { Node<K,V> e; // Internal call removinode to remove. The value corresponding to the removal key is returned successfully, and null is returned in case of failure return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } /** * Implements Map.remove and related methods * * @param hash hash for key * @param key the key * @param value the value to match if matchValue, else ignored * @param matchValue if true only remove if value is equal * @param movable if false do not move other nodes while removing * @return the node, or null if none */ // The meaning of parameters is as above final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; // This is the same in a getNode. First, find the node corresponding to the key. There is no more verbosity here if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } // If the node corresponding to the key is found, move its next pointer, which is similar to the linked list operation if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) // Remove the red black tree. If the removal meets certain conditions, the tree will be reduced to a linked list ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; }
3.7 resize()
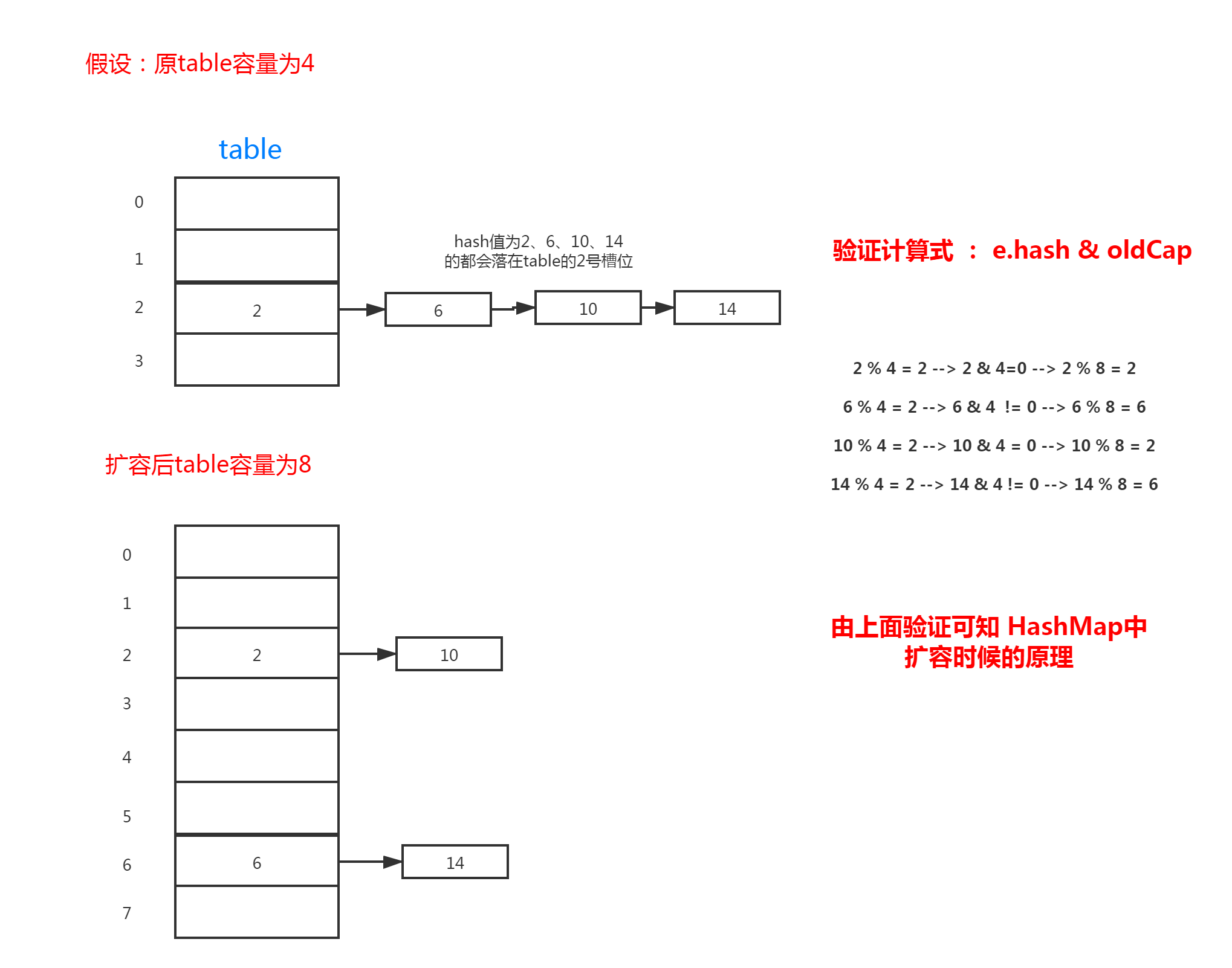
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; // Get old table capacity int oldCap = (oldTab == null) ? 0 : oldTab.length; // Old threshold int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { // If the old table capacity is greater than or equal to the maximum capacity limit // Then update the threshold value to the maximum value of Integer 2147483647 and return to the old table if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // Or double the capacity of the old table // If the condition that the capacity of the old table is larger than the initial capacity is satisfied, the threshold will be increased to twice of the original capacity else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold }else if (oldThr > 0) // initial capacity was placed in threshold // The if condition is to call the HashMap constructed by the constructor with capacity parameter or capacity parameter and capacity factor // Code executed by the first call to the resize() method // Assign new capacity to old threshold newCap = oldThr; else { // zero initial threshold signifies using defaults // This is the code to be executed when the constructor without parameter or with parameter Map enters the resize method for the first time newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } // If the newThr value is 0 // 1. It is possible to enter if (oldcap > 0), but the oldcap > = default \ initial \ capacity condition is not met // 2. Possible if (oldthr > 0) if (newThr == 0) { // Calculate ft based on new capacity * capacity factor float ft = (float)newCap * loadFactor; // If the new capacity is less than the maximum capacity and FT is less than the maximum capacity, then ft is assigned to the new threshold newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } // Assign the new threshold value to the member variable threshold threshold = newThr; // Create a new table and assign it to the member variable table @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; // If the old table is not empty, it means that there are elements in it, then the elements should be moved to the new table if (oldTab != null) { // Traverse the old table from the beginning for (int j = 0; j < oldCap; ++j) { Node<K,V> e; // If the j position of the old table is not empty, the element will be migrated to the new table if ((e = oldTab[j]) != null) { // Since the node in position j is assigned to e above, the following can be left empty for garbage collector recycling oldTab[j] = null; // If the next node of E is empty, migrate e directly to the corresponding location of the new table // Position can only be original position or original position + oldCapacity position // eg. 6%4=2 6% 8 = 6 if (e.next == null) newTab[e.hash & (newCap - 1)] = e; // If e is a tree node, the tree's split method will be called to migrate it back to the new table // This method may also reduce the tree to a linked list else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order // This indicates that the node is a normal zipper node // loHead and loTail are used to migrate the fixed nodes in the original location Node<K,V> loHead = null, loTail = null; // hiHead and hiTail are used to migrate nodes in the original location + oldCap Node<K,V> hiHead = null, hiTail = null; // The next temporary variable used for traversing the linked list Node<K,V> next; do { next = e.next; // The node with hash & oldcap 0 of the original node keeps the original position // This calculation can be understood as the original hash% newcap = = hash% oldcap if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { // Otherwise, it will be in the original position + oldCap position // This is the original hash% newcap! = hash% oldcap if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); // Finally, judge whether the tail pointer of high position is empty // If it is not empty, it means that there is node migration, then assign the corresponding header node to the corresponding location if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
The above is all the logic of the resize() method. Generally speaking, it is to expand the capacity and its threshold to twice as much as before. Data migration is completed. Some of these points are explained below.
① when I first looked at the code, I didn't understand the meaning of if ((e.hash & oldcap) = = 0). After calculation, it is obvious, as shown in the figure below.
Conclusion:
The above is the analysis of the commonly used methods of HashMap, in which the code of the red black tree is not analyzed temporarily, and the red black tree structure will be analyzed together when the TreeMap is recorded next time.