;
The Hadoop cluster depends on the following software: jdk, ssh, etc., so as long as these two items and Hadoop related packages are put into the image;
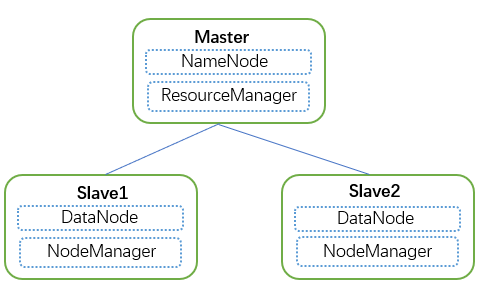
Profile preparation
1. Hadoop related configuration files: core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml, slaves, Hadoop env.sh
2. ssh configuration file: ssh config
3. Hadoop cluster startup file: start-hadoop.sh
Making mirrors
1. Installation dependency
RUN apt-get update && \ apt-get install -y openssh-server openjdk-8-jdk wget
2. Download Hadoop package
RUN wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz && \ tar -xzvf hadoop-2.10.0.tar.gz && \ mv hadoop-2.10.0 /usr/local/hadoop && \ rm hadoop-2.10.0.tar.gz && \ rm /usr/local/hadoop/share/doc -rf
3. Configure environment variables
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 ENV HADOOP_HOME=/usr/local/hadoop ENV PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
4. Generate SSH key for node password free login
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
5. Create Hadoop related directories, copy related configuration files, add execution permissions to related files, format namenode node finally, start ssh service when each node starts;
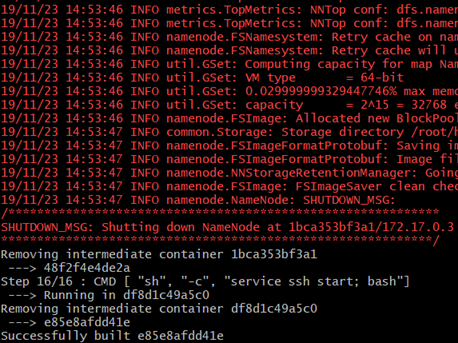
RUN mkdir -p ~/hdfs/namenode && \ mkdir -p ~/hdfs/datanode && \ mkdir $HADOOP_HOME/logs COPY config/* /tmp/ #Replication ssh, hadoop configuration related RUN mv /tmp/ssh_config ~/.ssh/config && \ mv /tmp/hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh && \ mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \ mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \ mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \ mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \ mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \ mv /tmp/start-hadoop.sh ~/start-hadoop.sh && \ mv /tmp/run-wordcount.sh ~/run-wordcount.sh #Add execution permission RUN chmod +x ~/start-hadoop.sh && \ chmod +x ~/run-wordcount.sh && \ chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \ chmod +x $HADOOP_HOME/sbin/start-yarn.sh # format namenode RUN /usr/local/hadoop/bin/hdfs namenode -format

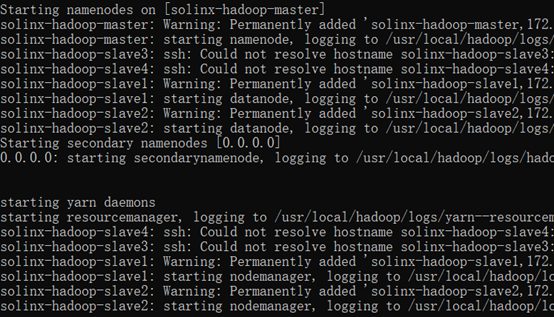
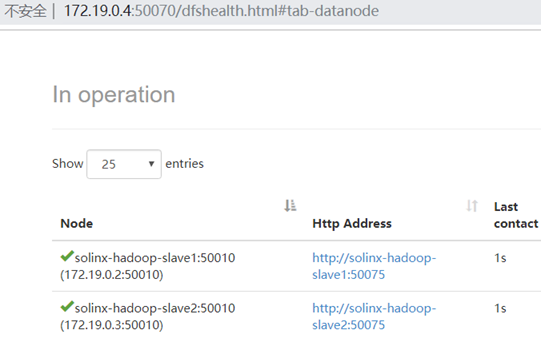
Running Hadoop cluster in Docker
;
Add bridge network:
docker network create --driver=bridge solinx-hadoop
Start the Master node:
docker run -itd --net=solinx-hadoop -p 10070:50070 -p 8088:8088 --name solinx-hadoop-master --hostname solinx-hadoop-master solinx/hadoop:0.1
Start Slave1 node:
docker run -itd --net=solinx-hadoop --name solinx-hadoop-slave1 --hostname solinx-hadoop-slave1 solinx/hadoop:0.1
Start the slave 2 node:
docker run -itd --net=solinx-hadoop --name solinx-hadoop-slave2 --hostname solinx-hadoop-slave1 solinx/hadoop:0.1
Enter the Master node and execute the start Hadoop cluster script: