A brief description of nosql concepts
The full name of nosql is not only sql, that is, not only non-relational database, but also nosql storage is not as dependent on business logic as relational database. nosql storage is very simple SQL storage.
What is redis
As we all know, total memory reads much faster than disk reads. So it's a good choice to have important and frequently queried data in memory.
As a result, memcache was born. memcache is a nosql database. The data is stored in memory, but the disadvantage is obvious. Because the data can only be stored in memory, once shut down, the data will be lost, and the memcache storage type is very single, so developers start to think about a better solution?
redis is the latest solution, with all the capabilities of memcache, support for data persistence, and a wide range of storage data structures.
redis installation
Install C language compilation environment
yum install centos-release-scl scl-utils-build yum install -y devtoolset-8-toolchain scl enable devtoolset-8 bash
Set gcc version after completion
gcc --version
Download the redis-6.2.1.tar.gz Place/opt directory
Unzip command: tar-zxvf redis-6.2.1.tar.gz
Enter directory after unzipping: cd redis-6.2.1
Type make
Note: 2.2.2.6. Make will fail if the C language compilation environment is not prepared - Jemalloc/jemalloc.h: Without that file, make distclean can be run, and make can be run again to solve the problem
Run make install
Summary
Since then, the redis installation has been completed and redis will be installed in the / usr/local/bin directory by default, so to facilitate subsequent operations, we can run the following command to create a redis configuration directory for subsequent experimental operations
# Create Profile Experiment Folder mkdir myredis Get into redis Unzip directory cd /opt/redis-6.2.1/ Copy profile to new folder cp redis.conf /myredis/ # Enter the redis command directory cd /usr/local/bin/
start-up
Foreground startup
Once the ctrl+c process is pressed, it ends directly
redis-server /myredis/redis.conf
Background boot (recommended)
Run the command profile once
vim /myredis/redis.conf
Press/daemonize to find daemonize and set this parameter to yes, as shown in the following figure
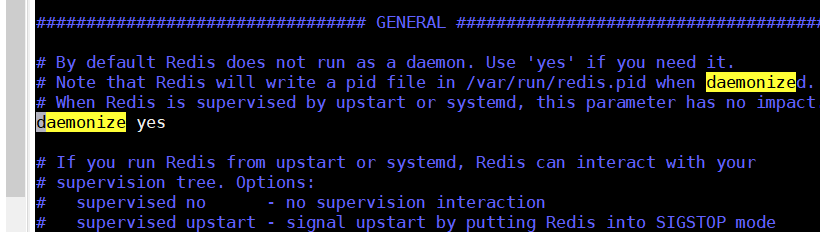
start-up
# Start redis /usr/local/bin/redis-server /myredis/redis.conf # Check if redis is started ps -ef|grep redis
Start Client
/usr/local/bin/redis-cli
cli type ping
If PONG is output, the redis client is already connected to the service.
Close Server
- Client runs shutdown
- /usr/local/bin/redis-cli -p 6379 shutdown
redis infrastructure operations
String
String is the most basic storage type for redis. It is binary safe so you can store pictures or binary objects. A redis can store up to 512M.
Common Commands
Add key-value pairs
set <key><value> #setNX: You can add key-value to a database when the key does not exist in the database #setXX: When a key exists in the database, you can add a key-value to the database, which is mutually exclusive from the NX parameter #setEX:key timeout seconds #setPX:key timeout milliseconds, mutually exclusive from EX
Query for corresponding key values
get <key>
Append the given value to the end of the original value
append <key> <value>
Length to get value
strlen <key>
Add 1 to the number stored in the key. Note that only numeric values can be manipulated. If empty, the new value is 1
incr <key>
Reduce the number stored in the key by 1. You can only operate on the number. If it is empty, the new value is -1
decr <key>
List
brief introduction
At the bottom of the list is a two-way queue, so lists operate faster on both ends, but drawings involving intermediate node operations are slower.
It is important to understand that this data structure is stored in ziplist when the data volume is good. ziplist is a continuous memory storage unit, but after a certain amount of data, quicklist is programmed. The quicklist is shown in the following figure, using precursor and successor nodes to connect countless ziplists.

Common Commands
Insert one or more values from left/right.
lpush/rpush <key> <value1> <value2> <value3> ....
Pop up a value from left/right.
lpop/rpop <key>
Pop up a value from the right of the list and insert it to the left of the list.
rpoplpush <key1> <key2>
Get elements by index subscript (left to right)
lrange <key><start><stop> lrange mylist 0 -1 0 First on the left,-1 First on the right, (0-1 Means get all)
Get elements by index subscript (left to right)
lindex <key><index>
Get List Length
llen <key>
Insert value after
linsert <key> before <value> <newvalue>
Delete n values from left (left to right)
lrem <key><n><value>
Replace list key index with value
lset <key> <index> <value>
Set
brief introduction
The set in redis is the same as hashset in java, a hashMap without a value.
Common Commands
If one or more member elements are added to the set key, existing member elements will be ignored
sadd <key><value1><value2> .....
Remove all values from the set
smembers <key>
Determine if the set contains this value, 1, No 0
sismember <key> <value>
Returns the number of elements in the collection.
scard<key>
Delete an element from the collection.
srem <key> <value1> <value2> ....
Randomly spit out a value from the set
spop <key>
Randomly take n values from the set. Will not be deleted from the collection
srandmember <key> <n>
Moving a value from one set to another
smove <source> <destination> <value>
Returns the intersection element of two sets.
sinter <key1> <key2>
Returns the union element of two sets.
sunion <key1> <key2>
Returns the difference element of two sets (key1, not key2)
sdiff <key1> <key2>
Hash
brief introduction
This is equivalent to Map in java, where ziplist is used for storage when the amount of data is small, and hashtable is used when the amount of data reaches a certain level.
Common Commands
Assigning values to keys in a set
hset <key> <field> <value>
Remove value from collection
hget <key1> <field>
Batch setting hash values
hmset <key1><field1><value1><field2><value2>...
Check the hash table key for the existence of a given field.
hexists <key1> <field>
List all field s of the hash collection
hkeys <key>
List all value s of the hash collection
hvals <key>
Add an increment of 1-1 to the field value in the hash table key
hincrby <key> <field> <increment>
Set the value of the field in the hash table key to value if and only if the field does not exist.
hsetnx <key> <field> <value>
Zset
brief introduction
It's similar to set, but each member of zset has one more score, which is used to sort collections, so using zset allows you to have a list of different members that are not duplicated but can be duplicated by score.
Its underlying implementation is also sophisticated, using hash's key to keep values unique and hash's value to store score s.
Then use jump tables to sort these data through score to ensure query speed.
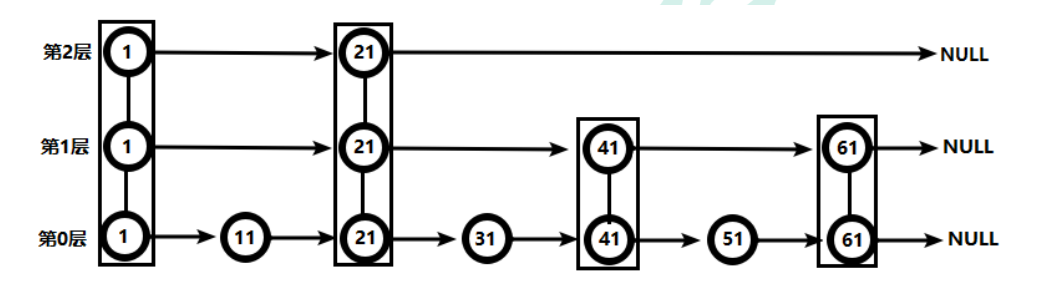
Here's a simple scenario for jumping tables.
As shown in the following figure, if the following data structures are stored in a chain table, query 51 requires six times.

The jump table shows the top 2 ^0, the bottom 2 ^1, and the bottom 2 ^2. Store key values using this structure interval interval.
The following figure is an example:
- At the top, you see that the first node is 1, less than 51, moving forward.
- Whether it's 21 or too small to continue, I can't find it, so I look down.
- The next node is 41, less than 51.
- Later it was found that it was greater than 61 and continued down. At this point, it was found that 51 lookups only took four times.
Common Commands
Add one or more member elements and their score values to the ordered set key.
zadd <key> <score1> <value1> <score2> <value2>...
Returns an ordered set key with the subscript in The elements in between have WITHSCORES, allowing the fractions to be combined with the values to be returned to the result set.
zrange <key><start><stop> [WITHSCORES]
Returns a member of the ordered set key whose score values are between min and max, including those equal to min or max. Ordered set members are ordered in increasing (small to large) order by score value.
zrangebyscore key minmax [withscores] [limit offset count]
Same as above, change from big to small.
zrevrangebyscore key maxmin [withscores] [limit offset count]
Add an increment to the element's scope
zincrby <key><increment><value>
Delete the element of the specified value under the set
zrem <key> <value>
Count the set, the number of elements in the fractional interval
zcount <key> <min> <max>
Returns the rank of the value in the set, starting at 0.
zrank <key> <value>