0. Preface
reference resources: The blogger . I write my own blog to facilitate review
1. Film review data set
Dataset Download: Link: https://pan.baidu.com/s/1zultY2ODRFaW3XiQFS-36w
Extraction code: mgh2 There are four files in the compressed package. Put the unzipped folder in the project directory
The training data set is too large, so I use the test data set for training
2. Load data
import pandas as pd
# Load data
train_data = pd.read_csv('./Dataset/test.txt', names=['label', 'review'], sep='\t')
train_labels = train_data['label']
train_reviews = train_data['review']

There are 369 training data
comments_len = train_data.iloc[:, 1].apply(lambda x: len(x.split(' ')))
print(comments_len)
train_data['comments_len'] = comments_len
print(train_data['comments_len'].describe(percentiles=[.5, .95]))
train_data.iloc[:, 1].apply(lambda x: len(x.split('')) means to train_ The data in column 2 of data (numbered 1, i.e. review) returns the number of each data word
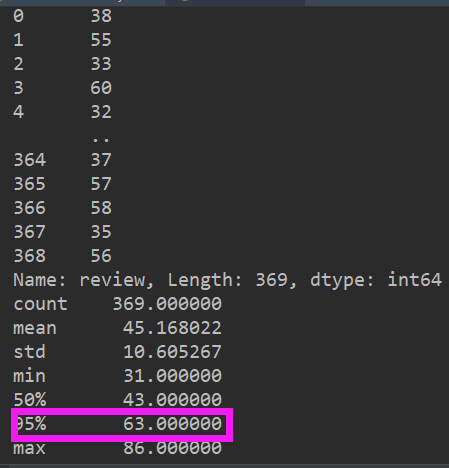
It can be seen that 95% of the comments are within 63, so we take the maximum number of each comment as max_ Send = 63, if it exceeds, cut off the following words, otherwise add them
3. Data preprocessing
from collections import Counter
def text_process(review):
"""
Data preprocessing
:param review: Comment data train_reviews
:return: glossary words,Words-id Dictionary of word2id,id-Dictionary of words id2word,pad_sentencesid
"""
words = []
for i in range(len(review)):
words += review[i].split(' ')
# Select the words with higher frequency and store them in word_ In freq.txt
with open('./Dataset/word_freq.txt', 'w', encoding='utf-8') as f:
# Counter(words).most_common() finds the word with the highest frequency (all words and their frequency are returned without parameters)
for word, freq in Counter(words).most_common():
if freq > 1:
f.write(word+'\n')
# Take out data
with open('./Dataset/word_freq.txt', encoding='utf-8') as f:
words = [i.strip() for i in f]
# De duplication (Glossary)
words = list(set(words))
# Dictionary of word ID word2id
word2id = {j: i for i, j in enumerate(words)}
# ID word dictionary id2word
id2word = {i: j for i, j in enumerate(words)}
pad_id = word2id['hold'] # The id of the neutral word is used for padding
sentences = [i.split(' ') for i in review]
# Fill in all the sentences, and each word is represented by id
pad_sentencesid = []
for i in sentences:
# If the word is not in the vocabulary, use pad_id substitution if there is a word, return the id corresponding to the word
temp = [word2id.get(j, pad_id) for j in i]
# If the number of words in the sentence is greater than max_sent, the following is truncated
if len(i) > max_sent:
temp = temp[:max_sent]
else: # If the number of words in a sentence is less than max_ Send, pad is used_ Fill with ID
for j in range(max_sent - len(i)):
temp.append(pad_id)
pad_sentencesid.append(temp)
return words, word2id, id2word, pad_sentencesid
First, put all the comments into words, select the words with frequency freq > 1 and store them in word_ Take out freq.txt and put it into words. Freq can control how much it is greater. Of course, this step can also be omitted. This step will be more efficient when there is a large amount of data. After screening, the keywords of emotion classification are basically retained
We turn those words with frequency freq < = 1 into "put" words. It doesn't matter what they become, as long as it won't affect our classification results. This word is a neutral word, so it won't have any impact on emotional classification.
After processing each sentence, if the number of words in the sentence is greater than max_sent, the following words will be truncated, otherwise the pad_id of the neutral word will be filled
4. Get data
import torch
import torch.utils.data as Data
import numpy as np
from gensim.models import keyedvectors
# hyper parameter
Batch_Size = 32
Embedding_Size = 50 # Word vector dimension
Filter_Num = 10 # Number of convolution kernels
Dropout = 0.5
Epochs = 60
LR = 0.01
# Load word vector model Word2vec
w2v = keyedvectors.load_word2vec_format('./Dataset/wiki_word2vec_50.bin', binary=True)
def get_data(labels, reviews):
words, word2id, id2word, pad_sentencesid = text_process(reviews)
x = torch.from_numpy(np.array(pad_sentencesid)) # [369, 63]
y = torch.from_numpy(np.array(labels)) # [369]
dataset = Data.TensorDataset(x, y)
data_loader = Data.DataLoader(dataset=dataset, batch_size=Batch_Size)
# Traverse all words in the vocabulary. If there is a vector representation of the word in w2v, do not operate. Otherwise, randomly generate a vector and put it in w2v
for i in range(len(words)):
try:
w2v[words[i]] = w2v[words[i]]
except Exception:
w2v[words[i]] = np.random.randn(50, )
return data_loader, id2word
Key: the words in the comments may not be in w2v, so we have to randomly assign vectors, otherwise an error will be reported
5. Turn words into word vectors
def word2vec(x): # [batch_size, 63]
"""
Turn all words in the sentence into word vectors
:param x: batch_size Sentences
:return: batch_size Word vector of a sentence
"""
batch_size = x.shape[0]
x_embedding = np.ones((batch_size, x.shape[1], Embedding_Size)) # [batch_size, 63, 50]
for i in range(len(x)):
# item() converts the tensor type to number type
x_embedding[i] = w2v[[id2word[j.item()] for j in x[i]]]
return torch.tensor(x_embedding).to(torch.float32)
Here, the words in all sentences are transformed into word vectors
6. Model
import torch.nn as nn
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv1d(1, Filter_Num, (2, Embedding_Size)),
nn.ReLU(),
nn.MaxPool2d((max_sent-1, 1))
)
self.dropout = nn.Dropout(Dropout)
self.fc = nn.Linear(Filter_Num, 2)
self.softmax = nn.Softmax(dim=1) # that 's ok
def forward(self, X): # [batch_size, 63]
batch_size = X.shape[0]
X = word2vec(X) # [batch_size, 63, 50]
X = X.unsqueeze(1) # [batch_size, 1, 63, 50]
X = self.conv(X) # [batch_size, 10, 1, 1]
X = X.view(batch_size, -1) # [batch_size, 10]
X = self.fc(X) # [batch_size, 2]
X = self.softmax(X) # [batch_size, 2]
return X
TextCNN network model
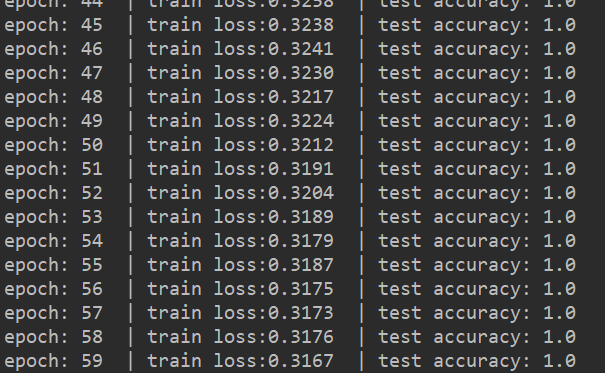
7. Training
if __name__ == '__main__':
data_loader, id2word = get_data(train_labels, train_reviews)
text_cnn = TextCNN()
optimizer = torch.optim.Adam(text_cnn.parameters(), lr=LR)
loss_fuc = nn.CrossEntropyLoss()
print("+++++++++++start train+++++++++++")
for epoch in range(Epochs):
for step, (batch_x, batch_y) in enumerate(data_loader):
# Forward propagation
predicted = text_cnn.forward(batch_x)
loss = loss_fuc(predicted, batch_y)
# Back propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Calculate accuracy
# dim=0 means to take the maximum value of each column, and dim=1 means to take the maximum value of each row
# torch.max()[0] returns the maximum value. torch.max()[1] returns the index of the maximum value
predicted = torch.max(predicted, dim=1)[1].numpy()
label = batch_y.numpy()
accuracy = sum(predicted == label) / label.size
if step % 30 == 0:
print('epoch:', epoch, ' | train loss:%.4f' % loss.item(), ' | test accuracy:', accuracy)
8. All codes
#encoding:utf-8
#Author: codeven
import pandas as pd
from collections import Counter
import torch
import torch.nn as nn
import torch.utils.data as Data
import numpy as np
from gensim.models import keyedvectors
# Load data
train_data = pd.read_csv('./Dataset/test.txt', names=['label', 'review'], sep='\t')
train_labels = train_data['label']
train_reviews = train_data['review']
# 95% of the comments were within 62
comments_len = train_data.iloc[:, 1].apply(lambda x: len(x.split(' ')))
print(comments_len)
train_data['comments_len'] = comments_len
print(train_data['comments_len'].describe(percentiles=[.5, .95]))
# Process the data. If the sentence length is greater than max_sent, it will be truncated. Otherwise, it will be filled with 'empty'
max_sent = 63
def text_process(reviews):
"""
Data preprocessing
:param review: Comment data train_reviews
:return: glossary words,Words-id Dictionary of word2id,id-Dictionary of words id2word,pad_sentencesid
"""
words = []
for i in range(len(reviews)):
words += reviews[i].split(' ')
# Select the words with higher frequency and store them in word_freq.txt
with open('./Dataset/word_freq.txt', 'w', encoding='utf-8') as f:
# Counter(words).most_common() find the word with the highest frequency (return all words and their frequency without parameters)
for word, freq in Counter(words).most_common():
if freq > 1:
f.write(word+'\n')
# Take out data
with open('./Dataset/word_freq.txt', encoding='utf-8') as f:
words = [i.strip() for i in f]
# De duplication (Glossary)
words = list(set(words))
# Dictionary of word ID word2id
word2id = {j: i for i, j in enumerate(words)}
# ID word dictionary id2word
id2word = {i: j for i, j in enumerate(words)}
pad_id = word2id['hold'] # The id of the neutral word is used for padding
sentences = [i.split(' ') for i in reviews]
# Fill in all the sentences, and each word is represented by id
pad_sentencesid = []
for i in sentences:
# If there is no word in the vocabulary, replace it with pad_id. if there is a word, return the ID corresponding to the word
temp = [word2id.get(j, pad_id) for j in i]
# If the number of words in the sentence is greater than max_sent, the following words are truncated
if len(i) > max_sent:
temp = temp[:max_sent]
else: # If the number of sentence words is less than max_sent, fill it with pad_id
for j in range(max_sent - len(i)):
temp.append(pad_id)
pad_sentencesid.append(temp)
return words, word2id, id2word, pad_sentencesid
# hyper parameter
Batch_Size = 32
Embedding_Size = 50 # Word vector dimension
Filter_Num = 10 # Number of convolution kernels
Dropout = 0.5
Epochs = 60
LR = 0.01
# Load word vector model Word2vec
w2v = keyedvectors.load_word2vec_format('./Dataset/wiki_word2vec_50.bin', binary=True)
def get_data(labels, reviews):
words, word2id, id2word, pad_sentencesid = text_process(reviews)
x = torch.from_numpy(np.array(pad_sentencesid)) # [369, 63]
y = torch.from_numpy(np.array(labels)) # [369]
dataset = Data.TensorDataset(x, y)
data_loader = Data.DataLoader(dataset=dataset, batch_size=Batch_Size)
# Traverse all words in the vocabulary. If there is a vector representation of the word in w2v, do not operate. Otherwise, randomly generate a vector and put it in w2v
for i in range(len(words)):
try:
w2v[words[i]] = w2v[words[i]]
except Exception:
w2v[words[i]] = np.random.randn(50, )
return data_loader, id2word
def word2vec(x): # [batch_size, 63]
"""
Turn all words in the sentence into word vectors
:param x: batch_size Sentences
:return: batch_size Word vector of a sentence
"""
batch_size = x.shape[0]
x_embedding = np.ones((batch_size, x.shape[1], Embedding_Size)) # [batch_size, 63, 50]
for i in range(len(x)):
# item() converts the tensor type to number type
x_embedding[i] = w2v[[id2word[j.item()] for j in x[i]]]
return torch.tensor(x_embedding).to(torch.float32)
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv1d(1, Filter_Num, (2, Embedding_Size)),
nn.ReLU(),
nn.MaxPool2d((max_sent-1, 1))
)
self.dropout = nn.Dropout(Dropout)
self.fc = nn.Linear(Filter_Num, 2)
self.softmax = nn.Softmax(dim=1) # that 's ok
def forward(self, X): # [batch_size, 63]
batch_size = X.shape[0]
X = word2vec(X) # [batch_size, 63, 50]
X = X.unsqueeze(1) # [batch_size, 1, 63, 50]
X = self.conv(X) # [batch_size, 10, 1, 1]
X = X.view(batch_size, -1) # [batch_size, 10]
X = self.fc(X) # [batch_size, 2]
X = self.softmax(X) # [batch_size, 2]
return X
if __name__ == '__main__':
data_loader, id2word = get_data(train_labels, train_reviews)
text_cnn = TextCNN()
optimizer = torch.optim.Adam(text_cnn.parameters(), lr=LR)
loss_fuc = nn.CrossEntropyLoss()
print("+++++++++++start train+++++++++++")
for epoch in range(Epochs):
for step, (batch_x, batch_y) in enumerate(data_loader):
# Forward propagation
predicted = text_cnn.forward(batch_x)
loss = loss_fuc(predicted, batch_y)
# Back propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Calculate accuracy
# dim=0 means to take the maximum value of each column, and dim=1 means to take the maximum value of each row
# torch.max()[0] returns the maximum value. torch.max()[1] returns the index of the maximum value
predicted = torch.max(predicted, dim=1)[1].numpy()
label = batch_y.numpy()
accuracy = sum(predicted == label) / label.size
if step % 30 == 0:
print('epoch:', epoch, ' | train loss:%.4f' % loss.item(), ' | test accuracy:', accuracy)
About a minute later, the training is over