preface
After migrating a single application to a distributed framework, it is likely to encounter such a problem: the system has only one control unit, which will call multiple computing units. If a computing unit (as a service provider) is unavailable, the control unit (as a service caller) will be blocked and eventually the control unit will crash, Thus, the whole system faces the risk of paralysis.
Causes of service avalanche effect
I simplified the participants in the service avalanche into Service provider and Service callers, and divide the process of service avalanche into the following three stages to analyze the causes:
-
Service provider unavailable
-
Retry to increase traffic
-
Service caller unavailable
Each stage of the service avalanche may be caused by different reasons, such as Service Unavailable The reasons are:
-
Hardware failure
-
Program Bug
-
Buffer breakdown
-
Large number of user requests
Hardware failure may be server host downtime caused by hardware damage and inaccessibility of service providers caused by network hardware failure
Cache breakdown usually occurs when the cache application is restarted, all caches are emptied, and a large number of caches fail in a short time. A large number of cache misses make requests hit the back end directly, resulting in overload of service providers and unavailability of services
Before the second kill and big promotion, if the preparation is not sufficient, users will initiate a large number of requests, which will also lead to the unavailability of service providers
And form Retry to increase traffic The reasons are:
-
User retry
-
Code logic retry
After the service provider is unavailable, users can't stand waiting for a long time on the interface, and constantly refresh the page or even submit forms
There will be a lot of retry logic after service exceptions at the service caller
These retries will further increase the request traffic
last, Service caller unavailable The main causes are:
-
Resource exhaustion caused by synchronization waiting
When used by the service caller Synchronous call Once the thread resources are exhausted, the services provided by the service caller will also be unavailable, so the service avalanche effect occurs
Coping strategies for service avalanche
Different coping strategies can be used for different causes of service avalanche:
-
flow control
-
Improved cache mode
-
Automatic service expansion
-
Service caller downgrade service
Specific measures for flow control include:
-
Gateway current limiting
-
User interaction current limiting
-
Close retry
Because of the high performance of Nginx, a large number of first-line Internet companies use the gateway of Nginx+Lua for flow control, and the resulting OpenResty is becoming more and more popular
The specific measures of user interaction current limiting are as follows: 1. Loading animation is adopted to improve the user's patient waiting time. 2. The submit button adds a forced waiting time mechanism
Measures to improve the cache mode include:
-
Cache preload
-
Synchronous to asynchronous refresh
The measures for automatic service expansion mainly include:
-
auto scaling of AWS
Measures taken by service callers to downgrade services include:
-
Resource isolation
-
Classify dependent services
-
Call to unavailable service failed quickly
Resource isolation is mainly used to isolate the thread pool calling the service
According to the specific business, we divide the dependent services into strong dependence and if dependence. The unavailability of strong dependence services will lead to the suspension of the current business, while the unavailability of weak dependence services will not lead to the suspension of the current business
The call of unavailable services fails quickly, usually through Timeout mechanism, Fuse And fused Degradation method To achieve it
Challenges after service:
-
Service Management: after agile iteration, there may be more and more micro services and more interactions between business systems. How to make an efficient cluster communication scheme is also a problem.
-
Application management: after each business system is deployed, it corresponds to a process, which can be started and stopped. If the machine is powered down or down, how to do seamless switching requires a strong deployment management mechanism.
-
Load balancing: in order to cope with large traffic scenarios and provide system reliability, the same business system will also be deployed in a distributed manner, that is, one business instance will be deployed on multiple machines. If a business system hangs up, how to automatically scale on demand and the distributed scheme also needs to be considered.
-
Problem location: the logs of individual applications are concentrated together, which is very convenient for problem location, while the problem delimitation and location in distributed environment and log analysis are more difficult.
-
Avalanche problem: distributed systems have such a problem. Due to the instability of the network, the availability of any service is not 100%. When the network is unstable, as a service provider, it may be dragged to death, resulting in the blocking of service callers, which may eventually lead to an avalanche effect.
There are many modes to improve system availability, two of which are very important: using timeout strategy and using fuse
-
Timeout strategy: if a service is frequently called by other parts of the system, the failure of one part may lead to cascading failure. For example, the operation of calling a service can be configured to execute timeout. If the service fails to respond within this time, a failure message will be replied. However, this strategy may cause many concurrent requests to the same operation to be blocked until the timeout period expires. These blocked requests may store critical system resources, such as Memory , thread, database connection, etc. Therefore, these resources may be exhausted, resulting in the failure of the system that needs to use the same resources. In this case, it would be preferable for the operation to fail immediately. Setting a short timeout may help solve this problem, but the time required for an operation request from sending to receiving a successful or failed message is uncertain.
-
Fuse mode: the fuse mode uses the circuit breaker to detect whether the fault has been solved, so as to prevent the request from repeatedly trying to perform an operation that may fail, so as to reduce the time waiting to correct the fault, which is more flexible than the timeout strategy.
Essence of avalanche problem:
Considering that the number of threads in the application container is basically fixed (for example, Tomcat's thread pool defaults to 200), in the case of high concurrency, if an externally dependent service (a third-party system or self-developed system fails) times out and blocks, it may fill the whole main process pool and increase memory consumption. This is the anti congestion mode of long request (a deterioration mode in which the delay of a single request becomes longer, resulting in system performance deterioration or even collapse).
Furthermore, if the thread pool is full, the whole service will not be available, and the above problems may occur again. Therefore, the whole system will collapse like an avalanche.
Several scenarios caused by avalanche effect
-
Traffic surge: for example, abnormal traffic and user retry lead to an increase in system load;
-
Cache refresh: assume A is client End, B is Server On the other hand, assuming that the requests of system A flow to system B, and the requests exceed the carrying capacity of system B, system B will crash;
-
The program has bugs: the logic problem of code circular call, memory leakage caused by unreleased resources, etc;
-
Hardware failure: such as downtime, power failure in the computer room, Optical fiber Cut off, etc.
-
Thread synchronous waiting: synchronous service invocation mode is often used between systems. Core services and non core services share a thread pool and message queue. If a core business thread calls a non core thread, the non core thread is completed by the third-party system. When the third-party system itself has a problem, resulting in the core thread blocking and waiting all the time, and the call between processes has a timeout limit, the thread will eventually break, which may also cause an avalanche;
Common solutions
There are many solutions for the above avalanche scenarios, but no universal model can deal with all scenarios.
-
For the surge of traffic, the automatic capacity expansion and contraction is adopted to deal with the sudden traffic, or the current limiting module is installed on the load balancer.
-
For Cache refresh, refer to the case study of service overload in Cache application
-
For hardware failure, multi machine room disaster recovery, cross machine room routing, remote multi activity, etc.
-
For synchronous waiting, using Hystrix for fault isolation and fuse mechanism can solve the problem of unavailable dependent services.
Flow control Specific measures include:
-
Gateway current limiting
-
User interaction current limiting
-
Close retry
Because of the high performance of Nginx, a large number of first-line Internet companies use the gateway of Nginx+Lua for flow control, and the resulting OpenResty is becoming more and more popular
The specific measures of user interaction current limiting are as follows: 1. Loading animation is adopted to improve the user's patient waiting time. 2. The submit button adds a forced waiting time mechanism
Improved cache mode Measures include:
-
Cache preload
-
Synchronous to asynchronous refresh
Service caller downgrade service Measures include:
-
Resource isolation
-
Classify dependent services
-
Call to unavailable service failed quickly
Resource isolation is mainly used to isolate the thread pool calling the service
Service avalanche process
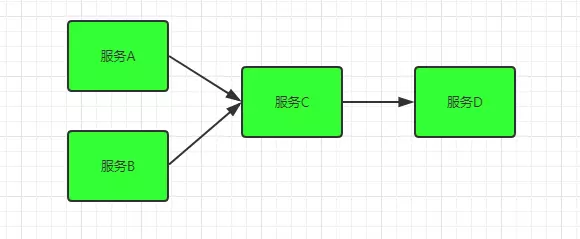
A set of simple service dependencies. Services a and B depend on Basic Service C at the same time, and basic service C calls service D
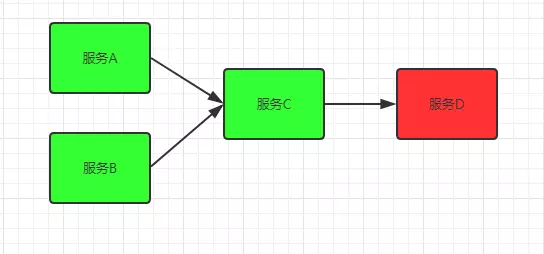
Service d is an auxiliary type service. The whole business does not depend on service D. one day, service d suddenly has A longer response time, resulting in A longer response time of core service C, more and more requests on it, and A slower response of service C. because A and B strongly depend on Service C, an insignificant service affects the availability of the whole system.
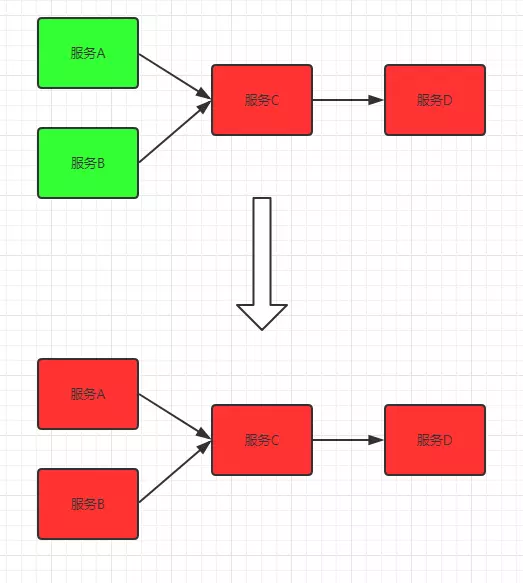
It affects the whole system
Avalanche is the butterfly effect in the system, which is caused by various reasons, such as unreasonable capacity design, slow response of a method under high concurrency, or resource depletion of a machine. It is impossible to completely eliminate the occurrence of avalanche from the source, but the root cause of avalanche comes from the strong dependence between services, so it can be evaluated in advance and fuse, isolate and limit current.
Fuse
I think of Hystrix for the first time. Let's look at the implementation principle of fuse
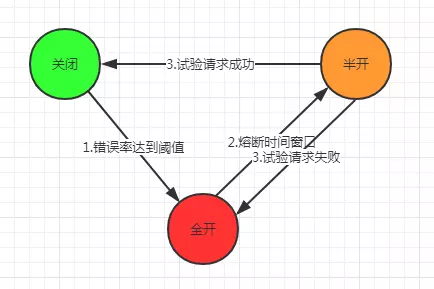
Health of service = number of failed requests / total number of requests,
The fuse is actually a simple finite state machine
1. When the request error rate reaches a certain threshold, the fuse is fully opened, resulting in fusing (all requests will be degraded during fusing) 2. After reaching the fusing time window, the fuse will enter the half open state. At this time, hystrix will miss one experimental request 3. If the test request is successful, the fuse will enter the closed state 4. If the test request fails, the fuse will re-enter the fully open state
hystrix official documents
1.Assuming the volume across a circuit meets a certain threshold (HystrixCommandProperties.circuitBreakerRequestVolumeThreshold())... 2.And assuming that the error percentage exceeds the threshold error percentage (HystrixCommandProperties.circuitBreakerErrorThresholdPercentage())... 3.Then the circuit-breaker transitions from CLOSED to OPEN. 4.While it is open, it short-circuits all requests made against that circuit-breaker. 5.After some amount of time (HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds()), the next single request is let through (this is the HALF-OPEN state). If the request fails, the circuit-breaker returns to the OPEN state for the duration of the sleep window. If the request succeeds, the circuit-breaker transitions to CLOSED and the logic in 1. takes over again.
Resource isolation
The separate design of the cabin itself is an idea of isolation. The water in A waterproof silo will not cause the whole ship to sink. If the whole system is compared to A ship floating on the sea, each service of the system is like each sealed cabin on the ship. If service A strongly depends on service B, they are in one cabin
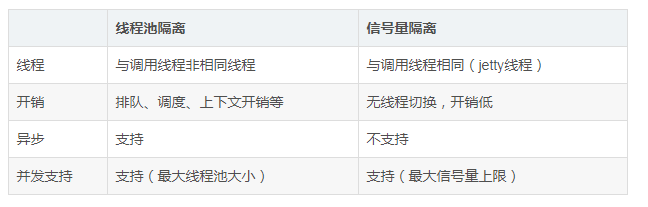
The application domain isolation means include wired process pool isolation, semaphore isolation, connection pool isolation, and hystrix to realize the first two. Their advantages and disadvantages are as follows
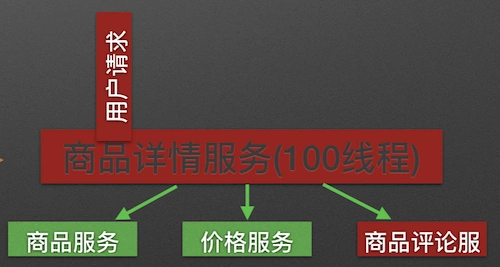
In a highly service-oriented system, a business logic implemented usually depends on multiple services, such as: The commodity detail display service will rely on Commodity services, price services and commodity review services, as shown in the figure:
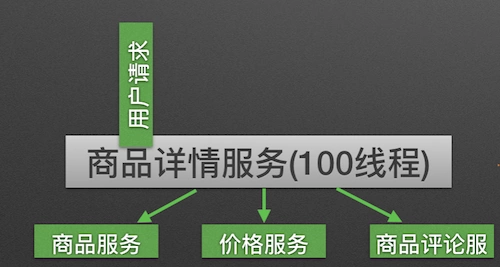
Calling three dependent services will share the thread pool of the commodity detail service. If the commodity comment service is unavailable, all threads in the thread pool will be blocked due to waiting for a response, resulting in a service avalanche. As shown in the figure:
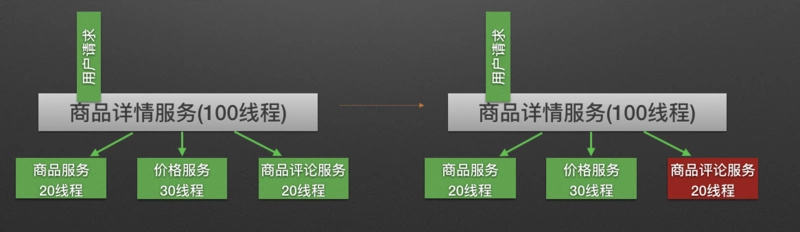
Hystrix avoids service avalanche by allocating independent thread pool for resource isolation
As shown in the figure below, when the commodity comment service is unavailable, even if all 20 threads independently allocated by the commodity service are in the synchronous waiting state, the call of other dependent services will not be affected
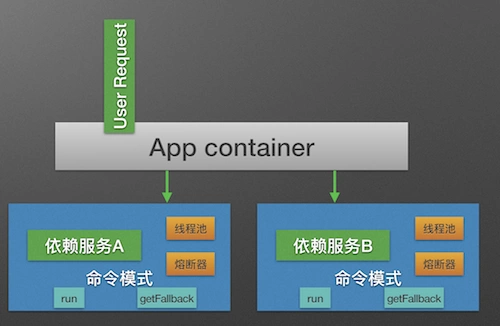
Command mode
Hystrix uses the command mode (inheriting the HystrixCommand class) to wrap the specific service call logic (run method), and adds the degradation logic after service call failure (getFallback) to the command mode
Meanwhile, in the construction method of Command, you can define the relevant parameters of the current service thread pool and fuse. The following code is shown:
public class Service1HystrixCommand extends HystrixCommand<Response> {
private Service1 service;
private Request request;
public Service1HystrixCommand(Service1 service, Request request){
supper(
Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ServiceGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("servcie1query"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("service1ThreadPool"))
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(20))//Number of service thread pools
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withCircuitBreakerErrorThresholdPercentage(60)//Fuse closed to open threshold
.withCircuitBreakerSleepWindowInMilliseconds(3000)//Length of time window from fuse opening to closing
))
this.service = service;
this.request = request;
);
}
@Override
protected Response run(){
return service1.call(request);
}
@Override
protected Response getFallback(){
return Response.dummy();
}
}Hystrix has two request commands: HystrixCommand and hystrixobservercommand.
HystrixCommand is used when the dependent service returns a single operation result. There are two other ways of execution
- execute(): execute synchronously. Return a single result object from the dependent service, or throw an exception when an error occurs.
- queue(); Asynchronous execution. Directly return a Future object, which contains a single result object to be returned at the end of service execution.
public class CommandHelloWorld extends HystrixCommand<String> {
private String name;
public CommandHelloWorld(String name) {
super(HystrixCommandGroupKey.Factory.asKey("HelloGroup"));
this.name = name;
}
@Override
protected String run() throws Exception {
return "Hello " + name;
}
/**
* Downgrade. When there are errors, timeouts, thread pool rejections, circuit breakers blown, etc. during the execution of run(), Hystrix will,
* Execute the logic within the getFallBack() method
*/
@Override
protected String getFallback() {
return "fail";
}
}Test:
/**
* Synchronous execution
*/
@Test
public void testHystrixCommand() {
CommandHelloWorld commandHelloWorld = new CommandHelloWorld("world");
String result = commandHelloWorld.execute();
log.info("------{}--------", result);
}
/**
* Asynchronous execution
*/
@Test
public void testHystrixAysncCommand() throws ExecutionException, InterruptedException {
CommandHelloWorld commandHelloWorld = new CommandHelloWorld("world");
log.info("{}", commandHelloWorld.queue().get());
}
/**
* HystrixCommand It has the functions of observe() and toObservable(), but its implementation has certain limitations,
* * The Observable returned by it can only transmit data once, so the Hystrix also provides the Hystrix Observable command,
* * The commands implemented through it can obtain Observable that can be sent multiple times
*/
@Test
public void testObserve() {
/**
* Hot observable is returned, regardless of whether the "event source" has a "Subscriber"
* The event will be published after creation. Therefore, for each "Subscriber" of Hot Observable
* It may start in the middle of the "event source" and may only see the local process of the whole operation
*/
Observable<String> observe = new CommandHelloWorld("World").observe();
// log.info("{}", observe.toBlocking().single()); // synchronization
observe.subscribe(new Observer<String>() {
@Override
public void onCompleted() {
log.info("==========completed============");
}
@Override
public void onError(Throwable e) {
e.printStackTrace();
}
@Override
public void onNext(String s) {
log.info("======{}=========", s);
}
});
observe.subscribe(new Action1<String>() {
@Override
public void call(String s) {
log.info("=========={}", s);
}
});
}
@Test
public void testToObservable() {
/**
* Cold Observable When there is no "Subscriber", the time will not be published,
* Instead, wait until you know that there are "subscribers" before publishing events, so for
* Cold Observable It can ensure to see the whole process of the whole operation from the beginning.
*/
Observable<String> observable = new CommandHelloWorld("World").toObservable();
log.info(observable.toBlocking().single());
}Annotation method
@Service
public class UserService {
@HystrixCommand(fallbackMethod = "helloFallback")
public String getUserById(String name) {
return "hello " + name;
}
public String helloFallback(String name) {
return "error " + name;
}
@HystrixCommand(fallbackMethod = "getUserNameError")
public Future<String> getUsername(Long id) {
AsyncResult<String> asyncResult = new AsyncResult<String>() {
@Override
public String invoke() {
return "name " + id;
}
};
return asyncResult;
}
public String getUserNameError(Long id) {
return "failed";
}
}
test
@Test
public void testGetUserById() throws ExecutionException, InterruptedException {
log.info("==========={}", userService.getUserById("Clearly"));
log.info("-----------{}", userService.getUsername(0000007L).get());
}The hystrixobservable command is used when the dependent service returns multiple operation results. Two execution modes are realized
- observe(): returns an observable object, which represents multiple results of the operation. It is a HotObservable object
- toObservable(): it also returns an Observable object, which also represents multiple results of the operation, but it returns a Cold Observable.
The logic of HystrixCommand is in run. The logic of HystrixObservableCommand is in construct. The observe method triggers run in a non blocking way, that is, a new thread executes run, while triggering construct is in a blocking way, that is, calling a thread to execute construct. The toObserve method itself will not trigger the run or construct method, but will trigger the run or construct method when subscribing. The trigger method is the same as observe. For run, the new thread is non blocking, and for construct, the calling thread is blocking.
observe will execute run or construct whether there are subscribers or not. toObserve will execute run or construct methods only when there are subscribers.
public class ObservableCommandHelloWorld extends HystrixObservableCommand<String> {
private String name;
public ObservableCommandHelloWorld(String name) {
super(HystrixCommandGroupKey.Factory.asKey("observableGroup"));
this.name = name;
}
@Override
protected Observable<String> construct() {
return Observable.create(new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> subscriber) {
if (!subscriber.isUnsubscribed()) {
subscriber.onNext("Hello ");
subscriber.onNext("Name ");
subscriber.onCompleted();
}
}
}).subscribeOn(Schedulers.io());
}
@Override
protected Observable<String> resumeWithFallback() {
return Observable.create(new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> subscriber) {
try {
if (!subscriber.isUnsubscribed()) {
subscriber.onNext("Failed!");
subscriber.onCompleted();
}
} catch (Exception e) {
subscriber.onError(e);
}
}
}).subscribeOn(Schedulers.io());
}
}
test
@Test
public void testObservable() {
Observable<String> observable = new ObservableCommandHelloWorld("World").observe();
Iterator<String> iterator = observable.toBlocking().getIterator();
while (iterator.hasNext()) {
log.info("--" + iterator.next());
}
}
Annotation method
@Service
public class ObservableUserService {
/**
* EAGER Parameter indicates that the execution is performed using observe()
*/
@HystrixCommand(observableExecutionMode = ObservableExecutionMode.EAGER, fallbackMethod = "observFailed") //Execute using observe()
public Observable<String> getUserById(final Long id) {
return Observable.create(new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> subscriber) {
try {
if(!subscriber.isUnsubscribed()) {
subscriber.onNext("Zhang San's ID:");
int i = 1 / 0; //Throw exceptions and simulate service degradation
subscriber.onNext(String.valueOf(id));
subscriber.onCompleted();
}
} catch (Exception e) {
subscriber.onError(e);
}
}
});
}
private String observFailed(Long id) {
return "observFailed---->" + id;
}
/**
* LAZY The parameter indicates that it is executed in toObservable() mode
*/
@HystrixCommand(observableExecutionMode = ObservableExecutionMode.LAZY, fallbackMethod = "toObserbableError") //Indicates the execution mode using toObservable()
public Observable<String> getUserByName(final String name) {
return Observable.create(new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> subscriber) {
try {
if(!subscriber.isUnsubscribed()) {
subscriber.onNext("find");
subscriber.onNext(name);
int i = 1/0; Throw exceptions and simulate service degradation
subscriber.onNext("Yes");
subscriber.onCompleted();
}
} catch (Exception e) {
subscriber.onError(e);
}
}
});
}
private String toObserbableError(String name) {
return "toObserbableError--->" + name;
}
}After the service object is built using Command mode, the service has the function of fuse and thread pool