Overall reference: Paddleocr 2.3 - Documentation tutorial
You must see the first three steps and ask for them on demand
one 🎨 environment
If the cuda version of this machine is not very satisfied with the image requirements of paddlepaddle, you can consider creating a cpu version. It wouldn't be that complicated.
For example: docker pull paddlepaddle/paddle:2.1.2
reference resources: Operation environment preparation
Use the CPU version of paddlepaddle2.1, which can be used to try ppstructure.
docker run -it -d --ipc=host -p 8507:8501 -v /ws/huangshan/paddle21:/paddle21 --name "paddle2.1" paddlepaddle/paddle:2.1.2 bash -c "/etc/rc.local; /bin/bash"
However, it is found that the pure cpu version is still slow. Consider using the gpu version. It will be faster. Even if the version is a little older, it doesn't matter,
After a second thought, I looked at the mirror Library of paddlepaddle. paddlepaddle hub
The following image is selected, which looks more appropriate:

# Download basic image docker pull paddlepaddle/paddle:2.0.2-gpu-cuda11.0-cudnn8
But although this thing looks like 8.82GB, it will be 30G after decompression???? If it's so large, you'd better use the old image of the previous version - paddlepaddle/paddle:2.0.1-gpu-cuda11.0-cudnn8
# Run a container docker run -it -d --gpus "device=4" --ipc=host -p 8508:8501 -v /ws/huangshan/paddle21:/paddle21 --name "paddle_gpu" paddlepaddle/paddle:2.0.1-gpu-cuda11.0-cudnn8 bash -c "/etc/rc.local; /bin/bash"
For the command writing method of running the container here, please refer to: 1) Deploy tensorflow, pytorch and other environments on linux server with docker Use container section in.
If you want to close a previously repeated container and delete it, you can
docker ps -a|grep paddle docker stop container ID docker rm container ID docker rmi image ID
- Note that the mirror used by paddleocr is the mirror of PaddlePaddle, so if you use the docker mirroring mode, the image comes with PaddlePaddle, but if the version does not match, you may need to upgrade it.
- In addition, you need to git clone or pip install the paddleocr related content.
two 💌 use
- PaddlePaddle has been packaged with the git command in the default mirror, so it can be executed directly.
pip install "paddleocr==2.2" -i https://pypi.tuna.tsinghua.edu.cn/simple # ✅ If you use the old 2.0.1 image, there is a python 2.7 version by default, so you need to specify the python version # Check it out. It's all available from Python 3.5-3.8.. pip3.7 install paddleocr -i https://pypi.tuna.tsinghua.edu.cn/simple # In addition, streaming is required for serving pip3.7 install streamlit -i https://pypi.tuna.tsinghua.edu.cn/simple # The following part can be omitted if you don't train git clone https://github.com/PaddlePaddle/PaddleOCR cd PaddleOCR pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # You'd better add Tsinghua mirror, otherwise it will be very slow
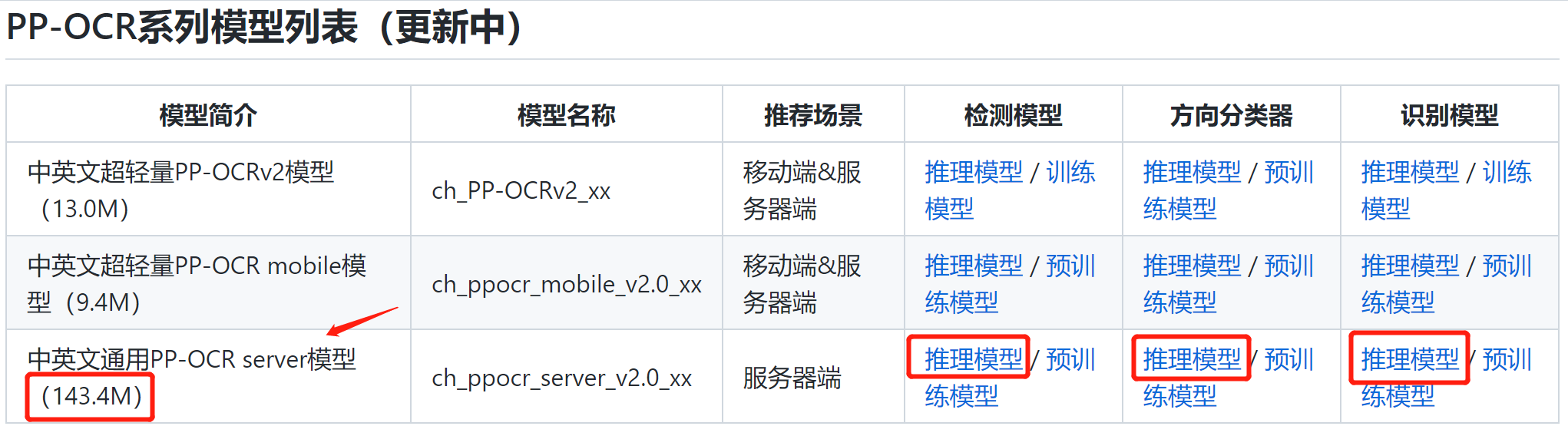
2.1 select an appropriate reasoning model
Consider two points:
- On the server, so the model can be larger
- Choose the latest
So in the document PP-OCR series model list (under update) In, the Server-side model is selected, in which the three models of detection + direction Classifier + recognition are 143.4MB in total
Download link:
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar
Alternatively, you can use the command to download to the server, unzip and delete the compressed package, similar to the following
cd PaddleOCR/ # Download the pre training model of MobileNetV3 wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar # Decompress model parameters cd pretrain_models tar -xf ch_ppocr_server_v2.0_rec_infer.tar && rm -rf ch_ppocr_server_v2.0_rec_infer.tar
Note: in addition, among the three files, three hidden files are generated after the rec file is decompressed. The file is very small, but it may be a little uncomfortable and will not be affected.
In addition, if you want to try the wheel of ppocr to use the above model as a user-defined model for reasoning, you also need to specify the corresponding character dictionary file. In here find

The configuration file yml will contain the dictionary file. If found, it is ppocr/utils/ppocr_keys_v1.txt, copy one to the appropriate location.
2.2 some useful points of paddleocr reasoning wheel
Refer to the user documentation for the wheel package of paddleocr: paddleocr package instructions
1. Parameter part
Confirm that the user-defined model can be used, as long as the path is specified.
First, ensure the basic running. At the same time, the model should be read from its own blob storage area at the remote end. Mainly observe the parameters of the model:
Namespace(benchmark=False, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./pretrain_models/ch_ppocr_server_v2.0_cls_infer', cls_thresh=0.9, cpu_threads=10, det=True, det_algorithm='DB', det_db_box_thresh=0.5, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.6, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./pretrain_models/ch_ppocr_server_v2.0_det_infer', det_sast_nms_thresh=0.2, det_sast_polygon=False, det_sast_score_thresh=0.5, drop_score=0.5, enable_mkldnn=False, gpu_mem=500, help='==SUPPRESS==', image_dir=None, ir_optim=True, label_list=['0', '180'], lang='ch', layout_path_model='lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config', max_batch_size=10, max_text_length=25, min_subgraph_size=10, output='./output/table', precision='fp32', process_id=0, rec=True, rec_algorithm='CRNN', rec_batch_num=6, rec_char_dict_path='./pretrain_models/ppocr_keys_v1.txt', rec_char_type='ch', rec_image_shape='3, 32, 320', rec_model_dir='./pretrain_models/ch_ppocr_server_v2.0_rec_infer', save_log_path='./log_output/', show_log=True, table_char_dict_path=None, table_char_type='en', table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=True, use_mp=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=True)
Among them,
- use_angle_cls indicates whether to load the classification model
- Whether to start classification in CLS forward (use_angle_cls in command line mode to control whether to start classification in CLS forward)
2 received image format
It can receive numpy format, path mode or http format. For details, see line 309 of paddleocr.py file:
def ocr(self, img, det=True, rec=True, cls=True):
"""
ocr with paddleocr
args:
img: img for ocr, support ndarray, img_path and list or ndarray
det: use text detection or not, if false, only rec will be exec. default is True
rec: use text recognition or not, if false, only det will be exec. default is True
"""
assert isinstance(img, (np.ndarray, list, str))
if isinstance(img, list) and det == True:
logger.error('When input a list of images, det must be false')
exit(0)
if cls == True and self.use_angle_cls == False:
logger.warning(
'Since the angle classifier is not initialized, the angle classifier will not be uesd during the forward process'
)
if isinstance(img, str):
# download net image
if img.startswith('http'):
download_with_progressbar(img, 'tmp.jpg')
img = 'tmp.jpg'
image_file = img
img, flag = check_and_read_gif(image_file)
if not flag:
with open(image_file, 'rb') as f:
np_arr = np.frombuffer(f.read(), dtype=np.uint8)
img = cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
if img is None:
logger.error("error in loading image:{}".format(image_file))
return None
if isinstance(img, np.ndarray) and len(img.shape) == 2:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
3. Returned result format
Previously:
[[[24.0, 36.0], [304.0, 34.0], [304.0, 72.0], [24.0, 74.0]], ['Pure nutritional conditioner', 0.964739]] [[[24.0, 80.0], [172.0, 80.0], [172.0, 104.0], [24.0, 104.0]], ['Product information/parameter', 0.98069626]] [[[24.0, 109.0], [333.0, 109.0], [333.0, 136.0], [24.0, 136.0]], ['(45 element/Per kilogram (from 100kg)', 0.9676722]] ......
Now it is changed to:
result:
(
[array([[213., 166.],[289., 169.],[288., 194.],[212., 191.]], dtype=float32),
array([[212., 539.],[262., 539.],[262., 566.],[212., 566.]], dtype=float32), array([[305., 584.],[419., 584.],[419., 624.],[305., 624.]], dtype=float32)], [('PM2.5', 0.93844336), ('QUANJISHOU', 0.9994316), ('15℃', 0.88811713)]
)
A tuple. The first element of the tuple is a list composed of coordinate array, and the second element is a list composed of predicted value + score.
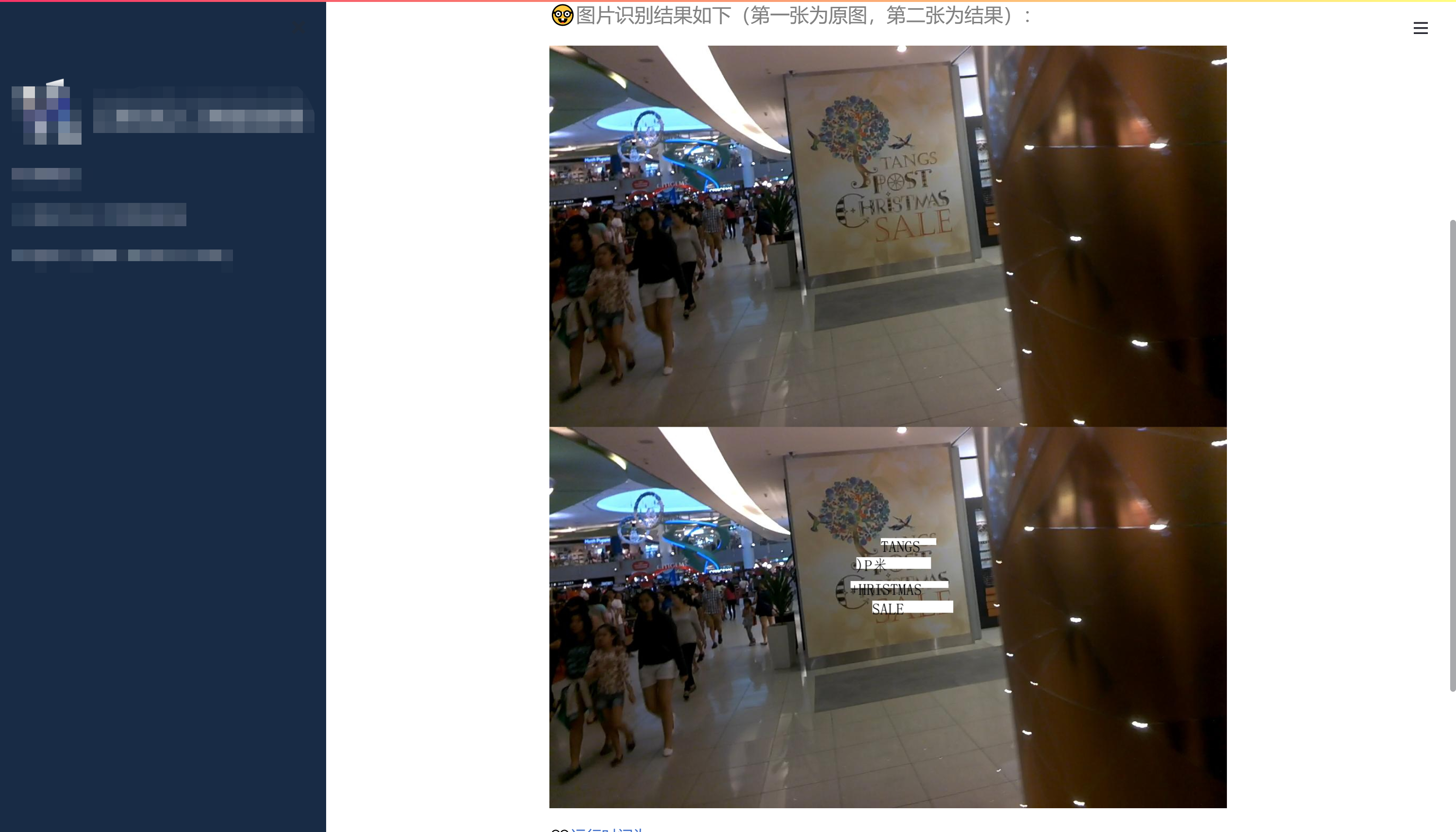
2.3 display with addWeighted
In addition, because the default display mode is as follows, it's too ugly, so change it.
Anyway, the coordinates of the content will be returned in the end, which can be drawn nearby. Or consider displaying the original image and displaying the image where the recognized characters cover the original position, and merging the two together for display.
reference resources: opencv_document-addWeighted()
oid cv::addWeighted ( InputArray src1, double alpha, InputArray src2, double beta, double gamma, OutputArray dst, int dtype = -1 ) Python: cv.addWeighted( src1, alpha, src2, beta, gamma[, dst[, dtype]] ) -> dst
Parameters
src1 first input array.
array of the first input image
alpha weight of the first array elements.
Weight of the first input image
src2 second input array of the same size and channel number as src1.
The second input image needs to be the same size and channel as the first image
beta weight of the second array elements.
The weight of the second input image, beta+alpha=1
gamma scalar added to each sum.
dst output array that has the same size and number of channels as the input arrays.
dtype optional depth of the output array; when both input arrays have the same depth, dtype can be set to -1, which will be equivalent to src1.depth().
2.4 putText of OpenCV does not support Chinese
putText Function Description: opencv official document - putText()
The problem here is that the font base is based on fontscale: font scale factor that is multiplied by the font specific base size
Because opencv does not support Chinese, most online solutions are converted to pilot Image for operation. Refer to: OpenCV add Chinese (V)
For example:
# format conversion
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# Draw with PIL
draw = ImageDraw.Draw(img)
fontText = ImageFont.truetype("font/simsun.ttc", textSize, encoding="utf-8")
draw.text((left, top), "Text content", textColor, font=fontText)
# Back to opencv
cv2.cvtColor(numpy.asarray(img), cv2.COLOR_RGB2BGR)
However, because I have a little more content to draw, this method is not very convenient. Search shows that PIL can also draw quadrangles, fill them, and set transparency.
However, due to the poor display effect of filling color and font color in cv2, it is not applicable to cv2 at all. PIL is used for drawing, including text and rectangle, for example:
from PIL import Image,ImageDraw,ImageFont
pil_img=Image.fromarray(cv2.cvtColor(label_img, cv2.COLOR_BGR2RGB))
text_size=30
fontText = ImageFont.truetype("./simfang.ttf", text_size, encoding="utf-8")
draw = ImageDraw.Draw(pil_img)
draw.rectangle((box[0][0],box[0][1],box[2][0],box[2][1]),"white","white")
draw.text((left, top), txt, (0,0,0), font=fontText)
Draw rectangular reference: [python image processing] geometric drawing and text drawing (detailed explanation of ImageDraw class)
reference resources:
- Introduction to the ImageDraw module of Python image processing library PIL
- How does python's pilot fill translucent colors with ImageDraw.Draw.polygon
- Python Pilot Library ImageDraw drawing image module
- Pillow v2.4.0 (PIL fork)
Finally, the effect is as follows:

4. Web display combined with streamlit
streamlit runs the script and passes parameters at the same time. Refer to:
Since the port mapping (8508:8501) is set when running the container, you can directly:
streamlit run test_ppocr.py
Then you can directly access the host URL of docker: port 8508
For the time being, the running script of streamlit and passing parameters are not considered. The model path is written directly. The final effect is similar to: