Online Process Recording for Network Deployment
Take the example of recommending similar items: reco-similar-product
Project Directory
Dockerfile Jenkinsfile README.md config deploy.sh deployment.yaml index offline recsys requirements.txt service stat
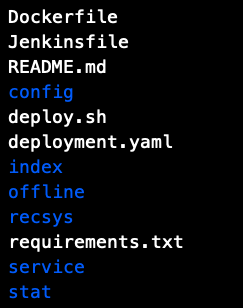
You can see that there are many files in the directory. Here is a brief description of the role of each directory:
- Dockerfile: Docker deployment script;
- Jenkinsfile: Jenkinsfile is a text file that contains the definition of the Jenkins pipeline and is checked into the source code control repository;
- README.md: Project introduction;
- config: The location where the configuration file is stored;
- deploy.sh: A script deployed on a Docker;
- deployment.yaml:k8-s configuration file;
- Index: The location where the index data is stored, which is used for ctr smoothing;
- Offline: code for the offline part;
- recsys: store some generic call modules
- requirements.txt: The package on which the project depends;
- service: code for the server section;
- stat: Related statistics script
Detailed introduction
Dockerfile
FROM tools/python:3.6.3 ADD . /usr/local/reco_similar_product_service WORKDIR /usr/local/reco_similar_product_service EXPOSE 5001 # build image RUN mkdir -p /data/reco_similar_product_service/log RUN bash deploy.sh build # launch image CMD bash deploy.sh launch
- from tools/python:3.6.3: Get Python image package from here
- ADD. /usr/local/reco_similar_product_service:The function of the ADD directive is to copy files and directories in the host build environment (context) directory and a URL tagged file into the mirror.Put the file in this file
- WORKDIR/usr/local/reco_similar_product_service: Specify working directory
- EXPOSE 5000: Expose port number, declare port
- RUN mkdir-p/data/algoreco_simproduct_service/log: Set the log file address to match the log location below
- RUN bash deploy.sh build: Call deploy.sh deployment
- CMD bash deploy.sh launch: boot mirror
Jenkinsfile
node('jenkins-jnlp') { stage("Clone") { checkout scm } stage("Tag") { script { tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim() } } stage("Push Docker Image") { sh "sed -i 's@TAG@${tag}@g' deployment.yaml" withDockerRegistry(credentialsId: '', url: '') { sh "docker build -t reco-similar-product:${tag} ." sh "docker push reco-similar-product:${tag}" } } stage("Deployment") { sh "kubectl apply -f deployment.yaml" } }
These are a couple of Jenkins pipelining processes, cloning a specific revision (Clone), getting tag s, creating mirrors, uploading local mirrors to a mirror repository (push), and changing resource application configurations for files or standard input streams (Deployment)
- Jenkins-jnlp: There are approximately two types of Agents for Jenkins.First, based on SSH, the SSH public key of Master needs to be configured on all Agent hosts.Second, based on JNLP, each agent needs to configure a unique password following the HTTP protocol.
- Stage ('Clone'): The stage directive takes place in the stages section and should contain a fact that all the actual work done by a flow lane is encapsulated in one or more stage directives.
- Checkout scm: The checkout step will check out code from source code control; SCM is a special variable that instructs the checkout step to clone a specific revision that triggers pipelining;
- docker build and docker push: create and upload mirrors
- kubectl apply -f deployment.yaml: change resource application configuration on file or standard input stream
deploy.sh
#!/bin/bash # Dependencies in $PATH (in base docker image): # - python 3.6.3 # - pip for this python build() { # prepare env if there's no docker # ENV_DIR="venv" # pip install virtualenv # virtualenv --no-site-packages $ENV_DIR # source $ENV_DIR/bin/activate pip install -r requirements.txt \ -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com python setup.py build_ext --inplace } launch() { # start web container cd service/ bash run.sh start } if [ x"$1" == "xbuild" ]; then echo "build" build fi if [ x"$1" == "xlaunch" ]; then echo "launch" launch
- build: Install the corresponding dependent packages;
- launch: Start the service;
deployment.yaml
apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: k8s-app: reco-similar-product-dev name: reco-similar-product-dev namespace: dev spec: minReadySeconds: 5 strategy: type: RollingUpdate rollingUpdate: maxSurge: 25% maxUnavailable: 25% replicas: 1 selector: matchLabels: k8s-app: reco-similar-product-dev template: metadata: labels: k8s-app: reco-similar-product-dev spec: serviceAccountName: dev nodeSelector: environment: dev imagePullSecrets: - name: dev containers: - name: reco-similar-product-dev image: develop/reco-similar-product:TAG env: - name: RECO_SIM_TEST value: "1" ports: - containerPort: 5000 protocol: TCP volumeMounts: - name: reco-similar-product-dev-log subPath: reco-similar-product-dev-log mountPath: /data/reco_similar_product_service/log securityContext: fsGroup: 1000 volumes: - name: reco-similar-product-dev-log persistentVolumeClaim: claimName: dev-logs --- kind: Service apiVersion: v1 metadata: labels: k8s-app: reco-similar-product-dev name: reco-similar-product-dev namespace: dev spec: ports: - port: 5000 targetPort: 5000 selector: k8s-app: reco-similar-product-dev
- dev: represents the test environment
- Port: port number
- app: service name
- mountPath: Log file path
config
This directory mainly stores some configuration files such as database, path configuration, etc.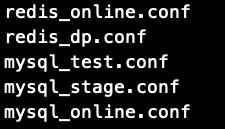
recsys
Place some generic modules, such as the basic module: the database connection module, etc., where the core processing logic code of the server can also be placed
offline
Offline part of the code, mainly the main logic part of the service function code.For recommending similar items, it is to generate the corresponding data and write it to the table.The purpose of the code is to process the data, compute offline to get a result, and write the result to the database.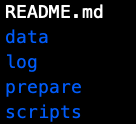
#!/usr/bin/env python # fileUsing: reco some pid from sale's pids # retrieve pids by cv feature # filt by type, alive import os import sys import oss2 import json import yiss import numpy as np from operator import itemgetter from datetime import datetime MODULE_REAL_DIR = os.path.dirname(os.path.realpath(__file__)) DATA_PATH = MODULE_REAL_DIR + '/../data' CONFIG_PATH = '../../../config/' class SearchItem(): def __init__(self, feat=None, pid=None, p_type=None, score=None): ''' create item struct every pid contain: feat: cv feature pid: product id p_type: type score: similar score ''' self.feat = feat self.pid = pid self.p_type = p_type self.score = score class ImgSearch(SearchItem): def __init__(self): ''' retrieve mode: ANN: Approximate Nearest Neighbor ''' # prepare cv feature dataset self.product_feature = {} feature_path = DATA_PATH + '/product_cv_feature.json' with open(feature_path, 'r') as f: for line in f: pid, _, feat = line.rstrip('\n').split('\t') self.product_feature[int(pid)] = json.loads(feat) # change key type into int # -> init build index and save index <- self.index = yiss.VectorIndex( data_file=feature_path, series='IDMap, Flat', suff_len=1, search_width=1) self.index.init(save_file=MODULE_REAL_DIR + '/../data/vector.index') # init ImageUtils self.ImgUtil = yiss.ImageUtils(CONFIG_PATH + '/config.json') # load tags: type, alive, color tag_path = DATA_PATH + "/pid_tags" self.pid_type = {} self.pid_alive = {} with open(tag_path, 'r') as f: for line in f: pid, type_top_id, is_alive = line.rstrip('\n').split('\t') self.pid_type[pid] = type_top_id self.pid_alive[pid] = is_alive # init retrieve length self.RETRIEVE_LEN = 1000 # init table length self.TABLE_LEN = 64 def retrieve(self, input_item): """ search similar feature pids by faiss """ similar_items = [] if input_item.feat == []: return similar_items # no feat, could not compare feat = np.array([input_item.feat.tolist()]) feat = feat.astype(np.float32) # change feat into the faiss needed type ds, ids = self.index.knn_search(feat, self.RETRIEVE_LEN) for pid, distance in zip(ids, ds): if pid != str(input_item.pid): # ignore itself similar_items.append({"pid": pid, "score": round(distance, 4)}) return sorted(similar_items, key=lambda e: e.__getitem__('score')) def build_item(self, pid): feat = np.array(self.product_feature[pid]) if pid in self.product_feature else [] pid = str(pid) # pid type and color dict key type is <string> pid_type = self.pid_type[pid] if pid in self.pid_type else self.ImgUtil.get_type_id(pid) return SearchItem(feat, int(pid), pid_type) def filter_pid(self, input_item, retrieve_items): """ filter by type, alive """ match_result = [] not_match_result = [] finally_match_result = [] input_pid = input_item.pid input_type = input_item.p_type for item in retrieve_items: pid, score = str(item["pid"]), item["score"] # change pid type from int into string p_type = self.pid_type[pid] if pid in self.pid_type else\ self.ImgUtil.get_type_id(pid) p_alive = self.pid_alive[pid] if pid in self.pid_alive else "0" item = {"pid": int(pid), "score": score, "path": "sVSM"} if p_alive == "1": if input_type == p_type: match_result.append(item) if len(match_result) >= self.TABLE_LEN: return match_result finally_result = match_result return finally_result[:self.TABLE_LEN] def search(self, pid): """ main function, input pid and search similar pids """ pid = int(pid) # build input item pid_item = self.build_item(pid) # print("pid item:", pid_item.pid, pid_item.p_type, pid_item.feat) if len(pid_item.feat) == 0: # feat is null, ignore this pid return [] # retrieve retrieve_item = self.retrieve(pid_item) # filter by some condition match_result = self.filter_pid(pid_item, retrieve_item) return match_result if __name__ == "__main__": img_search = ImgSearch() pid = sys.argv[1] match_result = img_search.search(pid) if len(match_result) > 0: match_result_pid = [int(item["pid"]) for item in match_result] print(match_result_pid)
Ann is recalled here based on feature similarity, filtered by category, and saved.Upload the results to the database.
service
Service End Directory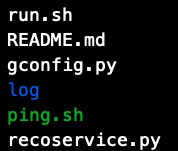
- gconfig.py:gunicorn configuration file
- recoservice.py: Use flask to provide online service interfaces
- run.sh: Start or shut down services
- ping.sh:
gconfig.py :
import multiprocessing bind = '0.0.0.0:5001' # Bind ip and port number daemon = False debug = False worker_class = 'sync' workers = multiprocessing.cpu_count() # Number of processes pidfile = 'project.pid' log_path = "/data/algoreco_simproduct_service/log/" # Log files are guaranteed to be in the same location as before timeout = 300 graceful_timeout = 300 # http://docs.gunicorn.org/en/stable/settings.html access_log_format = '%(h)s %(l)s %(u)s %(t)s "%(r)s" %(s)s %(b)s "%(f)s" "%(a)s" "%({xff}i)s"' logconfig_dict = { 'version': 1, 'disable_existing_loggers': False, 'loggers': { "gunicorn.error": { "level": "INFO", "handlers": ["error_file"], "propagate": 0, "qualname": "gunicorn.error" }, "gunicorn.access": { "level": "INFO", "handlers": ["access_file"], "propagate": 0, "qualname": "gunicorn.access" } }, 'handlers': { "error_file": { "class": "cloghandler.ConcurrentRotatingFileHandler", "maxBytes": 1024 * 1024 * 1024, "backupCount": 5, "formatter": "generic", "filename": log_path + "gunicorn_error.log", }, "access_file": { "level": "INFO", "handlers": ["access_file"], "propagate": 0, "qualname": "gunicorn.access" } }, 'handlers': { "error_file": { "class": "cloghandler.ConcurrentRotatingFileHandler", "maxBytes": 1024 * 1024 * 1024, "backupCount": 5, "formatter": "generic", "filename": log_path + "gunicorn_error.log", }, "access_file": { "class": "cloghandler.ConcurrentRotatingFileHandler", "maxBytes": 1024 * 1024 * 1024, "backupCount": 5, "formatter": "generic", "filename": log_path + "gunicorn_access.log", } }, 'formatters': { "generic": { "format": "%(asctime)s [%(process)d] %(levelname)s" + " [%(filename)s:%(lineno)s] %(message)s", "datefmt": "[%Y-%m-%d %H:%M:%S]", "class": "logging.Formatter" }, "access": { "format": "[%(asmidnighttime)s] [%(process)d] %(levelname)s" + " [%(filename)s:%(lineno)s] %(message)s", "class": "logging.Formatter" } } }
- worker_class: worker process type, sync (default), eventlet, gevent, or tornado, gthread, gaiohttp;
- workers: Number of worker processes, generally recommended is: (2 x $num_cores) + 1
- log-level LEVEL: Output error log granularity, valid LEVEL are: debug, info, warning, error, critical
recoservice.py :
import logging import json from flask import Flask, Response, request from recsys.sale.reco import RecoSaleSim from recsys.base.exception import ClientException from recsys.base.recologging import HeartBeatFilter app = Flask(__name__) class RecoSimSvr(): def __init__(self): self.SUCCESS_CODE = 200 self.CLIENT_ERROR_CODE = 400 self.SERVER_ERROR_CODE = 500 # init recsys module self.rss = RecoSaleSim() app.logger.info('Init done.') def get_recos(self): error_results = {} results = {} try: pid = request.args.get('productId', type=int) if not pid: raise ClientException('Param missing: productId') uid = request.args.get('uid', type=int) if not uid: raise ClientException('Param missing: uid') device_id = request.args.get('deviceId', type=str) if not device_id: raise ClientException('Param missing: deviceId') reco_len = request.args.get('maxLength', type=int, default=16) reco_items = self.rss.get_reco_items(pid, reco_len) # Output response results['data'] = reco_items results['code'] = self.SUCCESS_CODE results['msg'] = 'Success' return Response(json.dumps(results), status=200, mimetype='application/json') except ClientException as err: app.logger.error(str(err), exc_info=True) error_results['code'] = self.CLIENT_ERROR_CODE error_results['msg'] = str(err) return Response(json.dumps(error_results), status=400, mimetype='application/json') except Exception as err: app.logger.error(str(err), exc_info=True) error_results['code'] = self.SERVER_ERROR_CODE error_results['msg'] = 'Program error!' return Response(json.dumps(error_results), status=500, mimetype='application/json') def check_alive(self): results = {} results['code'] = 200 results['msg'] = 'I\'m Sale Similar Reco' return Response(json.dumps(results), status=200, mimetype='application/json') # setup logger gunicorn_access_logger = logging.getLogger('gunicorn.access') gunicorn_access_logger.addFilter(HeartBeatFilter()) app.logger.handlers = gunicorn_access_logger.handlers app.logger.setLevel(gunicorn_access_logger.level) # init main class reco_sim_svr = RecoSimSvr() # add url rule app.add_url_rule('/simproduct/', view_func=reco_sim_svr.check_alive, methods=['GET']) app.add_url_rule('/simproduct/getSaleSimRecos', view_func=reco_sim_svr.get_recos, methods=['GET']) app.logger.info('All Init Done.')
run.sh:
#!/bin/bash boot_dir=../ start() { gunicorn --chdir $boot_dir --config gconfig.py service.recoservice:app } stop() { pid_file=${boot_dir}/project.pid if [ ! -f $pid_file ];then echo "Cannot find pid file project.pid. Maybe the service is not running." return 255 fi pid=`cat $pid_file` kill -15 $pid } if [ $1"x" == "startx" ];then start fi if [ $1"x" == "stopx" ];then stop fi if [ $1"x" == "restartx" ];then stop echo "wait for stopping..." sleep 5 start fi
ping.sh:
#!/usr/bin/env bash if [ $# -lt 1 ]; then echo "Usage: bash $0 {online|mock|test|single|local}" exit -1 fi SENV=$1 BASE_DOMAIN=xxxx.com if [ $SENV"x" == "testx" ]; then DOMAIN="test"$BASE_DOMAIN elif [ $SENV"x" == "onlinex" ]; then DOMAIN=$BASE_DOMAIN elif [ $SENV"x" == "singlex" ]; then DOMAIN=x.x.x.x PORT=5001 elif [ $SENV"x" == "localx" ]; then DOMAIN=0.0.0.0 PORT=5001 elif [ $SENV"x" == "mockx" ]; then DOMAIN="mock"$BASE_DOMAIN fi device='TEST85EA5969-4398-4A78-8816-348E189' run_once() { curl -X GET "http://$DOMAIN:$PORT/simproduct/"; echo curl -X GET "http://$DOMAIN:$PORT/simproduct/getSaleSimRecos?uid=1&deviceId=$device&productId=51953&maxLength=16"; echo } basic_test() { # test if success echo "test service..." run_once } basic_test
stat
Statistics script placement related code