_When I came into contact with Java 8 streaming data processing, my first feeling was that streaming makes the set operation much simpler. Usually we need multiple lines of code to complete the operation, with the help of streaming processing can be implemented in one line. For example, if we want to filter out all even numbers from a set containing integers and encapsulate them into a new List to return, we need to implement them in the following code before Java 8:
List<Integer> evens = new ArrayList<>();
for (final Integer num : nums) {
if (num % 2 == 0) {
evens.add(num);
}
}Through streaming in Java 8, we can simplify the code as follows:
List<Integer> evens = nums.stream().filter(num -> num % 2 == 0).collect(Collectors.toList());
First, simply explain the meaning of the above statement. The stream() operation converts the collection into a stream. The filter() performs our custom filtering. Here, all even numbers are filtered through lambda expressions. Finally, we encapsulate the results through collect(), and specify that the encapsulation is returned as a List collection through Collectors.toList().
_As can be seen from the above examples, the streaming processing of Java 8 greatly simplifies the operation of collections. In fact, it is not only collections, including arrays, files, etc. As long as it can be converted into streams, we can use streaming processing to operate on them, similar to the way we write SQL statements. Java 8 implements convection through internal iteration. A streaming process can be divided into three parts: conversion flow, intermediate operation and terminal operation. The following picture:
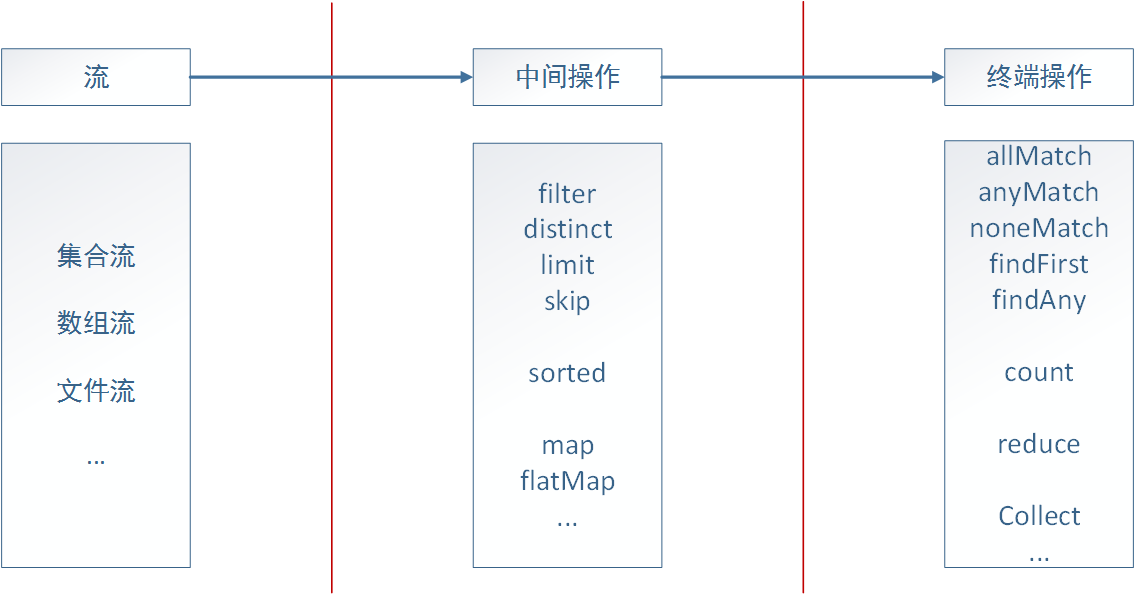
In the case of a set, we first need to call stream() function to convert it into a stream, then call corresponding intermediate operations to achieve the operations we need to perform on the set, such as filtering, transformation, etc. Finally, we encapsulate the previous results through terminal operations and return the form we need.
II. Intermediate operation
To facilitate the demonstration of the following examples, we first define a simple student entity class:
public class Student {
/** Student ID */
private long id;
private String name;
private int age;
/** grade */
private int grade;
/** major */
private String major;
/** School */
private String school;
// Omit getter and setter
}List<Student> students = new ArrayList<Student>() {
{
add(new Student(20160001, "Kong Ming", 20, 1, "Civil Engineering", "WuHan University"));
add(new Student(20160002, "Bo Yue", 21, 2, "information safety", "WuHan University"));
add(new Student(20160003, "Xuan de", 22, 3, "Economic management", "WuHan University"));
add(new Student(20160004, "Cloud length", 21, 2, "information safety", "WuHan University"));
add(new Student(20161001, "Yide", 21, 2, "Machinery and Automation", "Huazhong University of Science and Technology"));
add(new Student(20161002, "Yuan Zhi", 23, 4, "Civil Engineering", "Huazhong University of Science and Technology"));
add(new Student(20161003, "Obey the duty", 23, 4, "computer science", "Huazhong University of Science and Technology"));
add(new Student(20162001, "Zhong Mou", 22, 3, "Civil Engineering", "Zhejiang University"));
add(new Student(20162002, "Lu Su", 23, 4, "computer science", "Zhejiang University"));
add(new Student(20163001, "Ding Feng", 24, 5, "Civil Engineering", "Nanjing University"));
}
};2.1 filtration
_filtering, as its name implies, is to filter the elements that satisfy the conditions according to the given requirements. The filtering operations provided by Java 8 include filter, distinct, limit, skip.
(1)filter
_In the previous example, we have demonstrated how to use filter, which is defined as Stream < T > filter (Predicate <? Super T > predicate). The filter accepts a predicate Predicate, through which we can define the filter condition. In introducing lambda expression, we introduced Predicate as a functional interface, which contains a test (T) method, which returns B. Oolean. Now we hope to select all the students of Wuhan University from the set students. Then we can implement it through filter and pass the filter operation as a parameter:
List<Student> whuStudents = students.stream()
.filter(student -> "WuHan University".equals(student.getSchool()))
.collect(Collectors.toList());(2)distinct
_distinct operation is similar to DISTINNCT keyword added when we write SQL statements for de-reprocessing. distinct is implemented based on Object.equals(Object). Back to the original example, suppose we want to filter out all even numbers that do not repeat, then distinct operation can be added:
List<Integer> evens = nums.stream()
.filter(num -> num % 2 == 0).distinct()
.collect(Collectors.toList());(3)limit
_limit operation is similar to LIMIT keyword in SQL statement, but its function is relatively weak. Limit returns the stream containing the first n elements. When the set size is smaller than n, it returns the actual length. For example, the following example returns the first two students majoring in civil engineering:
List<Student> civilStudents = students.stream()
.filter(student -> "Civil Engineering".equals(student.getMajor())).limit(2)
.collect(Collectors.toList());Speaking of limit, I have to mention another flow operation: sorted. This operation is used for sorting elements in convection. Sorted requires that the elements to be compared must implement the Comparable interface. If not, we can pass the comparator as a parameter to sorted (Comparator <? Super T > comparator). For example, we want to screen out students majoring in civil engineering, and sort the two youngest ones by age from small to large. For a student, it can be achieved as follows:
List<Student> sortedCivilStudents = students.stream()
.filter(student -> "Civil Engineering".equals(student.getMajor())).sorted((s1, s2) -> s1.getAge() - s2.getAge())
.limit(2)
.collect(Collectors.toList());(4)skip
Skip operation is the opposite of limit operation. Like its literal meaning, skip the first n elements. For example, if we want to find the students who are majoring in civil engineering after 2, we can achieve the following:
List<Student> civilStudents = students.stream()
.filter(student -> "Civil Engineering".equals(student.getMajor()))
.skip(2)
.collect(Collectors.toList());2.2 mapping
_In SQL, by adding the required field name after the SELECT keyword, we can output only the field data we need, and the mapping operation of streaming processing is also to achieve this purpose. In the streaming processing of Java 8, there are mainly two types of mapping operations: map and flatMap.
(1)map
For example, suppose we want to screen out the names of all the students majoring in computer science, then we can map student entities into student name strings by map on the basis of filter filtering. The specific implementation is as follows:
List<String> names = students.stream()
.filter(student -> "computer science".equals(student.getMajor()))
.map(Student::getName).collect(Collectors.toList());In addition to these basic maps, Java 8 also provides mapToDouble (ToDoubleFunction <? Super T > mapper), mapToInt (ToIntFunction <? Super T > mapper), mapToLong (ToLongFunction <? Super T > mapper), and mapToLong (ToLongFunction <? Super T > mapper). These maps return to the corresponding types of streams respectively. Java 8 sets some special operations for these streams, such as we want to calculate all majors for computer science students. Sum of age, then we can achieve the following:
int totalAge = students.stream()
.filter(student -> "computer science".equals(student.getMajor()))
.mapToInt(Student::getAge).sum();By mapping Student directly to IntStream according to age, we can directly invoke the provided sum() method to achieve our goal. In addition, the advantage of using these numerical streams is that we can avoid the performance consumption caused by jvm boxing operations.
(2)flatMap
The difference between flatMap and map is that flatMap converts each value of a stream into a stream, and then flattens these streams into a stream. For example, suppose we have a string array String[] strs = {"java8", "is", "easy", "to", "use"}; we want to output all the non-repetitive characters that make up this array, then we may first think of the following implementation:
List<String[]> distinctStrs = Arrays.stream(strs)
.map(str -> str.split("")) // Mapping to Stream < String []>
.distinct()
.collect(Collectors.toList());After performing the map operation, we get a stream that contains multiple strings (an array of characters that make up a string). At this time, distinct operation is performed based on the comparison between these string arrays, so we can not achieve the desired purpose. At this time, the output is:
[j, a, v, a, 8] [i, s] [e, a, s, y] [t, o] [u, s, e]
distinct can only operate on a stream containing multiple characters, that is, Stream < String >. At this point, flatMap can achieve our goal:
List<String> distinctStrs = Arrays.stream(strs)
.map(str -> str.split("")) // Mapping to Stream < String []>
.flatMap(Arrays::stream) // Flattening into Stream < String >
.distinct()
.collect(Collectors.toList());flatMap converts Stream < String []> mapped by map into Stream < String > mapped by various string arrays, and flattens these small streams into a large stream of Steam < String > composed of all strings, so as to achieve our goal.
Similar to map, flatMap also provides mapping operations for specific types: flatMapToDouble (Function <? Super T,? Extends DoubleStream > mapper), flatMapToInt (Function <? Super T,? Extends IntStream > mapper), flatMapToLong (Function <? Super T,? Extends LongStream > mapper).
Terminal operation
_Terminal operation is the last step of streaming processing. We can implement convection lookup, reduction and other operations in terminal operation.
3.1 search
(1)allMatch
_allMatch is used to detect whether all the behaviors satisfy the specified parameters. If all the behaviors satisfy the specified parameters, it returns true. For example, if we want to test whether all the students have reached the age of 18, then it can be realized as follows:
boolean isAdult = students.stream().allMatch(student -> student.getAge() >= 18);
(2)anyMatch
_anyMatch detects whether there is one or more behavior that satisfies the specified parameters. If it satisfies, it returns true. For example, if we want to detect whether there are students from Wuhan University, it can be realized as follows:
boolean hasWhu = students.stream().anyMatch(student -> "WuHan University".equals(student.getSchool()));
(3)noneMatch
_noneMatch is used to detect whether there is no element that satisfies the specified behavior, and if it does not exist, it returns true. For example, we want to detect whether there is no student majoring in computer science, which can be achieved as follows:
(4)findFirstboolean noneCs = students.stream().noneMatch(student -> "computer science".equals(student.getMajor()));
findFirst is used to return the first element that meets the requirements. For example, if we want to select a major as the first student in civil engineering, we can achieve the following:
Optional<Student> optStu = students.stream().filter(student -> "Civil Engineering".equals(student.getMajor())).findFirst();
FindFirst does not carry parameters, the specific search conditions can be set by filter. In addition, we can find that findFirst returns an Optional type. For a specific explanation of this type, you can refer to the previous article: Java 8 new feature - Optional class.
(5)findAny
The difference between findAny and findFirst is that findAny does not necessarily return to the first one, but to any one, for example, we want to return to any student majoring in civil engineering, which can be achieved as follows:
In fact, for sequential streaming processing, findFirst and findAny return the same results. As for why they are designed this way, we will introduce parallel streaming processing in the next article. When we enable parallel streaming processing, there are many limitations in finding the first element. If it is not a special requirement, the performance of using findAny in parallel streaming processing will be limited. Better than findFirst.Optional<Student> optStu = students.stream().filter(student -> "Civil Engineering".equals(student.getMajor())).findAny();
3.2 reduction
In the previous examples, we mostly encapsulated and returned data through collect(Collectors.toList()). If my goal is not to return a new set, but to further calculate the set after the parameterization operation, then we can implement reduction operation on the set. Streaming in Java 8 provides a reduce method to achieve this goal.
_In the past, we mapped Stream < Student > to IntStream through map ToInt, and obtained the sum of all the students'ages through IntStream's sum method. In fact, we can also achieve this goal through reduction operation, which can be achieved as follows:
// The method in the previous example
int totalAge = students.stream()
.filter(student -> "computer science".equals(student.getMajor()))
.mapToInt(Student::getAge).sum();
// Reduction operation
int totalAge = students.stream()
.filter(student -> "computer science".equals(student.getMajor()))
.map(Student::getAge)
.reduce(0, (a, b) -> a + b);
// Further simplification
int totalAge2 = students.stream()
.filter(student -> "computer science".equals(student.getMajor()))
.map(Student::getAge)
.reduce(0, Integer::sum);
// With overloaded versions without initial values, you need to pay attention to returning Optional
Optional<Integer> totalAge = students.stream()
.filter(student -> "computer science".equals(student.getMajor()))
.map(Student::getAge)
.reduce(Integer::sum); // Remove the initial value_The previous use of collect(Collectors.toList()) is a simple collection operation, which is the encapsulation of the processing results, corresponding to toSet, toMap, to meet our needs for the results organization. These methods all come from java.util.stream.Collectors, which we can call collectors.
3.3.1 reduction
_Collectors also provide corresponding reduction operations, but they are different from reduce in internal implementation. Collectors are more suitable for reduction operations on variable containers. Generally speaking, these collectors are implemented based on Collectors. Reduction ().
Example 1: Total number of students
long count = students.stream().collect(Collectors.counting()); // Further simplification long count = students.stream().count();
// Maximum age Optional<Student> olderStudent = students.stream().collect(Collectors.maxBy((s1, s2) -> s1.getAge() - s2.getAge())); // Further simplification Optional<Student> olderStudent2 = students.stream().collect(Collectors.maxBy(Comparator.comparing(Student::getAge))); // Finding the Minimum Age Optional<Student> olderStudent3 = students.stream().collect(Collectors.minBy(Comparator.comparing(Student::getAge)));
Example 3: Age summation
There are also summing Long and summing Double.int totalAge4 = students.stream().collect(Collectors.summingInt(Student::getAge));
Example 4: Average age age
There are also averaging Long and averaging Double.double avgAge = students.stream().collect(Collectors.averagingInt(Student::getAge));
Example 5: Number, sum, mean, maximum and minimum of elements can be obtained at one time.
IntSummaryStatistics statistics = students.stream().collect(Collectors.summarizingInt(Student::getAge));
Output:
IntSummaryStatistics{count=10, sum=220, min=20, average=22.000000, max=24}Example 6: String splicing
String names = students.stream().map(Student::getName).collect(Collectors.joining());
// Output: Kong Mingbo, Xuande Yun, Changyi, Deyuan, Fengxiao Zhongmou, Lu Suding Feng
String names = students.stream().map(Student::getName).collect(Collectors.joining(", "));
// Output: Kongming, Boyo, Xuande, Yunchang, Yide, Yuanzhi, Fengxiao, Zhongmou, Lu Su, Ding Feng3.3.2 grouping
In database operation, we can group the queried data by GROUP BY keyword. The streaming processing of Java 8 also provides us with the function of Collectors. grouping By to operate the collection. For example, we can group the above students by school:
groupingBy receives a classifier Function <? Super T,? Extends K> classifier, and we can customize the classifier to achieve the desired classification effect.Map<String, List<Student>> groups = students.stream().collect(Collectors.groupingBy(Student::getSchool));
_The above demonstrates the first-level grouping. We can also define multiple classifiers to achieve multi-level grouping. For example, we hope to grouping according to specialty on the basis of grouping according to school. The realization is as follows:
Map<String, Map<String, List<Student>>> groups2 = students.stream().collect(
Collectors.groupingBy(Student::getSchool, // Grouping by school
Collectors.groupingBy(Student::getMajor))); // Second-level grouping, by professionIn fact, the second parameter in groupingBy is not only groupingBy, but also any Collector type. For example, we can pass a Collector.counting to count the number of groups:
If we don't add the second parameter, the compiler will add a Collectors.toList() by default.Map<String, Long> groups = students.stream().collect(Collectors.groupingBy(Student::getSchool, Collectors.counting()));
3.3.3 partition
_partitioning can be regarded as a special case of grouping. There are only two cases of key in the partition: true or false. The purpose is to divide the set of partitions into two parts according to the conditions. The streaming processing of Java 8 uses ollectors. partitioning by () method to realize partitioning. This method receives a predicate. For example, we want to divide students into martial arts students and non-martial Arts students, so it can be realized. As follows:
The advantage of partitioning over grouping is that we can get two kinds of results at the same time. In some application scenarios, we can get all the results we need in one step, such as dividing the array into odd and even numbers.Map<Boolean, List<Student>> partition = students.stream().collect(Collectors.partitioningBy(student -> "WuHan University".equals(student.getSchool())));
_All collectors described above implement self-interface java.util.stream.Collector, which is defined as follows:
public interface Collector<T, A, R> {
/**
* A function that creates and returns a new mutable result container.
*
* @return a function which returns a new, mutable result container
*/
Supplier<A> supplier();
/**
* A function that folds a value into a mutable result container.
*
* @return a function which folds a value into a mutable result container
*/
BiConsumer<A, T> accumulator();
/**
* A function that accepts two partial results and merges them. The
* combiner function may fold state from one argument into the other and
* return that, or may return a new result container.
*
* @return a function which combines two partial results into a combined
* result
*/
BinaryOperator<A> combiner();
/**
* Perform the final transformation from the intermediate accumulation type
* {@code A} to the final result type {@code R}.
*
* <p>If the characteristic {@code IDENTITY_TRANSFORM} is
* set, this function may be presumed to be an identity transform with an
* unchecked cast from {@code A} to {@code R}.
*
* @return a function which transforms the intermediate result to the final
* result
*/
Function<A, R> finisher();
/**
* Returns a {@code Set} of {@code Collector.Characteristics} indicating
* the characteristics of this Collector. This set should be immutable.
*
* @return an immutable set of collector characteristics
*/
Set<Characteristics> characteristics();
}IV. Parallel Streaming Data Processing
_Streaming processing is suitable for divide-and-conquer thinking, which greatly improves the performance of code when the processing set is large. The designers of Java 8 also see this point, so they provide parallel streaming processing. In the example above, we call stream() method to start streaming processing. Java 8 also provides parallelStream() to start parallel streaming processing. parallelStream() is essentially based on the Fork-Join framework of Java 7, and its default thread number is the number of hosts'kernels.
_Starting parallel streaming processing is simple, it only needs to replace stream() with parallelStream(), but since it is parallel, it will involve multi-threading security issues, so before enabling, we should first confirm whether parallel is worth (parallel efficiency is not necessarily higher than sequential execution), and also ensure thread safety. These two items can not be guaranteed, so parallelism is meaningless. After all, the results are more important than speed. Later, I will have time to analyze the implementation and best practices of parallel streaming data processing in detail.