What is ByteBuf?
- The Java NIO provides the ByteBuffer class as a byte buffer, but the use of ByteBuffer is complex, especially requiring flip() to switch between read and write
- So Netty redesigned a byte buffer ByteBuf with the following features:
- Extensibility
- Defines read and write indexes, so flip() switching is not required for read and write mode
- Zero-copy
- Implement ReferenceCounted to support reference counting
- Supports pooling
- Method can be chained
- Automatic Capacity Expansion
- Better performance
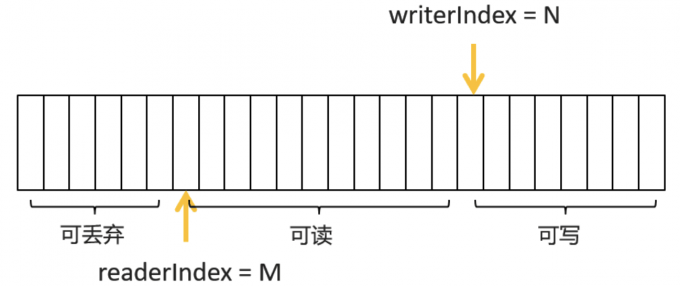
ByteBuf structure
- ByteBuf contains a read pointer (readerIndex) and a write pointer (writerIndex), so as to solve the need for ByteBuffer in NIO to call the flip() method for read-write switching, the words-read-write designed as two indexes do not affect each other and can be done simultaneously
- ByteBuf consists of three parts:
-
readable bytes:
- Indicates unread bytes, and if the readable bytes are exhausted, trying to read from ByteBuf again throws an IndexOutOfBoundsException, so it is best to pass isReadable() before reading the data
while(byteBuf.isReadable()){
// Read Content
}
-
writable bytes:
- Indicates the remaining writable byte space, and ByteBuf defaults to Integer.MAX_VALUE. Writing data to ByteBuf without writable space throws an IndexOutOfBoundsException exception, so it is best to pass isWriteable() before writing data
while(byteBuf.isWriteable()){
// Write Content
}
-
discardable bytes:
- A byte that represents a read byte and can be discarded. Bytes subscribed to 0 ~ readerIndex are treated as discardable bytes
ByteBuf Notes
- ByteBuf can read every byte by get method, but all get methods will only read the corresponding byte, will not move the read pointer, all read..., skip... methods will read or skip the specified byte and move the read pointer
- ByteBuf can write to each byte through the set method, but all set...methods only update the index at the specified location and do not move the write pointer, whereas all write...methods write specific bytes to the current writerIndex and move the write pointer.
ByteBuf partition
- There are many subclasses of ByteBuf, and there are two ways to classify ByteBuf
Implement By Bottom Level
-
HeapByteBuf heap buffer:
- The underlying implementation is an array of bytes in the Java heap, where the heap buffer is located in the JVM heap memory area and can be reclaimed by the GC. It is more efficient to request and release.This buffer is recommended for regular JAVA programs
-
DirectByteBuf direct buffer:
- The underlying implementation of DirectByteBuf is an array of bytes in the operating system's kernel space, and the byte array of the direct buffer is in the Native heap outside the JVM heap, which is requested and released by the operating system management
- References to DirectByteBuf are managed by the JVM.Direct buffers are managed by the operating system
- On the one hand, both request and release efficiency are lower than heap buffers
- On the other hand, it can greatly improve I/O efficiency.Because of I/O operations, data from user space (JAVA is the heap buffer) needs to be copied to the kernel space (the direct buffer) before the kernel space is written to a network SOCKET or file.If you get a direct buffer in user space, you can write data directly to the kernel space, reducing one copy and greatly improving I/O efficiency, also known as zero copy
-
Composite Buffer Composite Buffer
- Composite buffers are implemented in a combination of the above two ways, which is also a zero-copy Technology
- Imagine merging two buffers into one
- Typically, data from the latter buffer needs to be copied to the previous buffer
- Using a combined buffer, you can save two buffers directly, because its internal implementation combines the two buffers and ensures that the user operates the combined buffer as if it were a regular buffer, thereby reducing copy operations
By whether or not to use the object pool
-
UnpooledByteBuf
- Buffers that do not use an object pool are recommended when creating a large number of buffer objects is not required
-
PooledByteBuf
- Object pool buffers, which are returned to the object pool when the object is released, are reusable
- This type of buffer is recommended when a large number of buffers are needed and frequently created
- Netty4.1 uses object pool buffers by default and 4.0 uses non-object pool buffers by default
ByteBuf Creation
-
Official advice for creating ByteBufs is to use Unpooled's auxiliary methods, both static methods that create new ByteBufs by allocating new space or wrapping or copying existing byte arrays, byte buffers, and strings, as defined below:
// Allocate a ByteBuf on the heap and specify the initial and maximum capacity
public static ByteBuf buffer(int initialCapacity, int maxCapacity) {
return ALLOC.heapBuffer(initialCapacity, maxCapacity);
}
// Allocate a ByteBuf out of the heap, specifying initial and maximum capacity
public static ByteBuf directBuffer(int initialCapacity, int maxCapacity) {
return ALLOC.directBuffer(initialCapacity, maxCapacity);
}
// Wrap a byte[] into a ByteBuf and return using wrapping
public static ByteBuf wrappedBuffer(byte[] array) {
if (array.length == 0) {
return EMPTY_BUFFER;
}
return new UnpooledHeapByteBuf(ALLOC, array, array.length);
}
// Returns a ByteBuf combination and specifies the number of combinations
public static CompositeByteBuf compositeBuffer(int maxNumComponents){
return new CompositeByteBuf(ALLOC, false, maxNumComponents);
}
- All of the above methods are actually called by a static variable called ALLOC to create a specific ByteBuf, which is actually a ByteBufAllocator
private static final ByteBufAllocator ALLOC = UnpooledByteBufAllocator.DEFAULT;
- ByteBufAllocator is an interface specifically responsible for ByteBuf allocation and has several implementations: AbstractByteBufAllocator, PooledByteBufAllocator, PreferHeapByteBufAllocator, UnpooledByteBufAllocator.The corresponding Unpooled implementation class is UnpooledByteBufAllocator
ByteBuf Key Class Source Code Analysis
ByteBuf
- Although it is defined as an abstract class, it does not implement any methods. It extends the ReferenceCounted implementation of reference counting, and the most important methods for this class are as follows:
ByteBuf capacity(int newCapacity); // Set Buffer Capacity
ByteBuf order(ByteOrder endianness); // Set Buffer Byte Order
ByteBuf readerIndex(int readerIndex); // Set Buffer Read Index
ByteBuf writerIndex(int writerIndex); // Set Buffer Write Index
ByteBuf setIndex(int readerIndex, int writerIndex); // Set Read-Write Index
ByteBuf markReaderIndex(); // Tag Read Index, Write Index Analogue
ByteBuf resetReaderIndex(); // Read Index Reset to Tag
ByteBuf skipBytes(int length); // Skip specified bytes (increase read index)
ByteBuf clear(); // Read and write index set to 0
int readableBytes(); // Readable bytes
boolean isReadable(); // Is it readable
boolean isReadable(int size); // Is the specified number of bytes readable
boolean hasArray(); // Determine if the underlying implementation is a byte array
byte[] array(); // Returns an array of bytes implemented at the bottom level
int arrayOffset(); // The first byte position of the underlying byte array
boolean isDirect(); // Determine whether the underlying implementation is a direct buffer
boolean hasMemoryAddress(); // Does the underlying direct ByteBuffer have a memory address
long memoryAddress(); // First byte memory address of direct ByteBuffer
int indexOf(int fromIndex, int toIndex, byte value); // Find the absolute location of the first specific byte
int bytesBefore(int index, int length, byte value); // Find the relative position of the first specific byte, read the index relatively
ByteBuf copy(); // Copy a buffer, and copy() produces a ByteBuf that is completely independent of the original ByteBuf
ByteBuf slice(); // The ByteBuf generated by slice() and duplicate() shares the same underlying implementation as the original ByteBuf, but maintains separate indexes and tags. When using these two methods, special attention needs to be paid to combining usage scenarios to determine whether retain() is called to increase the reference count
String toString(); // Standard overload method of Object in JAVA, returns the JAVA description of ByteBuf
String toString(Charset charset); // Returns the character form of buffer byte data encoded with the specified encoding set
- Here, Netty uses a highly aggregated design pattern, and ByteBuf is all abstract. It aggregates all possible methods used by subclasses into base classes. In addition, factory mode generates ByteBuf, which makes it very convenient for programmers to operate without touching specific subclasses, simply using top-level Abstract classes.
AbstractByteBuf
- The abstract base class AbstractByteBuf defines common operations for ByteBuf, such as read-write and tag index maintenance, capacity expansion, discarded bytes, and so on.
- Private variables of this class
int readerIndex; // Read Index
int writerIndex; // Write Index
private int markedReaderIndex; // Tag Read Index
private int markedWriterIndex; // Tag Write Index
private int maxCapacity; // Maximum capacity
- Calculate capacity expansion method calculateNewCapacity(minNewCapacity), where the parameters represent the minimum capacity required for expansion, can be analyzed from the source code:
- The minimum capacity of ByteBuf is 64b
- Double capacity when minimum required capacity is between 64b and 4mb
- Increase capacity by 4 MB per expansion when minimum capacity required exceeds 4 MB
private int calculateNewCapacity(int minNewCapacity) {
final int maxCapacity = this.maxCapacity;
final int threshold = 1048576 * 4; // Threshold of 4MB
if (minNewCapacity == threshold) {
return threshold;
}
// The minimum required capacity exceeds the threshold of 4 MB, increasing by 4 MB each time
if (minNewCapacity > threshold) {
int newCapacity = (minNewCapacity / threshold) * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity; // No more expansion beyond maximum capacity
} else {
newCapacity += threshold; // Increase 4MB
}
return newCapacity;
}
// The minimum required capacity at this point is less than the threshold of 4MB, doubling capacity
int newCapacity = 64;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1; // Using shift operation to represent *2
}
return Math.min(newCapacity, maxCapacity);
}
- discardReadBytes() method to discard read bytes:
public ByteBuf discardReadBytes() {
if (readerIndex == 0) {
return this;
}
if (readerIndex != writerIndex) {
// Move data after readerIndex to start at 0
setBytes(0, this, readerIndex, writerIndex - readerIndex);
writerIndex -= readerIndex; // Write index to reduce readerIndex
adjustMarkers(readerIndex); // Tag Index Correspondence Adjustment
readerIndex = 0; // Read Index Set 0
} else {
// Read-write index identical to clear operation
adjustMarkers(readerIndex);
writerIndex = readerIndex = 0;
}
return this;
}
- Frequent calls to discardReadBytes() result in frequent forward movement of data, resulting in a loss of performance.As a result, discardSomeReadBytes() provides another way to move data forward when the read index exceeds half its capacity, with the following core implementations:
if (readerIndex >= capacity() >>> 1) {
setBytes(0, this, readerIndex, writerIndex - readerIndex);
writerIndex -= readerIndex;
adjustMarkers(readerIndex);
readerIndex = 0;
}
- If you do not want to discard bytes and only want the read index to move forward, use the skipBytes():
public ByteBuf skipBytes(int length) {
checkReadableBytes(length);
readerIndex += length;
return this;
}
- Take getInt() and readInt() for example, to analyze the common data acquisition methods, readInt will increase the read index, getInt will not have any impact on the index.The implementation of data setting methods setInt() and writeInt() can be analogized
public int getInt(int index) {
checkIndex(index, 4); // Index Correctness Check
return _getInt(index);
}
protected abstract int _getInt(int index);
public int readInt() {
checkReadableBytes0(4); // Check Index
int v = _getInt(readerIndex);
readerIndex += 4; // Read Index Increase
return v;
}
AbstractReferenceCountedByteBuf
- This abstract class implements reference count-related functions, where the count is added by 1 when an object is needed, and the count is subtracted by 1 when it is no longer used
- By increasing the count with the retain() function, the release() function decreases the count, triggering deallocate() to release buffer memory when the counter decreases to zero
CompositeByteBuf
- Netty implements a combination of multiple ByteBuf s with this class and does not need to copy objects. It maintains a ComponentList-type variable component internally. ComponentList is an internal class that inherits ArrayList with the following code:
private static final class ComponentList extends ArrayList<Component> {
ComponentList(int initialCapacity) {
super(initialCapacity);
}
@Override
public void removeRange(int fromIndex, int toIndex) {
super.removeRange(fromIndex, toIndex);
}
}
- ComponentList is a List that holds Components, and Component is an internal class that holds a final-type ByteBuf object internally
private static final class Component {
final ByteBuf buf;
final int length;
int offset;
int endOffset;
Component(ByteBuf buf) {
this.buf = buf;
length = buf.readableBytes();
}
void freeIfNecessary() {
// We should not get a NPE here. If so, it must be a bug.
buf.release();
}
}
- When you add ByteBuf to Composite ByteBuf, you actually encapsulate the ByteBuf as a Component and add it to the components as shown in the following code:
private int addComponent0(boolean increaseWriterIndex, int cIndex, ByteBuf buffer) {
assert buffer != null;
boolean wasAdded = false;
try {
checkComponentIndex(cIndex);
int readableBytes = buffer.readableBytes();
// No need to consolidate - just add a component to the list.
//Encapsulate ByteBuf as a Component
@SuppressWarnings("deprecation")
Component c = new Component(buffer.order(ByteOrder.BIG_ENDIAN).slice());
if (cIndex == components.size()) {
wasAdded = components.add(c);
if (cIndex == 0) {
c.endOffset = readableBytes;
} else {
Component prev = components.get(cIndex - 1);
c.offset = prev.endOffset;
c.endOffset = c.offset + readableBytes;
}
} else {
components.add(cIndex, c);
wasAdded = true;
if (readableBytes != 0) {
updateComponentOffsets(cIndex);
}
}
if (increaseWriterIndex) {
writerIndex(writerIndex() + buffer.readableBytes());
}
return cIndex;
} finally {
if (!wasAdded) {
buffer.release();
}
}
}
ByteBuf Pooling
- Pooling of frequently used or time-consuming objects, such as thread pools, database connection pools, string constant pools, is common to optimize system performance
- ByteBuf is also a frequently used object in Netty. Netty also pools ByteBuf, and reference counting is the key point to achieve pooling
- The ByteBuf class implements the ReferenceCounted interface, which marks a class as a class that needs to be managed with reference counts
public interface ReferenceCounted {
// Returns the reference count value of the current object, if 0, indicating that the current object has been released
int refCnt();
// Reference Count Plus 1
ReferenceCounted retain();
// Reference Count plus increment
ReferenceCounted retain(int increment);
// Reference Count minus 1
boolean release();
// Reference count minus decrement, releases the current object if the current reference count is 0, and returns true if the release is successful
boolean release(int decrement);
}
- Each object that uses a reference count maintains its own reference count. When an object is created, the reference count is 1. release() decreases the reference count by increasing the reference count by retain(), and releases the current object if the reference count is 0.
- Within each subclass of ByteBuf, they decide how to release the object themselves, return to the pool if it is a pooled ByteBuf, or destroy the underlying byte array reference or free the corresponding out-of-heap memory if it is not pooled
- The ByteBuf of reference counting is implemented through the release() method of AbstractReferenceCountedByteBuf, and the release() method actually calls the release 0() method, so let's take a look at the specific method implementation:
private boolean release0(int decrement) {
// The getAndAdd method of the AtomicIntegerFieldUpdater class returns the original value of the object before add ing it
int oldRef = refCntUpdater.getAndAdd(this, -decrement);
// If oldRef==decrement, the object's reference count is just released, and the object's release operation is possible, that is, the deallocate() method is called
if (oldRef == decrement) {
deallocate();
return true;
// If the original value of the reference count is less than the value to be released, or the decrement is less than 0, an exception IllegalReferenceCountException with an error in the reference count is thrown
} else if (oldRef < decrement || oldRef - decrement > oldRef) {
// Ensure we don't over-release, and avoid underflow.
// This will increase the value of the reference count back here
refCntUpdater.getAndAdd(this, decrement);
throw new IllegalReferenceCountException(oldRef, decrement);
}
return false;
}
// The release method of the reference count object is an abstract method implemented by each subclass
protected abstract void deallocate();
-
Here's how each ByteBuf implementation class handles object release
@Override
protected void deallocate() {
freeArray(array);
// Release the reference to byte[]
array = null;
}
@Override
protected void deallocate() {
ByteBuffer buffer = this.buffer;
if (buffer == null) {
return;
}
this.buffer = null;
// Release Buffer Out of Heap
if (!doNotFree) {
freeDirect(buffer);
}
}
- Pooled HeapByteBuf and Pooled DirectByteBuf
@Override
protected final void deallocate() {
if (handle >= 0) {
final long handle = this.handle;
this.handle = -1;
memory = null;
tmpNioBuf = null;
chunk.arena.free(chunk, handle, maxLength, cache);
chunk = null;
// Reuse this ByteBuf, i.e. put it back into the pool
recycle();
}
}
private void recycle() {
recyclerHandle.recycle(this);
}
static final class DefaultHandle<T> implements Handle<T> {
private Stack<?> stack;
// This variable is used to hold the recycled ByteBuf object
private Object value;
DefaultHandle(Stack<?> stack) {
this.stack = stack;
}
@Override
public void recycle(Object object) {
if (object != value) {
throw new IllegalArgumentException("object does not belong to handle");
}
// push the handle object onto the stack
stack.push(this);
}
}
- You can see that releasing pooled ByteBuf objects is a process of reclaiming objects
Introduction
- From above we have learned that ByteBuf is allocated through the ByteBufAllocator interface, which has two implementations:
- PooledByteBufAllocator
- UnpooledByteBufAllocator
- Netty uses PooledByteBufAllocator by default to pool allocated ByteBufs
- But we can change the default settings by ChannelConfig or specifying an allocator in the ServerBootStrap bootstrapper