Blog Outline:
1, Overview of Kafka
1) Message queuing
2) Why use message queuing?
3) What is Kafka?
4) Characteristics of Kafka
5) Kafka architecture
6) Difference between Topic and Partition
7) kafka flow chart
8) Kafka's file storage mechanism
9) Data reliability and persistence assurance
10) leader election
2, Deploy single Kafka
1) Deploy Kafka
2) Test Kafka
3, Deploy Kafka cluster
1) Environmental preparation
2) Deploy zookeeper cluster
3) Deploy Kafka cluster
1, Overview of Kafka
1) Message queuing
1) Point to point mode (one-to-one, consumers pull data actively, and messages are cleared after receiving)
The point-to-point model is usually a pull or poll based messaging model, which requests information from the queue rather than pushing messages to the client. The feature of this model is that messages sent to the queue are received and processed by one and only one receiver, even if there are multiple message listeners;
2) Publish / subscribe mode (one to many, push to all subscribers after data production)
The publish subscribe model is a push based messaging model. The publish / subscribe model can have many different subscribers. Temporary subscribers only receive messages when they actively listen to the topic, while persistent subscribers listen to all messages of the topic, even if the current subscriber is unavailable and offline.
2) Why use message queuing?
1) decoupling
Allows you to extend or modify processes on both sides independently, as long as you make sure they follow the same interface constraints.
2) redundancy
Message queues persist data until they have been fully processed, thus avoiding the risk of data loss. In the "insert get delete" paradigm adopted by many message queues, before deleting a message from the queue, your processing system needs to clearly indicate that the message has been processed, so as to ensure that your data is saved safely until you use it.
3) Expansibility
Because message queuing decouples your processing, it's easy to increase the frequency of message queuing and processing, as long as you add additional processing.
4) Flexibility & cutting peak and filling valley
In the case of increased traffic, applications still need to continue to play a role, but such burst traffic is not common. It is a great waste to put resources on standby to deal with such peak visits. Using message queuing can make critical components withstand sudden access pressure without completely crashing due to sudden overload requests.
5) Recoverability
Failure of some components of the system will not affect the whole system. Message queuing reduces the coupling between processes, so even if a process processing messages hangs up, the messages added to the queue can still be processed after the system recovers.
6) Sequence assurance
In most scenarios, the order of data processing is very important. Most of the message queues are originally ordered, and can ensure that the data will be processed in a specific order. (Kafka ensures the order of messages in a Partition)
7) buffer
It helps to control and optimize the speed of data flow through the system, and solve the inconsistency of processing speed between production message and consumption message.
8) Asynchronous communication
Many times, users don't want or need to process messages immediately. Message queuing provides an asynchronous processing mechanism that allows users to put a message on the queue, but not immediately process it. Put as many messages as you want in the queue, and then process them when you need them.
3) What is Kafka?
Kafka is an open source stream processing platform released by Apache Software Foundation, which is written by Scala and Java. It is a high-throughput distributed publishing subscription message system, which can handle all action flow data in consumer scale websites. This action (web browsing, search, and other user actions) is a key factor in many social functions on the modern web. These data are usually solved by processing log and log aggregation due to throughput requirements. For the log data and offline analysis system like Hadoop, but also the limitation of real-time processing, this is a feasible solution. Kafka aims to unify online and offline message processing through Hadoop's parallel loading mechanism, and also to provide real-time messages through clusters.
4) Characteristics of Kafka
kafka is a high throughput distributed publish subscribe message system, which has the following characteristics:
1) Through the disk data structure to provide message persistence, this structure can maintain long-term stable performance for even the number of terabytes of message storage;
2) Persistence: file storage and log file storage are used to store messages, which need to be written to the hard disk. A certain threshold value is used to write to the hard disk, so as to reduce disk I/O. if kafka suddenly goes down, part of the data will be lost;
3) High throughput: even ordinary hardware kafka can support millions of messages per second;
4) It supports message partition through kafka server and consumer cluster;
5) Support Hadoop parallel data loading;
5) Kafka architecture
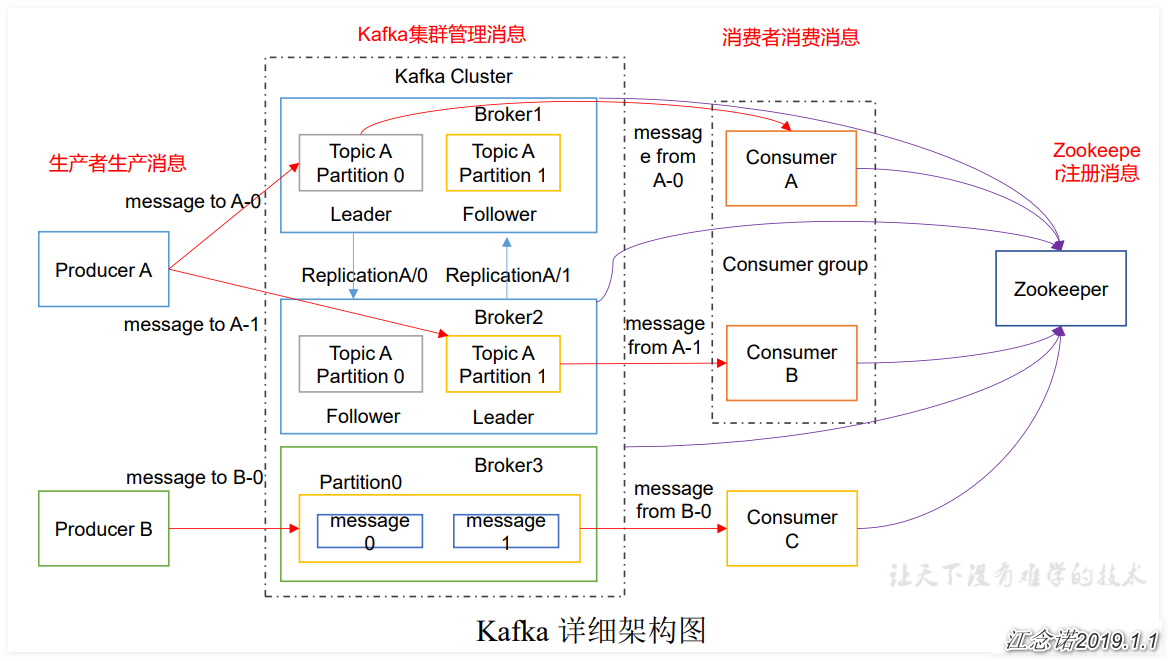
The function of each component in the architecture diagram:
1) Producer: Message producer is the client that sends messages to kafka broker;
2) Broker: a kafka server is a broker. A cluster consists of multiple brokers. A broker can hold multiple topic s;
3) Consumer: message consumer, the client that fetches messages from kafka broker;
4) Partition: to achieve scalability, a very large topic can be distributed to multiple broker s (i.e. servers). A topic can be divided into multiple partitions, each of which is an orderly queue. Each message in the partition is assigned an ordered id (offset). kafka only guarantees to send messages to consumer s in the order of one partition, and does not guarantee the order of the whole topic (among multiple partitions);
5) Topic: Kafka classifies the messages according to the topic. Each message published to Kafka cluster needs to specify a topic;
6) ConsumerGroup: each Consumer belongs to a specific Consumer Group. A message can be sent to multiple different Consumer groups, but only one Consumer in a Consumer Group can consume the message;
6) Difference between Topic and Partition
A topic can be regarded as a class of messages. Each topic will be divided into multiple partitions. Each partition is an append log file at the storage level. Any message published to this partition will be appended to the end of the log file. The position of each message in the file is called offset. The offset is a long number, which uniquely marks a message. Each message is attached to the partition, which is a sequential write disk, so the efficiency is very high (the speed of sequential write disk is higher than random write memory, which is a very important guarantee of high throughput of kafka).
When each message is sent to the broker, it will choose which partition to store according to the partition rule (by default, polling is used to write data). If the partition rules are set properly, all messages can be evenly distributed in different partitions, which enables horizontal expansion. (if a topic corresponds to a file, the I/O of the machine where the file is located will become the performance bottleneck of the topic, and partition solves this problem). If the message is consumed, append.log will be reserved for two days.
7) kafka flow chart
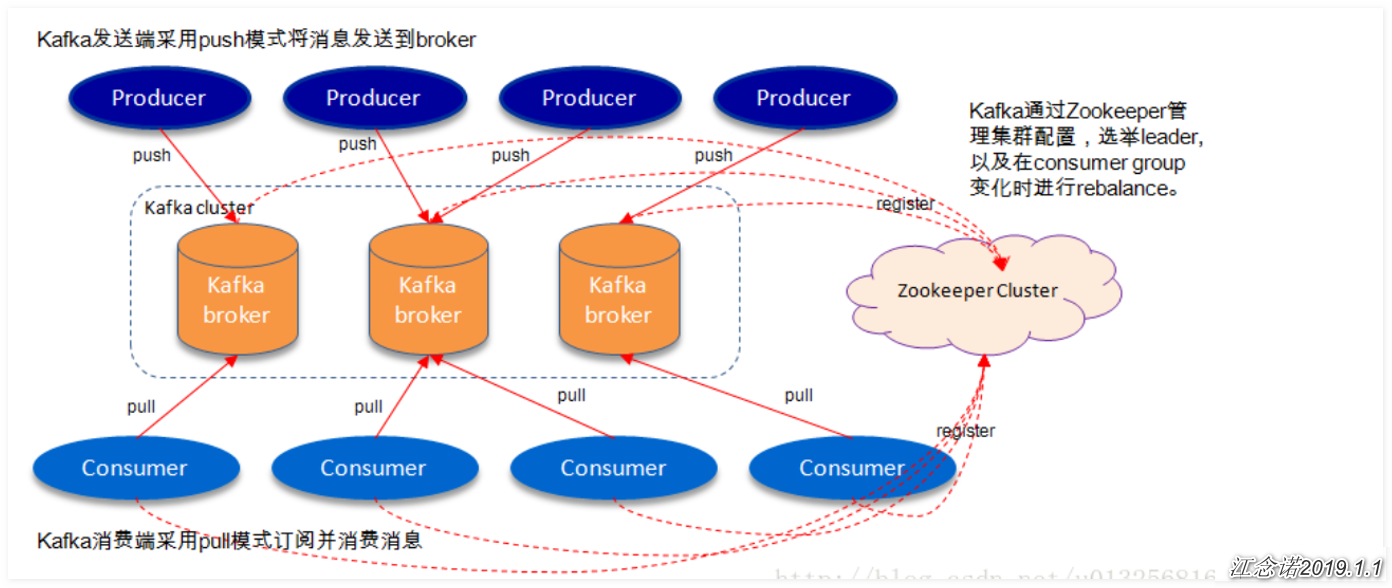
As shown in the figure above, a typical kafka architecture includes several producers (server logs, business data, page view s generated at the front end of the page, etc.), several brokers (kafka supports horizontal expansion, generally the more brokers, the higher the cluster throughput), such as a consumer (Group), and a Zookeeper cluster. kafka manages the cluster configuration through Zookeeper, elects the leader, and readjusts when the consumer group changes. Producer uses push mode to publish messages to broker, and consumer uses pull mode to subscribe and consume messages from broker.
There are two roles in the lookeeper cluster: leader and follower. Leader provides external services. Follower is responsible for generating replicas when the content synchronization messages generated in the leader are written and generated;
kafka's high reliability comes from its robust replica strategy. By adjusting its replica parameters, kafka can operate between performance and reliability easily. kafka provides partition level replication from version 0.8.x.
8) Kafka's file storage mechanism
Messages in kafka are classified by topic. Producers send messages to kafka broker through topic, and consumers read data through topic. However, at the physical level, topics can be grouped by partitions. A topic can be divided into several partitions, which can also be subdivided into segments. A partition is physically composed of multiple segments.
For the sake of explanation, suppose there is only one kafka cluster and only one kafka broker, that is, only one physical machine. In this kafka The log file storage path of kafka is defined in the server.properties configuration file of broker to set the kafka message file storage directory. At the same time, a topic: test is created. The number of partitions is 4. When kafka is started, four directories can be generated in the log storage path. In the kafka file storage, there are many different partitions under the same topic. Each partition It is a directory. The name rule of partition is: topic name + ordinal number. The first ordinal number starts from 0.
What is segment?
If we take partition as the minimum storage unit, we can imagine that when Kafka producer continuously sends messages, it will inevitably cause infinite expansion of partition files, which will have a serious impact on the maintenance of message files and the cleaning of messages that have been consumed. Therefore, partition is subdivided by segment. Each partition (directory) is equivalent to that a huge file is evenly allocated to multiple equal size segment data files (the number of messages in each segment file is not necessarily equal). This feature also facilitates the deletion of old segment s, that is, it facilitates the cleaning of consumed messages and improves the utilization of disk. Each partition only needs to support sequential read-write.
Segment file consists of two parts, namely ". Index" file and ". log" file, which are expressed as segment index file and data file respectively. The command rules of the two files are: the first segment of the partition global starts from 0, and each subsequent segment file name is the offset value (offset) of the last message of the previous segment file. The value size is 64 bits, and the length of 20 digit characters. No digits are filled with 0.
9) Data reliability and persistence assurance
When the producer sends data to the leader, the level of data reliability can be set through the request.required.acks parameter:
- 1 (default): the leader of producer has successfully received the data and has been confirmed. If the leader goes down, the data will be lost;
- 0: producer does not need to wait for confirmation from the broker to continue sending the next batch of messages. In this case, the data transmission efficiency is the highest, but the data reliability is the lowest;
- -1: producer needs to wait for all follower s to confirm receiving data before sending once, with the highest reliability;
10) leader election
A message is considered submitted only if it is copied from the leader by all followers. In this way, some data can not be written into the leader, and it will be down before being copied by any follower, resulting in data loss. For producer, it can choose whether to wait for the message commit.
A very common way to elect a leader is "the minority is subordinate to the majority". In the process of data replication, there are multiple followers, and the data speed of each follower is different. When the leader goes down, the leader is the one with the most data on the current follower.
2, Deploy single Kafka
1) Deploy Kafka
Kafka service depends on Java environment by default. This time, Centos 7 system is used, and Java environment is available by default.
Software download link for Kafka cluster: https://pan.baidu.com/s/1VHUH-WsptDB2wOugxvfKVg
Extraction code: 47x7
[root@kafka ~]# tar zxf kafka_2.11-2.2.1.tgz [root@kafka ~]# mv kafka_2.11-2.2.1 /usr/local/kafka [root@kafka ~]# cd /usr/local/kafka/bin/ [root@kafka bin]# ./zookeeper-server-start.sh ../config/zookeeper.properties & #To start zookeeper, you need to specify the configuration file of zookeeper #It is necessary to add "&" symbol to indicate background operation, otherwise terminals in the foreground will be occupied [root@kafka bin]# ./kafka-server-start.sh ../config/server.properties & #Start kafka in the same way as starting zookeeper [root@kafka bin]# netstat -anpt | grep 9092 #kafka's listening port is 9092, confirm that the port is listening
Because kafka is scheduled through zookeeper, even a single kafka needs to start the zookeeper service. By default, the installation directory of kafka integrates zookeeper, which can be started directly.
2) Test Kafka
[root@kafka bin]# ./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test #Create a topic on the local machine with the name of test, the number of copies is 1, and the number of partitions is 1 [root@kafka bin]# ./kafka-topics.sh --list --bootstrap-server localhost:9092 #View the topic of this computer [root@kafka bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic test #Add a message to the created topic, and customize the message content >aaaa >bbbb >cccc [root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning aaaa bbbb cccc #Start a new terminal to test the read message, "-- from beginning" means to read from the beginning
Test successful!
3, Deploy Kafka cluster
1) Environmental preparation
| System version | host name | IP address | Services running |
|---|---|---|---|
| Centos 7 | kafka01 | 192.168.1.6 | Kafka+zookeeper |
| Centos 7 | kafka02 | 192.168.1.7 | Kafka+zookeeper |
| Centos 7 | kafka03 | 192.168.1.8 | Kafka+zookeeper |
2) Deploy zookeeper cluster
1) Host kafka01 configuration
[root@kafka01 ~]# tar zxf zookeeper-3.4.9.tar.gz [root@kafka01 ~]# mv zookeeper-3.4.9 /usr/local/zookeeper #Install zookeeper [root@kafka01 ~]# cd /usr/local/zookeeper/conf [root@kafka01 conf]# cp -p zoo_sample.cfg zoo.cfg [root@kafka01 conf]# sed -i 's/dataDir=\/tmp\/zookeeper/dataDir=\/usr\/local\/zookeeper\/data/g' zoo.cfg [root@kafka01 conf]# echo "server.1 192.168.1.6:2888:3888" >> zoo.cfg [root@kafka01 conf]# echo "server.2 192.168.1.7:2888:3888" >> zoo.cfg [root@kafka01 conf]# echo "server.3 192.168.1.8:2888:3888" >> zoo.cfg [root@kafka01 conf]# egrep -v '^$|^#' zoo.cfg #Changed profile tickTime=2000 #Heartbeat detection time between nodes in milliseconds initLimit=10 #Disconnect the corresponding node after the number of check failures between nodes exceeds syncLimit=5 #Up to 5 accesses to synchronize data dataDir=/usr/local/zookeeper/data #Log file storage path clientPort=2181 #Monitor port server.1 192.168.1.6:2888:3888 server.2 192.168.1.7:2888:3888 server.3 192.168.1.8:2888:3888 #Declare the host participating in the cluster, ports 2888 and 3888 are used for internal communication of the cluster [root@kafka01 conf]# mkdir /usr/local/zookeeper/data [root@kafka01 conf]# echo 1 > /usr/local/zookeeper/data/myid #Create the required directory and set the ID number of the node [root@kafka01 conf]# scp -r /usr/local/zookeeper/ root@192.168.1.7:/usr/local/ [root@kafka01 conf]# scp -r /usr/local/zookeeper/ root@192.168.1.8:/usr/local/ #Copy the configured zookeeper directory to other nodes in the cluster [root@kafka01 conf]# /usr/local/zookeeper/bin/zkServer.sh start [root@kafka01 conf]# netstat -anpt | grep 2181 #Confirm that the zookeeper service port is listening
2) Host kafka02 configuration
[root@kafka02 ~]# echo 2 > /usr/local/zookeeper/data/myid #Modify ID number to 2 [root@kafka02 ~]# /usr/local/zookeeper/bin/zkServer.sh start #Start zookeeper
3) Host kafka03 configuration
[root@kafka03 ~]# echo 3 > /usr/local/zookeeper/data/myid #Modify ID number to 3 [root@kafka03 ~]# /usr/local/zookeeper/bin/zkServer.sh start #Start zookeeper
4) View the roles of nodes within a zookeeper cluster
[root@kafka01 conf]# /usr/local/zookeeper/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: follower #The role is follower [root@kafka02 ~]# /usr/local/zookeeper/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: follower #The role is follower [root@kafka03 ~]# /usr/local/zookeeper/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: leader #The role is leader
3) Deploy Kafka cluster
1) Host kafka01 configuration
[root@kafka01 ~]# tar zxf kafka_2.11-2.2.1.tgz [root@kafka01 ~]# mv kafka_2.11-2.2.1 /usr/local/kafka #Install kafka [root@kafka01 ~]# cd /usr/local/kafka/config/ [root@kafka01 config]# sed -i 's/broker.id=0/broker.id=1/g' server.properties [root@kafka01 config]# sed -i 's/#listeners=PLAINTEXT:\/\/:9092/listeners=PLAINTEXT:\/\/192.168.1.6:9092/g' server.properties [root@kafka01 config]# sed -i 's/#advertised.listeners=PLAINTEXT:\/\/your.host.name:9092/advertised.listeners=PLAINTEXT:\/\/192.168.1.6:9092/g' server.properties [root@kafka01 config]# sed -i 's/log.dirs=\/tmp\/kafka-logs/log.dirs=\/usr\/local\/zookeeper\/data/g' server.properties [root@kafka01 config]# sed -i 's/zookeeper.connect=localhost:2181/zookeeper.connect=192.168.1.6:2181,192.168.1.7:2181,192.168.1.8:2181/g' server.properties [root@kafka01 config]# sed -i 's/zookeeper.connection.timeout.ms=6000/zookeeper.connection.timeout.ms=600000/g' server.properties #Modify the configuration file of kafka [root@kafka01 config]# egrep -v '^$|^#' server.properties #Modified profile broker.id=1 #ID number of kafka, here is 1, and other nodes are 2 and 3 in turn listeners=PLAINTEXT://192.168.1.6:9092 - node listening address, fill in each node's own IP address advertised.listeners=PLAINTEXT://192.168.1.6:9092 - the port used by internal communication of nodes in the cluster, fill in the IP address of each node num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/usr/local/zookeeper/data num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=192.168.1.62:2181,192.168.1.7:2181,192.168.1.8:2181 #Declare the address of the link zookeeper node zookeeper.connection.timeout.ms=600000 #The time to modify this, in milliseconds, to prevent the connection zookeeper from timeout group.initial.rebalance.delay.ms=0 [root@kafka01 config]# scp -r /usr/local/kafka/ root@192.168.1.7:/usr/local/ [root@kafka01 config]# scp -r /usr/local/kafka/ root@192.168.1.8:/usr/local/ #Send the modified kafka directory to other nodes [root@kafka01 bin]# ./kafka-server-start.sh ../config/server.properties & #Start kafka [root@kafka01 bin]# netstat -anpt | grep 9092 //Confirm that the port is listening
2) Host kafka02 configuration
[root@kafka02 ~]# cd /usr/local/kafka/ [root@kafka02 kafka]# sed -i 's/broker.id=1/broker.id=2/g' config/server.properties [root@kafka02 kafka]# sed -i 's/192.168.1.6:9092/192.168.1.7:9092/g' config/server.properties #Modify the conflict with kafka01 [root@kafka02 kafka]# cd bin/ [root@kafka02 bin]# ./kafka-server-start.sh ../config/server.properties & #Start kafka [root@kafka02 bin]# netstat -anpt | grep 9092 #Confirm that the port is listening
3) Host kafka03 configuration
[root@kafka03 ~]# cd /usr/local/kafka/ [root@kafka03 kafka]# sed -i 's/broker.id=1/broker.id=3/g' config/server.properties [root@kafka03 kafka]# sed -i 's/192.168.1.6:9092/192.168.1.8:9092/g' config/server.properties #Modify the conflict with kafka01 [root@kafka03 kafka]# cd bin/ [root@kafka03 bin]# ./kafka-server-start.sh ../config/server.properties & #Start kafka [root@kafka03 bin]# netstat -anpt | grep 9092 #Confirm that the port is listening
4) Publish and subscribe message test
[root@kafka01 bin]# ./kafka-topics.sh --create --bootstrap-server 192.168.1.6:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
#Create a topic named my replicated topic
[root@kafka01 bin]# ./kafka-topics.sh --describe --bootstrap-server 192.168.1.6:9092 --topic my-replicated-topic
#View the status and leader of topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
#The returned information indicates that the number of partition s is 1, the number of replicas is 3, and the number of segment bytes is 1073741824
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,3,Isr: 1,3,2
#The node with name "my replicated topic" and ID 1 is leader
[root@kafka01 bin]# ./kafka-console-producer.sh --broker-list 192.168.1.6:9092 --topic my-replicated-topic
#Insert data into the topic named my replicated topic for testing
>aaaaaaaa
>bbbbbbbbbbbbbbb
>ccccccccccccccccccccccc
[root@kafka02 bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.1.7:9092 --from-beginning --topic my-replicated-topic
#View inserted data on other nodes
aaaaaaaa
bbbbbbbbbbbbbbb
ccccccccccccccccccccccc5) Simulate leader downtime, check the status of topic and the new leader
[root@kafka01 bin]# ./kafka-topics.sh --describe --bootstrap-server 192.168.1.6:9092 --topic my-replicated-topic
#View the status of the topic named my replicated topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,3,Isr: 1,3,2
#It can be seen that the node with ID 1 is a leader
[root@kafka01 bin]# ./kafka-server-stop.sh
#Node with ID 1 stops kafka service
[root@kafka02 bin]# ./kafka-topics.sh --describe --bootstrap-server 192.168.1.7:9092 --topic my-replicated-topic
#View the topic status on the second node
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 1,3,Isr: 3,2
#You can see that the leader has been replaced by a node with ID 3————————Thank you for reading————————