1. Introduction to Kafka
1.1. Main functions
According to the introduction of the official website, ApacheKafka ® is a distributed streaming media platform, which has three main functions:
1: It lets you publish and subscribe to streams of records
2: it lets you store streams of records in a fault tolerant way
3: It lets you process streams of records as they occur
1.2. Use scenario
1: building real-time streaming data pipelines that reliable get data between systems or applications
2: Building real-time streaming applications that transform or react to the streams of data. Build real-time stream data processing program to transform or process data stream, data processing function
1.3. Detailed introduction
Kafka is currently mainly used as a distributed publish subscribe message system. Here is a brief introduction to Kafka's basic mechanism
1.3.1 message transmission process
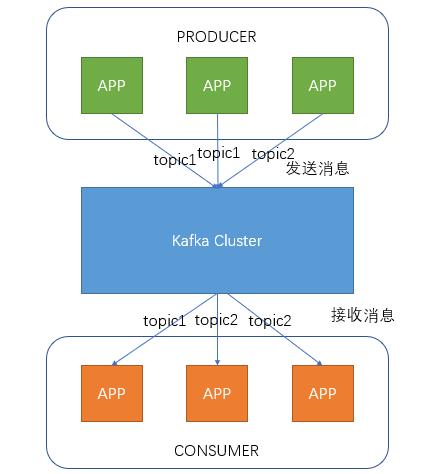
Producer is the producer who sends messages to Kafka cluster. Before sending messages, the messages will be classified as topic. The figure above shows that two producers send messages classified as topic1 and the other sends messages classified as topic2.
Topic is the topic. By specifying a topic for messages, messages can be classified. Consumers can only focus on the messages in the topic they need
Consumer is the consumer. By establishing a long connection with kafka cluster, the consumer constantly pulls messages from the cluster, and then can process these messages.
From the above figure, we can see that the number of consumers and producers under the same Topic is not corresponding.
1.3.2 kafka server message storage strategy
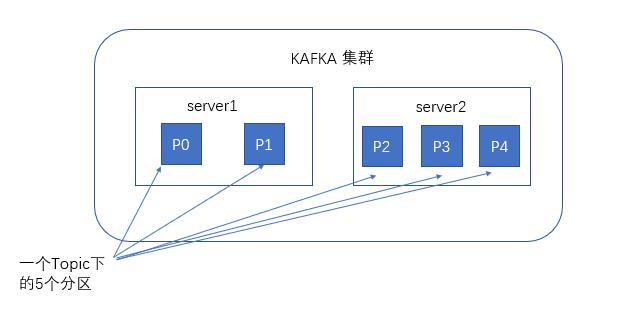
When it comes to kafka storage, we have to mention partitions, that is, partitions. When creating a topic, you can specify the number of partitions at the same time. The more partitions, the greater the throughput, but the more resources you need, and the higher the unavailability. After receiving the messages sent by the producers, kafka will store the messages to different ones according to the equalization strategy Zoning.
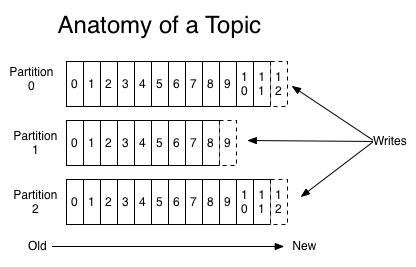
In each partition, messages are stored in order, and the latest received messages are consumed.
1.3.3 interaction with producers
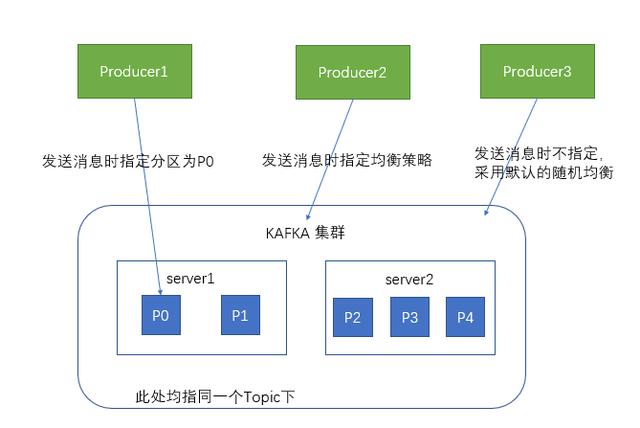
When the producer sends messages to the kafka cluster, it can send them to the specified partition through the specified partition
You can also send messages to different partitions by specifying an equalization strategy
If not specified, the message will be randomly stored in different partitions using the default random equalization strategy
1.3.4 interaction with consumers
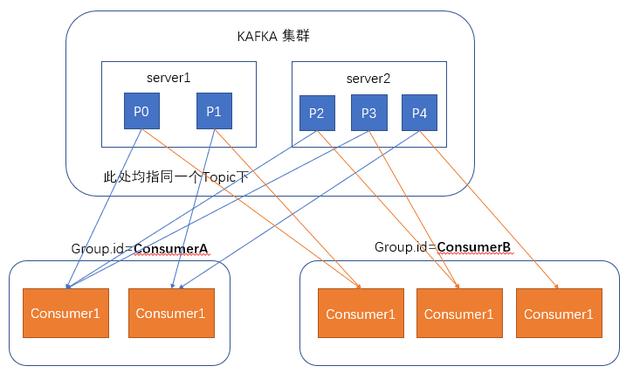
When consumers consume messages, kafka uses offset to record the current consumption position
In kafka's design, there can be multiple different groups to consume messages under the same topic at the same time. As shown in the figure, we have two different groups to consume messages at the same time. Their consumption record positions offset are different and do not interfere with each other.
For a group, the number of consumers should not be more than the number of partitions, because in a group, each partition can only be bound to one consumer at most, that is, one consumer can consume multiple partitions, and one partition can only consume one consumer
Therefore, if the number of consumers in a group is greater than the number of partitions, the redundant consumers will not receive any messages.
2. Kafka installation and use
2.1. Download
You can download the latest Kafka installation package on the Kafka official website http://kafka.apache.org/downloads, choose to download the binary version of tgz file, and you may need fq according to the network status. Here, we choose the version 0.11.0.1, the latest version at present
2.2. installation
Kafka is a program written in scala and running on the jvm virtual machine. Although it can also be used on windows, Kafka is basically running on the linux server, so we also use linux here to start today's practice.
First of all, make sure that you have jdk installed on your machine. kafka needs java running environment. The previous kafka also needs zookeeper. The new version of kafka has a built-in zookeeper environment, so we can use it directly
To install, if we only need to make the simplest attempt, we just need to unzip to any directory. Here we unzip the kafka package to the / home directory
2.3. configuration
Under the kafka decompression directory, there is a config folder, which contains our configuration files
Consumer.properties consumer configuration. This configuration file is used to configure the consumers opened in Section 2.5. Here we use the default
producer.properties producer configuration. This configuration file is used to configure the producers opened in Section 2.5. Here we use the default
Configuration of server.properties kafka server. This configuration file is used to configure kafka server. At present, only a few basic configurations are introduced
- broker.id states the unique ID of the current kafka server in the cluster, which needs to be configured as integer, and the ID of each kafka server in the cluster should be unique. We can use the default configuration here
- listeners state the port number that this kafka server needs to listen to. If the virtual machine is running on the local machine, you may not need to configure this item. By default, the address of localhost will be used. If it is running on the remote server, you must configure it, for example:
listeners=PLAINTEXT:// 192.168.180.128:9092. And ensure that the 9092 port of the server can be accessed
3. zookeeper.connect states that the address of the zookeeper connected by kafka needs to be configured as the address of the zookeeper. Because this time we use the zookeeper in the higher version of kafka, we can use the default configuration
zookeeper.connect=localhost:2181
2.4. operation
- Start zookeeper
cd enters the kafka decompression directory, and input
bin/zookeeper-server-start.sh config/zookeeper.properties
After starting zookeeper successfully, you will see the following output

2. Start kafka
cd enters the kafka decompression directory, input
bin/kafka-server-start.sh config/server.properties
After starting kafka successfully, you will see the following output

2.5. Create first message
2.5.1 create a topic
Kafka manages the same kind of data through topic. Using the same topic for the same kind of data can make data processing more convenient
Open the terminal in the kafka decompression directory and input
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Create a topic named test

After the topic is created, you can enter
bin/kafka-topics.sh --list --zookeeper localhost:2181
To view the topic s that have been created
2.4.2 create a message consumer
Open the terminal in the kafka decompression directory and input
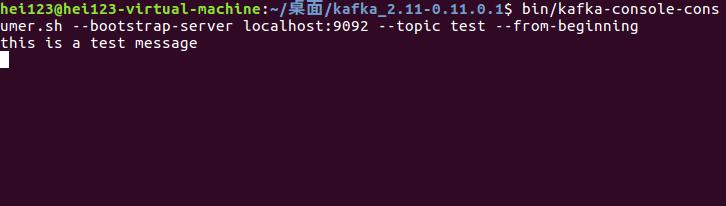
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
You can create a consumer whose topic is test

After the creation of the consumer, because no data has been sent, no data has been printed out after execution
But don't worry. Don't close this terminal. Open a new terminal. Next, we create the first message producer
2.4.3 create a message producer
Open a new terminal in the kafka decompression directory and input
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Editor page to enter after execution
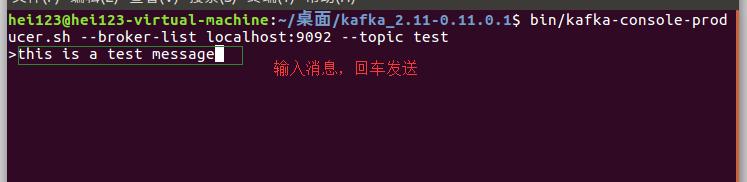
After sending the message, you can go back to our message consumer terminal. You can see that the terminal has printed out the message we just sent
3. Using kafka in java program
As in the previous section, we are now trying to use kafka in java programs
3.1 create Topic
public static void main(String[] args) { //Create topic properties props = new properties(); props. Put ("bootstrap. Servers", "192.168.180.128:9092"); adminclient adminclient = adminclient. Create (props); ArrayList < newtopic > topics = new ArrayList < newtopic > (); newtopic newtopic = new newtopic ("topic test", 1, (short) 1); topics. Add (newtopic); create topics result result = adminclient. Createtopic s(topics); try { result.all().get(); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
The AdminClient API can be used to control the configuration of kafka server. Here we use
NewTopic(String name, int numPartitions, short replicationFactor)
To create a Topic named "Topic test", the number of partitions is 1, and the replication factor is 1
3.2 Producer sending message
public static void main(String[] args){ Properties props = new Properties(); props.put("bootstrap.servers", "192.168.180.128:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<String, String>(props); for (int i = 0; i < 100; i++) producer.send(new ProducerRecord<String, String>("topic-test", Integer.toString(i), Integer.toString(i))); producer.close(); }
After sending the message with producer, the server-side consumer mentioned in 2.5 can listen to the message. You can also use the java consumer program described next to consume messages
3.3 Consumer consumer consumption message
public static void main(String[] args){ Properties props = new Properties(); props.put("bootstrap.servers", "192.168.12.65:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); final KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(props); consumer.subscribe(Arrays.asList("topic-test"),new ConsumerRebalanceListener() { public void onPartitionsRevoked(Collection<TopicPartition> collection) { } public void onPartitionsAssigned(Collection<TopicPartition> collection) { //Set the offset to the beginning consumer. Seektobeeting (Collection);}}); while (true) {consumer record s < string, string > records = consumer. Poll (100); for (consumer record < string, string > record: Records) system. Out. Printf ("offset =% D, key =% s, value =% s% n", record. Offset(), record. Key(), record. Value());}}
Here, we use the consumption API to create a common java consumer program to listen to the Topic named "Topic test". Whenever a producer sends a message to kafka server, our consumers can receive the message sent.
4. Using spring Kafka
Spring kafka is a spring subproject in the incubation stage. It can use the features of spring to make us more convenient to use kafka
4.1 basic configuration information
Like other spring projects, configuration is always necessary. Here we use java configuration to configure our kafka consumers and producers.
- Import pom file
<!--kafka start--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.11.0.1</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>0.11.0.1</version> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.3.0.RELEASE</version> </dependency>
- Create configuration class
We will create a new class named KafkaConfig in the main directory
@Configuration @EnableKafka public class KafkaConfig { }
- Configure Topic
Add configuration to kafkaConfig class
@Configuration @EnableKafka public class KafkaConfig { //In this paper, the author analyzes the characteristics of
- Configure producer Factory and Template
Append in the configuration file above
//producer config start @Bean public ProducerFactory<Integer, String> producerFactory() { return new DefaultKafkaProducerFactory<Integer,String>(producerConfigs()); } @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<String,Object>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.180.128:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); return props; } @Bean public KafkaTemplate<Integer, String> kafkaTemplate() { return new KafkaTemplate<Integer, String>(producerFactory()); } //producer config end
5. Configure ConsumerFactory
Append in the configuration file above
//consumer config start @Bean public ConcurrentKafkaListenerContainerFactory<Integer,String> kafkaListenerContainerFactory(){ ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<Integer, String>(); factory.setConsumerFactory(consumerFactory()); return factory; } @Bean public ConsumerFactory<Integer,String> consumerFactory(){ return new DefaultKafkaConsumerFactory<Integer, String>(consumerConfigs()); } @Bean public Map<String,Object> consumerConfigs(){ HashMap<String, Object> props = new HashMap<String, Object>(); props.put("bootstrap.servers", "192.168.180.128:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); return props; } //consumer config end
4.2 create message producer
//Using spring Kafka's template to send a single message to send multiple messages only needs to cycle multiple times to public static void main (string [] args) throws executionexception, interruptedexception {annotationconfidapplicationcontext CTX = new annotationconfidapplicationcontext (kafkaconfig. Class); kafkatemplate < integer, string > kafkatemplate = (kafkatemplate < in teger, String>) ctx.getBean("kafkaTemplate"); String data="this is a test message"; ListenableFuture<SendResult<Integer, String>> send = kafkaTemplate.send("topic-test", 1, data); send.addCallback(new ListenableFutureCallback<SendResult<Integer, String>>() { public void onFailure(Throwable throwable) { } public void onSuccess(SendResult<Integer, S tring> integerStringSendResult) { } }); }4.3 creating message consumers
First, we create a class for message listening. When the topic named "topic test" receives the message, our listen method will call.
public class SimpleConsumerListener { private final static Logger logger = LoggerFactory.getLogger(SimpleConsumerListener.class); private final CountDownLatch latch1 = new CountDownLatch(1); @KafkaListener(id = "foo", topics = "topic-test") public void listen(byte[] records) { //do something here this.latch1.countDown(); } }
We also need to configure this class into KafkaConfig as a Bean
Append in configuration file
@Bean public SimpleConsumerListener simpleConsumerListener(){ return new SimpleConsumerListener(); }
By default, spring kafka creates a thread for each listening method to pull messages from kafka server
Last
Thanks for your attention and forwarding.