Kafka Stream concepts and initial high-level architecture diagrams
Kafka Stream is a new Feature introduced by Apache Kafka from version 0.10 that provides streaming and analysis of data stored in Kafka.In short, Kafka Stream is a class library for stream computing, similar to Storm, Spark Streaming, Flink, but much lighter.
Basic concepts of Kafka Stream:
- Kafka Stream is a client-side library (lib) that handles analysis of data stored in Kafka
- Since Kafka Streams is a lib of Kafka, the implementation of the program does not depend on a separate environment
- Kafka Stream achieves efficient state operation through state store
- Supports primitive Processor and high-level Abstract DSL
High-level architecture diagram of Kafka Stream: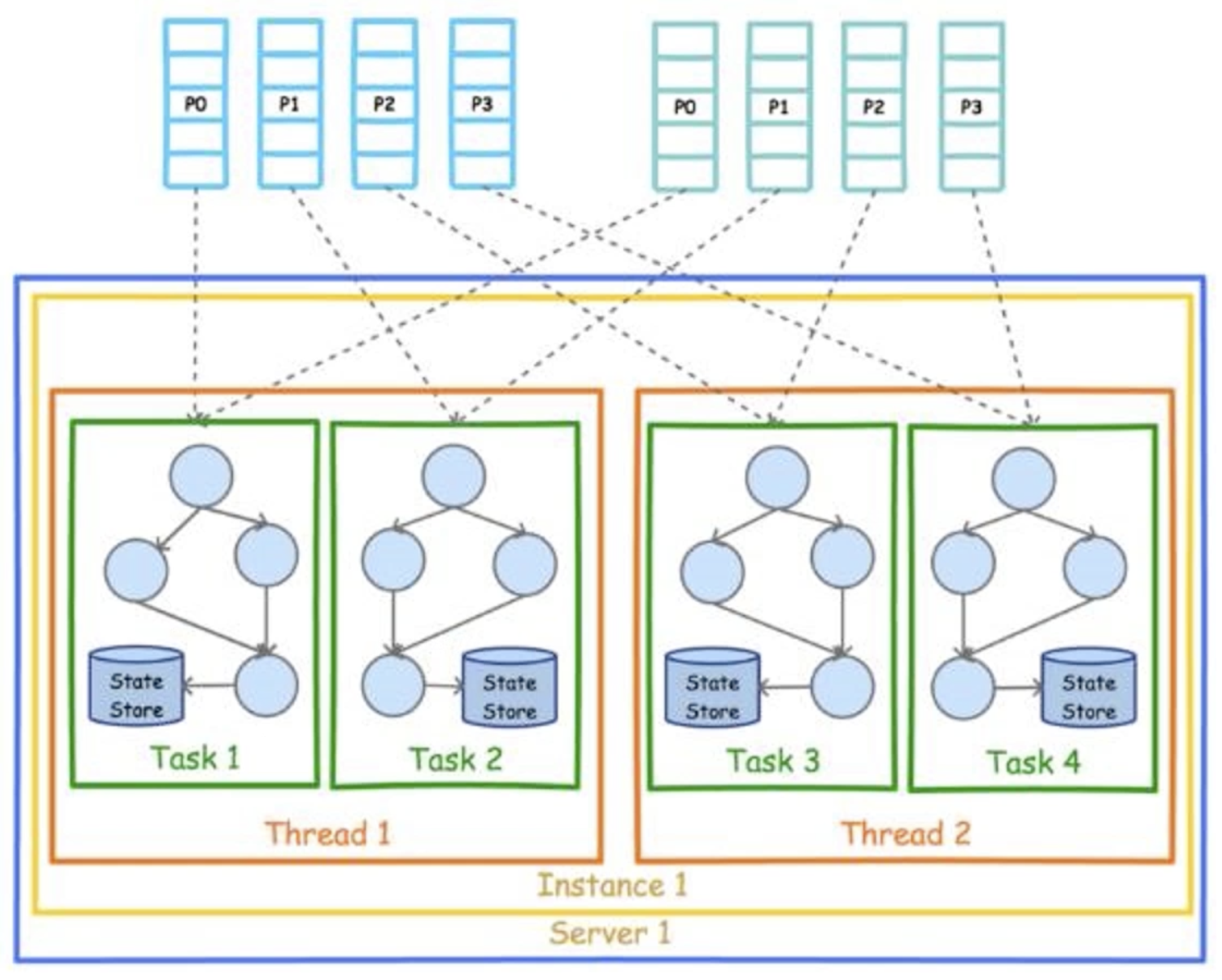
- Partition data is distributed to different Task s, which are used primarily for streaming parallel processing
- Each Task has its own state store to record state
- There are multiple Task s in each Thread
Kafka Stream Core Concepts
Kafka Stream keywords:
- Stream and Stream Processors: Stream refers to the data stream, and stream processor refers to the unit that processes the data stream when it reaches a node
- Stream Processing Topology: A topology diagram that shows the direction of the data flow and the node location of the stream processor
- Source Processor and Sink Processor: Source Processor refers to the source of the data, the first processor, and Sink Processor, on the other hand, is a processor that produces the final output.
As shown in the following figure: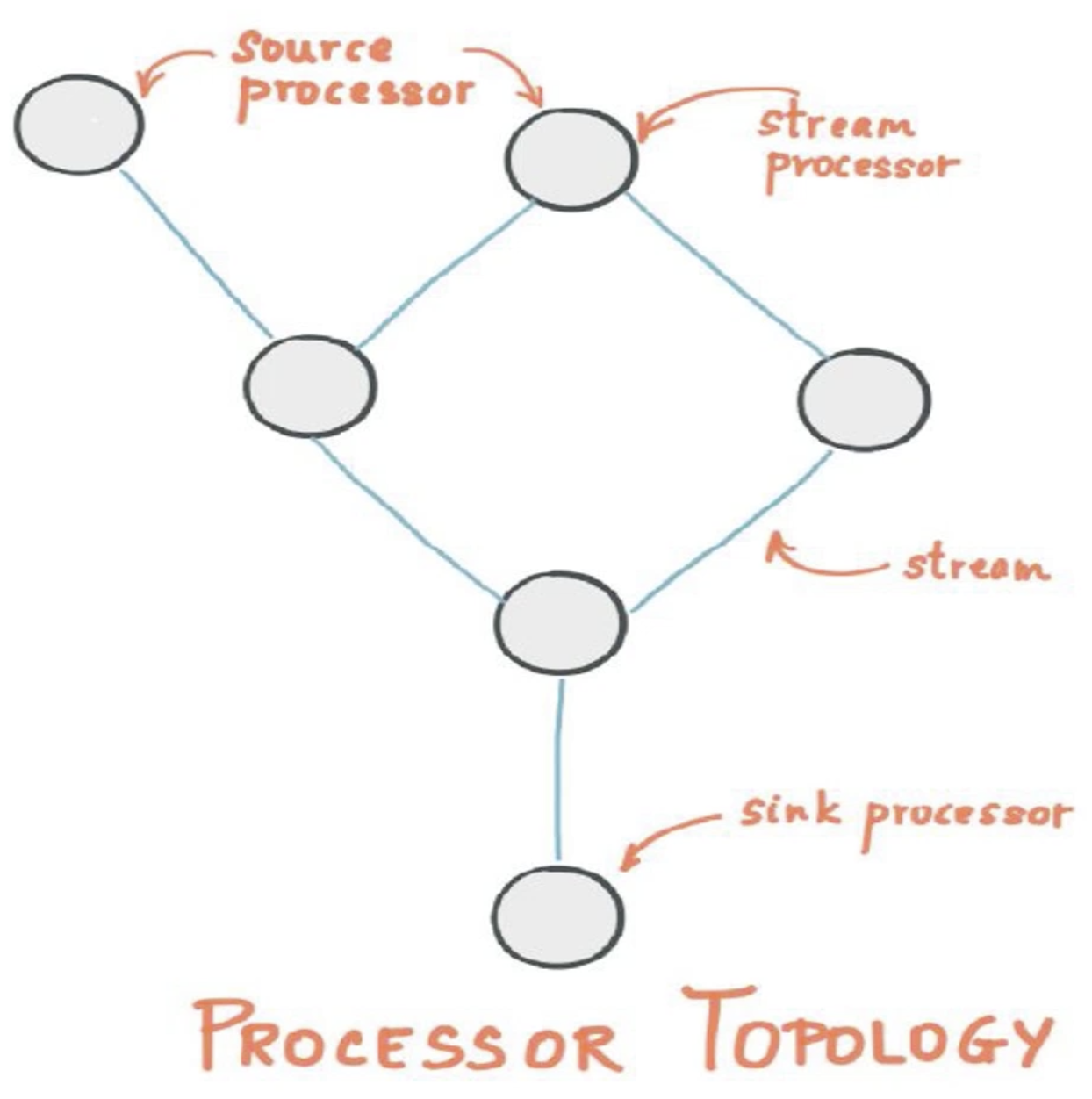
Kafka Stream Usage Demo
The following is a complete high-level architecture diagram of Kafka Stream: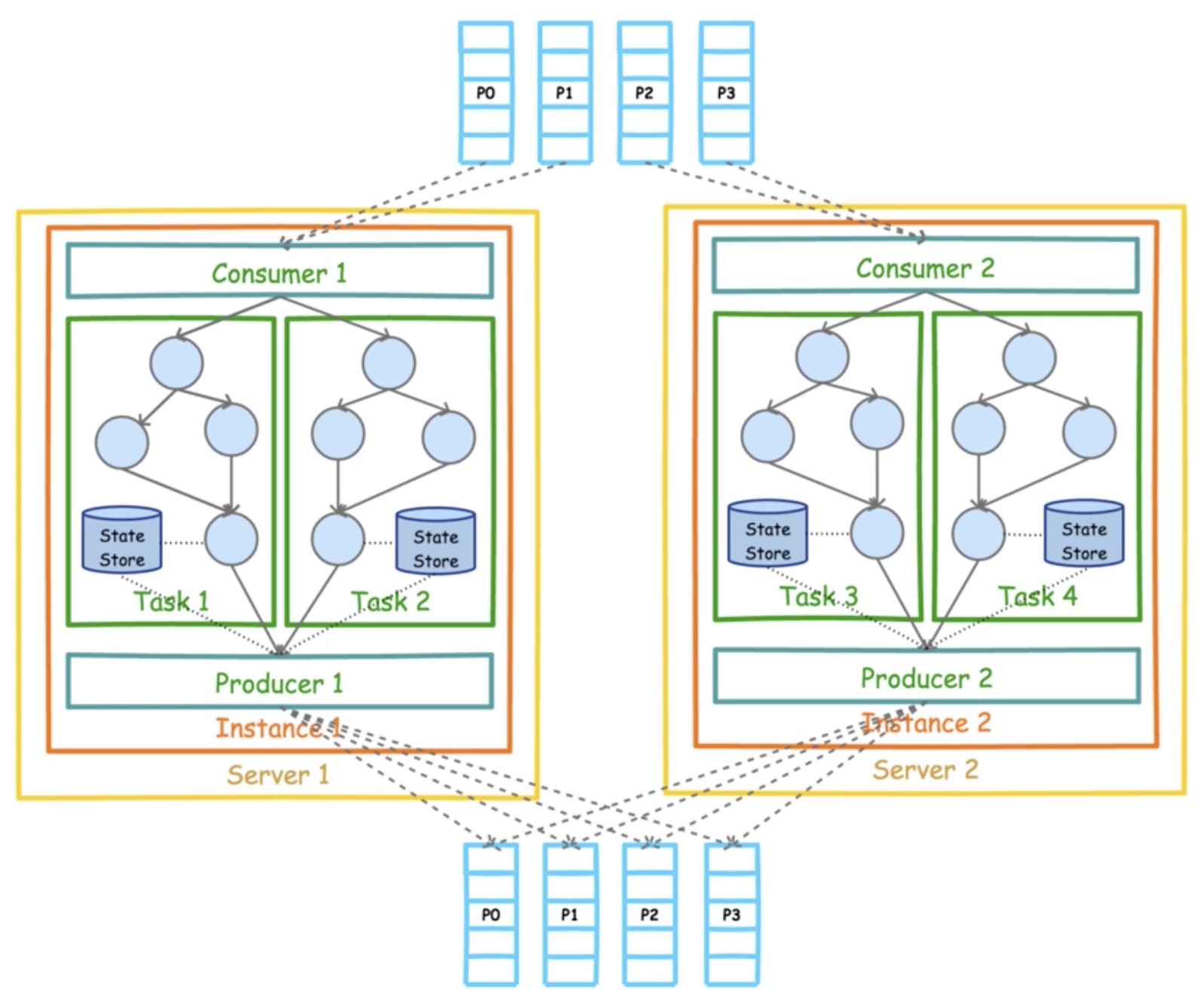
As you can see from the diagram above, Consumer s consume a set of Partitions that can be in one Topic or more Topics.Then data streams are formed, and after each stream processor, they are output to a set of Partitions via a Producer, which can also be in one Topic or more Topics.This process is the input and output of the data stream.
Therefore, before using the Stream API, we need to create two Topics, one as input and one as output.Use the command line to create two Topics on the server:
[root@txy-server2 ~]# kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic input-topic [root@txy-server2 ~]# kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic output-topic
Since there is no Stream API in the previously dependent kafka-clients package, an additional dependent package for Stream needs to be introduced.Add the following dependencies to your project:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.5.0</version>
</dependency>Next, take a classic word frequency statistic as an example to demonstrate the use of the Stream API.Code example:
package com.zj.study.kafka.stream;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.util.List;
import java.util.Properties;
public class StreamSample {
private static final String INPUT_TOPIC = "input-topic";
private static final String OUTPUT_TOPIC = "output-topic";
/**
* Build Configuration Properties
*/
public static Properties getProperties() {
Properties properties = new Properties();
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "49.232.153.84:9092");
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-app");
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return properties;
}
public static KafkaStreams createKafkaStreams() {
Properties properties = getProperties();
// Building Stream Structure Topology
StreamsBuilder builder = new StreamsBuilder();
// Build wordCount this Processor
wordCountStream(builder);
Topology topology = builder.build();
// Build KafkaStreams
return new KafkaStreams(topology, properties);
}
/**
* Define flow calculation process
* Examples are word frequency statistics
*/
public static void wordCountStream(StreamsBuilder builder) {
// Constantly from INPUT_Get new data on TOPIC and append to an abstract object on the stream
KStream<String, String> source = builder.stream(INPUT_TOPIC);
// KTable is an abstract object of a dataset
KTable<String, Long> count = source.flatMapValues(
// Split strings with spaces as separators
v -> List.of(v.toLowerCase().split(" "))
// Group Statistics by value
).groupBy((k, v) -> v).count();
KStream<String, Long> sink = count.toStream();
// Output statistics to OUTPUT_TOPIC
sink.to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
}
public static void main(String[] args) {
KafkaStreams streams = createKafkaStreams();
// Start the Stream
streams.start();
}
}The relationship and difference between KTable and KStream are as follows: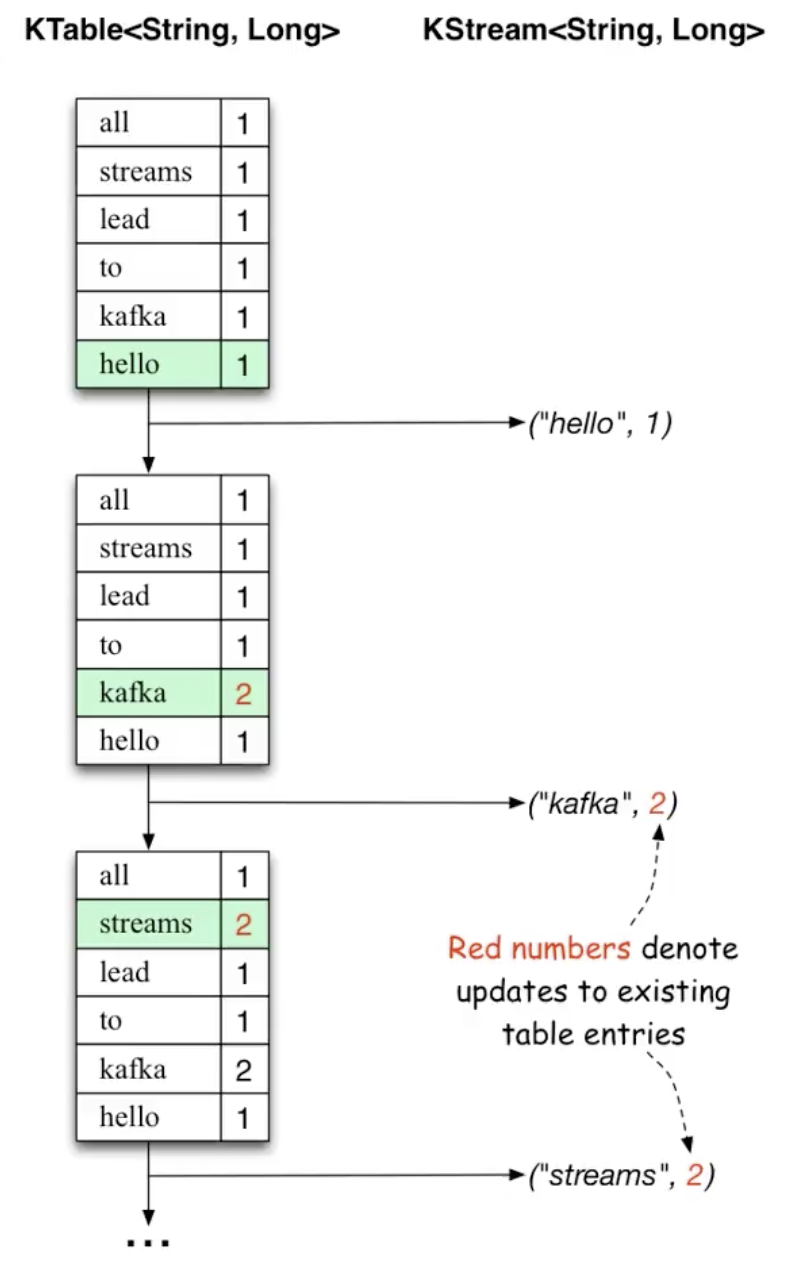
- KTable is similar to a time slice in that the data entered in a time slice is update d to maintain this table
- KStream doesn't have the concept of update, it keeps appending
Run the above code and use kafka-console-on the serverProducer.shThe script command produces some data to input-top as follows:
[root@txy-server2 ~]# kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic input-topic >Hello World Java >Hello World Kafka >Hello Java Kafka >Hello Java
Then run kafka-console-Consumer.shScript commands consume data from output-top and print it.Specifically as follows:
[root@txy-server2 ~]# kafka-console-consumer.sh --bootstrap-server 172.21.0.10:9092 --topic output-topic --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer --from-beginning
Console output:
world 2 hello 3 java 2 kafka 2 hello 4 java 3
As you can see from the output, Kafka Stream first performs a word frequency statistic on the first three lines, so the first half of the paragraph is:
world 2 hello 3 java 2 kafka 2
After the last line of input, we make another word frequency statistic and output the new statistic result. The other unchanged ones do not output, so we print the last line:
hello 4 java 3
This is also a reflection of KTable and KStream, which can be seen from the test results that Kafka Stream streams in real time and only outputs for changing content at a time.
foreach method
In the previous example, we read data from one Topic and stream it to another Topic.In some scenarios, however, we may not want to export the result data to Topic, but rather write it to some storage services, such as Elastic Search, MongoDB, MySQL, and so on.
In this scenario, you can use the foreach method, which iterates over elements in the stream.We can store data in containers such as Map, List, and so on in foreach, then write it in bulk to a database or other storage middleware.
Example foreach method use:
public static void foreachStream(StreamsBuilder builder) {
KStream<String, String> source = builder.stream(INPUT_TOPIC);
source.flatMapValues(
v -> List.of(v.toLowerCase().split(" "))
).foreach((k, v) -> System.out.println(k + " : " + v));
}