Written in the foregoing, the author first read the source code of the framework, so there may be some misunderstanding errors or no detailed explanation. If you find errors in the reading process, you are welcome to comment and point out in the article below. The article will be updated in succession. You can pay attention to it or collect it. Please trust me before forwarding it. Thank you. By the way, I'm looking at version 2.2.1. Last blog, JStorm Source Reading Series--01--Nimbus Startup Analysis In the initFollowerThread method, if the current Nimbus becomes a Leader, it will be responsible for performing some initialization init operations. Now let's talk about the first initialization operation, the topology assignment. This article will explain in detail (very long, so take a look) how to allocate resources for a topology.
_Beginning with the method initTopologyAssign, TopologyAssign is a singleton object. After a simple assignment operation is done in the init method of this class and a scheduler instance object is initialized, a daemon thread is established. The purpose of this daemon thread is to maintain one from within TopologyAs continuously. The blocking queue reads the topological tasks submitted by the system and calls the corresponding method doTopologyAssignment to perform the assignment operation. Code is relatively simple, do not waste the layout to paste.
The following is the source code of the doTopologyAssignment method.
protected boolean doTopologyAssignment(TopologyAssignEvent event) { Assignment assignment; try { Assignment oldAssignment = null; boolean isReassign = event.isScratch(); if (isReassign) { //If there is old allocation information, the old allocation information needs to be stored first. oldAssignment = nimbusData.getStormClusterState().assignment_info(event.getTopologyId(), null); } //Call methods to perform new assignments assignment = mkAssignment(event); //Add task to metrics of the cluster pushTaskStartEvent(oldAssignment, assignment, event); if (!isReassign) { //If you are a new topology, you need to set the topology to active state setTopologyStatus(event); } } catch (Throwable e) { LOG.error("Failed to assign topology " + event.getTopologyId(), e); event.fail(e.getMessage()); return false; } if (assignment != null) //Back up the topology to ZK backupAssignment(assignment, event); event.done(); return true; }
So the most important method is mkAssignment, where the actual allocation operation is performed. Here is a detailed description of this method.
prepareTopologyAssign
_prepareTopologyAssign This method aims to initialize the context information of the topology assignment and generate an instance object of TopologyAssignContext. This context object needs to store a lot of key information about the topology, including the component information of the topology (saved with StormTopology object, which will be described in detail when adding acker), the configuration information of the topology, all task IDs on the topology, and dead task id s, unstopped task IDS (explained here is Those supervisor s die, but the worker continues to run is called unstopworker, and the task contained in the unstopworker is called unstoppedTask. As well as the worker to which the topology can be assigned, the information mentioned above will be slowly initialized in this method. Let's take a step by step. The source code of the prepareTopologyAssign method is relatively long, which is explained in part.
//Create a context instance object TopologyAssignContext ret = new TopologyAssignContext(); String topologyId = event.getTopologyId(); ret.setTopologyId(topologyId); int topoMasterId = nimbusData.getTasksHeartbeat().get(topologyId).get_topologyMasterId(); ret.setTopologyMasterTaskId(topoMasterId); LOG.info("prepareTopologyAssign, topoMasterId={}", topoMasterId); Map<Object, Object> nimbusConf = nimbusData.getConf(); //Read the configuration information of the topology from nimbus according to the topology id Map<Object, Object> topologyConf = StormConfig.read_nimbus_topology_conf(topologyId, nimbusData.getBlobStore()); //Here we read a structure of each component in the topology, and we will explain the composition of this class later. StormTopology rawTopology = StormConfig.read_nimbus_topology_code(topologyId, nimbusData.getBlobStore()); ret.setRawTopology(rawTopology); //Set up some configuration information Map stormConf = new HashMap(); stormConf.putAll(nimbusConf); stormConf.putAll(topologyConf); ret.setStormConf(stormConf);
_Next, according to the current state of the cluster, initialize all supervisor s on a cluster and obtain all available worker s
StormClusterState stormClusterState = nimbusData.getStormClusterState(); // get all running supervisor, don't need callback to watch supervisor Map<String, SupervisorInfo> supInfos = Cluster.get_all_SupervisorInfo(stormClusterState, null); // init all AvailableWorkerPorts for (Entry<String, SupervisorInfo> supInfo : supInfos.entrySet()) { SupervisorInfo supervisor = supInfo.getValue(); if (supervisor != null) //Set all ports to be available, and then remove those already used worker s by HB //supervisor is a k-v, K is supervisorid, V is to save instance information supervisor.setAvailableWorkerPorts(supervisor.getWorkerPorts()); } //This method is to use HB to remove the suspended supervisor s. //The method of judgment is to get the latest HB time of each supervisor. //Subtract the most recent HB time from the current time and compare it with the timeout time. getAliveSupervsByHb(supInfos, nimbusConf);
_Next, we get the corresponding components of the taskid defined in the topology. Here we explain that for a topology, taskid is always allocated from the beginning, and the same components taskid are adjacent. For example, if you define a SocketSpout (parallelism degree 5), a PrintBolt (parallelism degree 4), then the taskid of SocketSpout may be 1-5, and the taskid of PrintBolt may be 6-9.
//This k-v, K is taskid, and V is the id of the component defined in the topology. //Students who have written about applications should know that TopologyBuilder needs to specify <component id, object, and parallelism> when setSpout or Bo lt. //eg: builder.setSpout("integer", new ReceiverSpout(), 2); Map<Integer, String> taskToComponent = Cluster.get_all_task_component(stormClusterState, topologyId, null); ret.setTaskToComponent(taskToComponent); //Get all taskid. Set<Integer> allTaskIds = taskToComponent.keySet(); ret.setAllTaskIds(allTaskIds);
_If the old topology assignment information exists, we need to set up unstoppedTasks, deadTasks, unstoppedWorkers and other information. The getFreeSlots method is then called to remove those workers that have been assigned. The process is relatively intuitive, obtaining all the topology allocation information on the cluster, and then removing those allocated workers from the original supInfos according to the worker information stored in each allocation information.
If there is no old allocation information, the type of topology allocation is ASSIGN_TYPE_NEW. If there is a topology with the same name, the old allocation information of the same name will also be set in the context. If the old allocation information exists, it is necessary to put the old allocation information into the context, and to determine whether it is ASSIGN_TYPE_REBALANCE or ASSIGN_TYPE_MONITOR, because the information of unstoppedWorkers needs to be set. At this point, the pre-allocation and creation of the topology allocation context are complete. At present, we have more important information about all the taskid of the topology and the basic component information of the topology.
Cluster assignTasks
_After the initialization of the topology context, we begin to assign the corresponding worker to the topology. However, we need to decide whether it is local mode or cluster mode. The local mode is relatively simple, find a suitable port, and then create a new worker resource object, ResourceWorkerSlot, to assign some key information such as ho. Stname, port, allTaskId are configured. Because local mode is relatively simple, even if you set up multiple workers, you won't start multiple jvms. In cluster mode, a worker represents a jvm process. Next, we will focus on the distribution under the cluster. I divide the allocation process (assign Tasks) on the cluster into three main parts: resource preparation, worker allocation and task allocation.
Set<ResourceWorkerSlot> assignments = null; if (!StormConfig.local_mode(nimbusData.getConf())) { IToplogyScheduler scheduler = schedulers.get(DEFAULT_SCHEDULER_NAME); //Distribution under clusters, as explained below assignments = scheduler.assignTasks(context); } else { assignments = mkLocalAssignment(context); }
Resource preparation
The first step is to determine whether the type of topological allocation meets the requirements or throw an exception if it does not. Next, a default instance object of the topology assignment context is generated based on the topology assignment context generated by the previous method. The construction method of the class DefaultTopologyAssignContext performs many very detailed operations. Including adding additional components for the topology, storing the corresponding information of taskid and components, calculating the number of worker needed for the topology, and calculating the number of unstopworker, etc.
//Initialize an allocated context object based on the previous context DefaultTopologyAssignContext defaultContext = new DefaultTopologyAssignContext(context); if (assignType == TopologyAssignContext.ASSIGN_TYPE_REBALANCE) { freeUsed(defaultContext); }
The following code is the construction method of Default Topology AssignContext
public DefaultTopologyAssignContext(TopologyAssignContext context){ super(context); try { sysTopology = Common.system_topology(stormConf, rawTopology); } catch (Exception e) { throw new FailedAssignTopologyException("Failed to generate system topology"); } sidToHostname = generateSidToHost(); hostToSid = JStormUtils.reverse_map(sidToHostname); if (oldAssignment != null && oldAssignment.getWorkers() != null) { oldWorkers = oldAssignment.getWorkers(); } else { oldWorkers = new HashSet<ResourceWorkerSlot>(); } refineDeadTasks(); componentTasks = JStormUtils.reverse_map(context.getTaskToComponent()); for (Entry<String, List<Integer>> entry : componentTasks.entrySet()) { List<Integer> componentTaskList = entry.getValue(); Collections.sort(componentTaskList); } totalWorkerNum = computeWorkerNum(); unstoppedWorkerNum = computeUnstoppedAssignments(); }
Adding additional components
From the above code, we can see that in the construction method of DefaultTopologyAssignContext, the first sentence is to call the parent constructor to initialize some parameters, and then call the system_topology method. Let's look at the internals of this method. The first method is to add an acker to the original topology. Topology, as a logical model of JStrom processing, provides users with very simple and powerful programming primitives. As long as two components are inherited separately, a topology model can be constructed. But in fact, a real running topology model is far more than a user-defined spout for processing input and a service for processing business. In order to ensure the reliability of the message, JStorm adds several very important bolt s to the actual model of the topology, such as Topology Metrics Management, Topology HB Management, and then introduces acker in detail to ensure the reliability of the message.
public static StormTopology system_topology(Map storm_conf, StormTopology topology) throws InvalidTopologyException { StormTopology ret = topology.deepCopy(); add_acker(storm_conf, ret); addTopologyMaster(storm_conf, ret); add_metrics_component(ret); add_system_components(ret); return ret; }
StormTopology
_Here we first introduce the StormTopology class, in order to understand. StormTopology is a class used to store the component information of the topology. Within this class, there are three very important member variables, spout, bolt and state_spout. The third one is not clear about its function for the time being, but the first two are very obvious. They store the two components of the topology, spout and bolt respectively.
private Map<String,SpoutSpec> spouts; // required private Map<String,Bolt> bolts; // required private Map<String,StateSpoutSpec> state_spouts; // required
The key in Map represents the id of the component we defined, the id mentioned above. There are two important member variables in SpoutSpec and Bolt.
private ComponentObject spout_object; // required private ComponentCommon common; // required
_ComponentObject is used to store serialized code information, and the second ComponentCommon is used to store important configuration information, including input stream, output stream and grouping information. There are three important member variables
//GlobalStreamId has two String member variables. CompoonentId represents the component id from which the input component flows. //StreaId represents a specific stream output by componentId private Map<GlobalStreamId,Grouping> inputs; // Source and grouping of input //StreamInfo has an important member variable List < String > output_fields, which represents the output domain. private Map<String,StreamInfo> streams; // Output stream private int parallelism_hint; // Parallelism
_According to the above structure, StormTopology can fully represent the flow direction of each component output in the topology.
acker
In this section, the author does not intend to start from the source code point of view. First, I will explain the role of an acker and how an acker works from a small example. As we all know, as a streaming framework, message reliability is one of the most important characteristics. Apart from the more advanced transaction framework, which ensures that messages are processed only once, JStorm itself provides at-least-once, which ensures that messages are processed. Here is an example of how this can be achieved.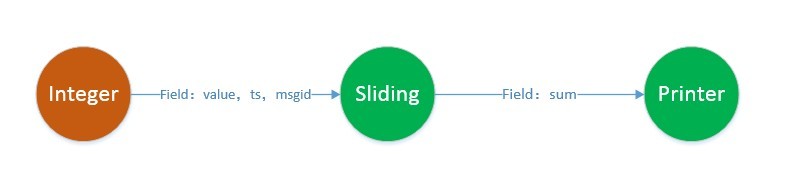
_As shown in the figure above, spout, sliding and printer as input are all bolt s for processing. Field represents the key corresponding to the elements in the tuple of output between them. StreamID is the default, and shuffle is the default without specifying the form of data stream grouping. The above is a very simple topological logical structure, and after adding_acker, the actual topological structure changes, as shown below.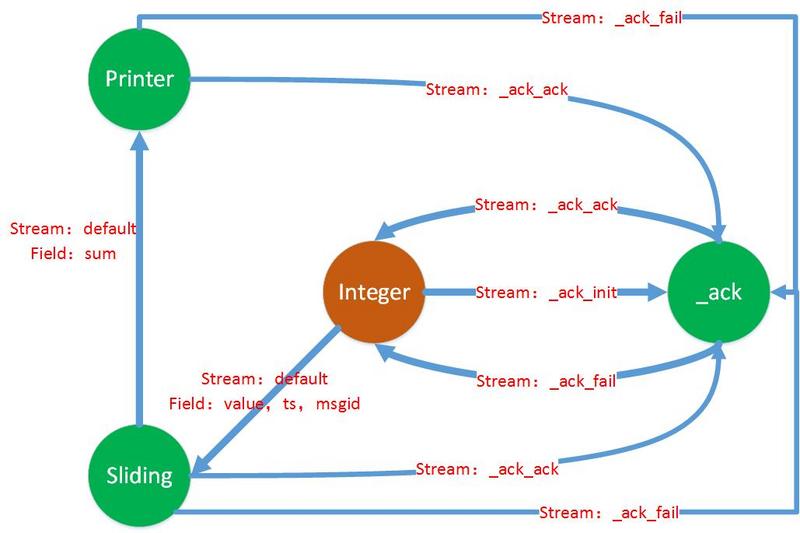
JStrom adds a ack bolt to the original topology, which is responsible for maintaining the reliability of the topology. It can be seen from the figure above that whenever a tuple is sent to the downstream bolt of the topology, it will be sent to ack to save it, and then every bolt that is processed subsequently calls ack function every time. It sends _ack (bolt) to receive the final processing ack within a specified time interval. Then _ack (bolt) sends a message to the original spout, which guarantees the reliability of a tuple. So in summary, _ack is a Bolt that maintains the reliability of the whole topology, so readers may ask, _ack contains so many messages, if a tuple passes through so many components, will it cause the tuple's topology tree to become very large? Here Ali uses XOR to realize a very simple, efficient and low-cost judgment method.
In fact, the content stored in ack is very simple, that is, a k-v key-value pair, k is a random and non-repetitive id(root_id), and remains unchanged throughout the process of tuple processing. Messages are stored as <root_id, random>, random is generated by each component that receives tuple, and random changes after each component. Once. As shown above, after sending < root_id, x > to sliding, integer also sends < root_id, x > to _ack. After sliding is processed, it sends < root_id, Y > to printer, and sends < root_id, x^ Y > to _ack. Then when printer is finished, it sends < root_id, Y > to _ack. At this time, the _ack internal pair The value of the message at root_id is x^x^y^y=0. That is to say, if the value of root_id corresponding to the specified timeout time is not 0, then we need to notify the task that gives this tuple (_ack is also a bolt, so there is also a source task that saves a message internally) and ask for a retransmit. These are the methods used by JStorm to ensure message reliability. They are intuitive and simple.
_Subsequent methods such as addTopologyMaster, add_metrics_component and add_system_components all add corresponding control (bolt) to cooperate. For example, the topology master can be responsible for metrics or for the baskpressure mechanism. The author has not yet in-depth interpretation, the corresponding part of the follow-up to do the corresponding addition, here first dig a pit.
Calculate the number of worker s
_In the constructor of Default Topology AssignContext, after adding additional components, the key-value pairs corresponding to supervisorid and hostname are acquired immediately. If there is old allocation information, all the original workers are acquired. If not, a new set of workers is created. Remove tasks in deadtaskid that are in unstopworker (the purpose here is to separate them, and in the case of new, both are empty sets). Then calculate the number of workers needed. Look at the source code below.
private int computeWorkerNum() { //Get the number of worker s for the topology settings Integer settingNum = JStormUtils.parseInt(stormConf.get(Config.TOPOLOGY_WORKERS)); // int ret = 0, hintSum = 0, tmCount = 0; Map<String, Object> components = ThriftTopologyUtils.getComponents(sysTopology); for (Entry<String, Object> entry : components.entrySet()) { String componentName = entry.getKey(); Object component = entry.getValue(); ComponentCommon common = null; if (component instanceof Bolt) { common = ((Bolt) component).get_common(); } if (component instanceof SpoutSpec) { common = ((SpoutSpec) component).get_common(); } if (component instanceof StateSpoutSpec) { common = ((StateSpoutSpec) component).get_common(); } //Get the parallelism set in each component int hint = common.get_parallelism_hint(); if (componentName.equals(Common.TOPOLOGY_MASTER_COMPONENT_ID)) { //If it belongs to a TM component, add it to tmCount tmCount += hint; continue; } //This variable stores the sum of the parallelism of all components hintSum += hint; } //ret saves smaller values if (settingNum == null) { ret = hintSum; } else { ret = Math.min(settingNum, hintSum); } //It is also necessary to determine whether the master TM needs a separate worker node for processing. Boolean isTmSingleWorker = ConfigExtension.getTopologyMasterSingleWorker(stormConf); if (isTmSingleWorker != null) { if (isTmSingleWorker == true) { ret += tmCount; setAssignSingleWorkerForTM(true); } } else { if (ret >= 10) { ret += tmCount; setAssignSingleWorkerForTM(true); } } return ret; }
worker allocation
After the Default Topology AssignContext is instantiated, if it is rebalance type, the original occupied worker needs to be released first. The specific method is to put the ports used by the worker back into the available ports set. The meaning of several variables, needAssignTasks: refers to tasks that need to be assigned, that is, to remove those tasks from unstopworker. allocWorkerNum: Equal to the number of previously calculated workers - minus the number of unstopworkers and minus the number of keepAssigns (only if the topology type is ASSIGN_TYPE_MONITOR). Among the actual worker assignments, the most important is the method WorkerScheduler. getAvailable Workers. Next, we will explain how to implement this method in detail.
int workersNum = getAvailableWorkersNum(context); if (workersNum < allocWorkerNum) { throw new FailedAssignTopologyException("there's no enough worker.allocWorkerNum="+ allocWorkerNum + ", availableWorkerNum="+ workersNum); } workersNum = allocWorkerNum; List<ResourceWorkerSlot> assignedWorkers = new ArrayList<ResourceWorkerSlot>(); getRightWorkers(context,needAssign,assignedWorkers,workersNum,getUserDefineWorkers(context, ConfigExtension.getUserDefineAssignment(context.getStormConf())));
Firstly, we know all workers available on the cluster. If the number of workers available is less than the number of workers that need to be allocated, we need to throw an exception. If sufficient, a sufficient worker is allocated to the specified topology. Call the getRightWorkers method to get the right worker, where the so-called right worker refers to a user-defined worker that can specify the worker's resource allocation.
getRightWorkers
_is divided into two parts to explain this method, the first is preparation work - getUserDefineWorkers method, this method requires two parameters, the context of the topology information, user-defined worker list workers. Look at the following source code:
private List<ResourceWorkerSlot> getUserDefineWorkers( DefaultTopologyAssignContext context, List<WorkerAssignment> workers) { List<ResourceWorkerSlot> ret = new ArrayList<ResourceWorkerSlot>(); //If there is no user-defined worker, no action is necessary if (workers == null) return ret; Map<String, List<Integer>> componentToTask = (HashMap<String, List<Integer>>) ((HashMap<String, List<Integer>>) context .getComponentTasks()).clone(); //If the allocation type is not NEW, unstopworker is removed from the worker resource allocation information list. //This is where the user specifies that some worker resources belong to unstopworker before they can be removed. if (context.getAssignType() != context.ASSIGN_TYPE_NEW) { checkUserDefineWorkers(context, workers, context.getTaskToComponent()); } //Traverse through user-defined worker s to remove those that do not assign task s //Which task s have been specified in user-defined worker and which worker should be assigned to for (WorkerAssignment worker : workers) { ResourceWorkerSlot workerSlot = new ResourceWorkerSlot(worker,componentToTask); if (workerSlot.getTasks().size() != 0) { ret.add(workerSlot); } } return ret; }
After removing those workers that do not specify task, they really enter the getRightWorkers method. The source code is as follows. Here, the meaning of the following five parameters is explained. Context represents the previously prepared topology context information, needAssign represents each taskid that the topology needs to allocate, assignedWorkers represents the worker resources that are allocated in this method, and workersNum represents the worker that needs to be allocated by the topology. Number, workers represent user-defined available worker resources in the previous method. In short, this method is to select the worker from the worker who has assigned the specified task and save it in the assigned workers.
private void getRightWorkers(DefaultTopologyAssignContext context, Set<Integer> needAssign, List<ResourceWorkerSlot> assignedWorkers, int workersNum, Collection<ResourceWorkerSlot> workers) { Set<Integer> assigned = new HashSet<Integer>(); List<ResourceWorkerSlot> users = new ArrayList<ResourceWorkerSlot>(); if (workers == null) return; for (ResourceWorkerSlot worker : workers) { boolean right = true; Set<Integer> tasks = worker.getTasks(); if (tasks == null) continue; for (Integer task : tasks) { if (!needAssign.contains(task) || assigned.contains(task)) { right = false; break; } } if (right) { assigned.addAll(tasks); users.add(worker); } } if (users.size() + assignedWorkers.size() > workersNum) { LOG.warn( "There are no enough workers for user define scheduler / keeping old assignment, userdefineWorkers={}, assignedWorkers={}, workerNum={}", users, assignedWorkers, workersNum); return; } assignedWorkers.addAll(users); needAssign.removeAll(assigned); }
_The main processing logic of the above code is in the for loop, which determines whether there is a taskid in the worker in this topology. If there is one, it stores the worker and removes the assigned tasks from the taskid list. If not, it exits directly.
Use old allocation/rebalance
Back to the getAvailable Workers method, look at the following code.
//If the configuration specifies that the old allocation is to be used, the appropriate worker is selected from the old allocation. if (ConfigExtension.isUseOldAssignment(context.getStormConf())) { getRightWorkers(context, needAssign, assignedWorkers, workersNum, context.getOldWorkers()); } else if (context.getAssignType() == TopologyAssignContext.ASSIGN_TYPE_REBALANCE && context.isReassign() == false) { //If it is rebalance, and you can use the original worker, the original worker will be stored. int cnt = 0; for (ResourceWorkerSlot worker : context.getOldWorkers()) { if (cnt < workersNum) { ResourceWorkerSlot resFreeWorker = new ResourceWorkerSlot(); resFreeWorker.setPort(worker.getPort()); resFreeWorker.setHostname(worker.getHostname()); resFreeWorker.setNodeId(worker.getNodeId()); assignedWorkers.add(resFreeWorker); cnt++; } else { break; } } } // Calculate the number of TM bolt s int workersForSingleTM = 0; if (context.getAssignSingleWorkerForTM()) { for (Integer taskId : needAssign) { String componentName = context.getTaskToComponent().get(taskId); if (componentName.equals(Common.TOPOLOGY_MASTER_COMPONENT_ID)) { workersForSingleTM++; } } } int restWokerNum = workersNum - assignedWorkers.size(); if (restWokerNum < 0) throw new FailedAssignTopologyException( "Too much workers are needed for user define or old assignments. workersNum=" + workersNum + ", assignedWokersNum=" + assignedWorkers.size());
_At first, the author thought that the above code might be used to judge that restWokerNum < 0 is very likely to be valid and cause an exception to be thrown, because if the user specifies the worker to assign information at the beginning, and then rebalance the situation, constantly adding the old worker to assignedWorkers, which will lead to assignedWorkers. The size is larger than the actual number of workers needed. But it's not yet time to test with the actual cluster, just ask the official person in github, if there is an update solution, it will be explained later here.
Allocate the remaining worker
//restWokerNum is the number of remaining worker s needed, adding the ResourceWorkerSlot instance object directly. for (int i = 0; i < restWokerNum; i++) { assignedWorkers.add(new ResourceWorkerSlot()); } //Here are the supervisor nodes that specify the running topology. List<SupervisorInfo> isolationSupervisors = this.getIsolationSupervisors(context); if (isolationSupervisors.size() != 0) { putAllWorkerToSupervisor(assignedWorkers, getResAvailSupervisors(isolationSupervisors)); } else { putAllWorkerToSupervisor(assignedWorkers, getResAvailSupervisors(context.getCluster())); } this.setAllWorkerMemAndCpu(context.getStormConf(), assignedWorkers); LOG.info("Assigned workers=" + assignedWorkers); return assignedWorkers;
__The isolation Supervisors in the above code store the id of the supervisor nodes assigned to the topology. If it is specified, it is allocated on these specific nodes, and if it is not specified, it is allocated globally. So the actual remaining assignment task is put AllWorker ToSupervisor, which is responsible for eliminating supervisor nodes that cannot assign workers because the assigned workers on the nodes are full. Here's how putAllWorkerToSupervisor works.
Put AllWorker ToSupervisor requires two parameters. The first is the assigned worker, which contains those workers that have not been set to run on that node (those newly created directly above), and the second is the supervisor node currently available. Here's the code for this method
private void putAllWorkerToSupervisor( List<ResourceWorkerSlot> assignedWorkers, List<SupervisorInfo> supervisors) { for (ResourceWorkerSlot worker : assignedWorkers) { if (worker.getHostname() != null) { for (SupervisorInfo supervisor : supervisors) { if (NetWorkUtils.equals(supervisor.getHostName(), worker.getHostname()) && supervisor.getAvailableWorkerPorts().size() > 0) { putWorkerToSupervisor(supervisor, worker); break; } } } } supervisors = getResAvailSupervisors(supervisors); Collections.sort(supervisors, new Comparator<SupervisorInfo>() { @Override public int compare(SupervisorInfo o1, SupervisorInfo o2) { // TODO Auto-generated method stub return -NumberUtils.compare( o1.getAvailableWorkerPorts().size(), o2.getAvailableWorkerPorts().size()); } }); putWorkerToSupervisor(assignedWorkers, supervisors); }
_The first step to enter the method is to assign a suitable port to the worker who has already allocated the node from the supervisor node. The main operation of putWorkerToSupervisor is to get a available port from the supervisor node, then set the port of the worker, and remove the port from the list of available ports of the supervisor node. The code structure is very simple, as follows:
private void putWorkerToSupervisor(SupervisorInfo supervisor, ResourceWorkerSlot worker) { int port = worker.getPort(); if (!supervisor.getAvailableWorkerPorts().contains(worker.getPort())) { port = supervisor.getAvailableWorkerPorts().iterator().next(); } worker.setPort(port); supervisor.getAvailableWorkerPorts().remove(port); worker.setNodeId(supervisor.getSupervisorId()); }
_After setting up some of the assigned worker s, continue to assign those who do not specify the supervisor. According to the reverse order of available ports in supervisor, from large to small rows. Then call the putWorkerToSupervisor method.
putWorkerToSupervisor method first counts all the ports that have been used, and then calculates the theoretical average load {(all used + to be allocated)/ supervisor number. After allocation, the theoretical load value of the cluster, theoryAverage Ports, can be spread to each Superviso equally. R body}. Then, by traversing the list of workers that need to be allocated for the first time, the worker can be allocated to supervisors whose load values (as the theoretical values are calculated) are less than the theoretical average load. If it exceeds the load, it will be put into the load list. After a round of allocation, if there is no allocated worker (Source code here first sort and then judge, it is obvious that the possibility of waste of sorting time). Sort from large to small according to the reverse order of available ports in supervisor. Worker is allocated continuously.
_Here, the worker allocation is successfully completed. To sum up, firstly, the context information is initialized according to the topological information, and then the number of workers actually used is calculated. If these workers are designated to run on a supervisor node, then the appropriate worker is allocated on the node. If not specified, then according to the load of the node, it is allocated to each supervisor node as evenly as possible. If everybody's load is relatively large, which nodes have more available ports are allocated to complete the allocation.
task allocation
_. The getAvailable Workers method completes the assignment of the worker, and if the user specifies a specific worker to run the specified task, the remaining taskid will explain how to assign in the next method. Mainly in the constructor of Task Scheduler, three parameters are needed. The first is defaultContext, the second is needAssignTasks, the list of tasks to be allocated, and the appropriate worker list availableWorkers obtained above. (ps: remember, if no specific worker resource allocation information is specified in the previous article, no taskid is allocated to the worker, that is, there is only supervisorid, memory, cpu, port and other information in the worker, and there is no tasks information. Next, look at the constructor of Task Scheduler.
public TaskScheduler(DefaultTopologyAssignContext context, Set<Integer> tasks, List<ResourceWorkerSlot> workers) { this.tasks = tasks; LOG.info("Tasks " + tasks + " is going to be assigned in workers " + workers); this.context = context; this.taskContext = new TaskAssignContext(this.buildSupervisorToWorker(workers), Common.buildSpoutOutoputAndBoltInputMap(context), context.getTaskToComponent()); this.componentSelector = new ComponentNumSelector(taskContext); this.inputComponentSelector = new InputComponentNumSelector(taskContext); this.totalTaskNumSelector = new TotalTaskNumSelector(taskContext); if (tasks.size() == 0) return; if (context.getAssignType() != TopologyAssignContext.ASSIGN_TYPE_REBALANCE || context.isReassign() != false){ // warning ! it doesn't consider HA TM now!! if (context.getAssignSingleWorkerForTM() && tasks.contains(context.getTopologyMasterTaskId())) { assignForTopologyMaster(); } } int taskNum = tasks.size(); Map<ResourceWorkerSlot, Integer> workerSlotIntegerMap = taskContext.getWorkerToTaskNum(); Set<ResourceWorkerSlot> preAssignWorkers = new HashSet<ResourceWorkerSlot>(); for (Entry<ResourceWorkerSlot, Integer> worker : workerSlotIntegerMap.entrySet()) { if (worker.getValue() > 0) { taskNum += worker.getValue(); preAssignWorkers.add(worker.getKey()); } } setTaskNum(taskNum, workerNum); // Check the worker assignment status of pre-assigned workers, e.g user defined or old assignment workers. // Remove the workers which have been assigned with enough workers. for (ResourceWorkerSlot worker : preAssignWorkers) { if (taskContext.getWorkerToTaskNum().keySet().contains(worker)){ Set<ResourceWorkerSlot> doneWorkers = removeWorkerFromSrcPool(taskContext.getWorkerToTaskNum().get(worker), worker); if (doneWorkers != null) { for (ResourceWorkerSlot doneWorker : doneWorkers) { taskNum -= doneWorker.getTasks().size(); workerNum--; } } } } setTaskNum(taskNum, workerNum); // For Scale-out case, the old assignment should be kept. if (context.getAssignType() == TopologyAssignContext.ASSIGN_TYPE_REBALANCE && context.isReassign() == false) { keepAssignment(taskNum, context.getOldAssignment().getWorkers()); } }
Initialization
In this constructor, the first step is to construct a task allocation context information. The main information that this object needs to be maintained is
taskToComponent: A Map where Key represents taskid and Value represents the corresponding component id.
Supervisor ToWorker: It's also a Map. Key represents the supervisorid of the topology allocation, and Value represents the list of worker s allocated on the node.
Relation: A structural information that maintains this topology is still a Map. Key represents the component id of the component bolt/spot, and Value represents the id of all the corresponding components input to the component if the key corresponding component is a bolt. If the Key corresponding component is a spout, then Value saves all the component IDs that the component outputs. For example, integer (spout) is output to sliding (bolt) and sliding (bolt) to printer (bolt). Then relationship saves [{integer, [sliding]}, {sliding, [integer]}, {printer, [sliding]}.
workerToTaskNum: Map, Key represents a worker, and Value represents the total number of task s actually running on this worker.
workerToComponentNum: Map, Key represents a worker, Value represents a Map, saves the component id, and the corresponding number.
Firstly, Component Num selector (which defines one or two Worker Comparators internally, is responsible for comparing the worker and comparing the number of tasks of a component in the worker). The second is Input Component Num selector (which also defines two matching functions, one is to get the total number of tasks input by a component in the worker, and the other is to get the total number of tasks input by a component in the worker, and the third is to get the total number of tasks input by the whole supervisor). TalTask Num selector (the number of all tasks in the worker and the number of tasks in the supervisor). The purpose of these three selectors is to prepare for assigning tasks to these workers in a reasonable way.
Distribution TM bolt
_If cluster resources are sufficient and user-defined TM needs to be allocated separately to a separate worker, assignForTopologyMaster needs to be invoked to allocate separately.
private void assignForTopologyMaster() { int taskId = context.getTopologyMasterTaskId(); ResourceWorkerSlot workerAssigned = null; int workerNumOfSuperv = 0; for (ResourceWorkerSlot workerSlot : taskContext.getWorkerToTaskNum().keySet()){ List<ResourceWorkerSlot> workers = taskContext.getSupervisorToWorker().get(workerSlot.getNodeId()); if (workers != null && workers.size() > workerNumOfSuperv) { for (ResourceWorkerSlot worker : workers) { Set<Integer> tasks = worker.getTasks(); if (tasks == null || tasks.size() == 0) { workerAssigned = worker; workerNumOfSuperv = workers.size(); break; } } } } if (workerAssigned == null) throw new FailedAssignTopologyException("there's no enough workers for the assignment of topology master"); updateAssignedTasksOfWorker(taskId, workerAssigned); taskContext.getWorkerToTaskNum().remove(workerAssigned); assignments.add(workerAssigned); tasks.remove(taskId); workerNum--; LOG.info("assignForTopologyMaster, assignments=" + assignments); }
_This method first finds out the most suitable worker, which meets two conditions: one is that there is no other task allocated, the second is that the supervisor where the worker is allocated the most worker, and the second is to ensure load balancing. If the appropriate worker is not found, an exception is thrown. If you can find it, assign the task responsible for TM to the worker. The purpose of updateAssigned Tasks OfWorker is to update the new allocation.
task allocation
_Next, get the total number of tasks and the list of workers that have been allocated, preAssign Workers. The average number of tasks on each worker, avgTaskNum, and the remaining number of tasks (total task% total worker, leftTaskNum) are calculated based on the total number of tasks obtained. Then traverse the preAssignWorkers, calling the method removeWorkerFromSrcPool to determine whether a worker has allocated enough tasks, and remove those tasks and workers that have been reasonably allocated.
for (ResourceWorkerSlot worker : preAssignWorkers) { if (taskContext.getWorkerToTaskNum().keySet().contains(worker)){ Set<ResourceWorkerSlot> doneWorkers = removeWorkerFromSrcPool(taskContext.getWorkerToTaskNum().get(worker), worker); if (doneWorkers != null) { for (ResourceWorkerSlot doneWorker : doneWorkers) { taskNum -= doneWorker.getTasks().size(); workerNum--; } } } }
The method of removeWorker FromSrcPool is interesting. It's a bit confusing when I first saw it, but it's very clear when I look at it carefully. Let me briefly explain the following:
private Set<ResourceWorkerSlot> removeWorkerFromSrcPool(int taskNum, ResourceWorkerSlot worker) { Set<ResourceWorkerSlot> ret = new HashSet<ResourceWorkerSlot>(); if (leftTaskNum <= 0) { if (taskNum >= avgTaskNum) { taskContext.getWorkerToTaskNum().remove(worker); assignments.add(worker); ret.add(worker); } } else { if (taskNum > avgTaskNum ) { taskContext.getWorkerToTaskNum().remove(worker); leftTaskNum = leftTaskNum -(taskNum -avgTaskNum); assignments.add(worker); ret.add(worker); } if (leftTaskNum <= 0) { List<ResourceWorkerSlot> needDelete = new ArrayList<ResourceWorkerSlot>(); for (Entry<ResourceWorkerSlot, Integer> entry : taskContext.getWorkerToTaskNum().entrySet()) { if (avgTaskNum != 0 && entry.getValue() == avgTaskNum) needDelete.add(entry.getKey()); } for (ResourceWorkerSlot workerToDelete : needDelete) { taskContext.getWorkerToTaskNum().remove(workerToDelete); assignments.add(workerToDelete); ret.add(workerToDelete); } } } return ret; }
ret saves the worker collection that needs to be returned to the caller and removed. If the number of tasks in the current worker is greater than or equal to the average number, it shows that the worker has allocated reasonable tasks. (The reason is, if leftTaskNum is less than or equal to 0, is it considered that the average will be 1 more than normal. For example, if there are three boxes and 10 balls in it, then if the average number is 3, the remainder is 1, if the average number is 4, then the remainder is - 2. If the leftTaskNum is greater than 0, the judgment is more complicated. First, if the number of taskNum is greater than the average avgTaskNum, it means that the worker allocates more tasks, then these allocations must be subtracted from the leftTaskNum. It is even possible that the number of taskNum is larger than that of avgTaskNum+leftTaskNum, which directly results in the number of leftTaskNum less than or equal to 0. When the leftTaskNum is less than or equal to 0, find out that the number of tasks allocated by the worker in the allocation context is just the average worker, which exists in the needDelete list. Then traverse the list, add these workers from the collection ret that needs to be removed, and return. (Because if a worker allocates more than avgTaskNum+leftTaskNum, then those workers whose allocations are average must be reasonable, and those whose allocations are less than average need to be adjusted).
_After performing the above operations, update the current average avgTaskNum and assign the remaining task number leftTaskNum. (There are still some tasks that haven't been actually allocated yet), and the assignment method is the one that completes the assignment. In this method, if there is no task that needs to be allocated, the original allocated task will be returned. If there are tasks that need to be allocated, traverse the list of tasks that need to be allocated. If the components corresponding to tasks belong to system components (components with id of _acker or _topology_master), they are saved. If they are general tasks, the chooseWorker method is called to select an appropriate worker, and then the task is allocated to W. On orker. (Of course, there are some additional operations that need to be done here, such as clearing the worker that has been reasonably allocated, by calling the removeWorker FromSrcPool method). ChooseWorker uses the three selector s mentioned above to select the best supervisor and worker (it needs to consider the input received by the task, the load of the supervisor node and the load in the worker). After assigning the common task, the system components are allocated in the same way.
_At this point, task allocation is also completed. To sum up, in addition to those assigned allocations, it is more important to define a reasonable selector (considering node load, worker load, input input and localization). At the same time, keep checking whether the worker has been reasonably allocated, so don't continue to allocate to that worker.
HeartBeat operation
_After the assignment of task and worker is completed above, we return to the mkAssignment method. The rest is to set task's HB start time and timeout time. These are relatively simple and will not go into detail.
Concluding remarks
_The process of interpreting topology allocation can make us more clear how a logical topology we write actually becomes a topology that can actually run in a cluster. And how to ensure load balancing in the topology. The source code analysis of several important features of JStorm will be updated in the future. It includes how to implement the backpressure mechanism, how to implement nimbus and supervisor fault tolerance, which operations need to be performed when supervisor starts.