In order to better control multithreading, JDK provides a threading framework Executor to help programmers effectively control threads. The Java.util.concurrent package is designed for Java concurrent programming. There are many written tools under it:
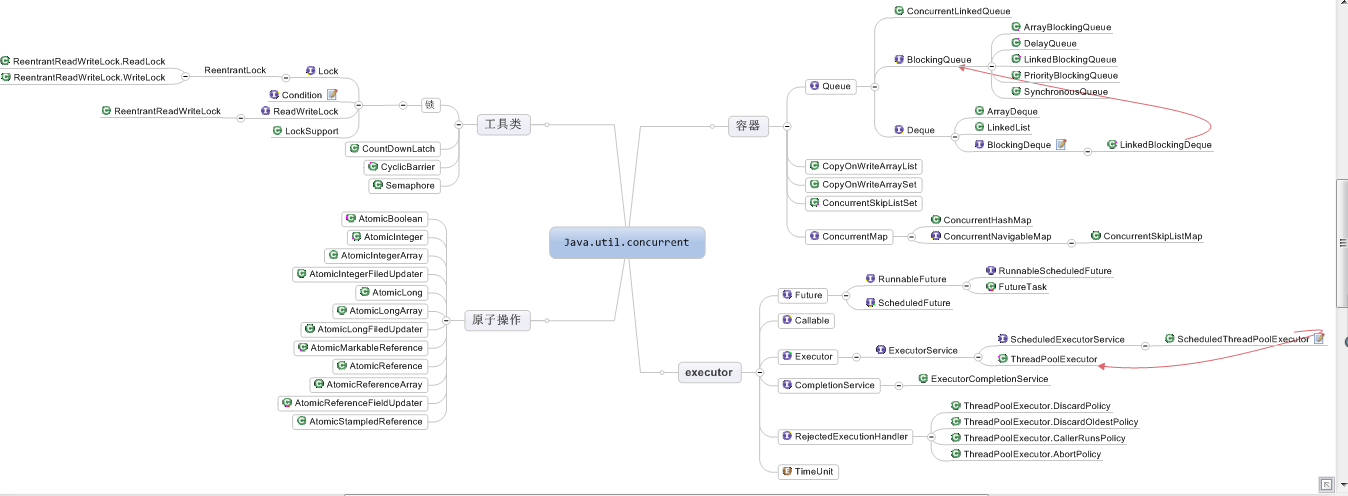
Brain Map Address Thank you. Deep and shallow Java Concurrency This brain map is modified on the basis of this article. One of the more important thread factory classes is Executors.
In the past, when we used new Thread every time we executed a task, frequent creation of objects would lead to poor system performance, lack of unified management of threads, may create new threads unrestrictedly, competition among them will lead to exhaustion of the system, and lack of timed tasks, interruptions and other functions. Thread pool can effectively improve the utilization of system resources, avoid excessive resource competition, reuse existing threads and reduce object creation. Java provides the following four types of thread pools through the Executors factory, through which we can create thread pools with different functions. If Executors can not meet the requirements, we can also create custom thread pools:
1. New Fixed ThreadPool () method
2. New Single ThreadExecutor () method
3. New CachedThreadPool () method
4. New Scheduled ThreadPool () method
5. Custom thread pool
1. New Fixed ThreadPool () Method
Create a fixed number of thread pools, where the number of threads remains unchanged. When a thread commits, if there are idle threads in the thread pool, it executes immediately. If not, it suspends waiting for idle threads to execute in a blocked queue, Linked Blocking Queue. (Linked Blocking Queue can be seen in the blogger's last article: [JDK Concurrent Packaging Foundation] Concurrent Container Details)
Now let's think about this: if Thread1, Thread2, Thread3 and Thread4 threads count the size of C, D, E and F disks respectively, then all threads are counted and submitted to Thread5 threads for summary, how should they be realized?
The first way is to use join(), which is not recommended:

Thread pooling is recommended:
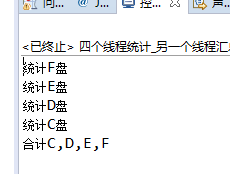
public static void main(String[] args) throws InterruptedException { //Implemented with CountDownLatch, CountDownLatch input 4 is equivalent to a timer, and an await requires four countDown s to wake up. final CountDownLatch countDownLatch= new CountDownLatch(4); Runnable run1= new Runnable() { @Override public void run() { try { Thread.sleep(3000); System.out.println("Statistics C disc"); countDownLatch.countDown();//Single task, subtract counter by 1 } catch (InterruptedException e) { e.printStackTrace(); } } }; Runnable run2= new Runnable() { @Override public void run() { try { Thread.sleep(3000); System.out.println("Statistics D disc"); countDownLatch.countDown(); } catch (InterruptedException e) { e.printStackTrace(); } } }; Runnable run3= new Runnable() { @Override public void run() { try { Thread.sleep(3000); System.out.println("Statistics E disc"); countDownLatch.countDown(); } catch (InterruptedException e) { e.printStackTrace(); } } }; Runnable run4= new Runnable() { @Override public void run() { try { Thread.sleep(3000); System.out.println("Statistics F disc"); countDownLatch.countDown(); } catch (InterruptedException e) { e.printStackTrace(); } } }; //Create thread pools with fixed threads ExecutorService service= Executors.newFixedThreadPool(4); service.submit(run1); service.submit(run2); service.submit(run3); service.submit(run4); // new Thread(run1).start(); // new Thread(run2).start(); // new Thread(run3).start(); // new Thread(run4).start(); countDownLatch.await();//The main thread, thread 5, waits System.out.println("Total C,D,E,F"); service.shutdown(); }
The results are as follows: the first four disk sizes can be counted in no order, but the total is always at the end:
2. New Single ThreadExecutor () method
Create a thread pool with only one thread and execute immediately if there are idle threads in the thread pool. If not, it suspends waiting for idle threads to execute in a blocked queue, Linked Blocking Queue, which guarantees that all tasks are executed in the order of submission. Let's look at its source code:
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService//Don't pay attention to this first. (new ThreadPoolExecutor(1, //Number of core threads 1,//Maximum number of threads 0L,//Time to keep threads alive when idle TimeUnit.MILLISECONDS,//Unit of time above new LinkedBlockingQueue<Runnable>()));//When there are no idle threads in the thread pool, they are placed in this queue. }
Application scenario: When an exception occurs in the thread pool, a thread is restarted to replace the original thread to execute.
3. New CachedThreadPool () method
Create a thread pool that can adjust the number of threads according to the actual situation, without restricting the number of threads. If there are tasks, create threads. Without tasks, no threads are created, and each idle thread is automatically reclaimed after 60 seconds. Let's look at the source code:
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0,//Number of core threads, 0 means initialization does not create threads Integer.MAX_VALUE,//The maximum value of int, which means that thread pool capacity is not limited 60L,//Cache threads for 60 seconds TimeUnit.SECONDS,//Company new SynchronousQueue<Runnable>()); }
As soon as SynchronousQueue, a queue with no capacity, is created, it is blocked internally by take() method and executed directly when a thread arrives.
4. New Scheduled ThreadPool () Method
Create an infinite thread pool that supports the need to perform tasks on a regular and periodic basis. Its source code is as follows:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); } public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor//Note that ThreadPool Executor is inherited here implements ScheduledExecutorService { public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize,//Number of core threads, incoming Integer.MAX_VALUE,//The maximum value of int, which means that thread pool capacity is not limited 0, //Represents no delay TimeUnit.NANOSECONDS,//The unit is nanoseconds. new DelayedWorkQueue()); } }
Delayed WorkQueue is a queue with latency, in which elements can only be retrieved from the queue when the specified time is up, and can be timed.
Create a task and print a sentence every 3 seconds after initialization:
public class ScheduledThread { public static void main(String args[]) throws Exception { Temp command = new Temp(); //Create a thread pool that implements timers ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1); //The command represents the specific task object, the first number represents the initialization time, and the second number represents the polling time. ScheduledFuture<?> scheduleTask = scheduler.scheduleWithFixedDelay(command, 3, 1, TimeUnit.SECONDS); } } class Temp extends Thread { public void run() { System.out.println("run"); } }
This is a Java-like Timer timer, but if you integrate Quartz with Spring in your project, you'd better use the @Scheduled annotation. ref: Implementation of Spring Schedule Task Scheduling
5. Custom thread pool
ThreadPool Executor is used to create thread pool in the above Executors factory class. ThreadPool Executor can implement custom thread pool. Its construction method is as follows:
public ThreadPoolExecutor(int corePoolSize,//Number of core threads int maximumPoolSize,//Maximum number of threads long keepAliveTime,//How long does the thread last? TimeUnit unit,//Company BlockingQueue<Runnable> workQueue,//Thread pool function ThreadFactory threadFactory,//Don't pay attention to this first. RejectedExecutionHandler handler)//Denial strategies, such as exceeding the maximum number of threads, can tell clients that the server is busy {...}
This construction method is key to what type of BlockingQueue queue is, and it is related to the functionality of this custom thread pool.
When bounded queues are used, threads are created when the actual number of threads is less than corePoolSize. If it is larger than corePoolSize, the task will join the BlockingQueue queue. If the queue is full, a new thread will be created when the total number of actual threads is not greater than the maximum PoolSize. If it is also larger than maximumPoolSize, the rejection policy is executed, or in other ways customized.
2. When using unbounded queues, Linked BlockingQueue buffers the queues. When the actual threads exceed the number of corePoolSize core threads, the waiting threads are placed. Finally, when the system is idle and fetched in the queue, the maximum PoolSize parameter will not work here. Because it is an unbounded queue, unless the system resources are exhausted, there will be no task entry failure. For example, the speed at which tasks are created and processed varies greatly, and unbounded queues grow rapidly until the system runs out of memory.
Examples of bounded and unbounded queues are as follows:
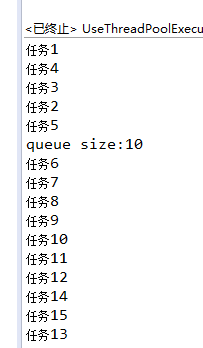
public class ThreadPoolExecutorDemo implements Runnable{ private static AtomicInteger count = new AtomicInteger(0); @Override public void run() { try { int temp = count.incrementAndGet(); System.out.println("task" + temp); Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main(String[] args) throws Exception{ BlockingQueue<Runnable> queue = new LinkedBlockingQueue<Runnable>(); //new ArrayBlockingQueue<Runnable>(10); ExecutorService executor = new ThreadPoolExecutor( 5, //corePoolSize 10, //Maximum PoolSize has nothing to do with this parameter here. 120L, //2 minutes TimeUnit.SECONDS, queue); for(int i = 0 ; i < 15; i++){//Submit 15 tasks executor.execute(new ThreadPoolExecutorDemo()); } Thread.sleep(1000); System.out.println("queue size:" + queue.size()); executor.shutdown(); } }
The result of LinkedBlockingQueue unbounded queue execution is that five tasks are executed at a time:
For rejection strategy, what should be done when the number of tasks exceeds the actual carrying capacity of the system? JDK provides several implementation strategies:
AbortPolicy: Throw an exception directly to prevent the system from working properly.
Caller Runs Policy: As long as the thread pool is not closed, the discarded tasks will be executed first.
Discard OledestPolicy: Discard the oldest request and try to resubmit the current task
DiscardPolicy: Discard tasks that cannot be handled and leave them untreated.
Personally, these four strategies are not very good. We can implement a custom policy, just implement the Rejected Execution Handler interface here.
public class MyThreadPoolExecutor { public static void main(String[] args) { ThreadPoolExecutor pool = new ThreadPoolExecutor( 1, //coreSize 2, //MaxSize 60, //60 TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(3) //Specify a queue (bounded queue) //new LinkedBlockingQueue<Runnable>() , new MyRejected() //new DiscardOldestPolicy()// throws an exception directly ); MyTask mt1 = new MyTask(1, "Task 1");//The first task will be performed directly. MyTask mt2 = new MyTask(2, "Task 2");//The second task will be queued until the first task is completed. MyTask mt3 = new MyTask(3, "Task 3");//Because there are three capacity in the queue, Task 3 will also be put in the queue. MyTask mt4 = new MyTask(4, "Task 4");//Since there are three capacity in the queue, Task 4 will also be put in the queue. MyTask mt5 = new MyTask(5, "Task 5");//If there are five tasks, Task 1 and 5 are executed simultaneously, Task 234 is in the queue MyTask mt6 = new MyTask(6, "Task 6");//If the queue is full and the maximum number of threads in the thread pool exceeds, the rejection policy will be implemented. pool.execute(mt1); pool.execute(mt2); pool.execute(mt3); pool.execute(mt4); pool.execute(mt5); pool.execute(mt6); pool.shutdown(); } } class MyRejected implements RejectedExecutionHandler{ @Override //Pass in the current task object and the current thread pool object public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { //1. You can do some processing, such as creating a request to the client with http to send the task again. At peak time, the system is overloaded and no further requests are recommended. //2. Just record logs: id and other important information, suspend to disk, run some regular job to parse logs in the off-peak period, and process the unprocessed tasks again or in batches. System.out.println("Custom Processing.."); System.out.println("The tasks currently rejected are:" + r.toString()); } } class MyTask implements Runnable { private int taskId; private String taskName; public MyTask(int taskId, String taskName){this.taskId = taskId;this.taskName = taskName;} public int getTaskId() {return taskId;} public void setTaskId(int taskId) {this.taskId = taskId;} public String getTaskName() {return taskName;} public void setTaskName(String taskName) {this.taskName = taskName;} @Override public void run() { try { System.out.println("run taskId =" + this.taskId); Thread.sleep(3000); //System.out.println("end taskId =" + this.taskId); } catch (InterruptedException e) { e.printStackTrace(); } } public String toString(){ return Integer.toString(this.taskId); } }
The results are as follows:

The thread pool under Java concurrent package has been introduced here. The blogger is an ordinary programmer ape with limited level. There are inevitably mistakes in the article. Readers who sacrifice their precious time are welcome to express their opinions on the content of this article.