Coding Chinese in Java
Step 1: coding concept
The computer can only store numbers, and all characters will be converted into different numbers.
Just like a chessboard, different words are in different positions, and different positions have different numbers.
Some chessboards are very small, only numbers and English can be put
Some are bigger, and they can also put Chinese
Some are "big enough" to put down all the words and symbols used by the people of the world
As shown in the figure, the English character A can be placed in all chessboards, and the positions are almost the same
Chinese characters can be placed in the last two chessboards with different positions, and in the small chessboard, Chinese characters cannot be placed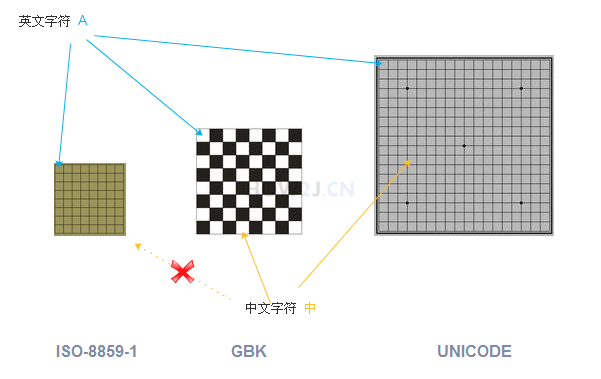
Step 2: common coding
The coding methods frequently contacted after work are as follows:
ISO-8859-1 ASCII numbers and Western European letters
GBK GB2312 BIG5 Chinese
UNICODE (unified code, universal code)
among
ISO-8859-1 contains ASCII
GB2312 is simplified Chinese, BIG5 is traditional Chinese, GBK includes both simplified and traditional Chinese as well as Japanese.
UNICODE includes all Chinese, English, Tibetan, French and all other languages in the world.
Step 3: Unicode and UTF
According to the previous study, we learned that different encoding methods correspond to different checkerboards, while UNICODE is the largest because it stores all the data.
Not only that, each number in the chessboard is very long (4 bytes), because it not only represents letters, but also represents Chinese characters and so on.
If the data is stored in the way of UNICODE, there will be a lot of waste.
For example, in ISO-8859-1, the number corresponding to a character is 0x61
The corresponding number in UNICODE is 0x00000061. If most of an article is in English letters, it will consume a lot of space to save data according to UNICODE.
In this case, there are various weight loss sub codes of UNICODE, for example, UTF-8 uses one byte for numbers and letters, and three bytes for Chinese characters, so as to achieve the effect of weight loss and health guarantee.
UTF-8, UTF-16 and UTF-32 have different weight loss effects for different types of data. Generally speaking, UTF-8 is a common way.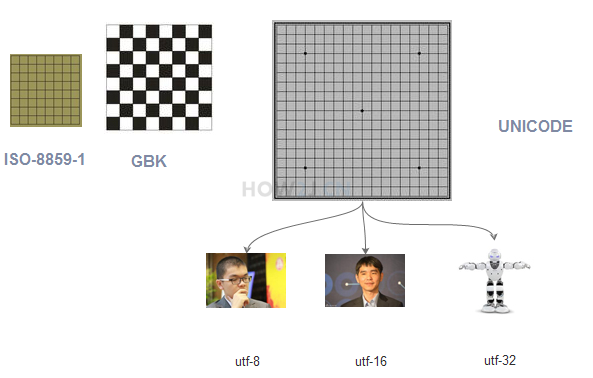
Step 4: Java uses Unicode
Chinese characters written in the. java source code will become characters in the JVM after execution.
The encoding method of these Chinese characters is to use UNICODE. The UNICODE corresponding to the "middle" word is 4E2D, so in memory, the actual data saved is 0x4E2D in hex, that is, 20013 in decimal.
package stream;
public class TestStream {
public static void main(String[] args) {
String str = "in";
}
}Step 5: expression of a Chinese character using different coding methods
Take character as an example to see its value in different encoding modes.
I.e. position on different chessboards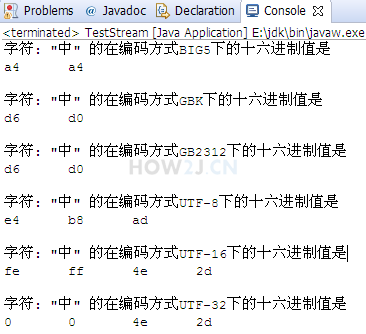
package stream;
import java.io.UnsupportedEncodingException;
public class TestStream {
public static void main(String[] args) {
String str = "in";
showCode(str);
}
private static void showCode(String str) {
String[] encodes = { "BIG5", "GBK", "GB2312", "UTF-8", "UTF-16", "UTF-32" };
for (String encode : encodes) {
showCode(str, encode);
}
}
private static void showCode(String str, String encode) {
try {
System.out.printf("character: \"%s\" In coding mode of%s The hexadecimal value below is%n", str, encode);
byte[] bs = str.getBytes(encode);
for (byte b : bs) {
int i = b&0xff;
System.out.print(Integer.toHexString(i) + "\t");
}
System.out.println();
System.out.println();
} catch (UnsupportedEncodingException e) {
System.out.printf("UnsupportedEncodingException: %s Character cannot be resolved by encoding%s\n", encode, str);
}
}
}Step 6: document coding - Notepad
Characters in the file must also be saved in the form of numbers, that is, different numbers corresponding to different checkerboards
Open any text file with Notepad, and save as, you can see a drop-down here.
ANSI does not mean ASCII, but local coding. If you are a Chinese operating system, GBK will be used. If you are an English operating system, ISO-8859-1 will be used.
Unicode UNICODE native encoding
Unicode big endian another UNICODE encoding
The most common UTF-8 encoding mode of UTF-8 is one byte for numbers and letters, and three bytes for Chinese characters.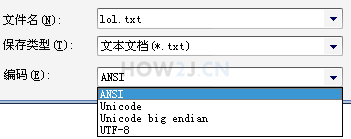
Step 7: file encoding - eclipse
eclipse has a similar encoding method. Right click any text file and click the bottom "property"
You can see Text file encoding
There are also ISO-8859-1, GBK,UTF-8 and other options.
Other US-ASCII,UTF-16, UTF-16BE,UTF-16LE are not commonly used.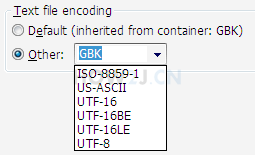
Step 8: use FileInputStream byte stream to read Chinese correctly
In order to read Chinese content correctly
- You have to understand how text is encoded to hold characters
- Use byte stream to read the text, and then use the corresponding encoding method to identify these numbers to get the correct characters.
For example, if the content of a file is in characters and the encoding method is GBK, the read data must be D6D0.
Then using GBK code to recognize D6D0, we can get the correct characters.
Note: after the Chinese characters are found on the board of GBK, the JVM will automatically find the corresponding numbers on the board of UNICODE, and save them in memory with the numbers on UNICODE.
package stream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class TestStream {
public static void main(String[] args) {
File f = new File("E:\\project\\j2se\\src\\test.txt");
try (FileInputStream fis = new FileInputStream(f);) {
byte[] all = new byte[(int) f.length()];
fis.read(all);
//The data read from the file is
System.out.println("The data read out in the file is:");
for (byte b : all)
{
int i = b&0x000000ff; //Take only the last two digits of hexadecimal
System.out.println(Integer.toHexString(i));
}
System.out.println("Put this number in GBK On the chessboard:");
String str = new String(all,"GBK");
System.out.println(str);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}Step 9: use FileReader character stream to read Chinese correctly
FileReader gets characters, so it must have recognized bytes as characters according to some encoding.
The encoding method used by FileReader is the return value of Charset.defaultCharset(). If it is a Chinese operating system, it is GBK.
FileReader can't set the encoding mode manually. In order to use other encoding modes, InputStreamReader can only be used instead, like this:
new InputStreamReader(new FileInputStream(f),Charset.forName("UTF-8"));In this case, use Notepad to save as UTF-8 format, and then use UTF-8 to recognize the corresponding Chinese.
Explanation: why is there a Chinese character in front of it?
If you use Notepad to save as UTF-8, there is an identifier in the first byte, called BOM, to mark that the file is encoded with UTF-8.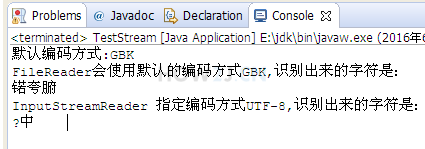
package stream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.nio.charset.Charset;
public class TestStream {
public static void main(String[] args) throws UnsupportedEncodingException, FileNotFoundException {
File f = new File("E:\\project\\j2se\\src\\test.txt");
System.out.println("Default encoding method:"+Charset.defaultCharset());
//FileReader gets characters, so it must have recognized bytes as characters according to some encoding.
//The encoding method used by FileReader is the return value of Charset.defaultCharset(). If it is a Chinese operating system, it is GBK.
try (FileReader fr = new FileReader(f)) {
char[] cs = new char[(int) f.length()];
fr.read(cs);
System.out.printf("FileReader The default encoding will be used%s,The recognized characters are:%n",Charset.defaultCharset());
System.out.println(new String(cs));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//FileReader cannot set encoding mode manually. In order to use other encoding modes, InputStreamReader can only be used instead.
//And use the form of new InputStreamReader(new FileInputStream(f),Charset.forName("UTF-8")); and
try (InputStreamReader isr = new InputStreamReader(new FileInputStream(f),Charset.forName("UTF-8"))) {
char[] cs = new char[(int) f.length()];
isr.read(cs);
System.out.printf("InputStreamReader Specify encoding method UTF-8,The recognized characters are:%n");
System.out.println(new String(cs));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}Practice: Remove BOM
If you use Notepad to save Chinese characters according to UTF-8 encoding, a segment of identifier will be generated at the front, which is used to indicate that the file is encoded with UTF-8.
Find out the hexadecimal corresponding to this identifier, and develop a method to automatically remove this identifier
Answer:
package stream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
public class TestStream {
public static void main(String[] args) {
File f = new File("E:\\project\\j2se\\src\\test.txt");
try (FileInputStream fis = new FileInputStream(f);) {
byte[] all = new byte[(int) f.length()];
fis.read(all);
System.out.println("First of all, confirm according to UTF-8 Identified?");
String str = new String(all,"UTF-8");
System.out.println(str);
System.out.println("According to what we have learned, we know'in'Word correspondence UTF-8 The code is: e4 b8 ad");
System.out.println("The hexadecimal of all data in the printed file is:");
for (byte b : all) {
int i = b&0xff;
System.out.print(Integer.toHexString(i)+ " ");
}
System.out.println();
System.out.println("By observation UTF-8 Of BOM yes ef bb bf");
byte[] bom = new byte[3];
bom[0] = (byte) 0xef;
bom[1] = (byte) 0xbb;
bom[2] = (byte) 0xbf;
byte[] fileContentWithoutBOM= removeBom(all,bom);
System.out.println("Removed BOM The hexadecimal of the following data is:");
for (byte b : fileContentWithoutBOM) {
int i = b&0xff;
System.out.print(Integer.toHexString(i)+ " ");
}
System.out.println();
System.out.println("The corresponding string has no question mark:");
String strWithoutBOM=new String(fileContentWithoutBOM,"UTF-8");
System.out.println(strWithoutBOM);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private static byte[] removeBom(byte[] all, byte[] bom) {
return Arrays.copyOfRange(all, bom.length, all.length);
}
}