Catalog
Preface
With the advent of the era of high concurrency, the original HashMap can no longer meet the basic needs. In HashMap 1.7, the possible dead cycle under multithreading is fatal. But there is such a class in the juc package of java api: ConcurrentHashMap, which is based on HashMap 1.7 and thread is safe. This blog will explain it carefully. It is strongly recommended that you read this blog before reading it HashMap1.7 source details.
By default, the blogger understands the basic principles of HashMap 1.7. Therefore, the same parts of them will not be described in detail. The HashMap and concurrent HashMap mentioned below are based on JDK 1.7 unless otherwise specified.
HashTable and ConcurrentHashMap
HashTable costs too much to ensure thread safety. get(), put() and other methods are synchronized, which is equivalent to adding a big lock to the entire hash table. It will cause a lot of time loss when calling methods of HashTable concurrently.
The design of concurrent HashMap is very clever. It uses the method of segmented locking to ensure the thread safety, instead of locking the entire hash table, which reduces the thread blocking time.
data structure
Segment + HashEntry
Each HashEntry structure is equivalent to a hash table (array + linked list) in the HashMap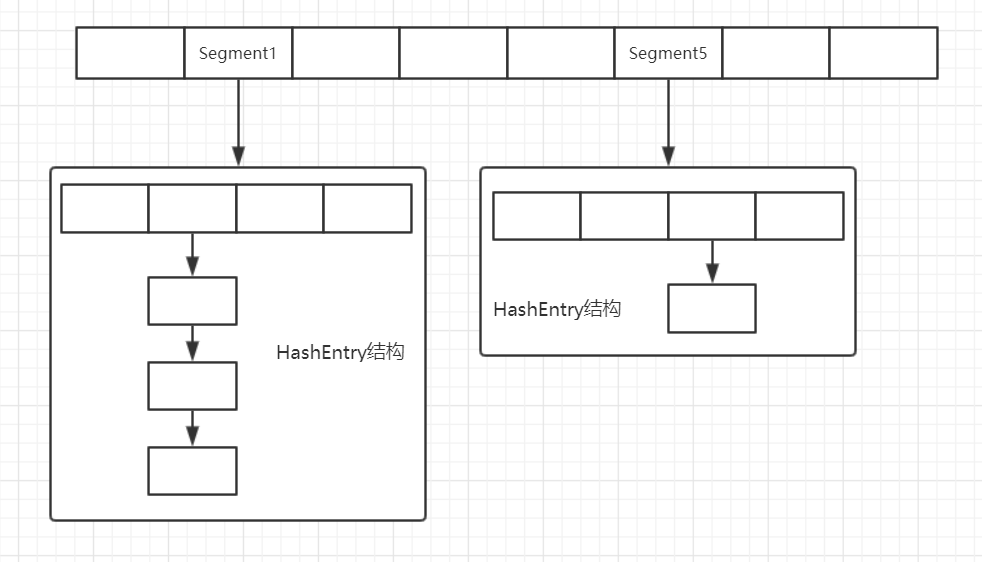
Concurrent HashMap uses the mechanism of Segment locking to Segment the whole hash table; when operating on different segments, it can avoid mutual interference and lock.
Class Segment
static final class Segment<K,V> extends ReentrantLock implements Serializable {}
The Segment class inherits the ReentrantLock class. ReentrantLock and synchronized are exclusive locks that can be reentered. Only threads are allowed to access the critical area mutually exclusive. This verifies that the ConcurrentHashMap is locked based on the Segment segment. It implements the Serializable interface, which can serialize and deserialize objects.
attribute
// Maximum number of attempts before forced locking
// availableProcessors() returns the number of processors available for the java virtual machine
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
// There is an array in each segmented lock
transient volatile HashEntry<K,V>[] table;
// Array nodes
transient int count;
transient int modCount;
// Dilatation threshold
transient int threshold;
// Loading factor
final float loadFactor;
From the above point of view, the Segment class covers almost all the core attributes in the HashMap, which means that each Segment object is equivalent to a HashMap, which is the core of segmentation. It needs to be emphasized that Max? Scan? Retries and modCount. In ConcurrentHashMap, some methods are not locked directly when they are executed, but are used to determine whether the original hash table has been modified by other threads through continuous multiple iterations. The judgment is based on whether the modCount is changed, and the number of loop traversals cannot be unlimited. Max scan retry is to determine the maximum number of attempts before locking. The specific use will be explained in the code.
put(K key, int hash, V value, boolean onlyIfAbsent)
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// The tryLock() method has a return value, which indicates that it is used to attempt to acquire the lock. If the acquisition is successful,
// Returns true if the acquisition fails (that is, the lock has been acquired by another thread), false,
// That is to say, this method will return immediately anyway. You won't be waiting when you can't get the lock.
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// Get array subscript
int index = (tab.length - 1) & hash;
// Get the first node of the list
HashEntry<K,V> first = entryAt(tab, index);
// Find whether there is the same key. If there is, determine whether to replace it according to onlyIfAbsent
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// Same key or equal condition
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
// onlyIfAbsent: add if key does not exist
if (!onlyIfAbsent) {
e.value = value;
// Number of modifications plus 1
++modCount;
}
break;
}
// If the current node is not empty, query the next node
e = e.next;
}
// The link list is empty or the target key is not found at the end node
else {
// Node is not empty, indicating that scanAndLockForPut() has a return value
if (node != null)
// The forward interpolation method is also used in HashMap 1.7
node.setNext(first);
// tryLock() succeeded in the first sentence
else
// Add the node forward, and take the first as the next node of the node
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// Expand when the capacity threshold is reached and the maximum capacity is not reached
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
// Put the list of new head nodes into the array
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
// Make sure to unlock no matter what happens
} finally {
unlock();
}
return oldValue;
}
scanAndLockForPut(K key, int hash, V value)
// Method function: create a new node or find a node with the same key and lock it to prepare for adding
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
// Find the head node of the linked list corresponding to the hashcode
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // Positioning node is negative
// Loop acquire lock, thread safe
while (!tryLock()) {
HashEntry<K,V> f; // Please recheck below
if (retries < 0) {
// The linked list is empty or no node with the same key is found after traversing the linked list
if (e == null) {
// retries may be set to - 1 in the lowest else if
// So it's possible to enter here again. You need to judge whether the node is empty
// Although a new node is created here, but there is no link on the list, e is still empty
if (node == null) // Create a new node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
// If the keys are the same, new nodes are not needed
else if (key.equals(e.key))
retries = 0;
// If the end node is not reached and it is not the current node, query the next node
else
e = e.next;
}
// The following code appears: 1. New gives a new node. 2. Find the node with the same key
// Force lock acquisition if number of scans is greater than threshold
else if (++retries > MAX_SCAN_RETRIES) {
// If the maximum number of attempts is exceeded, the lock is forced. If the lock cannot be obtained, it will block (lock the Segment object)
lock();
break;
}
// (retries & 1) = = 0, when the lowest order is not 1
// (retries & 1) = = 0, no such sentence may cause a dead cycle
// Dead cycle: if the above if always sets retries to 0, and Max scan retry > = 1
// If there is no (retries & 1) = = 0 limit, then the following is always a reset scan, i.e. a dead cycle
else if ((retries & 1) == 0 &&
// If the linked list changes, it represents that the thread prior to the current thread has modified the linked list
// Once the link list relationship changes, it is necessary to re traverse the query and lock it
(f = entryForHash(this, hash)) != first) {
e = first = f;
retries = -1;
}
}
return node;
}
// This method is basically the same as the above method, but it is more efficient for locking
private void scanAndLock(Object key, int hash) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
int retries = -1;
while (!tryLock()) {
HashEntry<K,V> f;
if (retries < 0) {
if (e == null || key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f;
retries = -1;
}
}
}
The above method is quite difficult. Readers need to understand each line of code deeply, which is conducive to the reading of the source code. It also verifies the use scenario of max_scan_attributes.
entryAt(HashEntry<K,V>[] tab, int i)
// Use volatile to get the i-th element of a given table and read it directly through the offset address
@SuppressWarnings("unchecked")
static final <K,V> HashEntry<K,V> entryAt(HashEntry<K,V>[] tab, int i) {
return (tab == null) ? null :
// getObjectVolatile() gets the corresponding attribute according to the tab object and offset length
// Here is the element to get the offset length of the array. Volatile ensures visibility and order
(HashEntry<K,V>) UNSAFE.getObjectVolatile
// TSHIFT: offset length of each element of the array, TBASE: offset of the first address of the array
// From these two parameters, we can get the physical address of the element
(tab, ((long)i << TSHIFT) + TBASE);
}
setEntryAt(HashEntry<K,V>[] tab, int i, HashEntry<K,V> e)
// Use volatile write to set the i-th element of the given table.
static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i,
HashEntry<K,V> e) {
// Put e in the specified position of tab by offset address
UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e);
}
The Unsafe class is not covered in this article.
private static final sun.misc.Unsafe UNSAFE;
private static final long SBASE;
private static final int SSHIFT;
private static final long TBASE;
private static final int TSHIFT;
private static final long HASHSEED_OFFSET;
private static final long SEGSHIFT_OFFSET;
private static final long SEGMASK_OFFSET;
private static final long SEGMENTS_OFFSET;
static {
int ss, ts;
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class tc = HashEntry[].class;
Class sc = Segment[].class;
// The offset of the first element of the array is the first address
TBASE = UNSAFE.arrayBaseOffset(tc);
SBASE = UNSAFE.arrayBaseOffset(sc);
// Size of each element in the array, object (pointer) size
ts = UNSAFE.arrayIndexScale(tc);
ss = UNSAFE.arrayIndexScale(sc);
// Get the offset address of the property in the object
HASHSEED_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("hashSeed"));
SEGSHIFT_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("segmentShift"));
SEGMASK_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("segmentMask"));
SEGMENTS_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("segments"));
} catch (Exception e) {
throw new Error(e);
}
// Element length must be exponential power of 2, array element is object (pointer)
// (SS & (SS-1))! = 0 ensures that there is only one 1 in the binary bit, and the rest are all 0
if ((ss & (ss-1)) != 0 || (ts & (ts-1)) != 0)
throw new Error("data type scale not a power of two");
// numberOfLeadingZeros(ss), the number of zeros of the first 1 from high to low
// If the parameter is 0000 0100, the result is: 5
SSHIFT = 31 - Integer.numberOfLeadingZeros(ss);
TSHIFT = 31 - Integer.numberOfLeadingZeros(ts);
}
rehash(HashEntry<K,V> node)
// Expand the capacity of the array and transfer the nodes in the old array to the new array
// This method is implemented in the lock, so the thread is safe and the dead cycle is avoided
@SuppressWarnings("unchecked")
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// Under the limitation of original capacity, double the capacity
int newCapacity = oldCapacity << 1;
// New expansion threshold
threshold = (int)(newCapacity * loadFactor);
// Create a new array
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
// Traversal array, each chain is transferred
for (int i = 0; i < oldCapacity ; i++) {
// Get the first node of the original array subscript
HashEntry<K,V> e = oldTable[i];
// If the list is not empty, transfer
if (e != null) {
HashEntry<K,V> next = e.next;
// Relocate subscript in new array
int idx = e.hash & sizeMask;
// The list has only one node
if (next == null)
newTable[idx] = e;
// If there are multiple nodes, all nodes will be transferred
else {
// Save previous node
HashEntry<K,V> lastRun = e;
// Save the subscript of the previous node
int lastIdx = idx;
// Traversing linked list
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
// Each node needs to be relocated
int k = last.hash & sizeMask;
// Only the subscripts are compared here, which means that although there are multiple nodes, the lastRun has not changed
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// The subscript is marked above, so only one chain is transferred here
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
// Relocation
int k = h & sizeMask;
// Forward interpolation
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// Add a new node to the list
int nodeIndex = node.hash & sizeMask;
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
Because the algorithm of rehash() method is peculiar, it needs to be explained here. Take a linked list as an example to demonstrate.
A linked list in a subscript of the original array. x and y represent the subscript after relocation
Let's trace the changes of lastRun and lastIdx
lastRun = Entry0 lastIdx = x
lastRun = Entry1 lastIdx = y
lastRun = Entry2 lastIdx = x
lastRun = Entry4 lastIdx = x
newTable[lastIdx] = lastRun
//Function: put the last two nodes with subscript y into the subscript y of the new array
//Traverse the nodes before Entry4 and put them in the corresponding subscript of the new array in turn
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
// Relocation
int k = h & sizeMask;
// Forward interpolation
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
From the above demonstration results, if the subscripts of the nodes at the back of a chain list are the same after relocation, then the chain with the same subscripts at the back can be directly transferred to avoid the transfer of one node at a node; when the whole chain is relocated at the same time, the performance is the best.
remove(Object key, int hash, Object value)
// Basic operation of deleting linked list
final V remove(Object key, int hash, Object value) {
if (!tryLock())
// Lock up
scanAndLock(key, hash);
V oldValue = null;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
// Find the first node of the target subscript
HashEntry<K,V> e = entryAt(tab, index);
// Previous node
HashEntry<K,V> pred = null;
while (e != null) {
K k;
HashEntry<K,V> next = e.next;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
V v = e.value;
// If the value is null or equal
if (value == null || value == v || value.equals(v)) {
// The current node is the head node
if (pred == null)
setEntryAt(tab, index, next);
else
pred.setNext(next);
++modCount;
--count;
oldValue = v;
}
break;
}
pred = e;
e = next;
}
} finally {
unlock();
}
return oldValue;
}
Class HashEntry
Consistent with the Entry function of HashMap, only Unsafe is used to improve the reading and writing speed
static final class HashEntry<K,V> {
final int hash;
final K key;
// Values and node points can be changed
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// Place n at the offset address of the next member of this object
final void setNext(HashEntry<K,V> n) {
UNSAFE.putOrderedObject(this, nextOffset, n);
}
static final sun.misc.Unsafe UNSAFE;
// Offset address of next member
static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = HashEntry.class;
// Get the offset of the next member in the object for link operation
// Using UnSafe class can improve speed by directly operating memory
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
attribute
static final int DEFAULT_INITIAL_CAPACITY = 16; static final float DEFAULT_LOAD_FACTOR = 0.75f; // Default concurrency level for this table static final int DEFAULT_CONCURRENCY_LEVEL = 16; static final int MAXIMUM_CAPACITY = 1 << 30; // Minimum capacity per segment table static final int MIN_SEGMENT_TABLE_CAPACITY = 2; // Maximum number of segments, slightly conservative static final int MAX_SEGMENTS = 1 << 16; // Maximum number of attempts before locking, matching with modCount static final int RETRIES_BEFORE_LOCK = 2; // The mask value of the segment through which the segment subscript is located final int segmentMask; // The number of bits used to determine the high position of the segment in the hash value final int segmentShift; // Segment, each segment is a special hash table final Segment<K,V>[] segments;
Construction method
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// concurrencyLevel: concurrency level, that is, the number of Segment segments, which cannot exceed the maximum number of segments
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// segmentShift: number of bits in the middle of the hash value
// If concurrencyLevel = 16, segmentShift = 27
this.segmentShift = 32 - sshift;
// Number of segments - 1, used to calculate the subscript of the target segment through the hash value
this.segmentMask = ssize - 1;
// Array size cannot exceed the maximum capacity
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// c: size of hash table required for each segment
int c = initialCapacity / ssize;
// If initialCapacity / ssize is a floating-point number, it needs to be expanded upward
if (c * ssize < initialCapacity)
++c;
// The minimum array capacity of each segment table is 2
int cap = MIN_SEGMENT_TABLE_CAPACITY;
// Expand the cap to meet the requirements
while (cap < c)
cap <<= 1;
// Although an array of segments is created, only the first element is instantiated, similar to lazy loading
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// Put s0 in the first element of ss array
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
// Initialize with default load factor and synchronization level
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
// threshold = capacity * loadFactor
// -> capacity = m.size / loadFactor
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
putAll(m);
}
Core method
put(K key, V value)
// put() method, if there is the original key value pair, replace the value, no direct addition
// key and value cannot be null
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s;
// Value cannot be null
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// Segment subscript is determined by high n bits of hash value
int j = (hash >>> segmentShift) & segmentMask;
// Get the target segment according to the physical address
// SSHIFT: Segment array offset of each element, SBASE: Segment array offset of the first element
// The physical address of the target subscript element can be calculated from the above two offsets
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
// Confirm that the segment exists. If not, the method will initialize
s = ensureSegment(j);
// false : boolean onlyIfAbsent
return s.put(key, hash, value, false);
}
// If there is an original key value pair, the value will not be replaced and there will be no direct addition
@SuppressWarnings("unchecked")
public V putIfAbsent(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
// true : boolean onlyIfAbsent
return s.put(key, hash, value, true);
}
// Add all maps of the target map to this object
public void putAll(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
ensureSegment(int k)
// Confirm the segment, if not, create
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
// Get physical address, offset of SSHIFT: Segment element, address of first element of SBASE: ss
long u = (k << SSHIFT) + SBASE;
Segment<K,V> seg;
// When the object obtained by physical address is empty, the condition is true
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// The first element of the segments array is initialized in the constructor
// Therefore, the first element can be used as a template to initialize other empty segments
Segment<K,V> proto = ss[0];
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
// Check whether the segment is empty again to avoid that other threads have already created it
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// Create segment object
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// cas operation. When the target segment is empty, it is replaced. Otherwise, it is not replaced
// This judgment can prevent two threads from replacing twice at the same time
// If one thread completes the replacement, the other thread does not set the exit loop condition at the next get
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
get(Object key)
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
// Get hash value of key
int h = hash(key);
// H > >
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// If the subscript segment is not empty and the array in the segment is not empty, the condition is true
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// UNSAFE.getObjectVolatile() gets the object under the physical address of the array
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
// (tab. Length - 1) & H: use all hash values for element subscript positioning
// TSHIFT: offset of each element in the hash table, TBASE: offset of the first element in the hash table
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
size()
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // True if size overflows 32 bits
long sum; // Sum of modCounts
long last = 0L; // Previous sum
int retries = -1; // The first iteration is not a retry
try {
for (;;) {
// Retries before locking, retries "before" lock = 2, retries 3 times
// When you can't get the ideal result without locking, force locking for size statistics
if (retries++ == RETRIES_BEFORE_LOCK) {
// Lock every segment
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock();
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
// overflow
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// Retry until no other thread operates on the hash table during statistics
// When the sum traversed twice is the same, it means that there is no other thread to interfere, and the value can be returned
if (sum == last)
break;
last = sum;
}
} finally {
// It's only necessary to unlock if it's locked
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
remove(Object key)
public V remove(Object key) {
int hash = hash(key);
// Get target segment based on hash value
Segment<K,V> s = segmentForHash(hash);
return s == null ? null : s.remove(key, hash, null);
}
public boolean remove(Object key, Object value) {
int hash = hash(key);
Segment<K,V> s;
return value != null && (s = segmentForHash(hash)) != null &&
s.remove(key, hash, value) != null;
}
summary
This blog has explained the key internal classes and methods of concurrenthashmap 1.7. By reading its source code, we find that the author of JDK is very flexible in the operation related to ensuring multithreading safety, from which we can learn some ideas and apply them to daily concurrent programming.

