We take jdk1.7.0_80 as an example to analyze the HashMap source code.
Catalog
- 1, Source code analysis
- 1.1 important properties of HashMap
- 1.2 analytical PUT method
- 1.3 analyze resize method
- 1.4 parse GET method
- 2, Problem summary
- 2.1 how does the rounduptopower of 2 (toSize) method realize to find a power of 2 greater than or equal to toSize?
- 2.2 why is the initialization capacity or expansion capacity of an array a power of 2?
- 2.3 what is the function of inithashseedasneeded (capacity) method?
- 2.4 why does the hash value of key need to be obtained through multiple right shifts and XORs?
- 2.5 why is the subscript value of an array passed through the hash value of the key & (array length - 1) instead of |?
- 2.6 what is the purpose of array expansion?
- 2.7 when the hashmap of jdk1.7 is expanded under multithreading, the call get or put will have a dead cycle. Why?
- 2.8 what is modcount used for?
- 2.9 how to find a power number less than or equal to the current number?
1, Source code analysis
This article will not analyze all methods in HashMap, but only several important methods, such as PUT, GET, etc.
1.1 important properties of HashMap
Let's take a look at some of the important properties in the Hashmap class.
//Default array initialization capacity 16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 //30 power of maximum capacity 2 tatic final int MAXIMUM_CAPACITY = 1 << 30; //Default load factor. static final float DEFAULT_LOAD_FACTOR = 0.75f; //Empty array static final Entry<?,?>[] EMPTY_TABLE = {}; //Array, resize as needed. The length must always be a power of 2. transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //Number of elements in the current hashMap transient int size; //Threshold value (capacity * load factor). Used for capacity expansion 16 * 0.75 int threshold; //Load factor for the hash table. final float loadFactor; //Number of Hashmap modifications transient int modCount; //Default threshold for mapped capacity static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE; //The element of an array is a linked list static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } //……………………… Ellipsis. }
It can be seen from the above code that: HashMap is implemented by array plus linked list.
So here's a simple question: why use the combination of arrays and linked lists instead of just arrays?
We all know that arrays are characterized by fast queries and slow inserts. The characteristics of linked list are fast insertion and slow query. When using HashMap, put and get methods are used frequently. If only array structure is used, put efficiency will be poor. If only the linked list structure is used, the efficiency of get will be very poor. We should consider both efficiency, so we use the combination of array and linked list.
1.2 analytical PUT method
Let's start with a simple example:
public class HashMapDemo { public static void main(String[] args) { HashMap<Object, Object> map = new HashMap<>(); map.put("1","1"); map.get("1"); } }
First, analyze the HashMap < object, Object > map = new HashMap < > (); of course, we can also use new HashMap(10); custom array capacity. Follow up the source code, we can see that he just did some simple initialization work, that is, assign the incoming load factor to the loadFactor attribute of HashMap, and assign the incoming initial capacity to the threshold attribute of HashMap.
public HashMap() { //DEFAULT_INITIAL_CAPACITY = 16,DEFAULT_LOAD_FACTOR = 0.75f this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); }
Enter this method:
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); //Assign the incoming load factor value of 0.75 to the loadFactor attribute of the hashMap this.loadFactor = loadFactor; //Assign the incoming initial capacity 16 to the threshold attribute of the hashMap threshold = initialCapacity; init(); }
Next, analyze the put method. Look at the source code of put:
public V put(K key, V value) { //Initialize if array is empty if (table == EMPTY_TABLE) { //Array initialization inflateTable(threshold); } //If key==null, enter the following method, indicating that in hashmap, key can be null if (key == null) return putForNullKey(value); //Calculate the hash value of key int hash = hash(key); //Calculate array subscript corresponding to key int i = indexFor(hash, table.length); //Loop the list of the current element of the array. It will not loop every time or to the end of the list, so you don't need to worry about efficiency for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //If the passed in key already exists in the linked list, the value corresponding to the passed in key will be used to overwrite the value //And return the old value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } //HashMap modification flag plus 1 modCount++; //Add Entry, put in array addEntry(hash, key, value, i); return null; }
Each line of comments explains the overall process of put, and we will analyze each line of code below.
(1) First, enter judgment. If the array is empty, initialize it. Let's enter the inflateTable(threshold) method to see how to initialize. The threshold is 16 by default
private void inflateTable(int toSize) { //Find a power of 2 greater than or equal to toSize as the array initialization capacity //For example, if toSize=10, then capacity should be = 16 //If toSize=16, then capacity should be = 16 //How is it done here? int capacity = roundUpToPowerOf2(toSize); //Calculate the threshold value, 16 * 0.75 = 12 by default threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); //Array initialization, this capacity is the calculated value 16 table = new Entry[capacity]; //Initialize hash seed initHashSeedAsNeeded(capacity); }
Through the above array initialization, we know that the passed in parameter toSize=16, and the capacity obtained by the rounduptopof2 (tosize) method is 16, so the initialized array capacity is 16.
At the same time, two questions are raised here:
- How does the rounduptopower of 2 (toSize) method find a power number greater than or equal to toSize?
- Why does the initialization capacity of an array have to be a power of two?
- What is the function of the initHashSeedAsNeeded(capacity) method?
(2) Next, let's see how HashMap deals with the case of key=null. We enter putForNullKey(value) to analyze:
private V putForNullKey(V value) { //Traversing elements (linked list) at position 0 of array for (Entry<K,V> e = table[0]; e != null; e = e.next) { //Traverse the linked list. If key==null, the new value will overwrite the original value and return the original value if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } //Modification mark plus 1 modCount++; //If the 0 position of the array is null, put the passed value at the 0 position of the array addEntry(0, null, value, 0); return null; }
It can be seen from the above code that the key is allowed to be null in the HashMap, and the value corresponding to key=null will be encapsulated as Entry and put in the position with the array subscript of 0, and the original existing elements will be overwritten.
(3) Next, calculate its hash value hash(key) according to the passed key:
final int hash(Object k) { //The seed value is 0 by default. If it is not 0, disable k.hashCode() to reduce hash conflict int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } //Calculate the hash value of key h ^= k.hashCode(); //The hash value is 32 bits, and the array length is only 16 bits. The constant right shift and exclusive or of hash value will enable the high bit of hash value to participate in the calculation, ensure better hash and reduce hash conflict. h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
It can be seen from the above code that the hash value of key is not directly obtained from hashCode(), but from multiple right shifts and XORs.
Here we ask a question:
- Why does the hash value of key need to be obtained through multiple right shifts and XORs?
(4) Next, parse indexFor(hash, table.length) to get the index of the array:
static int indexFor(int h, int length) { // Hash value of key & (array length - 1) return h & (length-1); }
From the above code, we can see that the subscript value of the array is obtained by the hash value & (array length - 1) of the key.
Let's ask a question here:
- Why is the index value of the array passed through the hash value of the key & (array length - 1)?
(4) After calculating the array subscript value, we start to loop through the array elements (linked list) corresponding to the subscript value:
for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
From the above code, traverse the list. If the passed key already exists in the list, overwrite the old value with the value corresponding to the passed key, and return the old value.
(5) Finally, analyze addEntry(hash, key, value, i), which is the real way to store elements:
void addEntry(int hash, K key, V value, int bucketIndex) { //If the number of elements stored in the current hashMap is greater than the threshold value and the array elements under the bucket index index are not empty, expand the capacity if ((size >= threshold) && (null != table[bucketIndex])) { //Capacity expansion resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } //Create elements createEntry(hash, key, value, bucketIndex); }
It is the first time for us to put data, so we don't need to expand the capacity and directly enter the createentry (hash, key, value, bucket index) method:
void createEntry(int hash, K key, V value, int bucketIndex) { //Find the corresponding element e according to the subscript value bucketIndex Entry<K,V> e = table[bucketIndex]; //Create an element Entry, assign e to Entry.next, and place the Entry in the bucket index of the array table[bucketIndex] = new Entry<>(hash, key, value, e); //Length plus 1 size++; } //*********new Entry************* Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; }
From the above code, we can see that the array storage element is in the way of header insertion.
If the format of the array was originally shown in Figure 1, now put a data with key = Li Si and value = Li Si, and encapsulate it as an Entry. The array subscript corresponding to this element happens to be bucketIndex, then we put this Entry in this position, and the flow is shown in Figure 2 and figure 3: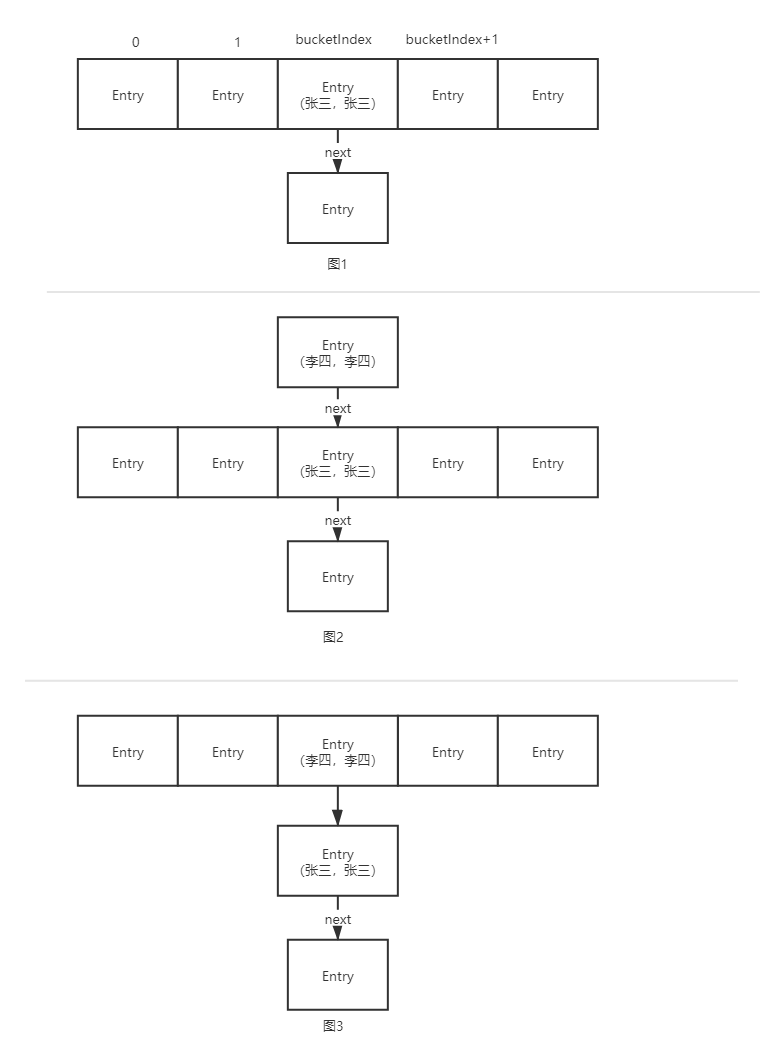
So here's a question:
- What about the head insertion method used in the put method of HashMap in jdk1.7?
From the above figure, it is easy to know that the head insertion method does not need to traverse the list, which has high efficiency. If the tail insertion method is used, it needs to traverse the list to find the tail, which has low efficiency.
1.3 analyze resize method
When parsing to the createEntry(int hash, K key, V value, int bucketIndex) method, there is a section of expanding Code:
//If the number of elements stored in the current hashMap is greater than the threshold value and the array elements under the bucket index index are not empty, expand the capacity if ((size >= threshold) && (null != table[bucketIndex])) { //Capacity expansion resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); }
Assuming that the capacity size of the current element put into the table has exceeded the threshold (value is 12), and the element under the subscript of the bucketIndex is not null, then resize(2 * table.length), and the expansion parameter is 2 * table.length=2*16=32:
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } //The above code is to record the old array table and save it //Create a new 32 capacity array newTable Entry[] newTable = new Entry[newCapacity]; //Put the elements on the oldTable on the newTable to complete the array transfer transfer(newTable, initHashSeedAsNeeded(newCapacity)); //Assign new array to old array after transfer table = newTable; //Recalculate threshold 32 * 0.75 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
It can be seen from the above code that the real way to realize capacity expansion is transfer(newTable, initHashSeedAsNeeded(newCapacity)):
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; //Double loop, loop the old array table first for (Entry<K,V> e : table) { //Recycle list elements above old array elements while(null != e) { Entry<K,V> next = e.next; //rehash defaults to false, which will be resolved later if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } //Recalculate the array subscript value according to the hash value of key and the new array capacity 32 //The calculated i may be the same as before and may be different (related to the high hash value of key) int i = indexFor(e.hash, newCapacity); //The following two lines of code use the method of header insertion to put the element e on the new array e.next = newTable[i]; newTable[i] = e; //Assign next to amount for next cycle e = next; } } }
It can be seen from the above code that the capacity expansion of HashMap is to create a new array, which is twice the capacity of the old array, and then the elements on the old array are recalculated according to the array subscript value. Store on the new array.
We use graphics to describe the above Codes:
First, there is a linked list element at a certain position on the old array. We traverse the linked list, assuming that the new index value i calculated is the same. The new array has twice the capacity of the old one:
When e.next = newTable[i]; is executed, it becomes as follows:
Then execute newTable[i] = e; as shown below:
Next, execute e = next; enter the next cycle, and the final result is as follows: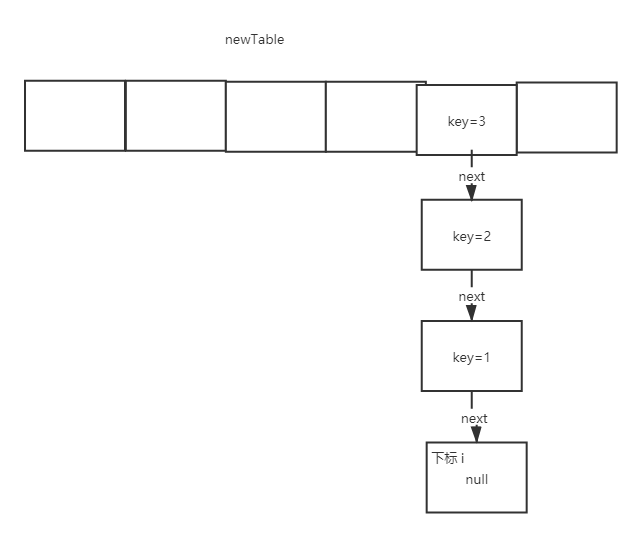
As can be seen from the above figures, the expanded list is in reverse order.
So here are two questions:
- What is the purpose of array expansion?
- There will be a dead cycle in the expansion of hashmap of jdk1.7 under multithreading. Why?
- How can multithreading prevent loops?
1.4 parse GET method
The source code of get method is as follows:
public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
When the key is null, we enter the getForNullKey() method to get the corresponding value:
private V getForNullKey() { if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
As we said earlier, when the key is null, the corresponding value is encapsulated as an Entry and placed in the 0 position of the array table. Then the above method is to find the corresponding value when the key is null from table[0].
When the key is not null, get the value through getEntry(key):
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } //Calculate the hash value of key int hash = (key == null) ? 0 : hash(key); //The array subscript value is calculated according to the hash value and the array length, and the array elements corresponding to the subscript value are traversed for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; //Traverse the linked list, and if the same key value as the passed key is found, this element will be returned if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
2, Problem summary
In the process of parsing the source code, we have raised some questions, and we will answer them one by one.
2.1 how does the rounduptopower of 2 (toSize) method realize to find a power of 2 greater than or equal to toSize?
First, the rounduptopower of 2 (toSize) method is called when the put element initializes the array:
private static int roundUpToPowerOf2(int number) { // number =16 //Maximum ABCD capacity defaults to the thirtieth power of 2 //Because number > 1 is set, enter the integer.highestonebit ((number - 1) < 1) method, and the result is 15 * 2 = 30 if the number - 1) < 1 result is 15 move left return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; }
Let's go to Integer.highestOneBit(30). The theoretical result should be 16:
public static int highestOneBit(int i) { // HD, Figure 3-1 i |= (i >> 1); i |= (i >> 2); i |= (i >> 4); i |= (i >> 8); i |= (i >> 16); return i - (i >>> 1); }
The calculation process is as follows:
highestOneBit(30)
30 0001 1110
>>1 0000 1111
| 0001 1111 -------32
>>2 0000 0111
| 0001 1111 ------32
>> 4 0000 0001
| 0001 1111 ----- 32
........
The later operation is the same as the previous one, and the result is 0001 1111
0001 1111
>>>1 0000 1111
Subtract 00010000
Result 00010000 ------ 16
So the final value returned by the rounduptopower of 2 (int number) method is 16
2.2 why is the initialization capacity or expansion capacity of an array a power of 2?
Let's look at an example to see the law of binary numbers:
2--------------0010
4--------------0100
8--------------1000
16-------------0001 0000 --------------- Minus 1 ----------- 0000 1111
From the above example, we can see that there is only one binary number corresponding to the power of 2, so we will execute h & (length-1) when calculating the subscript of the array. We take the default value of length as 16, for example, length-1=15, and the corresponding binary number is 0000 1111, so that the result of h & 0000 1111 will satisfy the length range of the array must be 0-15 (because the high-order & rear all 0), and the lower four bits of the result are the lower four bits of h, so that the subscript values can be evenly distributed above 0-15. For example, if length=15,15 is not the power of 2, then length-1=14, and the corresponding binary number is 0000 1110, then the last bit of h & 0000 1110 must be 0, the last bit is 0, and the last four bits are 00010011010110011001101101111101101101, which can never store the elements. The space waste is quite large and even worse In this case, the position that an array can be used is much smaller than the length of the array, which means that the probability of collision is further increased and the efficiency of query is slowed down! This will result in a waste of space.
2.3 what is the function of inithashseedasneeded (capacity) method?
In the previous source code analysis, we used this method in array initialization and array expansion.
First, we enter the static code block of HashMap:
static final int ALTERNATIVE_HASHING_THRESHOLD; static { //If the JDK parameter jdk.map.althashing.threshold is configured, then the altThreshold is not empty. In general, the user will not configure this threshold String altThreshold = java.security.AccessController.doPrivileged( new sun.security.action.GetPropertyAction( "jdk.map.althashing.threshold")); int threshold; try { //If altThreshold is not null, threshold =altThreshold, otherwise threshold = nterger.max_value threshold = (null != altThreshold) ? Integer.parseInt(altThreshold) : ALTERNATIVE_HASHING_THRESHOLD_DEFAULT; // disable alternative hashing if -1 if (threshold == -1) { threshold = Integer.MAX_VALUE; } if (threshold < 0) { throw new IllegalArgumentException("value must be positive integer."); } } catch(IllegalArgumentException failed) { throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed); } //assignment ALTERNATIVE_HASHING_THRESHOLD = threshold; }
Enter the initHashSeedAsNeeded method:
final boolean initHashSeedAsNeeded(int capacity) { //By default, hashSeed=0, then currentAltHashing=false boolean currentAltHashing = hashSeed != 0; // If the JDK parameter jdk.map.althashing.threshold is configured, and the capacity > = configuration value is set (generally not set, useAltHashing =false), then useAltHashing =true boolean useAltHashing = sun.misc.VM.isBooted() && (capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD); // boolean switching = currentAltHashing ^ useAltHashing; if (switching) { //Calculate hash seed value hashSeed = useAltHashing ? sun.misc.Hashing.randomHashSeed(this) : 0; } return switching; }
When expanding an array, there is a code like this:
if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); }
rehash is the switching value returned above. If it is true, the hash value of the key will be recalculated. The purpose of hash seed is to make key computing hash more complex and hash.
2.4 why does the hash value of key need to be obtained through multiple right shifts and XORs?
The hash value is 32 bits, and the length is only 16 bits when the array is not expanded. The constant right shift and exclusive or of the hash value will enable the high bit of the hash value to participate in the calculation, ensure better hash and reduce hash conflict.
2.5 why is the subscript value of an array passed through the hash value of the key & (array length - 1) instead of |?
Because & is more efficient than I and has better hash.
2.6 what is the purpose of array expansion?
The purpose is to reduce hash conflicts and shorten the list.
2.7 when the hashmap of jdk1.7 is expanded under multithreading, the call get or put will have a dead cycle. Why?
The code is as follows:
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
If there are the following scenarios: two threads execute to the capacity expansion stage at the same time, two new arrays will be created. When they execute to the entry < K, V > next = e.next stage, thread 1 continues to execute normally, and thread 2 is stuck here.
After the execution of thread 1, thread 2 is still in entry < K, V > next = e.next; the phase scenario is as follows: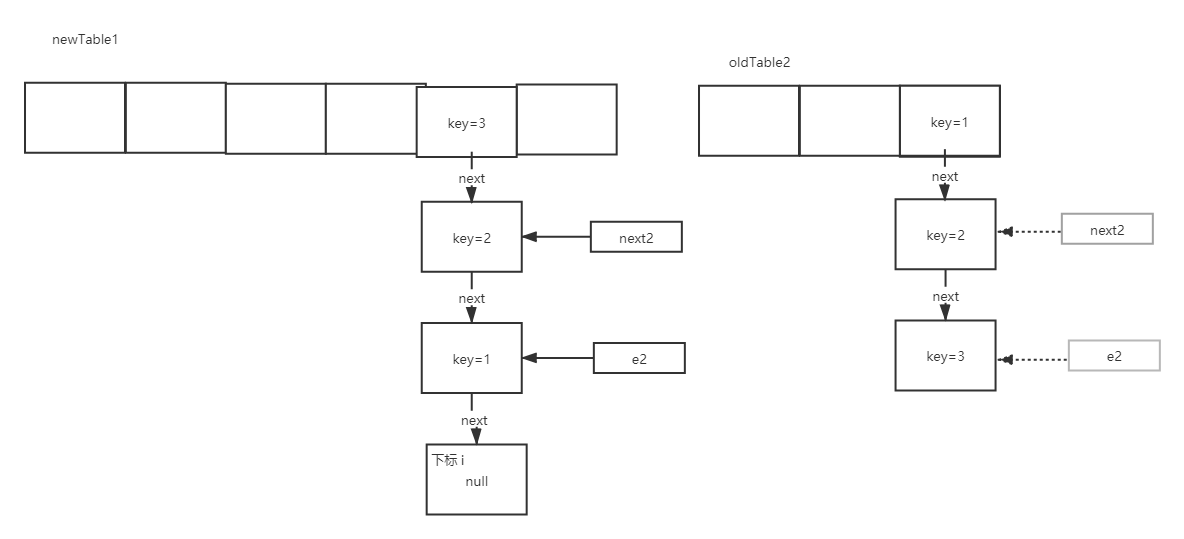
When thread 1 finishes executing, a scenario of newTable1 will appear. At this time, the original pointer of oldTable2 will also be transferred to newTable1.
Suppose thread 2 starts executing again at this time, executing the first cycle: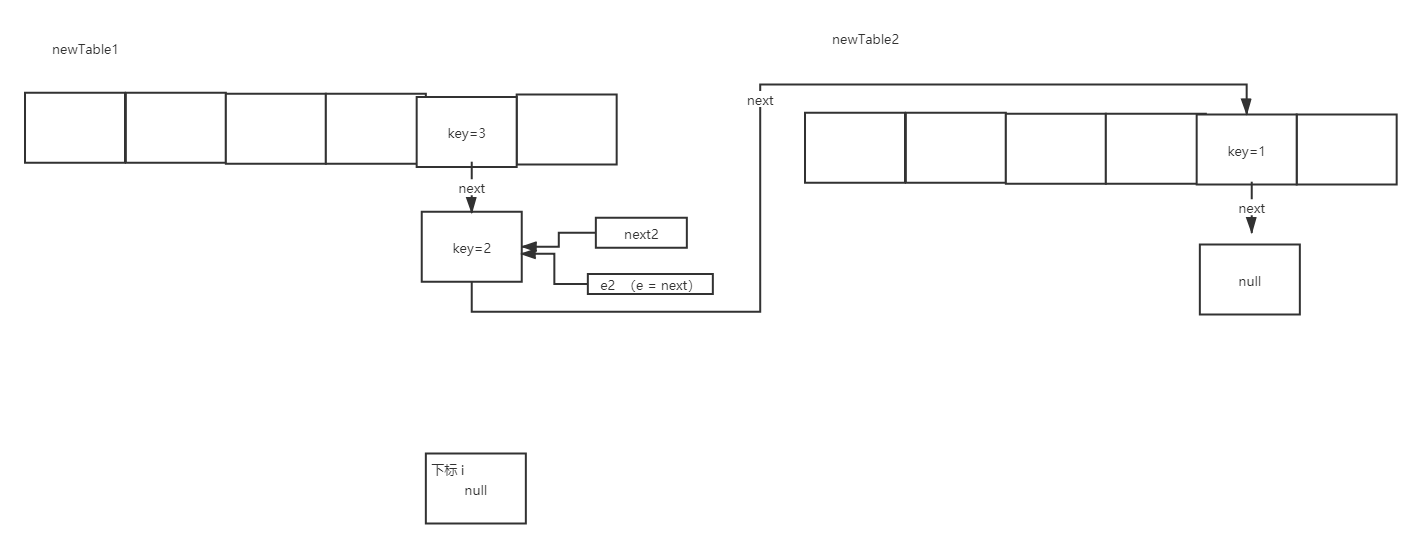
When executing the second loop of this code, enter < K, V > next = e.next;: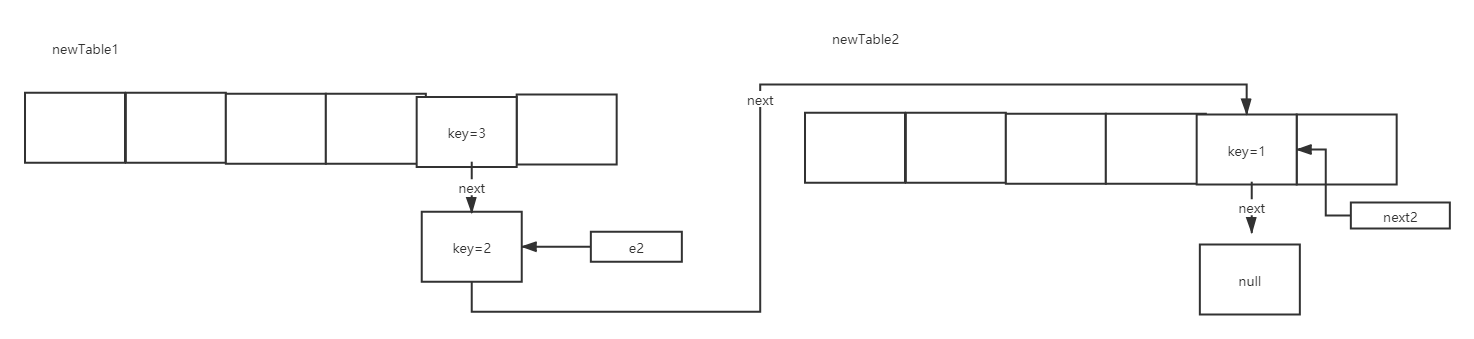
And then when you're done with the code
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
The scenario is as follows: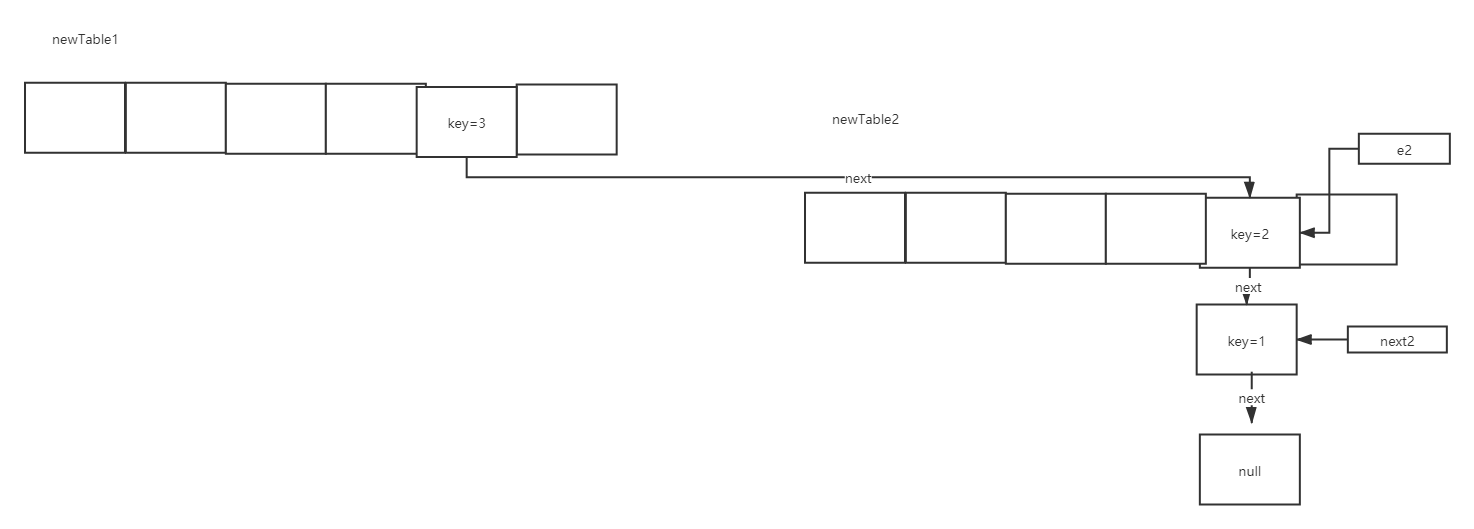
Next, execute e = next; then e2 moves to the position of key=1: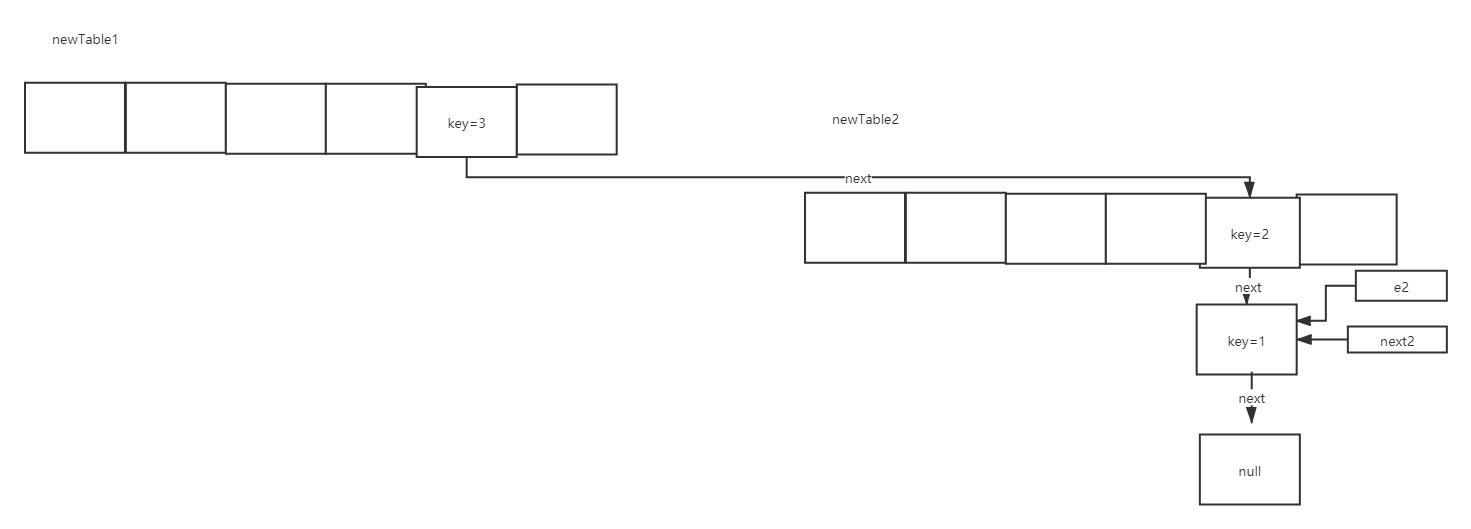
Execute the third cycle again, entry < K, V > next = e.next;:
Then execute e.next = newTable[i];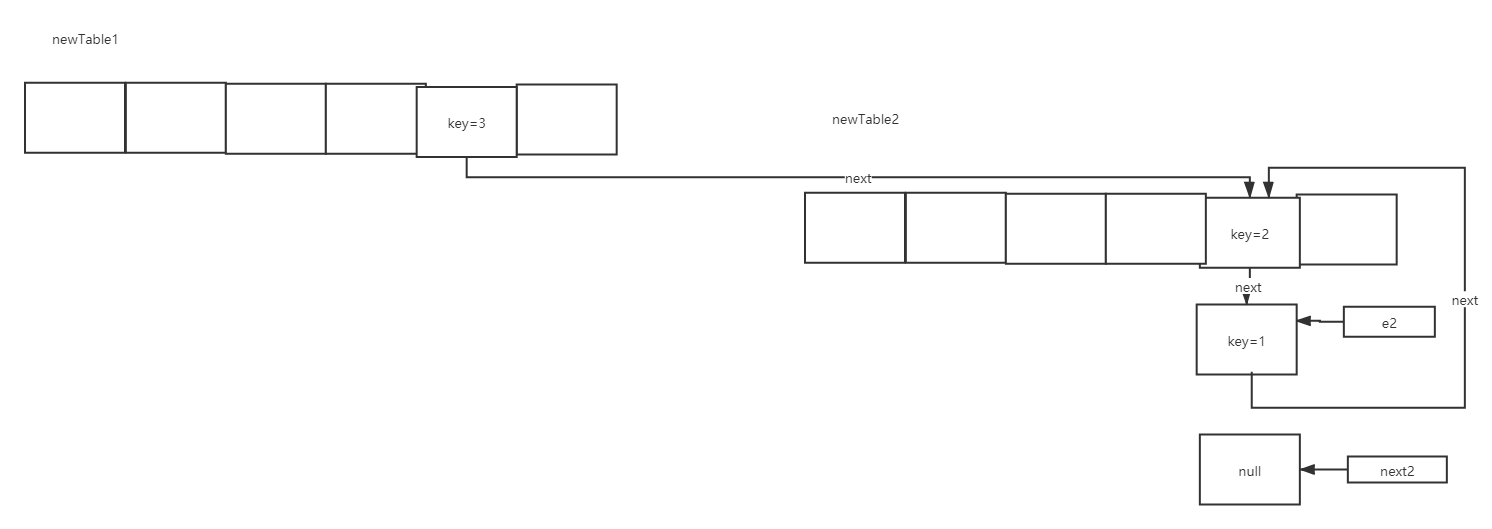
Finally, execute e = next; get e=null, and exit the code at the third loop.
At this time, there is a circular list. When we get elements or put, we will traverse the list and a dead cycle will appear.
2.8 what is modcount used for?
for instance:
public class HashMapDemo { public static void main(String[] args) { HashMap<Object, Object> map = new HashMap(); map.put("1", "1"); map.put("2", "2"); map.put("3", "3"); for(Iterator i$ = map.keySet().iterator(); i$.hasNext(); ) { Object key = i$.next(); if (key.equals("2")) { map.remove(key); //i$.remove(); } } } }
The execution result of this code is:
Exception in thread "main" java.util.ConcurrentModificationException at java.util.HashMap$HashIterator.nextEntry(HashMap.java:922) at java.util.HashMap$KeyIterator.next(HashMap.java:956) at HashMapDemo.main(HashMapDemo.java:12)
Wrong report. The reason for wrong report is related to modCount. First let's look at the source of the anomaly:
final Entry<K,V> nextEntry() { //Error reported when modcount! = expectedmodcount if (modCount != expectedModCount) throw new ConcurrentModificationException(); Entry<K,V> e = next; if (e == null) throw new NoSuchElementException(); if ((next = e.next) == null) { Entry[] t = table; while (index < t.length && (next = t[index++]) == null) ; } current = e; return e; }
Because the three execution of map.put in the example code is based on the source code of put. At this point, modCount =3, when we traverse map, executes map.keySet().iterator(), enters the source code, and calls newEntryIterator (), then calls EntryIterator(), then calls its parent class HashIterator construction method:
HashIterator() { expectedModCount = modCount; if (size > 0) { // advance to first entry Entry[] t = table; while (index < t.length && (next = t[index++]) == null) ; } }
It can be seen from the above code that modCount is assigned to expectedModCount. If it is known that modCount=3, expectedModCount =3.
Next, execute Object key = i$.next(); get the key:
public Map.Entry<K,V> next() { return nextEntry(); }
In this method, the method of throwing the exception above is called nextEntry().
Next, execute the map.remove(key) method to delete the element:
final Entry<K,V> removeEntryForKey(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); int i = indexFor(hash, table.length); Entry<K,V> prev = table[i]; Entry<K,V> e = prev; while (e != null) { Entry<K,V> next = e.next; Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { modCount++; size--; if (prev == e) table[i] = next; else prev.next = next; e.recordRemoval(this); return e; } prev = e; e = next; } return e; }
In this method, modCount + +, modCount=4.
Then the code in the example enters the next cycle, and executes Object key = i$.next(); nextEntry() will be called, at this time, modCount =4, expectedModCount=3, modcount! = expectedmodcount, so throw new ConcurrentModificationException();
How to solve this exception:
Change map.remove(key); to i$.remove();
The significance of HashMap is that it is not thread safe. If there are two threads, traversal and modification, there will be concurrency problem. If HashMap finds this problem, it will throw an exception and fail quickly.
2.9 how to find a power number less than or equal to the current number?
In the 2.1 problem, there is a method, highestOneBit(int i), which can get a power of 2 less than or equal to the current number I.
public static int highestOneBit(int i) { // HD, Figure 3-1 i |= (i >> 1); i |= (i >> 2); i |= (i >> 4); i |= (i >> 8); i |= (i >> 16); return i - (i >>> 1); }
It is equivalent to changing the number of all bits after the high-order 1 to 1. Finally, subtract the number after the number moves one bit to the right from this number and you will get the power of 2.
In the way of moving right and or, you can always move right 1 + 2 + 4 + 8 + 16 = 31, which is exactly the 31 power of the range 2 of the integer (int 4 bytes, 32 bits), until the high bit becomes 0, which is the safest way to do so.

