hadoop to build highly available clusters
Question: What are the problems with existing clusters? HDFS clusters, in a single NN scenario, if the NN fails, the entire HDFS cluster will not be available (centralized cluster), the solution is to configure multiple NNs.
But the question arises again. Which one of these NN Ns provides services to the outside world?
When HDFS achieves high availability of multiple NNs, but only one NN provides service to the outside world, the other Ns are substitutes. When the NN downtime (standby) that is providing the service, the other Ns automatically switch the Active state.
When one NN fails, other NNs compete for the upper position
Use automatic failover mechanisms in highly available clusters to complete switching
2NN is not required in highly available clusters
No, the metadata maintenance strategy will continue to be as it is, but in highly available clusters, a new service (JournalNode) will be added, which itself will be built into a cluster state. Much like the Zookeeper cluster, where more than half of the surviving machines are available, the service will function properly. It is mainly responsible for edit ing the content sharing of log files.
Manually set up HA clusters
Preparations
1. stay/opt/module/Create Folder under ha
mkdir /opt/module/ha
2. Put the current hadoop Copy installation directory to /opt/module/ha
cp -r hadoop-3.1.3/ ha/
3. Deleting some redundant directory files is guaranteed to be an initialization cluster state(Back to Filelist State)
rm -rf data/ logs/ input_smallfile/ output output1 wcinput/ wcoutput/
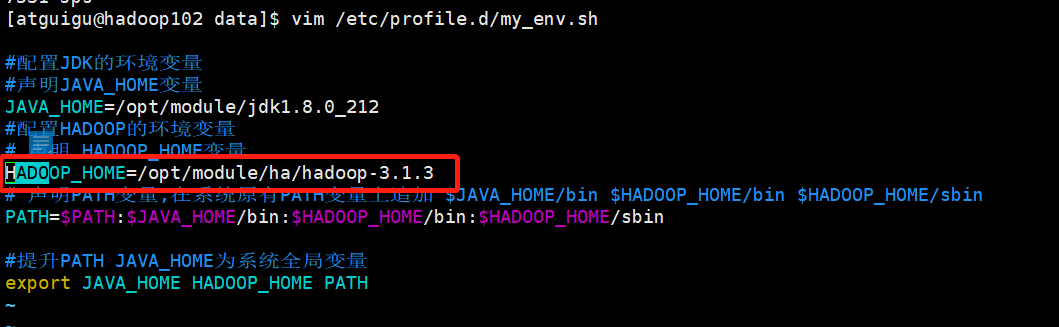
4. modify HADOOP_HOME Environment variables vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/ha/hadoop-3.1.3
5. Remember to distribute after modifying environment variables
my_rsync.sh /etc/profile.d/my_env.sh
Formally set up HA cluster
-
Modify the configuration file core-site.xml
<configuration> <!-- Put more than one NameNode Addresses are assembled into a cluster mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- Appoint hadoop Storage directory for data --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/ha/hadoop-3.1.3/data</value> </property> <!-- To configure HDFS The static user used for Web page login is atguigu --> <property> <name>hadoop.http.staticuser.user</name> <value>atguigu</value> </property> <!-- Configure this atguigu(superUser)Host Node Allowed Access through Proxy --> <property> <name>hadoop.proxyuser.atguigu.hosts</name> <value>*</value> </property> <!-- Configure this atguigu(superUser)Allow users to belong to groups through proxy --> <property> <name>hadoop.proxyuser.atguigu.groups</name> <value>*</value> </property> <!-- Configure this atguigu(superUser)Allow users through proxy--> <property> <name>hadoop.proxyuser.atguigu.groups</name> <value>*</value> </property> </configuration>
5. Modify the configuration file hdfs-site.xml
<configuration> <!-- NameNode Data Store Directory --> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/name</value> </property> <!-- DataNode Data Store Directory --> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/data</value> </property> <!-- JournalNode Data Store Directory --> <property> <name>dfs.journalnode.edits.dir</name> <value>${hadoop.tmp.dir}/jn</value> </property> <!-- Fully distributed cluster name --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- In Cluster NameNode What are the nodes --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2,nn3</value> </property> <!-- NameNode Of RPC Mailing address --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop102:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop103:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn3</name> <value>hadoop104:8020</value> </property> <!-- NameNode Of http Mailing address --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop102:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop103:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>hadoop104:9870</value> </property> <!-- Appoint NameNode Metadata in JournalNode Storage location on --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value> </property> <!-- Access Proxy Class: client Used to determine which NameNode by Active --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- Configure isolation mechanisms where only one server can respond externally at a time --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- Required when using isolation mechanism ssh Secret key login--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/atguigu/.ssh/id_rsa</value> </property> </configuration>6. Distribute the two configuration files just modified, core-site.xml,hdfs-site.xml to 103,104 machines
# pwd = /opt/module/ha/hadoop-3.1.3/etc/hadoop [atguigu@hadoop102 hadoop]$ my_rsync core-site.xml hdfs-site.xml
7. On each JournalNode of 102, 103, 104, enter the following command to start the journalNode service
hdfs --daemon start journalnode You will find that/data A built under the directory jn Folder
8. On hadoop102 nn1, format it and start
hdfs namenode -format # Remember to delete the previously generated / data, /logs folder hdfs --daemon start namenode
9. Synchronize nn1 metadata information on nn2 of hadoop103 and nn3 of hadoop104, respectively
hdfs namenode -bootstrapStandby This will occur in the/data Generate under directory/name Folder, if not generated, must confirm that the command was executed successfully
10. Start nn1 on hadoop103 and nn2 on hadoop104, respectively.
hdfs --daemon start namenode
11. Access nn1 nn2 nn3 via web address
http:hadoop102:9870 http:hadoop103:9870 http:hadoop104:9870
12. Start DN on each machine
hdfs --daemon start datanode
13. Switch one of the NNs to Active state
hdfs haadmin -transitionToActive nn1
14. Check to see if Active
hdfs haadmin -getServiceState nn1
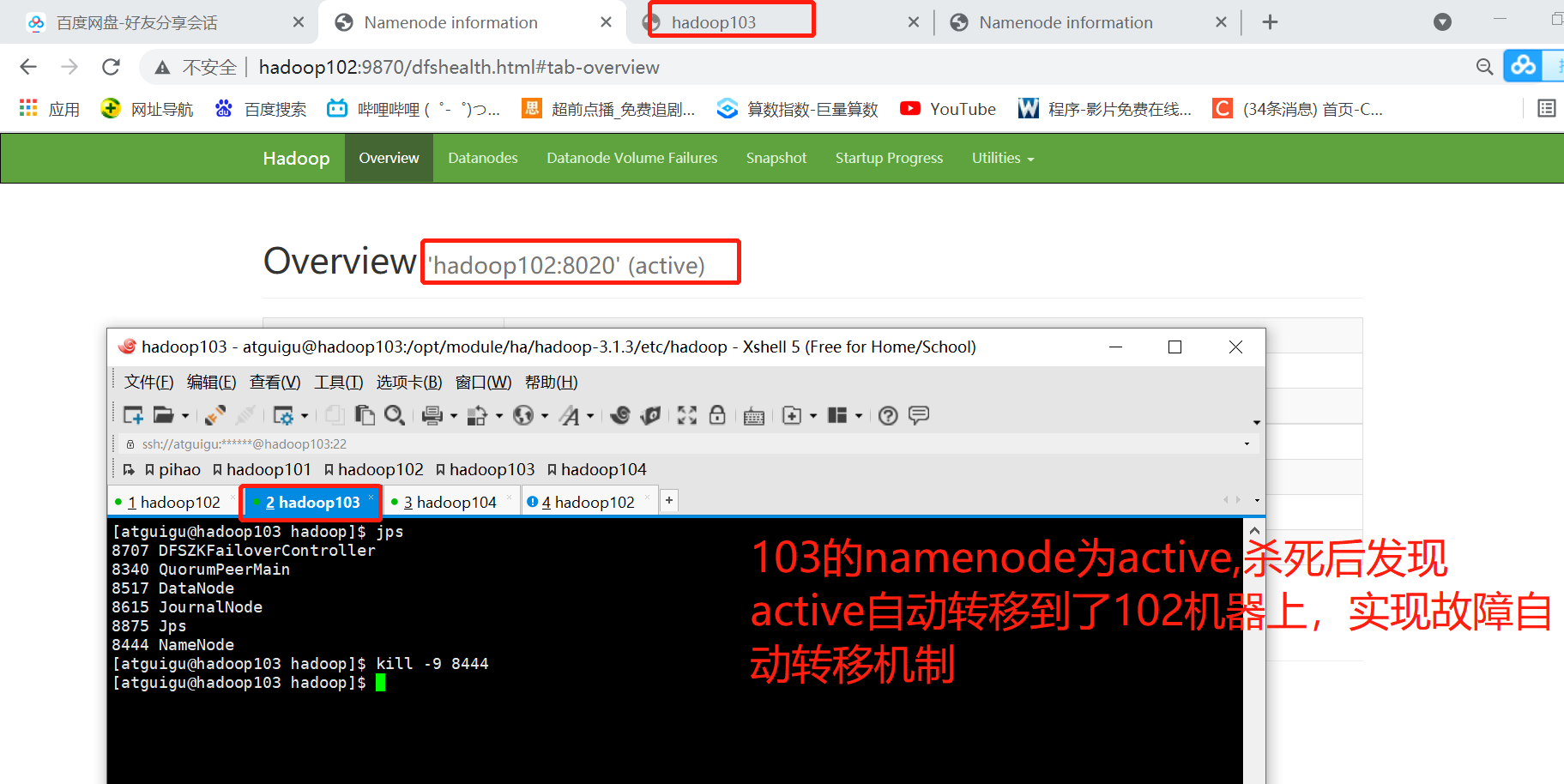
At this point, the highly available cluster for the manual version of hadoop has been set up, but now think about the question: nn2 is active now, but if nn2 is down? Will the NNs of the other two machines become active? After testing, it is found that this is not possible, and it is not possible to switch NN to active manually

Manual switch is not allowed because 102 may be in a false dead state
Restart 102 hdfs cluster, start-dfs.sh, at which point 102 becomes standby again, and you need to manually specify which machine is active again. It is cumbersome, at which point failover is not automatic
Full HDFS HA Cluster
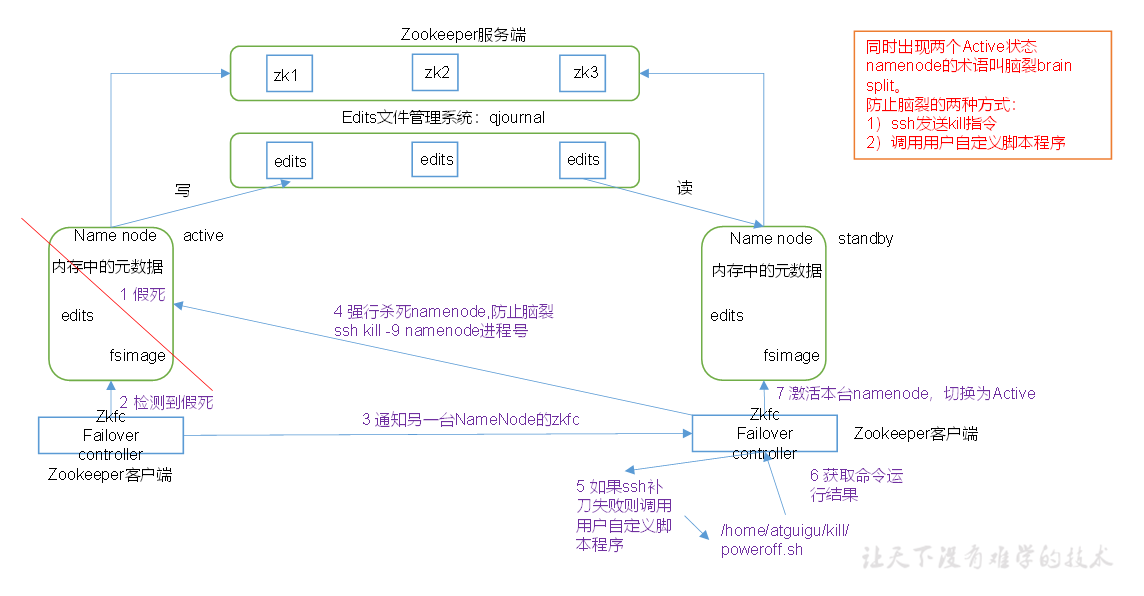
Principle of automatic failover mechanism
Automatic failover adds two new components to HDFS deployment: ZooKeeper and ZKFailoverController (ZKFC) processes
Function of ZKFC: When the cluster starts, zkfc of each NN will write its own content to the node specified by zk, which NN will write successfully, which is equivalent to the success of the upper position contention, becoming Active. zkfc is mainly used to monitor the health status of the current nn. Through ping, once the current NN is not available, it will immediately communicate with ZK to inform the NN of zk's current active state that it is not availableYes, ZK deletes the content belonging to the previous active machine from the node, and then ZK informs other NNs of the zkfc process through the notification mechanism. Everyone is rushing to write the content again.
Cluster Planning
hadoop102 : Namenode Datanode JournalNode ZKFC ZK hadoop103 : Namenode Datanode JournalNode ZKFC ZK hadoop104 : Namenode Datanode JournalNode ZKFC ZK
Implement HA failover automatically
-
Add in the core-site.xml file
<!-- Appoint zkfc To connect zkServer address --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value> </property>
-
Increase in hdfs-site.xml
<!-- Enable nn Failover --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
-
Modified Distribution Profile
my_rsync /opt/module/ha/hadoop-3.1.3/etc/hadoop
-
Turn off HDFS cluster
stop-dfs.sh
-
Start Zookeeper Cluster
zk_cluster.sh start
-
Initialize HA status in Zookeeper
hdfs zkfc -formatZK
-
Start HDFS service
start-dfs.sh
Test Failover
Join YARN HA Cluster Planning
hadoop102 : Namenode Datanode JournalNode ZKFC ZK ResourceManager NodeManager hadoop103 : Namenode Datanode JournalNode ZKFC ZK ResourceManager NodeManager hadoop104 : Namenode Datanode JournalNode ZKFC ZK ResourceManager NodeManager
YARN HA Cluster Setup Steps
-
Modify yarn-site.xml
<!-- Enable resourcemanager ha --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- Declare Three resourcemanager Address --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <!--Appoint resourcemanager Logical list of--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2,rm3</value> </property> <!-- ========== rm1 Configuration ========== --> <!-- Appoint rm1 Host name --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop102</value> </property> <!-- Appoint rm1 Of web End Address --> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop102:8088</value> </property> <!-- Appoint rm1 Internal communication address --> <property> <name>yarn.resourcemanager.address.rm1</name> <value>hadoop102:8032</value> </property> <!-- Appoint AM towards rm1 Address of the requested resource --> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop102:8030</value> </property> <!-- Designated for NM Connected Address --> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>hadoop102:8031</value> </property> <!-- ========== rm2 Configuration ========== --> <!-- Appoint rm2 Host name --> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop103</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop103:8088</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>hadoop103:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>hadoop103:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>hadoop103:8031</value> </property> <!-- ========== rm3 Configuration ========== --> <!-- Appoint rm3 Host name --> <property> <name>yarn.resourcemanager.hostname.rm3</name> <value>hadoop104</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm3</name> <value>hadoop104:8088</value> </property> <property> <name>yarn.resourcemanager.address.rm3</name> <value>hadoop104:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm3</name> <value>hadoop104:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm3</name> <value>hadoop104:8031</value> </property> <!-- Appoint zookeeper Address of the cluster --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value> </property> <!-- Enable automatic recovery --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- Appoint resourcemanager The status information of is stored in zookeeper colony --> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property>
-
Distribute yarn-site.xml file
[atguigu@hadoop102 hadoop]$ my_rsync.sh yarn-site.xml
-
Start yarn on any machine
start-yarn.sh # Notice that the zk here is started
-
Verify by accessing a web address
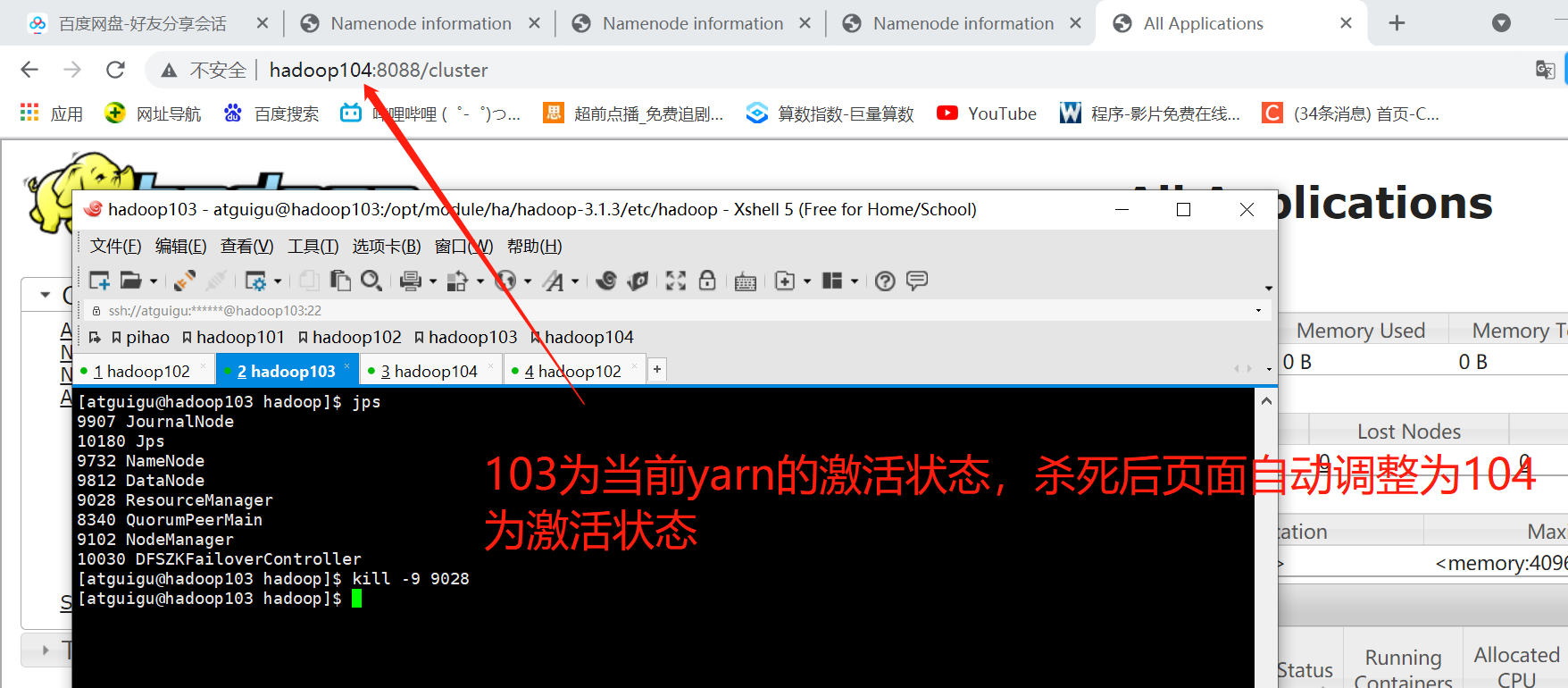
Start successfully, found that only one page at a time, other pages will automatically redirect to the Active machine
-
Test Yarn Failover Automation
ok, so far, the highly available cluster for hadoop has been set up!