Machine distribution
hadoop1 192.168.56121
hadoop2 192.168.56122
hadoop3 192.168.56123
Preparing the installation package
jdk-7u71-linux-x64.tar.gz
zookeeper-3.4.9.tar.gz
hadoop-2.9.2.tar.gz
Upload the installation package to the / usr/local directory of three machines and extract it
Configure hosts
echo "192.168.56.121 hadoop1" >> /etc/hosts echo "192.168.56.122 hadoop2" >> /etc/hosts echo "192.168.56.123 hadoop3" >> /etc/hosts
Configure environment variables
/etc/profile
export HADOOP_PREFIX=/usr/local/hadoop-2.9.2 export JAVA_HOME=/usr/local/jdk1.7.0_71
Deploy zookeeper
Create a zoo user
useradd zoo passwd zoo
Change the owner of zookeeper directory to zoo
chown zoo:zoo -R /usr/local/zookeeper-3.4.9
Modify the zookeeper configuration file
Go to the / usr/local/zookeeper-3.4.9/conf directory
cp zoo_sample.cfg zoo.cfg vi zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-3.4.9 clientPort=2181 server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888 server.3=hadoop3:2888:3888
Create the myid file and put it in the directory / usr/local/zookeeper-3.4.9. Only 1-255 numbers are saved in the myid file, which is the same as the ID in the server.id line of zoo.cfg.
myid is 1 in Hadoop 1
myid is 2 in Hadoop 2
myid is 3 in Hadoop 3
Start the zookeeper service on three machines
[zoo@hadoop1 zookeeper-3.4.9]$ bin/zkServer.sh start
Verify zookeeper
[zoo@hadoop1 zookeeper-3.4.9]$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.9/bin/../conf/zoo.cfg Mode: follower
Configure Hadoop
Create user
useradd hadoop passwd hadoop
Modify hadoop directory owner to hadoop
chmod hadoop:hadoop -R /usr/local/hadoop-2.9.2
Create directory
mkdir /hadoop1 /hadoop2 /hadoop3 chown hadoop:hadoop /hadoop1 chown hadoop:hadoop /hadoop2 chown hadoop:hadoop /hadoop3
Configure mutual trust
ssh-keygen ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop1 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop2 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop3 #Use the following command to test mutual trust ssh hadoop1 date ssh hadoop2 date ssh hadoop3 date
Configure environment variables
/home/hadoop/.bash_profile
export PATH=$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$PATH
configuration parameter
etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7.0_71
etc/hadoop/core-site.xml
<!-- Appoint hdfs Of nameservice by ns --> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <!--Appoint hadoop Temporary data storage directory--> <property> <name>hadoop.tmp.dir</name> <value>/usr/loca/hadoop-2.9.2/temp</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> <!--Appoint zookeeper address--> <property> <name>ha.zookeeper.quorum</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property>
etc/hadoop/hdfs-site.xml
<!--Appoint hdfs Of nameservice by ns,Need and core-site.xml Consistent in --> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!-- ns There are two below NameNode,Namely nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!-- nn1 Of RPC Mailing address --> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>hadoop1:9000</value> </property> <!-- nn1 Of http Mailing address --> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>hadoop1:50070</value> </property> <!-- nn2 Of RPC Mailing address --> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>hadoop2:9000</value> </property> <!-- nn2 Of http Mailing address --> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>hadoop2:50070</value> </property> <!-- Appoint NameNode The metadata of JournalNode Storage location on --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns</value> </property> <!-- Appoint JournalNode Where to store data on the local disk --> <property> <name>dfs.journalnode.edits.dir</name> <value>/hadoop1/hdfs/journal</value> </property> <!-- open NameNode Automatic switching in case of failure --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- Configuration failure auto switch implementation mode --> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- Configure the isolation mechanism if ssh Is the default 22 port, value direct writing sshfence that will do --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- When using isolation mechanism ssh No landfall --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop1/hdfs/name,file:/hadoop2/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop1/hdfs/data,file:/hadoop2/hdfs/data,file:/hadoop3/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- stay NN and DN Upper opening WebHDFS (REST API)function,Not necessary --> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <!-- List of permitted/excluded DataNodes. --> <name>dfs.hosts.exclude</name> <value>/usr/local/hadoop-2.9.2/etc/hadoop/excludes</value> </property>
etc/hadoop/mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> yarn-site.xml <!-- Appoint nodemanager Load on startup server The way is shuffle server --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- Appoint resourcemanager address --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop1</value> </property>
etc/hadoop/slaves
hadoop1 hadoop2 hadoop3
First start command
1,Start the Zookeeper,Execute the following command on each node: bin/zkServer.sh start 2,In a certain namenode The node executes the following command to create a namespace hdfs zkfc -formatZK 3,In each journalnode The node is started with the following command journalnode sbin/hadoop-daemon.sh start journalnode 4,In the main namenode Node format namenode and journalnode Catalog hdfs namenode -format ns 5,In the main namenode Node start up namenode process sbin/hadoop-daemon.sh start namenode 6,In preparation namenode The node executes the first line of command. This is the backup namenode The directory of the node is formatted and metadata is transferred from the primary namenode node copy Come here, and this order won't journalnode The directory is formatted again! Then start the standby with the second command namenode Process! hdfs namenode -bootstrapStandby sbin/hadoop-daemon.sh start namenode 7,In two namenode Nodes execute the following commands sbin/hadoop-daemon.sh start zkfc 8,In all datanode All nodes execute the following command to start datanode sbin/hadoop-daemon.sh start datanode
Daily start stop command
#Start script, start all node services sbin/start-dfs.sh #Stop script, stop all node services sbin/stop-dfs.sh Verification
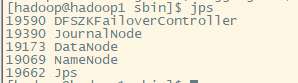
jps check process
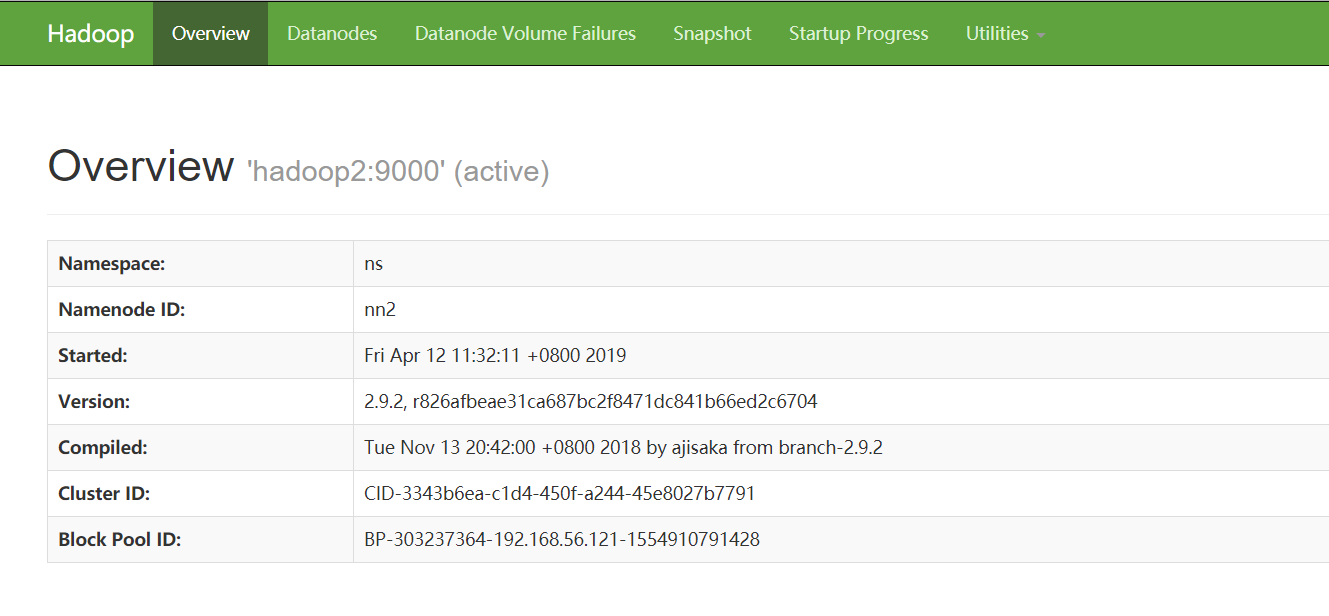
http://192.168.56.122:50070
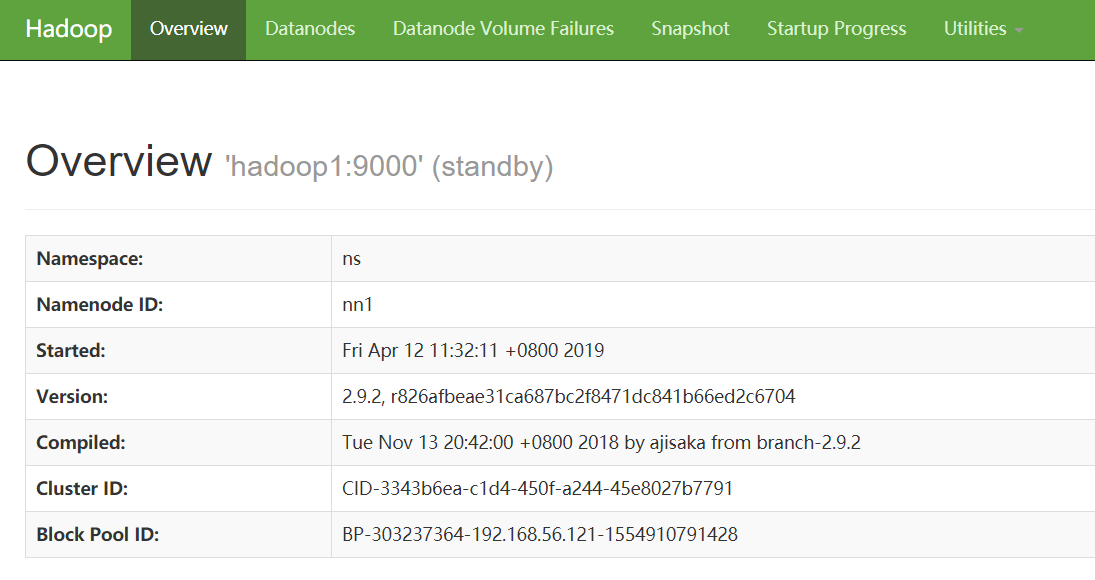
http://192.168.56.121:50070
Upload and download test files
#Create directory [hadoop@hadoop1 ~]$ hadoop fs -mkdir /test #Verification [hadoop@hadoop1 ~]$ hadoop fs -ls / Found 1 items drwxr-xr-x - hadoop supergroup 0 2019-04-12 12:16 /test #Upload files [hadoop@hadoop1 ~]$ hadoop fs -put /usr/local/hadoop-2.9.2/LICENSE.txt /test #Verification [hadoop@hadoop1 ~]$ hadoop fs -ls /test Found 1 items -rw-r--r-- 2 hadoop supergroup 106210 2019-04-12 12:17 /test/LICENSE.txt #Download files to / tmp [hadoop@hadoop1 ~]$ hadoop fs -get /test/LICENSE.txt /tmp #Verification [hadoop@hadoop1 ~]$ ls -l /tmp/LICENSE.txt -rw-r--r--. 1 hadoop hadoop 106210 Apr 12 12:19 /tmp/LICENSE.txt
Reference resources: https://blog.csdn.net/Trigl/article/details/55101826