Common hadoop cluster
- namenode(nn)
- secondarynamenode(2nn)
- datanode(dn)
The problems of common hadoop cluster
- Is there a single point of failure with datanode?
- No, because datanode has multiple machines and a copy mechanism as guarantee
- Is there a single point of failure with the namenode?
- Yes, because 2nn can't replace NN. The function of 2nn is only to fuse fsimage and edit files, so NN has a single point of failure
- How to solve the problem of single point failure of namenode
- Multiple namenode (realizing high availability of namenode)
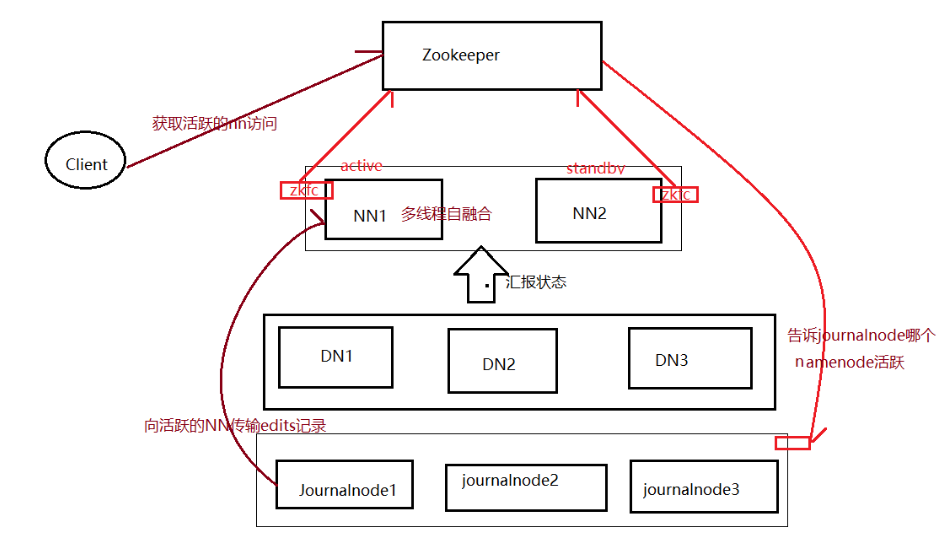
High availability cluster (HA) of hadoop
1 planning of cluster
namenode: mini01 mini02 resourcemanager: mini01 mini02 datanode: mini03 mini04 mini05 journalnode:mini03 mini04 mini05 zookeeper: mini03 mini04 mini05 nodemanager:mini03 mini04 mini05
2 profile
The following is a brand new cluster. If the original cluster needs to be deleted, / opt / Hadoop / opt / Hadoop repo, the following operations are all performed on mini01
export JAVA_HOME=/opt/jdk
export JAVA_HOME=/opt/jdk
export JAVA_HOME=/opt/jdk
- Core-site.xml (core configuration)
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- Appoint hdfs Of nameservice by ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <!-- Appoint hadoop Temporary directory --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-repo/tmp</value> </property> <!-- Appoint zookeeper address --> <property> <name>ha.zookeeper.quorum</name> <value>mini03:2181,mini04:2181,mini05:2181</value> </property> </configuration>
- Hdfs-site.xml (file system configuration)
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--Appoint hdfs Of nameservice by ns1,Need and core-site.xml Consistent in -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1 There are two below NameNode,Namely nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 Of RPC Mailing address -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>mini01:8020</value>
</property>
<!-- nn1 Of http Mailing address -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>mini01:50070</value>
</property>
<!-- nn2 Of RPC Mailing address -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>mini02:8020</value>
</property>
<!-- nn2 Of http Mailing address -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>mini02:50070</value>
</property>
<!-- Appoint NameNode Of edits Data in JournalNode Storage location on -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://mini03:8485;mini04:8485;mini05:8485/ns1</value>
</property>
<!-- Appoint JournalNode Where to store data on the local disk -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-repo/journal</value>
</property>
<!-- Appoint NameNode Where to store data on the local disk -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-repo/name</value>
</property>
<!-- Appoint DataNode Where to store data on the local disk -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-repo/data</value>
</property>
<!-- open NameNode Fail auto switch -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- Configuration failure auto switch implementation mode -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- Configure the isolation mechanism method. Multiple mechanisms are separated by line breaking, that is, each mechanism temporarily uses one line-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- Use sshfence Isolation mechanism ssh No landfall -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- To configure sshfence Isolation mechanism timeout -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- Number of data backups-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- Remove authority control-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
- mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- History job Access address for--> <property> <name>mapreduce.jobhistory.address</name> <value>mini02:10020</value> </property> <!-- History job Visit web address--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>mini02:19888</value> </property> <!-- Will be in hdfs Create a history Folder to store the related operation of historical tasks--> <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/history</value> </property> <!-- map and reduce Log level for--> <property> <name>mapreduce.map.log.level</name> <value>INFO</value> </property> <property> <name>mapreduce.reduce.log.level</name> <value>INFO</value> </property> </configuration>
- yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- open RM High reliability -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- Appoint RM Of cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- Appoint RM Name -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- Assign separately RM Address -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>mini01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>mini02</value>
</property>
<!-- Appoint zk Cluster address -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>mini03:2181,mini04:2181,mini05:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- slaves (about dn)
mini03 mini04 mini05
3 configure environment variables
export HADOOP_HOME=/opt/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- If there is a file system that needs to be deleted first
rm -rf /opt/hadoop-repo/ rm -rf /opt/hadoop //Leave hadoop on one machine
4 distribute hadoop
[root@mini01]: scp -r /opt/hadoop mini02:/opt/ scp -r /opt/hadoop mini03:/opt/ scp -r /opt/hadoop mini04:/opt/ scp -r /opt/hadoop mini05:/opt/
5 start ZooKeeper cluster
[root@mini03]: zkServer.sh start [root@mini04]: zkServer.sh start [root@mini05]: zkServer.sh start
6 start the journal node cluster
[root@mini03]: hadoop-daemon.sh start journalnode [root@mini04]: hadoop-daemon.sh start journalnode [root@mini05]: hadoop-daemon.sh start journalnode
7 format file system
Select a machine configured with namenode to format the file system
[root@mini01]: hdfs namenode -format
8 distribute file system meta information to other namenode
[root@mini01]: scp -r hadoop-repo/ mini02:/opt/
9 format zkfc
Format zkfc on any machine of namenode
[root@mini01]: hdfs zkfc -formatZK
10 start cluster
start-all.sh
11 yarn's bug
When start-all.sh is executed, yarn on mini02 will not be started automatically, but will be started manually
[root@mini02]: yarn-daemon.sh start resourcemanager yarn-daemon.sh stop resourcemanager(Close)
12 process of cluster
mini01,mini02:
NameNode
DFSZKFailoverController
ResourceManager
mini03,mini04,mini05:
DataNode
JournalNode
QuorumPeerMain
NodeManager
13 verify installation
http://mini01:50070 http://mini02:50070 http://mini01:8088 http://mini02:8088
Start zkfc

HA cluster description