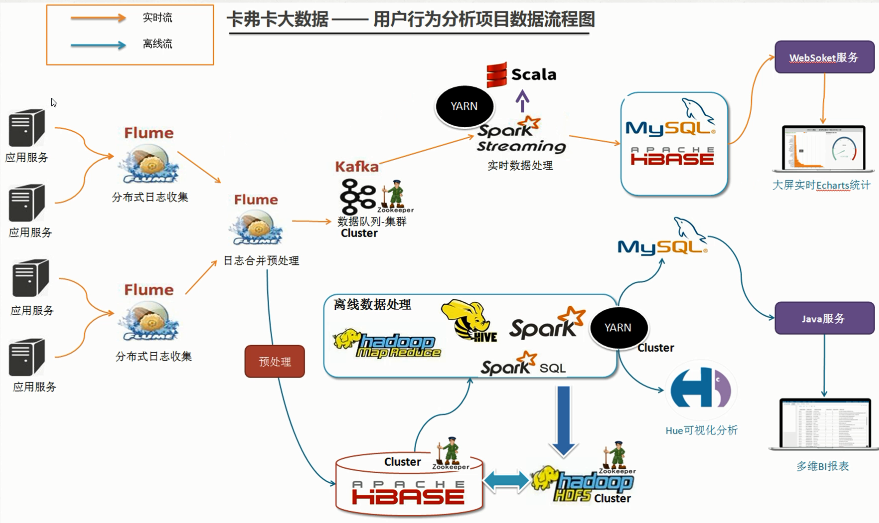
Flume is a highly available, reliable and distributed system for collecting, aggregating and transferring massive logs provided by Cloudera. Flume supports customizing various data senders in the log system for collecting data. At the same time, Flume provides the ability to process data simply and write to various data recipients (customizable).
1.flume Node Service Design
2. Download Flume and install it
1) Download Apache Version of Flume.
2) Download Cloudera Version of Flume.
3) Here, download apache-flume-1.7.0-bin.tar.gz and upload it to bigdata-pro01.kfk.com node/opt/softwares/directory.
4) Decompression Flume
[kfk@bigdata-pro01 softwares]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C ../modules/ [kfk@bigdata-pro01 softwares]$ cd ../modules/ [kfk@bigdata-pro01 modules]$ ls apache-flume-1.7.0-bin hadoop-2.6.0 hbase-0.98.6-cdh5.3.0 jdk1.8.0_60 kafka_2.11-0.8.2.1 zookeeper-3.4.5-cdh5.10.0 [kfk@bigdata-pro01 modules]$ mv apache-flume-1.7.0-bin/ flume-1.7.0-bin/
5) Distributing flume to two other nodes
scp -r flume-1.7.0-bin bigdata-pro02.kfk.com:/opt/modules/ scp -r flume-1.7.0-bin bigdata-pro03.kfk.com:/opt/modules/
3. Service Configuration of Flume Agent-1 Acquisition Node
1) bigdata-pro02.kfk.com node configures flume to collect data to bigdata-pro01.kfk.com node
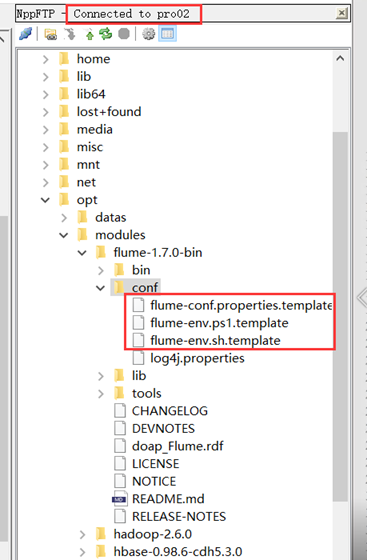
Create a new connection from notepad++ to the second node, then rename all files under conf and remove the. template suffix.
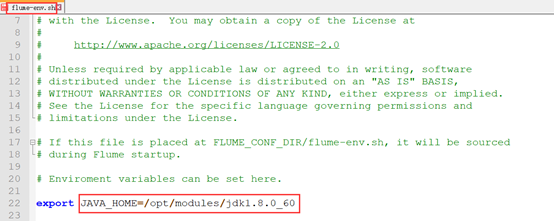
Configure Java environment variables first:
Then configure the flume-conf.properties file, focusing on the source, channel and sink threads in the above flowchart.
Due to the incomplete configuration of the templates and the confused format, all of them were eliminated and then filled in the following contents.
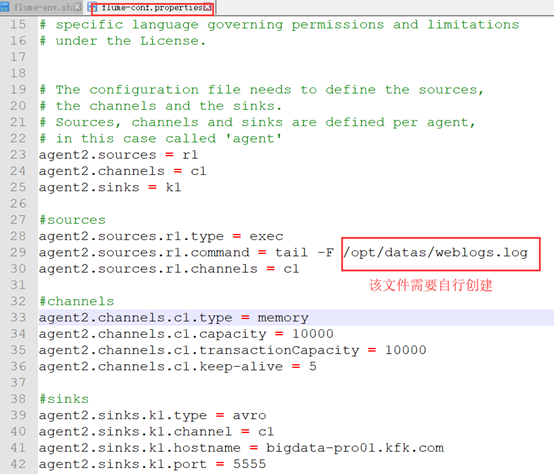
agent2.sources = r1 agent2.channels = c1 agent2.sinks = k1 agent2.sources.r1.type = exec agent2.sources.r1.command = tail -F /opt/datas/weblogs.log agent2.sources.r1.channels = c1 agent2.channels.c1.type = memory agent2.channels.c1.capacity = 10000 agent2.channels.c1.transactionCapacity = 10000 agent2.channels.c1.keep-alive = 5 agent2.sinks.k1.type = avro agent2.sinks.k1.channel = c1 agent2.sinks.k1.hostname = bigdata-pro01.kfk.com agent2.sinks.k1.port = 5555
Nodes 2 and 3 are responsible for collecting the logs of application servers. The source using them is exec (standard output of command line), which is then pushed to machine 1 through sink (avro type) for log merging. As shown in the red box below:
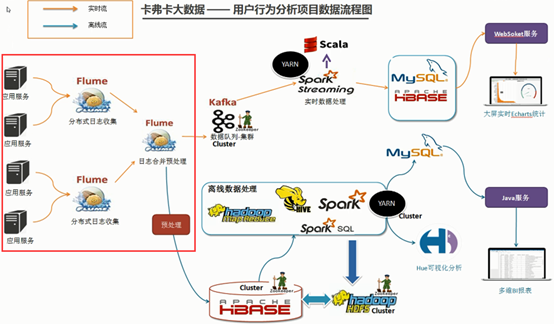
Flume's official website Configuration explanation Also very comprehensive, you can read the following, and learn to customize the configuration according to the official website guide.
2) Send the above configuration to Node 3.
scp -r flume-1.7.0-bin/ bigdata-pro03.kfk.com:/opt/modules/
Then the agent 2 in the configuration file is changed to agent 3 to realize the function of collecting data to bigdata-pro01.kfk.com node.
Remember to create weblogs files!
[kfk@bigdata-pro03 ~]$ cd /opt/datas/ [kfk@bigdata-pro03 datas]$ touch weblogs.log [kfk@bigdata-pro03 datas]$ ls weblogs.log
Above is the main content of the blogger's introduction to you. This is the blogger's own learning process. I hope it can give you some guidance. I also hope you can give us some support. If it's not useful for you, please point out the mistakes. If you have any expectations, you can pay attention to the bloggers to get updates as soon as possible. Thank you. At the same time, you are welcome to reprint, but you must mark the original address at the prominent position of Bo Civilization, and the right of interpretation belongs to the owner of the blog!