Catalog
5: The difference with sparkStreaming
7: Flink configuration description
1: Introduction
Flink is a framework and distributed computing engine for state computation of unbounded and bounded data flows
2: Why Flink
Streaming data more realistically reflects our lifestyle
Traditional data architecture is based on limited data set
Low latency, high throughput, accuracy of results and good fault tolerance
3: What industries need
E-commerce and marketing: data reporting, advertising, business process needs
Internet of things: sensor real-time data acquisition and display, real-time alarm, transportation industry
Telecommunication industry: base station traffic allocation
Banking and Finance: real time settlement and notification push, real-time monitoring of abnormal behavior
4: Features of Flink
event driven
Flow based world view (a batch of data is considered as bounded flow)
Provides a layered API
Support and handle event events
Guarantee of state consistency of exact once
Low latency
Can be connected to many common storage systems
High availability, dynamic expansion
5: The difference with sparkStreaming
1. Flink is a real stream calculation, while SparkStreaming divides data into batches of data, so Flink needs to be fast with low latency
2. The data model is different. Spark adopts RDD model. In fact, spark streaming DStream is a collection of a group of small batch of RDD data. Flink is based on the data model of flow data and event sequence
3. The architecture of runtime is different. spark is batch computing. You can calculate the next Flink only after you divide DAG into different stage s. The next Flink is the standard flow execution mode. An event can be sent directly to the next node for processing after one node finishes processing
6: Preliminary development
Add dependency:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>1.7.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.7.2</version> </dependency>
The batch processing code using Flink is as follows:
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val inputPath = "C:\\hnn\\Project\\Self\\spark\\in\\hello.txt"
//Read file contents
val inputDateSet: DataSet[String] = env.readTextFile(inputPath)
val words = inputDateSet.flatMap(_.split(" "))
.map((_, 1))
.groupBy(0)
.sum(1)
words.print()The code of using Flink for stream processing is as follows: (you need to start the nc (netCat) service locally to simulate the generation of data stream)
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//Receive a sock text stream
val dataStream: DataStream[String] = env.socketTextStream("localhost", 44444)
val result: DataStream[(String, Int)] = dataStream.flatMap(_.split(" "))
.filter(_.contains("a")) //Filter all words with a
.map((_, 1)) //Recombinant map
.keyBy(0) // Equivalent to groupBy
.sum(1)
result.print()
env.execute()7: Flink configuration description
#jobmanager ip address jobmanager.rpc.address: localhost # jobmanager port number jobmanager.rpc.port: 6123 # JobManager JVM heap size jobmanager.heap.size: 1024m # TaskManager JVM heap size taskmanager.heap.size: 1024m # Number of task slots provided by each task manager taskmanager.numberOfTaskSlots: 1 # Actual parallelism parallelism.default: 1
Eight: Environment
(1) Download Flink note that the version of scala you download should be consistent with your code
(2) Start Flink: start-cluster.bat
(3) Call Flink's web page: the default is localhost:8081
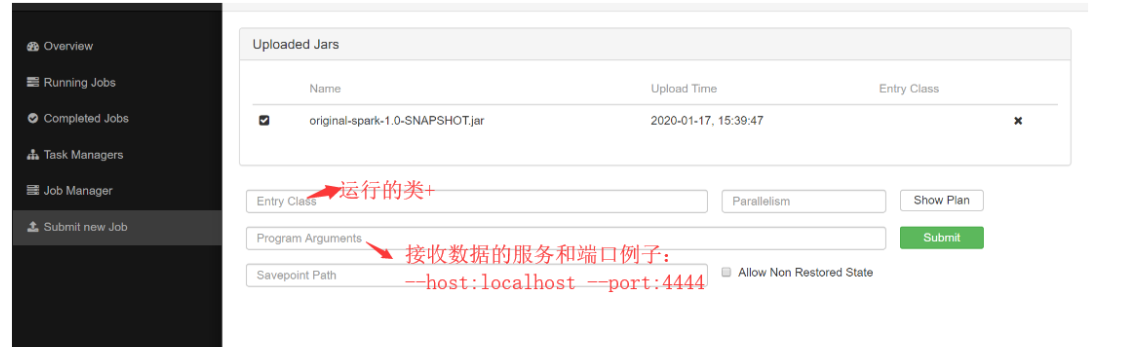
(4) Prepare netcat startup command: nc -L -p 44444
(5) Package project, upload jar, add configuration, submit sumit task
9: Running components
jobManage
Job manager, receiving the application to execute (the process of job submission) is a process
taskManage
Task manager, also a process, has one or more slots. Each taskmanager contains a certain number of slots. The number of slots limits the number of tasks that can be performed by taskmanager. After startup, taskmanager will register its slots with the resource manager. After receiving the instructions from the resource manager, taskmanager will provide one or more slots to the job manager for calling , jobmanage will assign tasks to the slots to perform
resourceManage
Resource manager, which manages slots
dispatcher
Dispenser

