Introduction to ThreadPool Executor
stay J.U.C. Excutors Framework: Excutors Framework Design Concept ThreadPool Executor has been briefly introduced in this chapter. Through the Executors factory, users can create the executor objects they need. ThreadPool Executor is an executor, or thread pool, that implements the ExecutorService interface provided by J.U.C. in JDK 1.5.
public class ThreadPoolExecutor extends AbstractExecutorService {
ThreadPoolExecutor does not directly implement the ExecutorService interface itself, because it is only one of the Executor implementations, so Doug Lea encapsulates some common parts into an abstract parent class, AbstractExecutorService, for inheritance by other implementers in J.U.C. If the reader needs to implement an Executor himself, he can also inherit the abstract class.
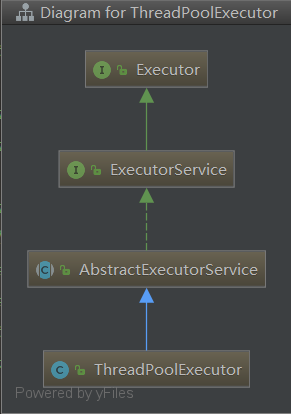
AbstractExecutorService
AbstractExecutorService provides the default implementation of ExecutorService interface, which mainly implements submit, invokeAny and invokeAll.
If the reader has read the last review article, you should know that these three methods of ExecutorService almost all return a Future object. Future is an interface. Since AbstractExecutorService implements these methods, it is necessary to implement the Future interface. Let's look at the submit method implemented by AbstractExecutorService:
public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; }
As you can see, the above methods first encapsulate Runnable and return value, then encapsulate a FutureTask object through the newTaskFor method, and then execute the task through the execute method, and finally return the asynchronous task object.
Note that the newTaskFor method creates a Future object:
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) { return new FutureTask<T>(runnable, value); }
FutureTask is actually the implementation class of FutureInterface: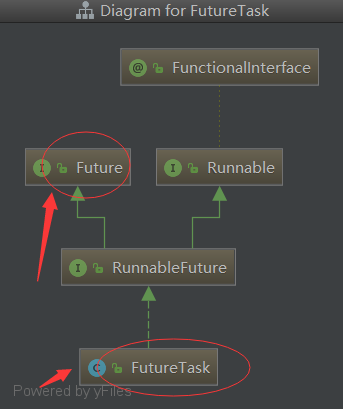
This section won't spend too much ink on Future mode. We'll talk about J.U.C's support for Future mode in the future.
Introduction to Thread Pool
Returning to ThreadPool Executor, you can see from the naming of this class that it is a thread pool executor. Thread pool is not unfamiliar to everyone. Database connection pool is often used in application development. Some database connections are maintained in database connection pool. When an application needs to connect to a database, it is not to create a connection by itself, but to get available connections from the connection pool; when the database connection is closed, it is only to connect the database. Return to connection pool for reuse.
Thread pool is a similar concept. When a task needs to be executed, the thread pool will assign threads to the task. If there are no available threads at present, the task will generally be put into a queue. When there are threads available, the task will be removed from the queue and executed. The following figure shows:
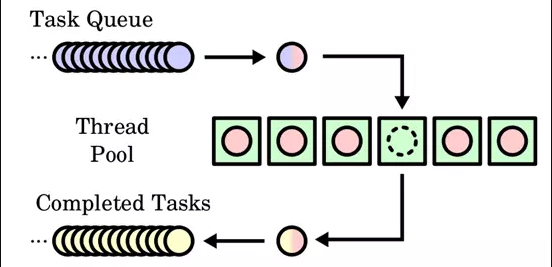
The introduction of thread pool mainly solves the following problems:
- Reduce system overhead due to frequent creation and destruction of threads;
- Automatically manage threads, transparent to users, so that they can focus on task building.
II. Basic Principles of ThreadPool Executor
Understanding the inheritance system of thread pool and ThreadPool Executor, let's look at how J.U.C implements a common thread pool.
Constructing thread pools
Let's first look at the constructor of ThreadPool Executor, which we've touched on before when we talked about Executors. The three thread pools created by the Executors factory method are new Fixed ThreadPool, new Single ThreadExecutor, and new Cached ThreadPool, all internally instantiated through the constructor below ThreadPool Executor. OlExecutor object:
/** * Create ThreadPoolExecutor with the given parameters. * * @param corePoolSize Maximum number of threads in the core thread pool * @param maximumPoolSize Maximum number of threads in bus process pool * @param keepAliveTime Survival time of idle threads * @param unit keepAliveTime Units * @param workQueue Task queue to save threads that have been submitted but not yet executed * @param threadFactory Thread factory (used to specify if a thread is created) * @param handler Rejection policy (when too many tasks lead to a full work queue) */ public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); // Save survival time in nanoseconds this.threadFactory = threadFactory; this.handler = handler; }
It is through the combination transformation of the above parameters that Executors factory can create different types of thread pools. Here, we will briefly talk about two parameters: core Pool Size and maximum Pool Size.
ThreadPool Executor logically divides its own managed thread pool into two parts: core thread pool (size corresponds to core Pool Size) and non-core thread pool (size corresponds to maximum Pool Size-core Pool Size).
When we submit a task to the thread pool, we will create a worker thread, which is called Worker. The worker logically belongs to the core thread pool or the non-core thread pool in the following figure. Which one belongs to, according to the total number of corePoolSize, maximumPoolSize and Worker?
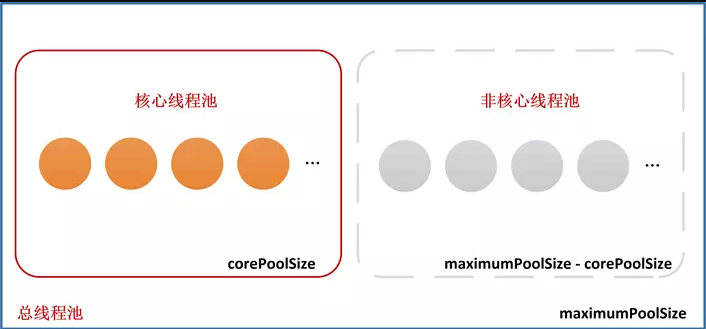
Note: We've been talking about workthreads, [core thread pools] and [non-core thread pools] all the time, and readers may be stunned, including when I first learned ThreadPool Executor, I was misled by the wrong descriptions of online and junk domestic technology books. Let me mention it first, and then we will elaborate on it when we analyze the task scheduling process of thread pool.
- There is only one type of thread in ThreadPoolExecutor, called Worker, which is an internal class defined by ThreadPoolExecutor and encapsulates the Runnable task and the Thread object that executes the task. We call it "worker thread". It is also the only thread that ThreadPoolExecutor needs to maintain.
- Core thread pool [non-core thread pool] is a logical concept. ThreadPool Executor decides how to schedule tasks according to the size of core Pool Size and maximum Pool Size in the process of task scheduling.
Thread pool status and thread management
At this point, the reader may think about a question: since it is a thread pool, there must be a thread pool state, but also involves the management of the Worker among them. How does ThreadPool Executor do?
ThreadPool Executor defines an Atomic Integer variable, ctl, which records the state of thread pool and the number of worker threads in a variable by bit partitioning. The number of saved threads is 29 bits lower and the state of thread pool is 3 bits higher.
/** * Save thread pool status and number of worker threads: * Low 29 bits: number of worker threads * High 3 bits: thread pool status */ private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3; // Maximum number of threads: 2 ^ 29-1 private static final int CAPACITY = (1 << COUNT_BITS) - 1; // 00011111 11111111 11111111 11111111 // Thread pool status private static final int RUNNING = -1 << COUNT_BITS; // 11100000 00000000 00000000 00000000 private static final int SHUTDOWN = 0 << COUNT_BITS; // 00000000 00000000 00000000 00000000 private static final int STOP = 1 << COUNT_BITS; // 00100000 00000000 00000000 00000000 private static final int TIDYING = 2 << COUNT_BITS; // 01000000 00000000 00000000 00000000 private static final int TERMINATED = 3 << COUNT_BITS; // 01100000 00000000 00000000 00000000
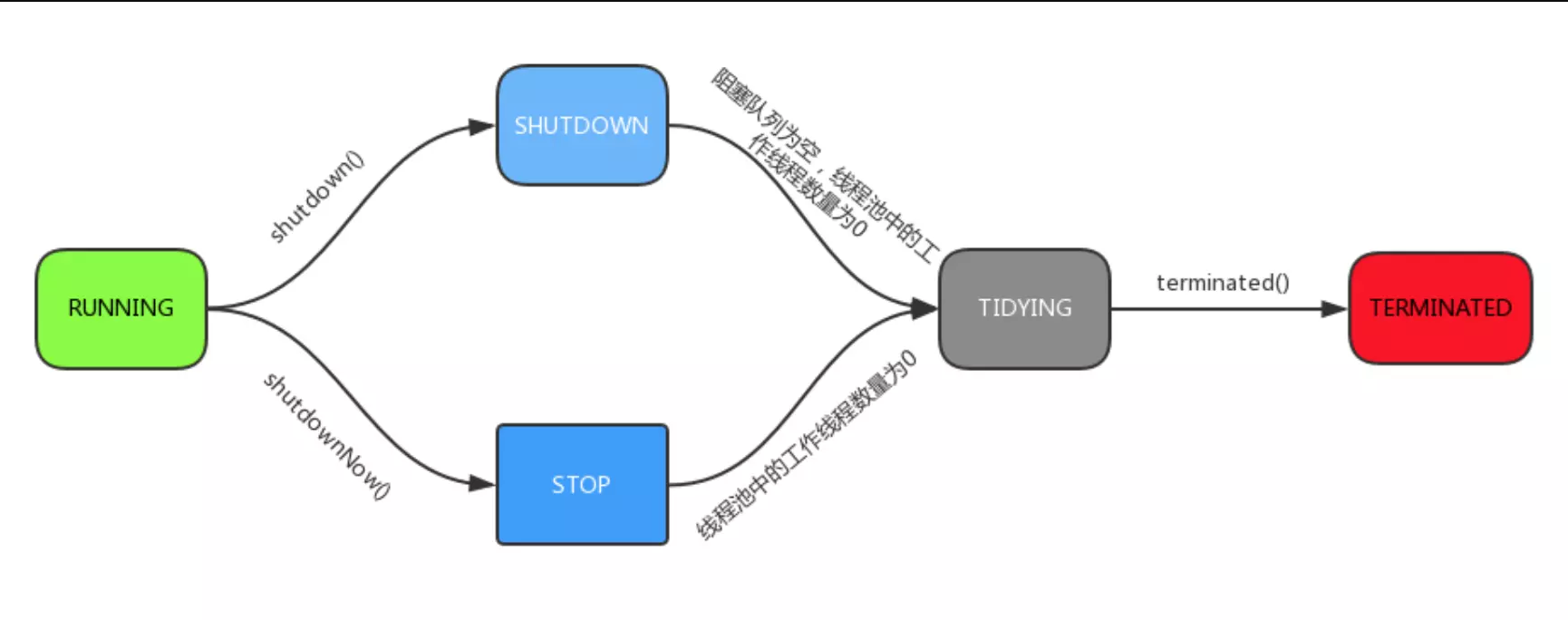
As you can see, ThreadPool Executor defines a total of five thread pool states:
- RUNNING: Accepts new tasks and processes tasks that have entered the blocking queue
- SHUTDOWN: Do not accept new tasks, but handle tasks that have entered the blocking queue
- STOP: Do not accept new tasks, and do not handle tasks that have entered the blocking queue, while interrupting running tasks
- TIDYING: All tasks have been terminated, the number of worker threads is 0, the threads are converted to TIDYING status and ready to call terminated method
- TERMINATED: The terminated method has been executed
Flow charts between states:
In addition, we mentioned worker just now. Worker is defined as the inner class of ThreadPoolExecutor, which implements the AQS framework. ThreadPoolExecutor saves worker threads through a HashSet:
/** * Collection of worker threads. */ private final HashSet<Worker> workers = new HashSet<Worker>();
Work threads are defined as follows:
/** * Worker Represents a worker thread in a thread pool that can be associated with a task. * Since the AQS framework is implemented, the synchronization state values are defined as follows: * -1: Initial state * 0: Unlocked state * 1: Locking status */ private final class Worker extends AbstractQueuedSynchronizer implements Runnable { /** * Threads associated with the Worker. */ final Thread thread; /** * Initial task to run. Possibly null. */ Runnable firstTask; /** * Per-thread task counter */ volatile long completedTasks; Worker(Runnable firstTask) { setState(-1); // Initial Synchronization State Value this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); } /** * Execution of tasks */ public void run() { runWorker(this); } /** * Whether to lock or not */ protected boolean isHeldExclusively() { return getState() != 0; } /** * Attempt to acquire locks */ protected boolean tryAcquire(int unused) { if (compareAndSetState(0, 1)) { setExclusiveOwnerThread(Thread.currentThread()); return true; } return false; } /** * Trying to release the lock */ protected boolean tryRelease(int unused) { setExclusiveOwnerThread(null); setState(0); return true; } public void lock() { acquire(1); } public boolean tryLock() { return tryAcquire(1); } public void unlock() { release(1); } public boolean isLocked() { return isHeldExclusively(); } /** * Interrupt threads (tasks are not initial only) */ void interruptIfStarted() { Thread t; if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) { try { t.interrupt(); } catch (SecurityException ignore) { } } } }
As you can see from the definition of Worker, each Worker object has a Thread thread object corresponding to it. When a task needs to be executed, it actually calls the start method of the internal Thread object, which is created in the Worker constructor by the getThreadFactory().newThread(this) method. D takes Worker itself as a task, so when we call the start method of Thread, we actually call the Worker.run() method, which delegates tasks to the runWorker method internally. This method will be described in detail later.
Thread Factory
ThreadFactory is used to create a single thread. When a thread pool needs to create a thread, it calls the new Thread (Runnable) method of this class to create a thread (the actual time to create a thread in ThreadPool Executor is when the task is wrapped as a worker thread Worker).
ThreadPoolExecutor creates a ThreadFactory, Executors.DefaultThreadFactory, by default, using Executors.defaultThreadFactory(), if the user does not specify the ThreadFactory at construction time:
public static ThreadFactory defaultThreadFactory() { return new DefaultThreadFactory(); } /** * Default thread factory. */ static class DefaultThreadFactory implements ThreadFactory { private static final AtomicInteger poolNumber = new AtomicInteger(1); private final ThreadGroup group; private final AtomicInteger threadNumber = new AtomicInteger(1); private final String namePrefix; DefaultThreadFactory() { SecurityManager s = System.getSecurityManager(); group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup(); namePrefix = "pool-" + poolNumber.getAndIncrement() + "-thread-"; } public Thread newThread(Runnable r) { Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0); if (t.isDaemon()) t.setDaemon(false); if (t.getPriority() != Thread.NORM_PRIORITY) t.setPriority(Thread.NORM_PRIORITY); return t; } }
3. Scheduling process of thread pool
The core method of ExecutorService is submit method, which is used to submit a task to be executed. If the reader reads the source code of ThreadPoolExecutor, he will find that it does not override the submit method, but follows the template of the parent AbstractExecutorService, and then implements the execute method himself:
public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; }
ThreadPoolExecutor's execute method is defined as follows:
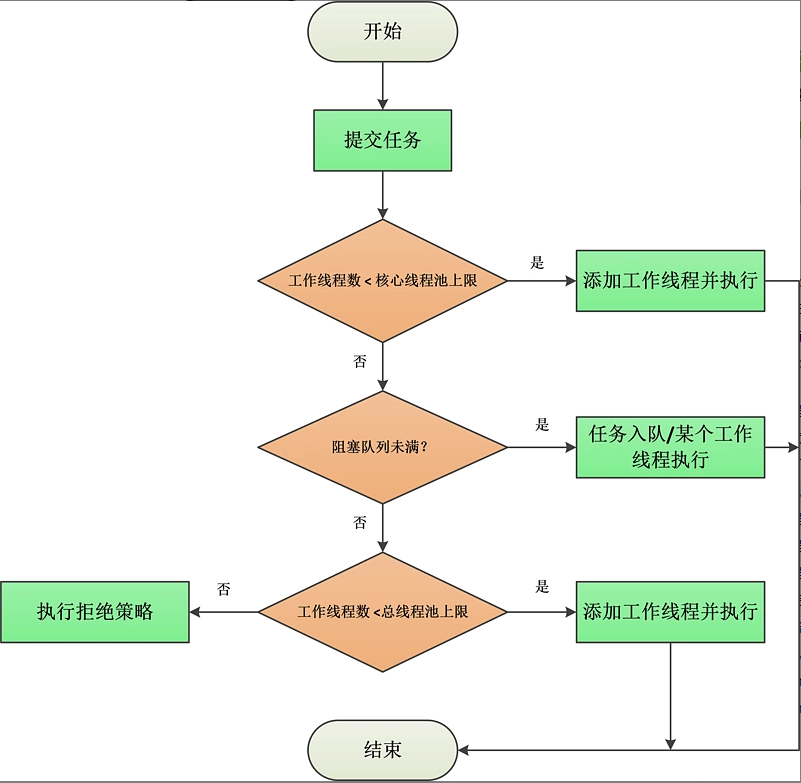
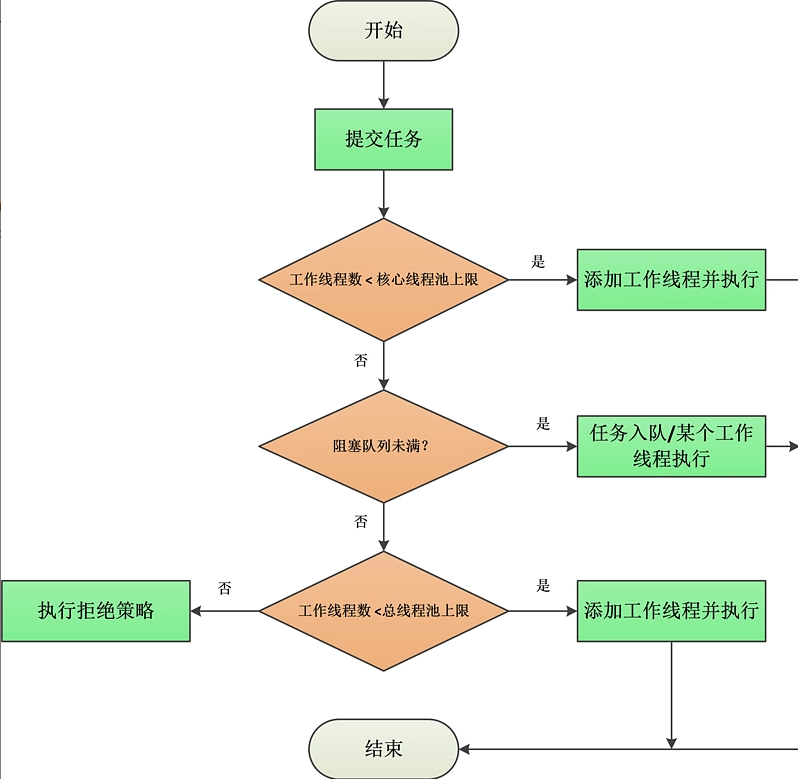
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { // CASE1: Number of Work Threads < Core Thread Pool Upper Limit if (addWorker(command, true)) // Add worker threads and execute return; c = ctl.get(); } // Execution to this point indicates that a worker thread failed to create or that the number of worker threads is greater than or equal to the upper limit of the core thread pool if (isRunning(c) && workQueue.offer(command)) { // CASE2: Insert Tasks into Queues // Check thread pool status again int recheck = ctl.get(); if (!isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) // CASE3: Insert Queue Failure, Judge Work Thread Number < Bus Process Pool Upper Limit reject(command); // Execution of rejection strategy }
The execution process of execute described above can be described in the following figure:
Special attention should be paid here to addWorker(null, false) in CASE2, which executes when the task is successfully added to the queue if the number of worker threads at this time is 0.
Therefore, in CASE2 of execute method, after adding tasks to the queue, it is necessary to determine whether the number of worker threads is 0 or not. If it is 0, then a new empty task worker thread must be created. At some time in the future, it will go to the queue to fetch tasks to execute, otherwise, the tasks in the queue will never be executed without worker threads.
In addition, we should go back to the concepts of worker thread, core thread pool, non-core thread pool and bus process pool.
The key to execute's whole execution process is the following two points:
- If the number of worker threads is less than the upper limit of the core thread pool (CorePool Size), a new worker thread is created directly and the task is executed.
- If the number of worker threads is greater than or equal to CorePoolSize, try to queue tasks for later execution. If the join queue fails (e.g. when the queue is full), a new worker thread will execute the task immediately when the bus process pool is not full (CorePoolSize < Maximum PoolSize < number of worker threads), otherwise the rejection policy will be executed.
Creation of Work Threads
Knowing the whole execution process of ThreadPoolExecutor, let's see how it adds workthreads and executes tasks. The addWorker method is called inside the execute method to add workthreads and execute tasks:
/** * Add worker threads and perform tasks * * @param firstTask If this parameter is specified, it means that a new worker thread will be created immediately to execute the first Task task; otherwise, existing worker threads will be reused to retrieve tasks from the workqueue and execute them. * @param core Which thread pool does the worker thread perform the task belong to: true-core thread pool false-non-core thread pool */ private boolean addWorker(Runnable firstTask, boolean core) { retry: for (; ; ) { int c = ctl.get(); int rs = runStateOf(c); // Get thread pool status /** * This if is mainly to determine which situations the thread pool will no longer accept new tasks to execute, but return directly. In summary, there are the following situations: * 1. Thread pool status is STOP or TIDYING or TERMINATED: When the thread pool status is either of the above, it will no longer accept tasks, so it returns directly. * 2. Thread pool status (> SHUTDOWN and first Task!= null: Because when thread pool status (> SHUTDOWN), new task submission is no longer accepted, so it returns directly. * 3. Thread pool status (> SHUTDOWN) and queue empty: there are no tasks in the queue, so there is no need to perform any tasks, you can return directly */ if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty())) return false; for (; ; ) { int wc = workerCountOf(c); // Get the number of worker threads /** * This if is mainly used to determine whether the number of worker threads exceeds the limit. Any of the following cases belongs to the limit and returns directly: * 1. The number of worker threads exceeds the maximum number of worker threads (2 ^ 29-1) * 2. The number of worker threads exceeds the upper limit of the core thread pool. * 3. The number of worker threads exceeds the upper limit of bus process pool (incorporation core is false, indicating belonging to non-core thread pool) */ if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) // Work threads plus 1 break retry; // Jump out of the outermost cycle c = ctl.get(); if (runStateOf(c) != rs) // Thread pool status changes, re-spin judgment continue retry; } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { w = new Worker(firstTask); // Wrap tasks into worker threads final Thread t = w.thread; if (t != null) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Re-check thread pool status int rs = runStateOf(ctl.get()); if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) throw new IllegalThreadStateException(); workers.add(w); // Join the worker thread set int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true; } } } finally { if (!workerStarted) // Creating/starting a worker thread failed, requiring a rollback operation addWorkerFailed(w); } return workerStarted; }
The logic of the whole addWorker is not complicated, and it is divided into two parts:
The first part is a spin operation, which mainly judges the state of the thread pool. If the state is not suitable for accepting new tasks, or the number of worker threads exceeds the limit, it returns false directly.
After filtering in the first part, the second part really creates workthreads and executes tasks:
First, the Runnable task is wrapped into a Worker object, then added to a set of worker threads (HashSet named workers). Finally, the start method of the Thread object in the worker thread is invoked to execute the task. In fact, the following method is delegated to the Worker to execute the task:
/** * Execution of tasks */ public void run() { runWorker(this); }
Execution of Work Threads
runWoker is used to perform tasks. The overall process is as follows:
- The while loop continuously retrieves tasks from the queue through the getTask() method (if the worker thread carries the task itself, it executes the carried task);
- Controls the interrupt state of the execution thread to ensure that if the thread pool is stopping, the thread must be interrupt state, otherwise the thread must not be interrupt state;
- Call task.run() to execute the task;
- Handles the exit of the worker thread.
final void runWorker(Worker w) { Thread wt = Thread.currentThread(); // Threads to execute tasks Runnable task = w.firstTask; // Tasks, if null, retrieve tasks from the queue w.firstTask = null; w.unlock(); // Allow execution threads to be interrupted boolean completedAbruptly = true; // Indicates whether exit is caused by interruption try { while (task != null || (task = getTask()) != null) { // When task==null, tasks are fetched from the queue through getTask w.lock(); /** * The function of the if judgment is as follows: * 1.Ensure that when the thread pool state is STOP/TIDYING/TERMINATED, the current thread wt executing the task is interrupted (because the thread pool can no longer perform new tasks when it is in any of the above states) * 2.Ensure that when the thread pool state is RUNNING/SHUTDOWN, the current thread wt executing the task is not an interrupt state */ if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); // Hook method, implemented by subclass customization Throwable thrown = null; try { task.run(); // Execution of tasks } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { afterExecute(task, thrown); // Hook method, implemented by subclass customization } } finally { task = null; w.completedTasks++; // Number of tasks completed + 1 w.unlock(); } } // Execution to this point indicates that the worker thread itself neither carries nor retrieves tasks from the task queue. completedAbruptly = false; } finally { processWorkerExit(w, completedAbruptly); // Handling the exit of a worker thread } }
Here we should pay special attention to the first IF method. The core function of this method is to sum up in one sentence.
In addition, the getTask method is used to retrieve a task from the task queue. If the task is not retrieved, it will jump out of the while loop and eventually clean up the worker threads through the processWorkerExit method. Notice the completedAbruptly field here, which indicates whether the worker thread exits because of interruption. There are several possibilities for the exit of the while loop:
- Normally, worker threads will survive and constantly retrieve task execution from task queue. If the task is not retrieved (getTask returns null), completedAbruptly will be set as false, and then perform cleanup work - processWorkerExit(worker,false);
- In exceptional cases, worker threads are interrupted or other exceptions occur in the execution process. completedAbruptly is set to true, and cleanup work is also performed - processWorkerExit(worker,true).
Cleaning of Work Threads
From the above discussion, we know that worker threads are cleaned up in process WorkerExit. Let's define:
private void processWorkerExit(Worker w, boolean completedAbruptly) { if (completedAbruptly) // Workthread exits due to abnormal conditions decrementWorkerCount(); // Reduce the number of worker threads by 1 (if no exception occurs during the execution of the worker threads, the number of threads has been reduced by 1 in the getTask() method) final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { completedTaskCount += w.completedTasks; // completedTaskCount records the total number of tasks completed by the thread pool workers.remove(w); // Remove from the collection of worker threads (which are automatically reclaimed by GC) } finally { mainLock.unlock(); } tryTerminate(); // Determine whether the thread pool needs to be terminated based on the state of the thread pool int c = ctl.get(); if (runStateLessThan(c, STOP)) { // If the thread pool status is RUNNING/SHUTDOWN if (!completedAbruptly) { // Work threads exit normally int min = allowCoreThreadTimeOut ? 0 : corePoolSize; if (min == 0 && !workQueue.isEmpty()) min = 1; if (workerCountOf(c) >= min) return; // replacement not needed } addWorker(null, false); // Create a new worker thread } }
The function of processWorkerExit is to clean up the exited worker thread and see if the thread pool needs to terminate.
After the process WorkerExit is executed, the life cycle of the entire worker thread is also over. We can review the whole life cycle of the worker thread through the following figure:
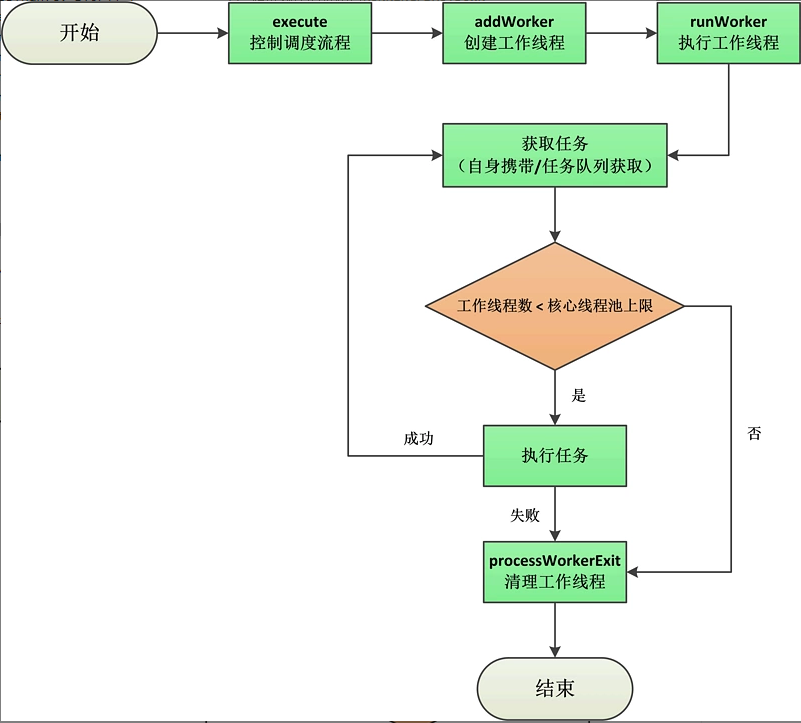
Task Acquisition
Finally, let's look at task acquisition, the getTask method used in runWorker:
private Runnable getTask() { boolean timedOut = false; // Indicates whether the last task taken from the blocked queue was timed out for (; ; ) { int c = ctl.get(); int rs = runStateOf(c); // Get thread pool status /** * The following IF is used to determine under which circumstances tasks are not allowed to be retrieved from the queue: * 1. The thread pool enters a stop state (STOP/TIDYING/TERMINATED), at which point it ceases to execute even if there are still tasks in the queue that have not been executed. * 2. Thread pool is non-RUNNING and queue is empty */ if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) { decrementWorkerCount(); // Work threads minus 1 return null; } int wc = workerCountOf(c); // Get the number of worker threads /** * timed Variables are used to determine whether timeout control is required: * For worker threads in the core thread pool, unless allowCoreThreadTimeOut===true, no timeout recovery will occur. * For working threads in non-core thread pools, timeout control is required */ boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; // This is mainly when the maximum number of threads is reset externally through the setMaximum PoolSize method, the extra worker threads need to be reclaimed. if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) return null; continue; } try { Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null) return r; timedOut = true; // Tasks are still unavailable due to timeouts } catch (InterruptedException retry) { timedOut = false; } } }
The main function of the getTask method is to continuously try to get a task from the blocked queue by spinning, and return null if the acquisition fails.
Blocking queues are specified in the constructor when we build the ThreadPoolExecutor object. Because queues are specified externally, the implementation of getTask method varies according to the characteristics of blocking queues.
| Queue characteristics | Bounded queue | Approximate unbounded queue | Unbounded queue | Special queue |
|---|---|---|---|---|
| Locking algorithm | ArrayBlockingQueue | LinkedBlockingQueue,LinkedBlockingDeque | / | PriorityBlockingQueue,DelayQueue |
| Unlock-free algorithm | / | / | LinkedTransferQueue | SynchronousQueue |
We can choose one of the blocking queues in the above table according to business requirements and task characteristics. According to Oracle official documents, there are three situations in which tasks queue in the blocking queue:
1. Direct submission
That is, the task is submitted directly to the waiting worker thread, at which time SynchronousQueue can be selected. Because SynchronousQueue has no capacity and adopts lock-free algorithm, it has better performance, but each entry operation has to wait for an exit operation, and vice versa.
Because the core thread pool is easily full, when using SynchronousQueue, you generally need to Maximum PoolSizes are set large, otherwise entry can easily fail, resulting in the execution of rejection policies, which is why SynchronousQueue is used as the task queue in the cache thread pool provided by Executors by default.
2. Unbounded Task Queue
LinkedTransferQueue and LinkedBlockingQueue are the main choices for unbounded task queues. LinkedTransferQueue adopts unlock-free algorithm in terms of performance, and has better performance in high concurrent environment, but there is little difference in the use of task queues only.
3. Bounded Task Queue
Bounded task queues, such as Array Blocking Queue, can prevent resource depletion. When the core thread pool is full, if the queue is full, a worker thread belonging to the non-core thread pool will be created. If the non-core thread pool is full, the rejection policy will be executed.
Refusal strategy
ThreadPool Executor executes a rejection policy in the following two cases:
- When the core thread pool is full, if the task queue is full, first judge whether the non-core thread pool is full or not, and then create a worker thread (belonging to the non-core thread pool), otherwise the rejection strategy will be executed.
- By the time the task was submitted, ThreadPool Executor was closed.
The so-called rejection strategy is the RejectedExecutionHandler object that is passed in when the ThreadPoolExecutor is constructed:
public interface RejectedExecutionHandler { void rejectedExecution(Runnable r, ThreadPoolExecutor executor); }
ThreadPool Executor provides four rejection strategies:
1.AbortPolicy (default)
The AbortPolicy strategy actually throws a RejectedExecutionException exception:
public static class AbortPolicy implements RejectedExecutionHandler { public AbortPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString()); } }
2.DiscardPolicy
The DiscardPolicy strategy is to do nothing and wait for the task to be reclaimed.
public static class DiscardPolicy implements RejectedExecutionHandler { public DiscardPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { } }
3.DiscardOldestPolicy
Discard Oldest Policy is the latest task in the discarded task queue and executes the current task:
public static class DiscardOldestPolicy implements RejectedExecutionHandler { public DiscardOldestPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { // Thread pool not closed (RUNNING) e.getQueue().poll(); // Discard the most recent task in the task queue e.execute(r); // Execute current tasks } } }
4.CallerRunsPolicy
CallerRunsPolicy strategy is equivalent to executing tasks with its own threads, which can slow down the submission of new tasks.
public static class CallerRunsPolicy implements RejectedExecutionHandler { public CallerRunsPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { // Thread pool not closed (RUNNING) r.run(); // Execute current tasks } } }
IV. Closing of Thread Pool
The ExecutorService interface provides two ways to close the thread pool. The main difference between the two methods is whether to continue processing tasks that have been added to the task queue.
shutdown
The shutdown method switches the thread pool to the SHUTDOWN state (if stopped, no switch is needed), interruptIdleWorkers method is invoked to interrupt all idle worker threads, and tryTerminate is finally invoked to attempt to terminate the thread pool:
public void shutdown() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(SHUTDOWN); // If the thread pool is in RUNNING state, switch to SHUTDOWN state interruptIdleWorkers(); // Interrupt all idle threads onShutdown(); // Hook method, implemented by subclasses } finally { mainLock.unlock(); } tryTerminate(); }
shutdownNow
The main difference of the shutdownNow method is that it sets the state of the thread pool at least to STOP, interrupts all worker threads (whether idle or running), and returns all tasks in the task queue.
public List<Runnable> shutdownNow() { List<Runnable> tasks; final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(STOP); // If the thread pool is RUNNING or SHUTDOWN, switch to STOP interruptWorkers(); // Interrupt all worker threads tasks = drainQueue(); // All Tasks in the Vacuum Task Queue } finally { mainLock.unlock(); } tryTerminate(); return tasks; }
V. Summary
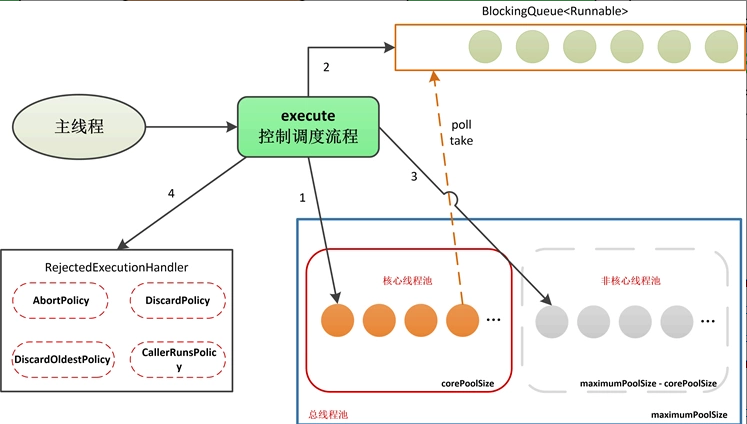
Finally, let's review the overall structure of ThreadPool Executor. The core method of ThreadPool Executor is execute, which controls the creation of worker threads and the execution of tasks.
At the same time, there are several important components in ThreadPool Executor: blocking queue, core thread pool and rejection policy. Their relationships are as follows. The sequence number in the figure indicates the execution order of execute, which can be understood with the flow chart above.
Regarding ThreadPool Executor, the most important thing is to set the parameters of ThreadPool and select the blocking queue reasonably according to the actual situation of the system. In reality, ThreadPool Executor constructors are often used to build thread pools themselves, rather than directly using Executors factories, because this is more conducive to parameter control and tuning.
In addition, according to the characteristics of the task, the size of the core thread pool should be configurated selectively.
- If the task is CPU-intensive (requiring a lot of computation and processing), you should configure as few threads as possible, such as the number of CPUs + 1, so as to avoid the situation that each thread needs a long time but there are too many threads competing for resources;
- If the task is IO-intensive (most of the time is I/O, CPU idle time is more), you should configure more threads, such as twice the number of CPUs, so that you can squeeze the CPU more efficiently.
ThreadPool Executor is finished here. In the next section, we will introduce a thread pool, Scheduled ThreadPool Executor, which can control the execution cycle of tasks. In fact, when we talked about the Scheduled Executor Service interface before, we have already touched on it. The next section will go into its implementation principle.
Reference to this article