I. Introduction to Elastic Stack
ElasticStack currently consists of four parts: Elastic search: core storage and retrieval engine Kibana: Data Visualization Logstash: high throughput data processing engine Beats: collect data
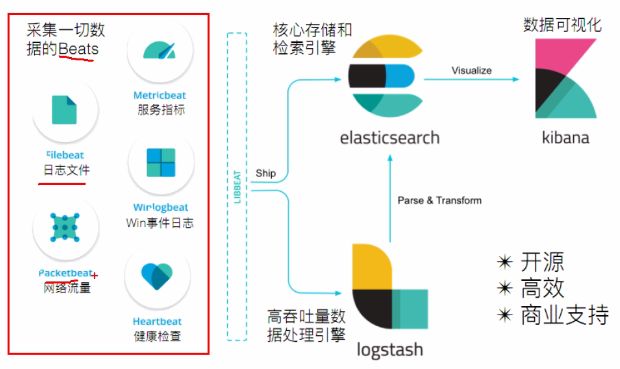
ElasticSearch: Based on Java, it is an open-source distributed search engine, featuring: distributed, zero configuration, automatic discovery, automatic index segmentation, index copy mechanism, restful style, multiple data sources, automatic search load, etc. logstash: Based on Java, it is an open source tool for collecting, analyzing and storing logs. (mainly using beats for data collection) kibana: Based on nodejs, it is also an open-source free tool. kibana can provide log analysis friendly web interface for logstash and elastic search, which can summarize, analyze and search important data logs. beats: it is an open-source agent for collecting system monitoring data of elastic company. It is a general designation of data collectors running in the form of client on the monitored server. You can send data directly to elastic search or through logstash to elastic search, and then carry out subsequent data analysis activities.
Beats consists of: Packetbeat: it is a network packet analyzer, which is used to monitor and collect network traffic information. Packetbeat sniffs traffic between servers, resolves application layer protocols, and is associated with message processing. It supports ICMP (v4 and v6), DNS, HTTP, Mysql, PostgreSQL, Redis, MongoDB, Memcache and other protocols; Filebeat: used to monitor and collect server log files, which has replaced logstash forwarder; Metricbeat: it can regularly obtain monitoring index information of external System, which can monitor and collect Apache, HAProxy, mongodbmmysql, Nginx, PostgreSQL, Redis, System, Zookeeper and other services; Winlogbeat: used to monitor and collect the log information of Windows system;
Introduction and installation of ElasticSearch
1, introduction
ElasticSearch is a Lucene based search server. It provides a distributed multi-user full-text search engine based on RestFul web interface. ElasticSearch is developed in Java, which can achieve real-time search, stability, reliability, fast, easy to install and use.
2, installation
Download: https://www.elastic.co/cn/downloads/elasticsearch
Stand alone installation:
##Create elsearch user, Elasticsearch does not support root user useradd elsearch ##Create elasticStack under opt mkdir elasticStack ##Create es in elasticStack cd elasticStack mkdir es ##Change user rights for elasticStack folder chown elsearch:elsearch elasticStack/ -R [Catalog elasticStack and es All folders belong to elsearch ] ##Switch user elsearch su elsearch ##Upload or download elasticsearch-6.5.4.tar.gz ##Extract to current directory tar -xvf elasticsearch-6.5.4.tar.gz -C /opt/elasticStack/es
Configure config:
##Modify profile cd /conf vim elasticsearch.yml network.host: 0.0.0.0 ?#Set ip address, any network can access ##Note: in elastic search, if network.host is not localhost or 127.0.0.1, ##It will be considered as a production environment with high requirements for the environment. Our test environment may not meet the requirements. Generally, two configurations need to be modified, as follows: #1: modify the jvm startup parameters vim conf/jvm.options -Xms128m #Modify the original value as - xms11g according to your own machine -Xmx128m #It turned out to be - Xmx1g ##2: the maximum number of memory mappings created by a process in Vmas (virtual memory area) [using root user operation: su root] vim /etc/sysctl.conf vm.max_map_count=655360 #Newly added sysctl -p #Configuration effective
Start up:
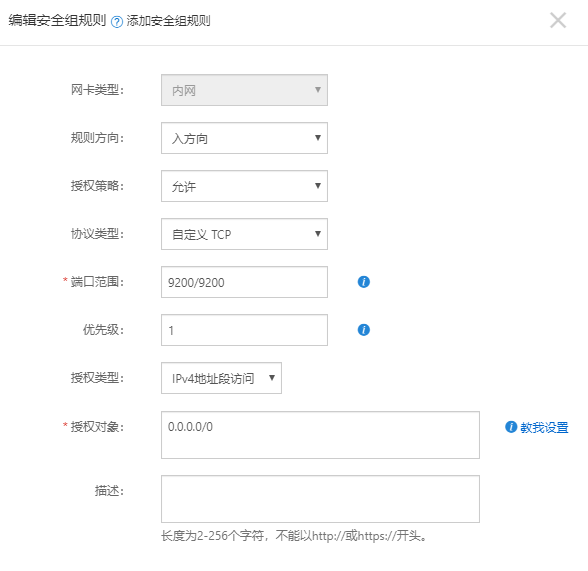
##Start ES service [start as elsearch user] su elsearch cd bin ./elasticsearch or ./elasticsearch -d #Background boot ##Visit: http://Your host IP:9200/ ##If alicloud denies access, you need to set security group rules for ESC instances:
Some errors will be found during startup, which are summarized as follows:
1,ERROR: [1] bootstrap checks failed, [1]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536] #Solution: switch to root, edit limits.conf and add something similar to the following vi /etc/security/limits.conf //Add the following: * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 2,max number of threads [1024] for user [elsearch] is too low, increase to at least [4096] #Solution: switch to the root user and enter the limits.d directory to modify the configuration file. vi /etc/security/limits.d/90-nproc.conf #Amend the following: * soft nproc 1024 #Modified to * soft nproc 4096 3,system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk #Solution: SecComp is not supported in Centos6, and ES5.2.0 default bootstrap.system ﹣ call ﹣ filter is true vim config/elasticsearch.yml //Add to: bootstrap.system_call_filter: false
3,ElasticSearch-head
Lasticsearch head is a page client tool developed for ES. Its source code is hosted in GitHub,
Address: https://github.com/mobz/elasticsearch-head
head provides four installation methods:
Source code installation, start with npm run start (not recommended)
Install through docker (recommended)
Install through the chrome plug-in (recommended)
Install via plugin mode of ES (not recommended)
Install through docker
#Pull mirror image docker pull mobz/elasticsearch-head:5 #Create container docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5 #Starting container docker start elasticsearch-head
Access via browser:
http://Your host IP:9100 [9100 port exposed by docker]
Be careful:
Due to the separation of front and back end development, there will be cross domain problems. It is necessary to configure CORS at the service end, as follows: vim elasticsearch.yml http.cors.enabled: true http.cors.allow-origin: "*" This problem does not exist when installing via the chrome plug-in.
How to install the chrome plug-in
https://github.com/liufengji/es-head Download and unzip Visit: chrome://extensions/ Open developer mode Load the extracted extension
III. introduction to ElasticSearch
1. Basic concepts
Indexes
index is the logical storage of logical data in elastic search, so it can be divided into smaller parts. The index can be regarded as the table of relational database. The structure of index is prepared for fast and effective full-text index, especially it does not store the original value. Elasticsearch can store indexes on one machine or on multiple servers. Each index has one or more Shards, Each shard can have multiple replica s.
File
The primary entity stored in elastic search is called a document. Using a relational database analogy, a document is equivalent to a row of records in a database table. Similar to documents in MongoDB, Elasticsearch can have different structures, but in documents of Elasticsearch, the same fields must have the same type. A document consists of multiple fields. Each field may appear in a document multiple times. Such a field is called multivalued. The type of each field, which can be text, value, date, etc. Field types can also be complex, with one field containing other subdocuments or arrays.
Document type
In elastic search, an index object can store many objects for different purposes. For example, a blog application can save articles and comments. Each document can have a different structure. Different document types cannot set different types for the same property. For example, in all document types in the same index, a field called title must have the same type.
mapping
All documents are analyzed before being written into the index. How to divide the input text into entries and which entries will be filtered is called mapping. Rules are generally defined by the user.
2,RestFul API
In elastic search, it provides rich RESTful API operations, including basic CRUD, index creation, index deletion and other operations.
2.1) create index
In Lucene, to create an index, you need to define the field name and field type. In Elasticsearch, you provide an unstructured index, that is, you can write data to the index without creating an index structure. In fact, in the bottom layer of Elasticsearch, you can perform structured operation, which is transparent to users.
(post man request only)
PUT /haoke { "settings": { "index": { "number_of_shards": "2", "number_of_replicas": "0" } } } ## "number_of_shards" #Fragmentation number ## "number_of_replicas" #Copy number
2.2) delete index
(post man request only)
DELETE /haoke { "acknowledged": true }
2.3) insert data
URL rules
POST / {index} / {type} / {ID} is optional and does not automatically generate a random number
POST /haoke/user/1001 ##data { "id":1001, "name":"Zhang San", "age":20, "sex":"male" } ##Result { _index: "haoke" _type: "user" _id: "1001" _version: 1 result: "created" ##Result _shards: { total: 1 successful: 1 failed: 0 }- _seq_no: 0 _primary_term: 1 }
2.4) update data
In elastic search, document data cannot be modified, but can be updated by overwriting. (delete before add)
Coverage update
URL rules:
PUT / {index} / {type}/{id}
PUT /haoke/user/1001 ##data { "id":1001, "name":"Zhang San", "age":21, "sex":"female" } ##Result { _index: "haoke" _type: "user" _id: "1001" _version: 2 ##Edition result: "updated" ##Result _shards: { total: 1 successful: 1 failed: 0 }- _seq_no: 2 _primary_term: 1 }
Partial update
URL rules:
POST /{Indexes}/{type}/{id}/_update
- Retrieve JSON from old documents 2. Modify it 3. Delete old documents 4. Index new documents
#Note: there are more "update" signs here, PUT is changed to POST POST /haoke/user/1001/_update ##data { "doc": { "age":23 } } ##Result { _index: "haoke" _type: "user" _id: "1001" _version: 4 result: "updated" _shards: { total: 1 successful: 1 failed: 0 }- _seq_no: 4 _primary_term: 1 }
2.5) delete data
URL rules:
DELETE / {index} / {type} / {id}
In elastic search, to DELETE document data, you only need to initiate a DELETE request.
Be careful:
Deleting a document does not immediately remove it from disk, it is simply marked as deleted. Elastic search will only clean up the deleted content in the background when you add more indexes later.
Test:
DELETE /haoke/user/1001 //Result: { _index: "haoke" _type: "user" _id: "1001" _version: 5 result: "deleted" ##Result _shards: { total: 1 successful: 1 failed: 0 }- _seq_no: 5 _primary_term: 1 }
2.6) query data
A. search by ID
URL rules:
GET / {index} / {type} / {id}
GET /haoke/user/FD_2gm4BoifuYiH46rUl //Result: { _index: "haoke" _type: "user" _id: "FD_2gm4BoifuYiH46rUl" _version: 1 found: true _source: { id: 1002 name: "Li Si" age: 21 sex: "male" }- }
B. query all
URL rules:
GET / {index} / {type} / {u search
Be careful:
10 data returned by default More data to do paging query
Test:
GET /haoke/user/_search ##Result: { took: 9 timed_out: false _shards: { total: 2 successful: 2 skipped: 0 failed: 0 }- hits: { total: 1 max_score: 1 hits: [1] ##Hit, find 1 piece of data 0: { _index: "haoke" _type: "user" _id: "FD_2gm4BoifuYiH46rUl" _score: 1 ##Score _source: { id: 1002 name: "Li Si" age: 21 sex: "male" }- }- - }- }
C. search by field
URL rules:
GET / {index} / {type} / {u search?q = field: field value
Test:
GET /haoke/user/_search?q=age:21 ##Result: { took: 2 timed_out: false _shards: { total: 2 successful: 2 skipped: 0 failed: 0 }- hits: { total: 1 max_score: 1 hits: [1] ##Hit 0: { _index: "haoke" _type: "user" _id: "FD_2gm4BoifuYiH46rUl" _score: 1 ##Score _source: { id: 1002 name: "Li Si" age: 21 sex: "male" }- }- - }- }
2.7) DSL search
| _index | _type | _id | _score | id | name | age | sex |
|---|---|---|---|---|---|---|---|
| haoke | user | FT_Hh24BoifuYiH4yLVZ | 1 | 1002 | Li Si | 21 | female |
| haoke | user | Fj_Ih24BoifuYiH4mrUZ | 1 | 1001 | Zhang San | 20 | male |
| haoke | user | Fz_Ih24BoifuYiH49rXb | 1 | 1004 | Zhao Liu | 32 | female |
| haoke | user | GD_Jh24BoifuYiH4ULXB | 1 | 1005 | Sun Qi | 33 | male |
| haoke | user | GT_Jh24BoifuYiH4frUv | 1 | 1003 | Wang Wu | 31 | male |
a. query age equal to 20
{ "query":{ "match":{ "age":20 } } }
b. query the male over 30 years old
{ "query":{ "bool":{ "filter":{ ##filter "range":{ ##Range "age":{ "gt":30 } } }, "must":{ ##Must "match":{ ##matching "sex":"male" } } } } }
//TODO's detailed description of DSL, to be written later
2.8) highlight
name highlight:
{ "query":{ "match":{ "name":"this one and that one" } }, "highlight":{ "fields":{ "name":{} } } }
2.9) polymerization
Similar to group by
{ "aggs":{ "all_interests":{ "terms":{ "field":"age" } } } }
The above is just a brief explanation. The details will be analyzed later