As we know, there are usually multiple instances on the Dubbo server, and the Dubbo consumer has built-in policies for load balancing scheduling. Let's take a general look.
The overall architecture of routing and load balancing officially given is as follows:
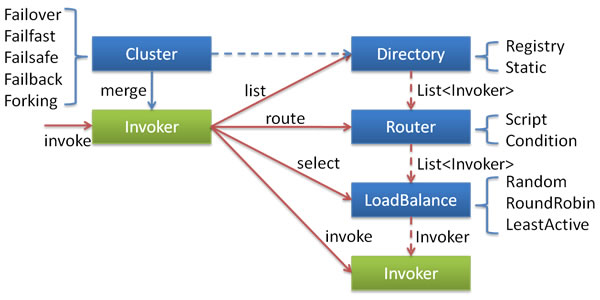
Before we start, let's talk about a few concepts in Dubbo:
- Cluster is commonly known as cluster. In order to avoid single point of failure, current applications are usually deployed on at least two servers. For some services with high load, more servers will be deployed. In this way, the number of service providers in the same environment will be greater than 1. For service consumers, there are multiple service providers in the same environment. At this point, a problem arises that the service consumer needs to decide which service provider to choose to invoke. In addition, the handling measures when the service call fails also need to be considered, such as retry, throwing an exception, or printing only an exception. In order to solve these problems, Dubbo defines the cluster interface cluster and Cluster Invoker. The purpose of cluster is to combine multiple service providers into a Cluster Invoker and expose the Invoker to service consumers. In this way, the service consumer only needs to make a remote call through the Invoker. The specific service provider to call and how to deal with it after the call fails are now handed over to the cluster module. The cluster module is the middle layer between service providers and service consumers. It shields the situation of service providers for service consumers, so that service consumers can concentrate on handling matters related to remote calls. For example, send a request and accept the data returned by the service provider. This is the role of clusters. The working process of the cluster can be divided into two stages. The first stage is that during the initialization of the service consumer, the cluster implementation class creates a Cluster Invoker instance for the service consumer, that is, the merge operation in the above figure. The second stage is when the service consumer makes a remote call. Take failovercluster Invoker as an example. This type of Cluster Invoker will first call the List method of directory to enumerate the List of invokers (Invoker can be simply understood as a service provider). Directory is used to save invokers, which can be simply compared to List. Its implementation class RegistryDirectory is a dynamic service directory, which can sense the changes of registry configuration, and its List of invokers will change with the changes of registry content. After each change, RegistryDirectory will dynamically add or delete invokers, and call the route method of the Router to route, filtering out the invokers that do not comply with the routing rules. When FailoverClusterInvoker gets the List of invokers returned from the directory, it will select an Invoker from the List of invokers through LoadBalance. Finally, FailoverClusterInvoker will pass the parameters to the invoke method of the Invoker instance selected by LoadBalance for real remote calls.
- Directory service directory stores some information related to service providers. Through the service directory, service consumers can obtain the information of service providers, such as ip, port, service protocol, etc. Through this information, service consumers can make remote calls through clients such as Netty. In a service cluster, the number of service providers is not invariable. If a machine is added to the cluster, a service provider record must be added in the service directory accordingly. Or, if the configuration of the service provider is modified, the records in the service directory should be updated accordingly. In fact, after obtaining the service configuration information of the registry, the service directory will generate an Invoker object for each configuration information and store the Invoker object, which is the object finally held by the service directory. The Invoker is the remote method call that is ultimately held
- LoadBalance load balancing is responsible for "sharing" network requests or other forms of load to different machines. Avoid excessive pressure on some servers in the cluster while others are idle. Through load balancing, each server can obtain the load suitable for its own processing capacity. While shunting high load servers, it can also avoid resource waste and kill two birds with one stone. Load balancing can be divided into software load balancing and hardware load balancing. In our daily development, it is generally difficult to touch hardware load balancing. However, software load balancing is still accessible, such as Nginx. In Dubbo, there are also load balancing concepts and corresponding implementations. Dubbo needs to allocate the call requests of service consumers to avoid excessive load on a few service providers. The service provider is overloaded, which will cause some requests to time out. Therefore, it is very necessary to balance the load on each service provider. Dubbo provides four load balancing implementations, namely RandomLoadBalance based on weight random algorithm, leadactiveloadbalance based on least active calls algorithm, ConsistentHashLoadBalance based on hash consistency, and roundrobin LoadBalance based on weighted polling algorithm.
- Router service,. In the process of refreshing the Invoker list, the service directory will route the service through the router to filter out the service providers that meet the routing rules. Service routing includes a routing rule, which determines the call target of service consumers, that is, it specifies which service providers can be called by service consumers. Dubbo currently provides three service routing implementations: conditional routing, script routing and tag routing.
The above explanation comes from Dubbo shopping website.
It can be seen that Dubbo's load balancing is realized with the help of these modules. And its
Based on previous analysis Dubbo consumer starts the process, processing logic, and method call implementation (based on Dubbo 3)
We know that Invoker is initialized in ReferenceConfig:
private T createProxy(Map<String, String> map) {
if (shouldJvmRefer(map)) {
URL url = new ServiceConfigURL(LOCAL_PROTOCOL, LOCALHOST_VALUE, 0, interfaceClass.getName()).addParameters(map);
invoker = REF_PROTOCOL.refer(interfaceClass, url);
if (logger.isInfoEnabled()) {
logger.info("Using injvm service " + interfaceClass.getName());
}
} else {
urls.clear();
if (url != null && url.length() > 0) { // user specified URL, could be peer-to-peer address, or register center's address.
String[] us = SEMICOLON_SPLIT_PATTERN.split(url);
if (us != null && us.length > 0) {
for (String u : us) {
URL url = URL.valueOf(u);
if (StringUtils.isEmpty(url.getPath())) {
url = url.setPath(interfaceName);
}
if (UrlUtils.isRegistry(url)) {
urls.add(url.putAttribute(REFER_KEY, map));
} else {
URL peerURL = ClusterUtils.mergeUrl(url, map);
peerURL = peerURL.putAttribute(PEER_KEY, true);
urls.add(peerURL);
}
}
}
} else { // assemble URL from register center's configuration
// if protocols not injvm checkRegistry
if (!LOCAL_PROTOCOL.equalsIgnoreCase(getProtocol())) {
checkRegistry();
List<URL> us = ConfigValidationUtils.loadRegistries(this, false);
if (CollectionUtils.isNotEmpty(us)) {
for (URL u : us) {
URL monitorUrl = ConfigValidationUtils.loadMonitor(this, u);
if (monitorUrl != null) {
u = u.putAttribute(MONITOR_KEY, monitorUrl);
}
urls.add(u.putAttribute(REFER_KEY, map));
}
}
if (urls.isEmpty()) {
throw new IllegalStateException(
"No such any registry to reference " + interfaceName + " on the consumer " + NetUtils.getLocalHost() +
" use dubbo version " + Version.getVersion() +
", please config <dubbo:registry address=\"...\" /> to your spring config.");
}
}
}
if (urls.size() == 1) {
invoker = REF_PROTOCOL.refer(interfaceClass, urls.get(0));
} else {
List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();
URL registryURL = null;
for (URL url : urls) {
invokers.add(REF_PROTOCOL.refer(interfaceClass, url));
if (UrlUtils.isRegistry(url)) {
registryURL = url; // use last registry url
}
}
if (registryURL != null) { // registry url is available
// for multi-subscription scenario, use 'zone-aware' policy by default
String cluster = registryURL.getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME);
// The invoker wrap sequence would be: ZoneAwareClusterInvoker(StaticDirectory) -> FailoverClusterInvoker(RegistryDirectory, routing happens here) -> Invoker
invoker = Cluster.getCluster(cluster, false).join(new StaticDirectory(registryURL, invokers));
} else { // not a registry url, must be direct invoke.
String cluster = CollectionUtils.isNotEmpty(invokers)
?
(invokers.get(0).getUrl() != null ? invokers.get(0).getUrl().getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME) :
Cluster.DEFAULT)
: Cluster.DEFAULT;
invoker = Cluster.getCluster(cluster).join(new StaticDirectory(invokers));
}
}
}
if (logger.isInfoEnabled()) {
logger.info("Referred dubbo service " + interfaceClass.getName());
}
URL consumerURL = new ServiceConfigURL(CONSUMER_PROTOCOL, map.get(REGISTER_IP_KEY), 0, map.get(INTERFACE_KEY), map);
MetadataUtils.publishServiceDefinition(consumerURL);
// create service proxy
return (T) PROXY_FACTORY.getProxy(invoker, ProtocolUtils.isGeneric(generic));
}
Here, we can see that if there is only one address and it is not a registered address, it will be connected directly without any load balancing.
If there are multiple addresses and the address is a registered address, this corresponds to the protocol corresponding to the registry,
Here is REF_PROTOCOL is an adaptive extension,
private static final Protocol REF_PROTOCOL = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
In Dubhbo, the corresponding Protocol$Adaptive is implemented as follows:
public org.apache.dubbo.rpc.Invoker refer(java.lang.Class arg0, org.apache.dubbo.common.URL arg1) throws org.apache.dubbo.rpc.RpcException {
if (arg1 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg1;
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null) throw new IllegalStateException("Failed to get extension (org.apache.dubbo.rpc.Protocol) name from url (" + url.toString() + ") use keys([protocol])");
org.apache.dubbo.rpc.Protocol extension = (org.apache.dubbo.rpc.Protocol)ExtensionLoader.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.refer(arg0, arg1);
}
Here we get a RegistryProtocol, and its corresponding refer ence implementation is as follows:
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
url = getRegistryUrl(url);
Registry registry = registryFactory.getRegistry(url);
if (RegistryService.class.equals(type)) {
return proxyFactory.getInvoker((T) registry, type, url);
}
// group="a,b" or group="*"
Map<String, String> qs = (Map<String, String>) url.getAttribute(REFER_KEY);
String group = qs.get(GROUP_KEY);
if (group != null && group.length() > 0) {
if ((COMMA_SPLIT_PATTERN.split(group)).length > 1 || "*".equals(group)) {
return doRefer(Cluster.getCluster(MergeableCluster.NAME), registry, type, url, qs);
}
}
Cluster cluster = Cluster.getCluster(qs.get(CLUSTER_KEY));
return doRefer(cluster, registry, type, url, qs);
}
protected <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url, Map<String, String> parameters) {
Map<String, Object> consumerAttribute = new HashMap<>(url.getAttributes());
consumerAttribute.remove(REFER_KEY);
URL consumerUrl = new ServiceConfigURL(parameters.get(PROTOCOL_KEY) == null ? DUBBO : parameters.get(PROTOCOL_KEY),
null,
null,
parameters.get(REGISTER_IP_KEY),
0, getPath(parameters, type),
parameters,
consumerAttribute);
url = url.putAttribute(CONSUMER_URL_KEY, consumerUrl);
ClusterInvoker<T> migrationInvoker = getMigrationInvoker(this, cluster, registry, type, url, consumerUrl);
return interceptInvoker(migrationInvoker, url, consumerUrl, url);
}
If it is a RegistryService service, register directly. Others go doRefer
We can see here that if we configure the group attribute, we will merge here and get a MergeableCluster
In the following doRefer, the actual service reference processing will be performed:
protected <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url, Map<String, String> parameters) {
Map<String, Object> consumerAttribute = new HashMap<>(url.getAttributes());
consumerAttribute.remove(REFER_KEY);
URL consumerUrl = new ServiceConfigURL(parameters.get(PROTOCOL_KEY) == null ? DUBBO : parameters.get(PROTOCOL_KEY),
null,
null,
parameters.get(REGISTER_IP_KEY),
0, getPath(parameters, type),
parameters,
consumerAttribute);
url = url.putAttribute(CONSUMER_URL_KEY, consumerUrl);
ClusterInvoker<T> migrationInvoker = getMigrationInvoker(this, cluster, registry, type, url, consumerUrl);
return interceptInvoker(migrationInvoker, url, consumerUrl, url);
}
ClusterInvoker migrationInvoker = getMigrationInvoker(this, cluster, registry, type, url, consumerUrl);
A ServiceDiscoveryMigrationInvoker is returned here
In addition, you should pay attention to the method interceptInvoker:
protected <T> Invoker<T> interceptInvoker(ClusterInvoker<T> invoker, URL url, URL consumerUrl, URL registryURL) {
List<RegistryProtocolListener> listeners = findRegistryProtocolListeners(url);
if (CollectionUtils.isEmpty(listeners)) {
return invoker;
}
for (RegistryProtocolListener listener : listeners) {
listener.onRefer(this, invoker, consumerUrl, registryURL);
}
return invoker;
}
This method is equivalent to calling the corresponding listener. The default implementation in Dubbo is MigrationRuleListener. When the refer ence event is triggered, it will call MigrationRuleHandler.doMigrate, and finally trigger:
serviceDiscoveryInvoker = registryProtocol.getServiceDiscoveryInvoker(cluster, registry, type, url);
Finally, an InvocationInterceptorInvoker is returned
Go back to the createProxy of ReferenceConfig
if (registryURL != null) { // registry url is available
String cluster = registryURL.getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME);
invoker = Cluster.getCluster(cluster, false).join(new StaticDirectory(registryURL, invokers));
} else {
String cluster = CollectionUtils.isNotEmpty(invokers)
?
(invokers.get(0).getUrl() != null ? invokers.get(0).getUrl().getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME) :
Cluster.DEFAULT)
: Cluster.DEFAULT;
invoker = Cluster.getCluster(cluster).join(new StaticDirectory(invokers));
}
If it is obtained through service registration, the returned one is zoneawareclusterinvoker (used to handle different machine room zones)
If we don't specify it specifically, zonewareclusterinvoker will hold a FailoverClusterInvoker, and the same FailoverClusterInvoker will hold an Invoker
Zoneawareclusterinvoker = > failoverclusterinvoker = > invoker
It is probably such a packaging process.
zone, multi registry machine room processing
If the machine room configuration is used in the configuration, for example:
dubbo.registries.shanghai.id=shanghai dubbo.registries.shanghai.address=xxxx dubbo.registries.shanghai.zone=shanghai dubbo.registries.beijing.id=beijing dubbo.registries.beijing.address=xxxx dubbo.registries.beijing.zone=beijing
In order to separate the flow, those requiring Beijing computer rooms can only consume Beijing, and those in Shanghai computer rooms can only consume Shanghai.
At this time, ZoneAwareClusterInvoker will first select one of multiple machine rooms according to the zone:
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
for (Invoker<T> invoker : invokers) {
ClusterInvoker<T> clusterInvoker = (ClusterInvoker<T>) invoker;
if (clusterInvoker.isAvailable() && clusterInvoker.getRegistryUrl()
.getParameter(PREFERRED_KEY, false)) {
return clusterInvoker.invoke(invocation);
}
}
String zone = invocation.getAttachment(REGISTRY_ZONE);
if (StringUtils.isNotEmpty(zone)) {
for (Invoker<T> invoker : invokers) {
ClusterInvoker<T> clusterInvoker = (ClusterInvoker<T>) invoker;
if (clusterInvoker.isAvailable() && zone.equals(clusterInvoker.getRegistryUrl().getParameter(ZONE_KEY))) {
return clusterInvoker.invoke(invocation);
}
}
String force = invocation.getAttachment(REGISTRY_ZONE_FORCE);
if (StringUtils.isNotEmpty(force) && "true".equalsIgnoreCase(force)) {
throw new IllegalStateException("No registry instance in zone or no available providers in the registry, zone: "
+ zone
+ ", registries: " + invokers.stream().map(invoker -> ((MockClusterInvoker<T>) invoker).getRegistryUrl().toString()).collect(Collectors.joining(",")));
}
}
Invoker<T> balancedInvoker = select(loadbalance, invocation, invokers, null);
if (balancedInvoker.isAvailable()) {
return balancedInvoker.invoke(invocation);
}
for (Invoker<T> invoker : invokers) {
ClusterInvoker<T> clusterInvoker = (ClusterInvoker<T>) invoker;
if (clusterInvoker.isAvailable()) {
return clusterInvoker.invoke(invocation);
}
}
return invokers.get(0).invoke(invocation);
}
Can see
- If set:
dubbo.registries.shanghai.preferred=true
Then, regardless of other rules, the registry is preferred.
2. If preferred is not set, the same zone has a higher priority
3. If the zone is not set, it is determined according to the weight
dubbo.registries.shanghai.weight=100
- If there are no other options, choose one
Cluster cluster
In this way, we select a registry, and then select one from multiple services in the registry through Cluster.
dubbo.registries.shanghai.cluster=failover
The optional strategies are as follows:
- The default policy of failover is FailoverCluster, which corresponds to failoverclusterinvoker. When the call fails, failoverclusterinvoker will automatically switch the Invoker to retry. By default, Dubbo will use this class as the default Cluster Invoker.
- failback policy. FailbackCluster corresponds to FailbackClusterInvoker. After the call fails, FailbackClusterInvoker will return an empty result to the service consumer. The failed call is retransmitted through scheduled tasks, which is suitable for message notification and other operations.
- failfast policy. FailfastCluster corresponds to failfastclusterinvoker. Failfastclusterinvoker will only be called once, and an exception will be thrown immediately after failure. It is applicable to idempotent operations, such as adding records.
- failsafe policy. FailsafeCluster corresponds to FailsafeClusterInvoker. FailsafeClusterInvoker is a failure safe Cluster Invoker. The so-called failure safety means that when an exception occurs during the call, FailsafeClusterInvoker will only print the exception and will not throw an exception. It is applicable to operations such as writing the audit log.
- In forking measurement, ForkingCluster corresponds to ForkingClusterInvoker. ForkingClusterInvoker will create multiple threads through the thread pool and call multiple service providers concurrently. As long as one service provider successfully returns the result, the doInvoke method will end running immediately. The application scenario of ForkingClusterInvoker is in some read operations that require high real-time performance (note that read operations and parallel write operations may not be safe), but this will consume more resources.
- brocadcast and BroadcastCluster correspond to BroadcastClusterInvoker. BroadcastClusterInvoker will call each service provider one by one. If one of them reports an error, BroadcastClusterInvoker will throw an exception after the end of the circular call. This class is usually used to notify all providers to update local resource information such as cache or log.
Service directory
When we select an Invoker from the Cluster, the Cluster does not hold the Invoker collection, but internally maintains a service directory to obtain the list of Invoker collections through the service directory.
In Dubbo, the service directory is abstracted as AbstractDirectory, and the class structure level is as follows:
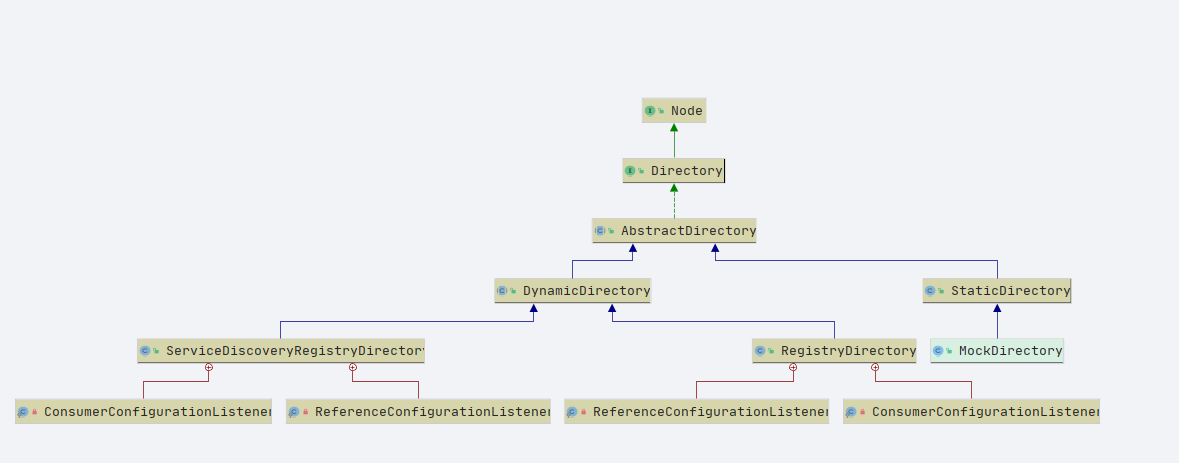
Let's pick two to illustrate:
- StaticDirectory: This is a static fixed service directory. The Invoker list in this directory is unchanged
- RegistryDirectory inherits from DynamicDirectory. From the name, we can see that it is a dynamic service directory, and the list of invokers in it will change. For RegistryDirectory, it will change dynamically according to the online and offline registration services in the registry.
In addition, when obtaining the Invoker list from the service directory, it will be filtered here according to the corresponding routing Router.
Router routing
When obtaining the Invoker list through the service directory, the Invoker list will be filtered through routing settings, such as ConditionRouter, TagRouter, ScriptRouter, etc.
LoadBalance load balancing
After obtaining the Invoker set through Cluster, we will select an Invoker from the set to be selected through LoadBalance to finally execute the request. Dubbo provides the following LoadBalance load balancing strategies:
- consistenthash,ConsistentHashLoadBalance, implementation of consistency hash,
- Random, RandomLoadBalance is A concrete implementation of weighted random algorithm. Its algorithm idea is very simple. Suppose we have A group of servers = [A, B, C], their corresponding weights = [5, 3, 2], and the total weight is 10. Now tile these weight values on one-dimensional coordinate values, [0, 5) interval belongs to server A, [5, 8) interval belongs to server B, [8, 10) the interval belongs to server C. next, A range is generated through the random number generator [0, 10), and then calculate which interval the random number will fall into. For example, the number 3 will fall into the corresponding interval of server A, and then return to server A. the larger the weight of the machine, the larger the range of the corresponding interval on the coordinate axis, so the number generated by the random number generator will have A greater probability of falling into this interval. As long as the random number is generated The random number generated by the server is well distributed. After multiple selections, the proportion of times each server is selected is close to its weight proportion. For example, after 10000 selections, server A is selected about 5000 times, server B is selected about 3000 times, and server C is selected about 2000 times.
- Round robin and round robin load balance are weighted polling load balancing. The so-called polling refers to allocating requests to each server in turn. For example, we have three servers A, B and C. We assign the first request to server A, the second request to server B, the third request to server C, and the fourth request to server A again. This process is called polling. Polling is A stateless load balancing algorithm, which is simple to implement and suitable for scenarios where the performance of each server is similar. But in reality, we cannot guarantee that the performance of each server is similar. It is obviously unreasonable if we allocate the same number of requests to servers with poor performance. Therefore, at this time, we need to weight the polling process to regulate the load of each server. After weighting, the proportion of requests that each server can get is close to or equal to their weight ratio. For example, the weight ratio of servers A, B and C is 5:2:1. Then, among the eight requests, server A will receive five of them, server B will receive two of them, and server C will receive one of them.
- Leadactive, leadactiveloadbalance and leadactiveloadbalance are implemented based on the weighted minimum active number algorithm. The smaller the number of active calls, it indicates that the service provider is more efficient and can process more requests per unit time. At this time, the request should be assigned to the service provider in priority. In the specific implementation, each service provider corresponds to an active number active. Initially, the active number of all service providers is 0. Each time a request is received, the active number is increased by 1. After the request is completed, the active number is reduced by 1. After the service runs for a period of time, the service provider with good performance processes the request faster, so the active number decreases faster. At this time, such service provider can give priority to obtaining new service requests, which is the basic idea of the minimum active number load balancing algorithm. In addition to the minimum active number, leadactiveloadbalance also introduces weight values in its implementation.
It can be seen that the general process of cluster load balancing in Dubbo is as follows:
If it is the registration center method, first judge whether there is a zone configuration. If there is a zone configuration, select a service registration center from multiple service registration addresses according to the zone method, and then select an Invoker set from the selected service registration center according to the configured Cluster method (at this time, the selection is made through the service directory, which will be filtered again according to the configured routing method). Then, select the selected Invoker list for load balancing, and finally select an Invoker according to the configured load balancing policy
If it is non Registry (direct connection) and has multiple addresses, it is basically the same as the above method, but there is no zone layer
If it is a non registered center and has only one address, it will be connected directly and there will be no other processing