After a container is pulled up by kubelet in k8s, the user can specify the way of sniffing to check the health of the container. TCP, Http and command are currently supported. Today, the implementation of the whole sniffing module is introduced to understand the implementation of its periodic detection, counter, delay and other design.
1. Exploring the overall design
1.1 Thread Model
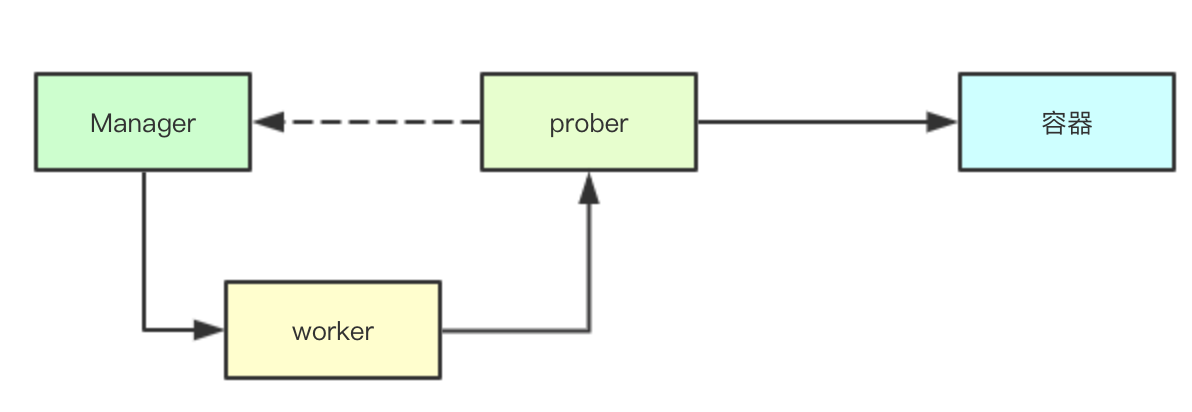 The spied threading model is relatively simple in design, with the worker performing the underlying spies and the Manager managing the worker while caching the spied results
The spied threading model is relatively simple in design, with the worker performing the underlying spies and the Manager managing the worker while caching the spied results
1.2 Periodic Expeditions
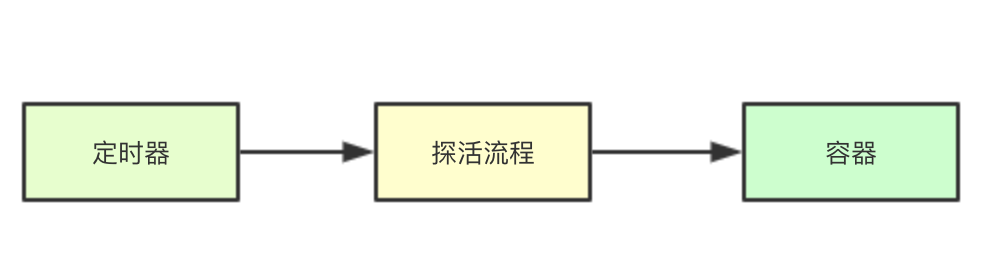 To generate a timer based on the cycle of each sniffing task, you only need to listen for timer events
To generate a timer based on the cycle of each sniffing task, you only need to listen for timer events
1.3 Realization of Exploration Mechanism
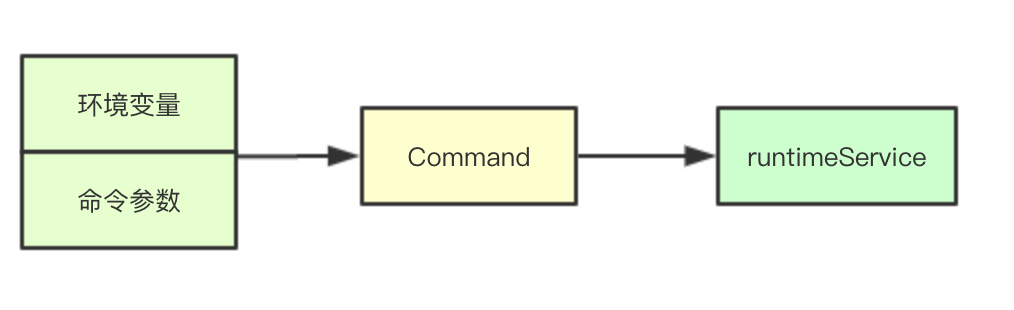 The implementation of the sniffing mechanism is relatively simple except for the commands Http and Tcp, Tcp only needs to be directly linked through net.DialTimeout, while Http constructs an http.Transport to construct an Http request to perform a Do operation.
The implementation of the sniffing mechanism is relatively simple except for the commands Http and Tcp, Tcp only needs to be directly linked through net.DialTimeout, while Http constructs an http.Transport to construct an Http request to perform a Do operation.
Relatively complex is exec, which first generates commands based on the current container's environment variables, then builds a Command through containers, commands, timeouts, etc. Finally calls runtimeService to call csi to execute commands.
2. Probing interface implementation
2.1 Core Member Structure
type prober struct { exec execprobe.Prober // We can see that for readiness/liveness a http Transport will be launched to link readinessHTTP httpprobe.Prober livenessHTTP httpprobe.Prober startupHTTP httpprobe.Prober tcp tcpprobe.Prober runner kubecontainer.ContainerCommandRunner // refManager is primarily a reference object used to get members refManager *kubecontainer.RefManager // The recorder is responsible for building the probe result event and eventually passing it back to apiserver recorder record.EventRecorder }
2.2 Exploring the Main Course
The main process of exploration is mainly in the probe method of prober, whose core process is divided into three sections
2.2.1 Getting the Target Configuration for the Exploration
func (pb *prober) probe(probeType probeType, pod *v1.Pod, status v1.PodStatus, container v1.Container, containerID kubecontainer.ContainerID) (results.Result, error) { var probeSpec *v1.Probe // Get the configuration of the probe for the corresponding location based on the type of probe switch probeType { case readiness: probeSpec = container.ReadinessProbe case liveness: probeSpec = container.LivenessProbe case startup: probeSpec = container.StartupProbe default: return results.Failure, fmt.Errorf("unknown probe type: %q", probeType) }
2.2.2 Execute sniffing to record error information
If an error is returned, or if it is not in a successful or warning state, the corresponding reference object is retrieved, then the event is constructed with a recorder, and the result is sent back to apiserver
// Execute the sounding process result, output, err := pb.runProbeWithRetries(probeType, probeSpec, pod, status, container, containerID, maxProbeRetries) if err != nil || (result != probe.Success && result != probe.Warning) { // //If an error is returned, or if it is not a success or warning state // Then the corresponding reference object is obtained and passed ref, hasRef := pb.refManager.GetRef(containerID) if !hasRef { klog.Warningf("No ref for container %q (%s)", containerID.String(), ctrName) } if err != nil { klog.V(1).Infof("%s probe for %q errored: %v", probeType, ctrName, err) recorder Construct events, send results back apiserver if hasRef { pb.recorder.Eventf(ref, v1.EventTypeWarning, events.ContainerUnhealthy, "%s probe errored: %v", probeType, err) } } else { // result != probe.Success klog.V(1).Infof("%s probe for %q failed (%v): %s", probeType, ctrName, result, output) // recorder constructs events and sends results back to apiserver if hasRef { pb.recorder.Eventf(ref, v1.EventTypeWarning, events.ContainerUnhealthy, "%s probe failed: %s", probeType, output) } } return results.Failure, err }
2.2.3 Probe Retry Implementation
func (pb *prober) runProbeWithRetries(probeType probeType, p *v1.Probe, pod *v1.Pod, status v1.PodStatus, container v1.Container, containerID kubecontainer.ContainerID, retries int) (probe.Result, string, error) { var err error var result probe.Result var output string for i := 0; i < retries; i++ { result, output, err = pb.runProbe(probeType, p, pod, status, container, containerID) if err == nil { return result, output, nil } } return result, output, err }
2.2.4 Depending on the type of exploration performed
func (pb *prober) runProbe(probeType probeType, p *v1.Probe, pod *v1.Pod, status v1.PodStatus, container v1.Container, containerID kubecontainer.ContainerID) (probe.Result, string, error) { timeout := time.Duration(p.TimeoutSeconds) * time.Second if p.Exec != nil { klog.V(4).Infof("Exec-Probe Pod: %v, Container: %v, Command: %v", pod, container, p.Exec.Command) command := kubecontainer.ExpandContainerCommandOnlyStatic(p.Exec.Command, container.Env) return pb.exec.Probe(pb.newExecInContainer(container, containerID, command, timeout)) } if p.HTTPGet != nil { // Get protocol type and http parameter information scheme := strings.ToLower(string(p.HTTPGet.Scheme)) host := p.HTTPGet.Host if host == "" { host = status.PodIP } port, err := extractPort(p.HTTPGet.Port, container) if err != nil { return probe.Unknown, "", err } path := p.HTTPGet.Path klog.V(4).Infof("HTTP-Probe Host: %v://%v, Port: %v, Path: %v", scheme, host, port, path) url := formatURL(scheme, host, port, path) headers := buildHeader(p.HTTPGet.HTTPHeaders) klog.V(4).Infof("HTTP-Probe Headers: %v", headers) switch probeType { case liveness: return pb.livenessHTTP.Probe(url, headers, timeout) case startup: return pb.startupHTTP.Probe(url, headers, timeout) default: return pb.readinessHTTP.Probe(url, headers, timeout) } } if p.TCPSocket != nil { port, err := extractPort(p.TCPSocket.Port, container) if err != nil { return probe.Unknown, "", err } host := p.TCPSocket.Host if host == "" { host = status.PodIP } klog.V(4).Infof("TCP-Probe Host: %v, Port: %v, Timeout: %v", host, port, timeout) return pb.tcp.Probe(host, port, timeout) } klog.Warningf("Failed to find probe builder for container: %v", container) return probe.Unknown, "", fmt.Errorf("missing probe handler for %s:%s", format.Pod(pod), container.Name) }
3. worker worker threads
Worker worker threads perform probes with several considerations: 1. Containers may need to wait for a while when they are just started, for example, applications may need to do some initialization work and are not ready 2. Repeated probes before startup are also meaningless if container probes fail and are restarted 3. Whether successful or unsuccessful, thresholds may be required to assist in avoiding a single small probability failure and restarting the container
3.1 Core Members
In addition to the detection configuration correlation, the key parameters are mainly the onHold parameter, which is used to determine whether to delay detection of containers, that is, when a container restarts, it needs to delay detection, and resultRun is a counter through which successive successes or failures are accumulated and subsequently whether a given threshold is exceeded.
type worker struct { // Stop channel stopCh chan struct{} // pod containing probe pod *v1.Pod // Container Probe container v1.Container // Probe Configuration spec *v1.Probe // Probe type probeType probeType // The probe value during the initial delay. initialValue results.Result // Store detection results resultsManager results.Manager probeManager *manager // The last known container ID of this worker process. containerID kubecontainer.ContainerID // Last Detection Result lastResult results.Result // Detection returns the same result continuously at this time resultRun int // Probe failure will be set to true and no probes will be made onHold bool // proberResultsMetricLabels holds the labels attached to this worker // for the ProberResults metric by result. proberResultsSuccessfulMetricLabels metrics.Labels proberResultsFailedMetricLabels metrics.Labels proberResultsUnknownMetricLabels metrics.Labels }
3.2 Probing Implements Core Processes
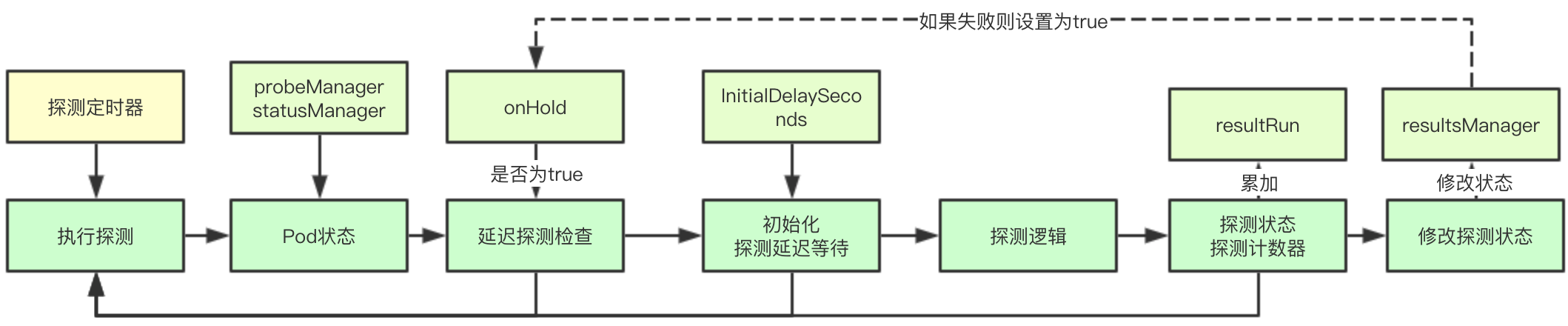
3.2.1 Failed Container Detection Interrupt
If the state of the current container has been terminated, it does not need to be probed and can be returned directly
// Gets the status of the current worker's corresponding pod status, ok := w.probeManager.statusManager.GetPodStatus(w.pod.UID) if !ok { // Either the pod has not been created yet, or it was already deleted. klog.V(3).Infof("No status for pod: %v", format.Pod(w.pod)) return true } // If pod terminates worker should terminate if status.Phase == v1.PodFailed || status.Phase == v1.PodSucceeded { klog.V(3).Infof("Pod %v %v, exiting probe worker", format.Pod(w.pod), status.Phase) return false }
3.2.2 Delayed detection recovery
Delayed detection recovery mainly refers to restart operation in case of detection failure, during which no detection will occur. The logic of recovery is to determine if the id of the corresponding container has changed, and to modify onHold.
// Get the latest container information by container name c, ok := podutil.GetContainerStatus(status.ContainerStatuses, w.container.Name) if !ok || len(c.ContainerID) == 0 { // Either the container has not been created yet, or it was deleted. klog.V(3).Infof("Probe target container not found: %v - %v", format.Pod(w.pod), w.container.Name) return true // Wait for more information. } if w.containerID.String() != c.ContainerID { // If the container changes, a container is restarted if !w.containerID.IsEmpty() { w.resultsManager.Remove(w.containerID) } w.containerID = kubecontainer.ParseContainerID(c.ContainerID) w.resultsManager.Set(w.containerID, w.initialValue, w.pod) // Getting a new container requires re-opening the probe w.onHold = false } if w.onHold { //If the current set delay state is true, no probing will occur return true }
3.2.3 Initialize Delay Detection
Initialization delay detection mainly refers to the container's Running time less than the configured InitialDelaySeconds returning directly
if int32(time.Since(c.State.Running.StartedAt.Time).Seconds()) < w.spec.InitialDelaySeconds { return true }
3.2.4 Executing probing logic
result, err := w.probeManager.prober.probe(w.probeType, w.pod, status, w.container, w.containerID) if err != nil { // Prober error, throw away the result. return true } switch result { case results.Success: ProberResults.With(w.proberResultsSuccessfulMetricLabels).Inc() case results.Failure: ProberResults.With(w.proberResultsFailedMetricLabels).Inc() default: ProberResults.With(w.proberResultsUnknownMetricLabels).Inc() }
3.2.5 Cumulative Probe Count
After the accumulated probe counts, it is determined whether the accumulated counts exceed the set threshold, and if they do not, no state changes are made
if w.lastResult == result { w.resultRun++ } else { w.lastResult = result w.resultRun = 1 } if (result == results.Failure && w.resultRun < int(w.spec.FailureThreshold)) || (result == results.Success && w.resultRun < int(w.spec.SuccessThreshold)) { // Success or failure is below threshold - leave the probe state unchanged. // Success or failure is below the threshold - keep the detector state unchanged. return true }
3.2.6 Modify detection state
If the probe state sends a change, the state needs to be saved first, and if the probe fails, the onHOld state needs to be modified to true to delay the probe and return the counter to 0
// This modifies the corresponding status information w.resultsManager.Set(w.containerID, result, w.pod) if (w.probeType == liveness || w.probeType == startup) && result == results.Failure { // Containers failed to run liveness/starup detection, they need to restart and stop detection until a new containerID is available // This is to reduce the chance of hitting #751, where running docker exec when the container stops may result in container state corruption w.onHold = true w.resultRun = 0 }
3.3 Detect Main Cycle Process
The main process simply answers the above detection process
func (w *worker) run() { // Construct a timer based on the probing cycle probeTickerPeriod := time.Duration(w.spec.PeriodSeconds) * time.Second // If kubelet restarted the probes could be started in rapid succession. // Let the worker wait for a random portion of tickerPeriod before probing. time.Sleep(time.Duration(rand.Float64() * float64(probeTickerPeriod))) probeTicker := time.NewTicker(probeTickerPeriod) defer func() { // Clean up. probeTicker.Stop() if !w.containerID.IsEmpty() { w.resultsManager.Remove(w.containerID) } w.probeManager.removeWorker(w.pod.UID, w.container.Name, w.probeType) ProberResults.Delete(w.proberResultsSuccessfulMetricLabels) ProberResults.Delete(w.proberResultsFailedMetricLabels) ProberResults.Delete(w.proberResultsUnknownMetricLabels) }() probeLoop: for w.doProbe() { // Wait for next probe tick. select { case <-w.stopCh: break probeLoop case <-probeTicker.C: // continue } } }
Get here today and talk about the implementation of proberManager tomorrow. Share the forwarding, even if you support me, you're ready to start
>Microsignal: baxiaoshi2020  >Focus on bulletin numbers to read more source analysis articles
>Focus on bulletin numbers to read more source analysis articles  >More articles www.sreguide.com
>This article is a multi-article blog platform OpenWrite Release
>More articles www.sreguide.com
>This article is a multi-article blog platform OpenWrite Release