Look at the effect first




MTCNN
Since the MTCNN algorithm came out in 2016, the industry has become very popular. Recently, I tried to reproduce the paper code.
Subject thought
Cascade network
**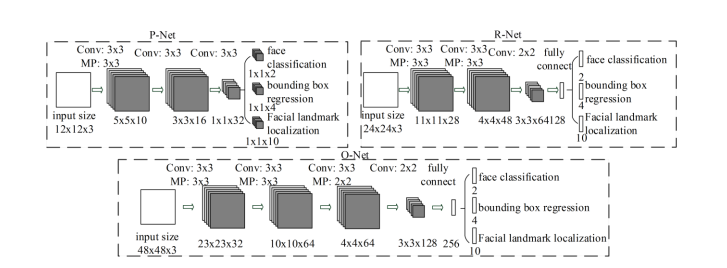
This paper belongs to a multi task cascade convolutional neural network, as shown in the figure, which uses P, R and O networks for detection.
Algorithm steps:
- Send the data to the p network, pre select some boxes, and generate the characteristic diagram
- Pass the preselected box in the p network into the R network for further filtering
- Transfer the preselected box in R network to O network for further filtering
- O network for final judgment and output face frame.

The above steps are implemented under the general framework of image pyramid. In order to realize face detection at different scales, the image pyramid algorithm is used to transfer faces at different scales into the network. Although this may improve the accuracy of the model, it also leads to an increase in the number of model operations.
P network:
Since the P network does not know how many faces a picture contains, the full convolution network is used to receive pictures of any size, the number of channels is used as the output feature number, the image pyramid is used to scale the picture (the shortest side length is greater than 12), and the convolution kernel step size is set to 1, which does not miss any possibility.
The 12x12 large core is used to determine the minimum face detected by the network. Cut a picture of the same size in a fixed size box (output fixed).
The convolution network is used to cut 12x12 pictures. The feature extraction of multi-layer small convolution kernel neural network is equivalent to large core single-layer neural network (the same receptive field). It has stronger abstraction ability, finer feature extraction, fewer parameters and faster network operation. The offset is used as the training loss, which makes the network calculation more convenient;.
Different loss functions are set for different tasks to enhance the pertinence of learning. Add facial features tasks, increase the complexity of e-learning tasks, and clarify the direction of e-learning. Each additional loss will improve the ability of neural network feature extraction and promote the optimization of network model.
R network:
The feature extraction of multi-layer small convolution kernel neural network is equivalent to large core single-layer neural network (the same receptive field).
Since the input is a 24 x 24 fixed size picture, the output can use full connection to extract features (the same as using convolution kernel to extract features here).
O network:
The feature extraction of multi-layer small convolution kernel neural network is equivalent to large core single-layer neural network (the same receptive field).
Since the input is a 48 x 28 fixed size picture, the output can use full connection to extract features (the same as using convolution kernel to extract features here).
image pyramid
There will be multiple targets in a picture, and the sizes of the targets are different. The model can not detect some too small or too large targets, so it is necessary to emphasize some multi-scale information. MTCNN The zoom factor for the image in is 0.703 about.
In addition, we have to mention two algorithms, IOU and NMS
IOU algorithm
Sample requirements for data set produced by MTCNN:
IOU range sample type label
0 ~ 0.3 non human face confidence is 0 (not involved in calculating offset loss)
0.3 ~ 0.4 landmarks (buffer zone to prevent misjudgment)
0.4 ~ 0.65 Part face confidence is 2 (does not participate in the calculation of confidence loss)
0.65 ~ 1 face confidence is 1
IoU is a standard for measuring the accuracy of detecting corresponding objects in a specific data set. IoU is a simple measurement standard. As long as it is a task to obtain a bounding box in the output, IoU can be used for measurement. In order to use IoU to measure objects of any size and shape, we need to mark the approximate range of the object to be detected in the training set image. That is, the a priori box.
In other words, this standard is used to measure the correlation between reality and prediction. The higher the correlation, the higher the value.
Fastercnn also proposed that the similar frame is similar to the linear transformation relationship. Using this, it is easier to learn the mapping relationship between the a priori frame and the actual frame than the frame of the direct learning target.
iou formula
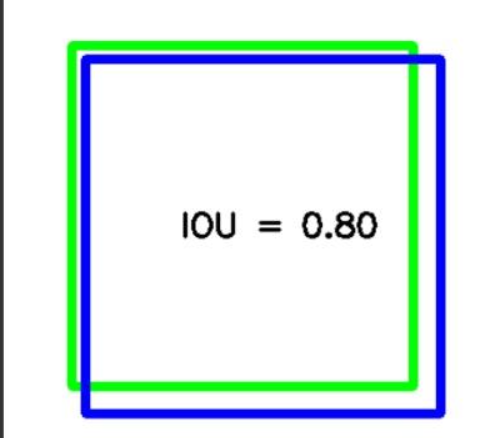
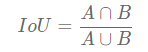
The larger the IOU, the greater the degree of overlap
def iou(box,boxes,isMin=False):
box_area = (box[3]-box[1])*(box[2]-box[0])
boxes_area = (boxes[:,3]-boxes[:,1])*(boxes[:,2]-boxes[:,0])
xx1 = np.maximum(box[0],boxes[:,0])
yy1 = np.maximum(box[1],boxes[:,1])
xx2 = np.minimum(box[2],boxes[:,2])
yy2 = np.minimum(box[3],boxes[:,3])
w = np.maximum(0, (xx2-xx1))
h = np.maximum(0,(yy2-yy1))
area =w*h
if isMin:
return np.true_divide(area,np.minimum(box_area,boxes_area))
else:
return np.true_divide(area,box_area+boxes_area-area)
nms algorithm

-The direct problem is to solve the problem of multiple output boxes
- Select the box with the maximum confidence
- The remaining frames are iou intersected and compared with the maximum confidence frame
- Filter the boxes whose iou is greater than a certain threshold, so that a large number of duplicate boxes can be removed
The code implementation is as follows:
def nms(boxes, thresh=0.3, isMin = False):
#When the length of the box is 0 (to prevent the program from reporting errors due to defects)
if boxes.shape[0] == 0:
return np.array([])
#When the length of the box is not 0
#Sort according to confidence: [x1,y1,x2,y2,C]
_boxes = boxes[(-boxes[:, 4]).argsort()] # #According to the confidence "from large to small", the default is from small to large (add a symbol to reverse the order)
#Create an empty list to hold the remaining boxes
r_boxes = []
# Compare 1st boxes with other boxes, and stop when the length is less than or equal to 1 (compared with len(_boxes)-1 time)
while _boxes.shape[0] > 1: #shape[0] is equivalent to shape(0), representing the number (dimension) of boxes on the 0 axis
#Take out the first box
a_box = _boxes[0]
#Remove the remaining boxes
b_boxes = _boxes[1:]
#Add 1st boxes to the list
r_boxes.append(a_box) ##Add a box for each cycle
# print(iou(a_box, b_boxes))
#Compare IOU S and keep the boxes that meet the threshold conditions
index = np.where(iou(a_box, b_boxes,isMin) < thresh) #Keep the suggestion box whose threshold is less than 0.3 and return the index of the reserved box
_boxes = b_boxes[index] #Cycle control conditions; Take out the suggestion box whose threshold is less than 0.3
if _boxes.shape[0] > 0: ##For the last time, only 1st matches or only one match is used in the result, if the number of boxes is greater than 1; ★ here_ The calls from boxes are in the while x loop. This judgment condition can be placed inside and outside the loop (only outside the function class can produce a local effect on)
r_boxes.append(_boxes[0]) #Add this box to the list
#Stack assembled as a matrix:: stack the data in the list on the 0 axis (row direction)
return np.stack(r_boxes)
After the above, the basic knowledge has been completed, and the practical operation code is left:
Network model code implementation:
Here I implemented the modification:
- BN is used to facilitate the faster convergence of the training model.
- The maximum pooling in each model is transformed into the method of convolution step size = 2 (the amount of data is basically sufficient, so there is no need to worry about over fitting, but this will increase the amount of calculation). The effect is really much better.
from torch import nn
import torch
class PNet(nn.Module):
def __init__(self):
super(PNet,self).__init__()
self.name = "pNet"
self.pre_layer = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=10,kernel_size=(3,3),stride=(1,1),padding=(1,1)), # conv1
nn.PReLU(),
# prelu1
nn.Conv2d(in_channels=10,out_channels=10,kernel_size=(3,3),stride=(2,2)),
nn.Conv2d(10,16,kernel_size=(3,3),stride=(1,1)), # conv2
nn.PReLU(), # prelu2
nn.Conv2d(16,32,kernel_size=(3,3),stride=(1,1)), # conv3
nn.PReLU() # prelu3
)
self.conv4_1 = nn.Conv2d(32,1,kernel_size=(1,1),stride=(1,1))
self.conv4_2 = nn.Conv2d(32,4,kernel_size=(1,1),stride=(1,1))
def forward(self, x):
x = self.pre_layer(x)
cond = torch.sigmoid(self.conv4_1(x)) # The confidence is activated with sigmoid (when BCEloos is used, it must be activated with sigmoid first)
offset = self.conv4_2(x) # The offset does not need to be activated and is output as is
return cond,offset
# R network
class RNet(nn.Module):
def __init__(self):
super(RNet,self).__init__()
self.name = "RNet"
self.pre_layer = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=28, kernel_size=(3,3),stride=(1,1),padding=(1,1)), # conv1
nn.BatchNorm2d(28),
nn.PReLU(), # prelu1
nn.Conv2d(in_channels=28, out_channels=28, kernel_size=(3, 3), stride=(2, 2)),
nn.BatchNorm2d(28),
nn.PReLU(),
# pool1
nn.Conv2d(28, 48, kernel_size=(3,3),stride=(1,1)), # conv2
nn.BatchNorm2d(48),
nn.PReLU(), # prelu2
nn.Conv2d(in_channels=48, out_channels=48, kernel_size=(3, 3), stride=(2, 2)),
nn.BatchNorm2d(48),
nn.PReLU(),
nn.Conv2d(48, 64, kernel_size=(2,2), stride=(1,1)), # conv3
nn.BatchNorm2d(64),
nn.PReLU() # prelu3
)
self.conv4 = nn.Linear(64*3*3,128) # conv4
self.prelu4 = nn.PReLU() # prelu4
#detetion
self.conv5_1 = nn.Linear(128,1)
#bounding box regression
self.conv5_2 = nn.Linear(128, 4)
def forward(self, x):
#backend
x = self.pre_layer(x)
x = x.view(x.size(0),-1)
x = self.conv4(x)
x = self.prelu4(x)
#detection
label = torch.sigmoid(self.conv5_1(x)) # Confidence
offset = self.conv5_2(x) # Offset
return label,offset
# O network
class ONet(nn.Module):
def __init__(self):
super(ONet,self).__init__()
self.name = "oNet"
# backend
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=(3,3), stride=(1,1),padding=(1,1)), # conv1
nn.BatchNorm2d(32),
nn.PReLU(), # prelu1
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(3, 3), stride=(2, 2)),
nn.BatchNorm2d(32),
nn.PReLU(),
nn.Conv2d(32, 64,kernel_size=(3,3), stride=(1,1)), # conv2
nn.BatchNorm2d(64),
nn.PReLU(), # prelu2
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(2, 2)),
nn.BatchNorm2d(64),
nn.PReLU(), # prelu2
nn.Conv2d(64, 64, kernel_size=(3,3), stride=(1,1)), # conv3
nn.BatchNorm2d(64),
nn.PReLU(), # prelu3
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(2, 2), stride=(2, 2)),
nn.BatchNorm2d(64),
nn.PReLU(), # prelu3
nn.Conv2d(64, 128,kernel_size=(2,2), stride=(1,1)), # conv4
nn.PReLU(), # prelu4
)
self.conv5 = nn.Linear(128 * 3 * 3, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
def forward(self, x):
# backend
x = self.pre_layer(x)
x = x.reshape(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
label = torch.sigmoid(self.conv6_1(x)) # Confidence
offset = self.conv6_2(x) # Offset
return label, offset
if __name__ == '__main__':
x = torch.randn(2,3,12,12)
x2 = torch.randn(2,3,24,24)
x3 = torch.randn(2,3,48,48)
model1 = PNet()
print(model1(x)[0].shape)
print(model1(x)[1].shape)
model2 = RNet()
print(model2(x2)[0].shape)
print(model2(x2)[1].shape)
model3 = ONet()
print(model3(x3)[0].shape)
print(model3(x3)[1].shape)
print(model1)
print(model2)
print(model3)
print(list(model1.pre_layer[0].weight))
Data conversion code: here are the data celeba and widerface in the paper
First, put the box and landmarks in the celeba data together
landmarks_path = r"F:\CelebA\Anno\list_landmarks_align_celeba.txt"
bbox_path = r"F:\CelebA\Anno\list_bbox_celeba.txt"
save_path = "anno.txt"
with open(landmarks_path,"r") as f:
landmarks = f.readlines()
with open(bbox_path,"r") as f:
bbox = f.readlines()
with open(save_path,"w") as f:
for i,(line1,line2) in enumerate(zip(bbox,landmarks)):
if i<1:
f.write(line1)
elif i==1:
strs = line1.strip()+" "+ line2
f.write(strs)
# f.write(line2)
else:
strs = line1.strip().split()+line2.strip().split()[1:]
strs = " ".join(strs)+"\n"
f.write(strs)
import os
import traceback
import numpy as np
from PIL import Image, ImageDraw
from tools import utils
class GenerateData():
def __init__(self, anno_src=r"anno.txt",
imgs_path=r"F:\CelebA\Img\img_celeba\img_celeba",
save_path="D:\DataSet"
):
self.anno_src = anno_src
self.imgs_path = imgs_path
self.save_path = save_path
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
def run(self, size=12):
print("gen %i image" % size) # %i: Decimal placeholder
for face_size in [size]:
# "Sample picture" storage path -- image
positive_image_dir = os.path.join(self.save_path, str(face_size), "positive") # Tertiary file path
negative_image_dir = os.path.join(self.save_path, str(face_size), "negative")
part_image_dir = os.path.join(self.save_path, str(face_size), "part")
print(positive_image_dir, negative_image_dir, part_image_dir)
for dir_path in [positive_image_dir, negative_image_dir, part_image_dir]:
if not os.path.exists(dir_path): # If the file does not exist, the file path is created
os.makedirs(dir_path)
# "Sample label" storage path -- text
positive_anno_filename = os.path.join(self.save_path, str(face_size), "positive.txt") # Creating a positive sample txt file
negative_anno_filename = os.path.join(self.save_path, str(face_size), "negative.txt")
part_anno_filename = os.path.join(self.save_path, str(face_size), "part.txt")
# Initial count value: name the file
positive_count = 0 # Counter initial value
negative_count = 0
part_count = 0
# For all file operations, it's best to try to prevent program errors from running away
try:
positive_anno_file = open(positive_anno_filename, "w") # Open txt document in write mode
negative_anno_file = open(negative_anno_filename, "w")
part_anno_file = open(part_anno_filename, "w")
for i, line in enumerate(open(self.anno_src)): # Give me all the information
if i < 2:
continue # When i is less than 2, continue reading the file readlines
# print(i,line)
try:
# print(line)
strs = line.strip().split(" ") # strip removes spaces on both sides
# print(strs)
# print(strs)
image_filename = strs[0].strip()
# print(image_filename)
image_file = os.path.join(self.imgs_path, image_filename) # Create file absolute path
with Image.open(image_file) as img:
img_w, img_h = img.size
x1 = float(strs[1].strip()) # Take 2nd values, remove the spaces on both sides, and then transfer to float type
y1 = float(strs[2].strip())
w = float(strs[3].strip())
h = float(strs[4].strip())
x2 = float(x1 + w)
y2 = float(y1 + h)
px1 = float(strs[5].strip()) # Human facial features
py1 = float(strs[6].strip())
px2 = float(strs[7].strip())
py2 = float(strs[8].strip())
px3 = float(strs[9].strip())
py3 = float(strs[10].strip())
px4 = float(strs[11].strip())
py4 = float(strs[12].strip())
px5 = float(strs[13].strip())
py5 = float(strs[14].strip())
# Filter fields to remove unqualified coordinates
if max(w, h) < 40 or x1 < 0 or y1 < 0 or w < 0 or h < 0:
continue
# The annotation is not standard: offset the face frame appropriately ★
x1 = int(x1 + w * 0.12) # The original coordinates are offset appropriately: 0.15 times of the face frame
y1 = int(y1 + h * 0.1)
x2 = int(x1 + w * 0.9)
y2 = int(y1 + h * 0.85)
w = int(x2 - x1) # The actual width of the offset box
h = int(y2 - y1)
boxes = [[x1, y1, x2, y2]] # Four coordinate points in the upper left corner and the lower right corner; The two-dimensional box has the concept of batch
# draw = ImageDraw.Draw(img)
# draw.rectangle(boxes[0],)
# img.show()
# Calculate the center position of the face: the center position of the frame
cx = x1 + w / 2
cy = y1 + h / 2
# Double the number of positive samples and partial samples to randomly offset the center point of the picture
for _ in range(2): # Each cycle 5 times, draw five frames and pull them out
# Make the center point of the face offset a little
w_ = np.random.randint(-w * 0.1, w * 0.1) # Lateral offset range of box: 20% to the left and right
h_ = np.random.randint(-h * 0.1, h * 0.1)
cx_ = cx + w_
cy_ = cy + h_
# Let the face form a square (12 * 12, 24 * 24, 48 * 48), and let the coordinates deviate a little
side_len = np.random.randint(int(min(w, h) * 0.8), np.ceil(1.25 * max(w, h)))
# Range of random number of side length offset; ceil is the smallest integer greater than or equal to the value (rounded up); Original 0.8
x1_ = np.max(cx_ - side_len / 2, 0) # Coordinate point random offset
y1_ = np.max(cy_ - side_len / 2, 0)
x2_ = x1_ + side_len
y2_ = y1_ + side_len
crop_box = np.array([x1_, y1_, x2_, y2_]) # Offset new box
# draw.rectangle(list(crop_box))
# Calculate the offset value of the coordinates
offset_x1 = (x1 - x1_) / side_len # Offset △ δ= (x1-x1_)/side_len; The width of the new frame;
offset_y1 = (y1 - y1_) / side_len
offset_x2 = (x2 - x2_) / side_len
offset_y2 = (y2 - y2_) / side_len
offset_px1 = (px1 - x1_) / side_len # Offset value of human facial features
offset_py1 = (py1 - y1_) / side_len
offset_px2 = (px2 - x1_) / side_len
offset_py2 = (py2 - y1_) / side_len
offset_px3 = (px3 - x1_) / side_len
offset_py3 = (py3 - y1_) / side_len
offset_px4 = (px4 - x1_) / side_len
offset_py4 = (py4 - y1_) / side_len
offset_px5 = (px5 - x1_) / side_len
offset_py5 = (py5 - y1_) / side_len
# Cut the picture and zoom
face_crop = img.crop(crop_box) # "Matting", clip out the framed image
face_resize = face_crop.resize((face_size, face_size),
Image.ANTIALIAS) # ★ zoom according to the face size ("pixel matrix size"): 12 / 24 / 48; Coordinates are not scaled
iou = utils.iou(crop_box, np.array(boxes))[0] # The extracted box and the original box calculate the IOU
if iou > 0.65: # Positive samples; Originally 0.65
positive_anno_file.write(
"positive/{0}.jpg {1} {2} {3} {4} {5} {6} {7} {8} {9} {10} {11} {12} {13} {14} {15}\n".format(
positive_count, 1, offset_x1, offset_y1,
offset_x2, offset_y2, offset_px1, offset_py1, offset_px2, offset_py2,
offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5))
positive_anno_file.flush() # flush: writes data from the cache to a file
face_resize.save(
os.path.join(positive_image_dir, "{0}.jpg".format(positive_count))) # preservation
positive_count += 1
elif iou > 0.4: # Partial samples; Originally 0.4
part_anno_file.write(
"part/{0}.jpg {1} {2} {3} {4} {5} {6} {7} {8} {9} {10} {11} {12} {13} {14} {15}\n".format(
part_count, 2, offset_x1, offset_y1, offset_x2,
offset_y2, offset_px1, offset_py1, offset_px2, offset_py2, offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5)) # Write txt file
part_anno_file.flush()
face_resize.save(os.path.join(part_image_dir, "{0}.jpg".format(part_count)))
part_count += 1
elif iou < 0.29: # ★ few negative samples are generated in this way; Originally 0.3
negative_anno_file.write(
"negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count, 0))
negative_anno_file.flush()
face_resize.save(os.path.join(negative_image_dir, "{0}.jpg".format(negative_count)))
negative_count += 1
# Generate negative samples
_boxes = np.array(boxes)
for i in range(2): # The quantity is generally the same as before
side_len = np.random.randint(face_size, min(img_w, img_h) / 2)
x_ = np.random.randint(0, img_w - side_len)
y_ = np.random.randint(0, img_h - side_len)
crop_box = np.array([x_, y_, x_ + side_len, y_ + side_len])
if np.max(utils.iou(crop_box, _boxes)) < 0.29: # Judge after adding IOU: keep the part less than 0.3; Originally 0.3
face_crop = img.crop(crop_box) # Matting
face_resize = face_crop.resize((face_size, face_size),
Image.ANTIALIAS) # ANTIALIAS: smooth, antialiasing
negative_anno_file.write(
"negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count, 0))
negative_anno_file.flush()
face_resize.save(os.path.join(negative_image_dir, "{0}.jpg".format(negative_count)))
negative_count += 1
except Exception as e:
print(e)
traceback.print_exc()
except Exception as e:
print(e)
# Close write file
finally:
positive_anno_file.close() # Close the positive sample
negative_anno_file.close()
part_anno_file.close()
if __name__ == '__main__':
data = GenerateData()
data.run(size=12)
data.run(size=24)
data.run(size=48)
widerface data code
import os
import traceback
import numpy as np
from PIL import Image, ImageDraw
from tools import utils
def gentxt():
imgs_path = r"F:\widerface\WIDER_train\images"
bbox_txt = r"F:\widerface\wider_face_split\wider_face_train_bbx_gt.txt"
with open(bbox_txt,"r") as f:
data = f.readlines()
empty_dict = {}
temp_name = None
for i,line in enumerate(data):
# i = i.strip()
if line.strip().endswith("jpg"):
line = line.strip()
empty_dict[line] = []
temp_name = line
else:
line = line.strip()
if len(line)>10:
# print(line.split()[:4])
empty_dict[temp_name].append(line.split()[:4])
with open("wider_anno.txt","w") as f:
for key in empty_dict.keys():
values = empty_dict[key]
f.write(f"{key} ")
for value in values:
# print(value)
# print(" ".join(value))
f.write(" ".join(value))
f.write(" ")
f.write("\n")
# exit()
# f.write(f"{key}",)
class GenerateData():
def __init__(self, anno_src=r"wider_anno.txt",
imgs_path=r"F:\widerface\WIDER_train\images",
save_path="D:\DataSet\wider"
):
self.anno_src = anno_src
self.imgs_path = imgs_path
self.save_path = save_path
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
def run(self, size=12):
print("gen %i image" % size) # %i: Decimal placeholder
for face_size in [size]:
# "Sample picture" storage path -- image
positive_image_dir = os.path.join(self.save_path, str(face_size), "positive") # Tertiary file path
negative_image_dir = os.path.join(self.save_path, str(face_size), "negative")
part_image_dir = os.path.join(self.save_path, str(face_size), "part")
print(positive_image_dir, negative_image_dir, part_image_dir)
for dir_path in [positive_image_dir, negative_image_dir, part_image_dir]:
if not os.path.exists(dir_path): # If the file does not exist, the file path is created
os.makedirs(dir_path)
# "Sample label" storage path -- text
positive_anno_filename = os.path.join(self.save_path, str(face_size), "positive.txt") # Creating a positive sample txt file
negative_anno_filename = os.path.join(self.save_path, str(face_size), "negative.txt")
part_anno_filename = os.path.join(self.save_path, str(face_size), "part.txt")
# Initial count value: name the file
positive_count = 0 # Counter initial value
negative_count = 0
part_count = 0
# For all file operations, it's best to try to prevent program errors from running away
try:
positive_anno_file = open(positive_anno_filename, "w") # Open txt document in write mode
negative_anno_file = open(negative_anno_filename, "w")
part_anno_file = open(part_anno_filename, "w")
for i, line in enumerate(open(self.anno_src)): # Give me all the information
try:
# print(line)
strs = line.strip().split(" ") # strip removes spaces on both sides
# print(strs)
# print(strs)
image_filename = strs[0].strip()
# print(image_filename)
image_file = os.path.join(self.imgs_path, image_filename) # Create file absolute path
values = list(map(float, strs[1:]))
all_boxes = []
for index in range(0, len(values), 4):
all_boxes.append(values[index:index + 4])
with Image.open(image_file) as img:
for one_box in all_boxes:
img_w, img_h = img.size
x1 = one_box[0]# float(strs[1].strip()) # Take 2nd values, remove the spaces on both sides, and then transfer to float type
y1 = one_box[1] # float(strs[2].strip())
w =one_box[2]# float(strs[3].strip())
h =one_box[3]# float(strs[4].strip())
x2 = float(x1 + w)
y2 = float(y1 + h)
# draw = ImageDraw.Draw(img)
# draw.rectangle([x1,y1,x2,y2])
# img.show()
# exit()
px1 = 0#float(strs[5].strip()) # Human facial features
py1 = 0#float(strs[6].strip())
px2 =0# float(strs[7].strip())
py2 =0# float(strs[8].strip())
px3 =0# float(strs[9].strip())
py3 =0# float(strs[10].strip())
px4 =0# float(strs[11].strip())
py4 =0# float(strs[12].strip())
px5 =0# float(strs[13].strip())
py5 =0# float(strs[14].strip())
# Filter fields to remove unqualified coordinates
if max(w, h) < 40 or x1 < 0 or y1 < 0 or w < 0 or h < 0:
continue
# x1 = int(x1 + w) # The original coordinates are offset appropriately: 0.15 times of the face frame
# y1 = int(y1 + h)
# x2 = int(x1 + w)
# y2 = int(y1 + h)
# w = int(x2 - x1) # The actual width of the offset box
# h = int(y2 - y1)
boxes = [[x1, y1, x2, y2]] # Four coordinate points in the upper left corner and the lower right corner; The two-dimensional box has the concept of batch
# print(boxes)
# # exit()
# Calculate the center position of the face: the center position of the frame
cx = x1 + w / 2
cy = y1 + h / 2
# Double the number of positive samples and partial samples to randomly offset the center point of the picture
for _ in range(1): # Each cycle 5 times, draw five frames and pull them out
# Make the center point of the face offset a little
# print(-w * 0.2, w * 0.2)
w_ = np.random.randint(-w * 0.2, w * 0.2) # Lateral offset range of box: 20% to the left and right
h_ = np.random.randint(-h * 0.2, h * 0.2)
cx_ = cx + w_
cy_ = cy + h_
# Let the face form a square (12 * 12, 24 * 24, 48 * 48), and let the coordinates deviate a little
side_len = np.random.randint(int(min(w, h) * 0.8), np.ceil(1.25 * max(w, h)))
# Range of random number of side length offset; ceil is the smallest integer greater than or equal to the value (rounded up); Original 0.8
x1_ = np.max(cx_ - side_len / 2, 0) # Coordinate point random offset
y1_ = np.max(cy_ - side_len / 2, 0)
x2_ = x1_ + side_len
y2_ = y1_ + side_len
crop_box = np.array([x1_, y1_, x2_, y2_]) # Offset new box
# draw.rectangle(list(crop_box))
# img.show()
# exit()
# Calculate the offset value of the coordinates
offset_x1 = (x1 - x1_) / side_len # Offset △ δ= (x1-x1_)/side_len; The width of the new frame;
offset_y1 = (y1 - y1_) / side_len
offset_x2 = (x2 - x2_) / side_len
offset_y2 = (y2 - y2_) / side_len
offset_px1 =0# (px1 - x1_) / side_len # Offset value of human facial features
offset_py1 =0 # (py1 - y1_) / side_len
offset_px2 =0 #(px2 - x1_) / side_len
offset_py2 =0# (py2 - y1_) / side_len
offset_px3 =0# (px3 - x1_) / side_len
offset_py3 = 0#(py3 - y1_) / side_len
offset_px4 =0# (px4 - x1_) / side_len
offset_py4 = 0#(py4 - y1_) / side_len
offset_px5 = 0#(px5 - x1_) / side_len
offset_py5 = 0#(py5 - y1_) / side_len
# Cut the picture and zoom
face_crop = img.crop(crop_box) # "Matting", clip out the framed image
face_resize = face_crop.resize((face_size, face_size),
Image.ANTIALIAS) # ★ zoom according to the face size ("pixel matrix size"): 12 / 24 / 48; Coordinates are not scaled
iou = utils.iou(crop_box, np.array(boxes))[0] # The extracted box and the original box calculate the IOU
if iou > 0.65: # Positive samples; Originally 0.65
positive_anno_file.write(
"positive/{0}.jpg {1} {2} {3} {4} {5} {6} {7} {8} {9} {10} {11} {12} {13} {14} {15}\n".format(
positive_count, 1, offset_x1, offset_y1,
offset_x2, offset_y2, offset_px1, offset_py1, offset_px2, offset_py2,
offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5))
positive_anno_file.flush() # flush: writes data from the cache to a file
face_resize.save(
os.path.join(positive_image_dir, "{0}.jpg".format(positive_count))) # preservation
positive_count += 1
elif iou > 0.4: # Partial samples; Originally 0.4
part_anno_file.write(
"part/{0}.jpg {1} {2} {3} {4} {5} {6} {7} {8} {9} {10} {11} {12} {13} {14} {15}\n".format(
part_count, 2, offset_x1, offset_y1, offset_x2,
offset_y2, offset_px1, offset_py1, offset_px2, offset_py2, offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5)) # Write txt file
part_anno_file.flush()
face_resize.save(os.path.join(part_image_dir, "{0}.jpg".format(part_count)))
part_count += 1
elif iou < 0.29: # ★ few negative samples are generated in this way; Originally 0.3
negative_anno_file.write(
"negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count, 0))
negative_anno_file.flush()
face_resize.save(os.path.join(negative_image_dir, "{0}.jpg".format(negative_count)))
negative_count += 1
# # Generate negative samples
# _boxes = np.array(boxes)
# for i in range(2): # The quantity is generally the same as before
# side_len = np.random.randint(face_size, min(img_w, img_h) / 2)
# x_ = np.random.randint(0, img_w - side_len)
# y_ = np.random.randint(0, img_h - side_len)
# crop_box = np.array([x_, y_, x_ + side_len, y_ + side_len])
#
# if np.max(utils.iou(crop_box, _boxes)) < 0.29: # Judge after adding IOU: keep the part less than 0.3; Originally 0.3
# face_crop = img.crop(crop_box) # Matting
# face_resize = face_crop.resize((face_size, face_size),
# Image.ANTIALIAS) # ANTIALIAS: smooth, antialiasing
#
# negative_anno_file.write(
# "negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count, 0))
# negative_anno_file.flush()
# face_resize.save(os.path.join(negative_image_dir, "{0}.jpg".format(negative_count)))
# negative_count += 1
except Exception as e:
print(e)
traceback.print_exc()
except Exception as e:
print(e)
# Close write file
finally:
positive_anno_file.close() # Close the positive sample
negative_anno_file.close()
part_anno_file.close()
if __name__ == '__main__':
data = GenerateData()
data.run(size=12)
data.run(size=24)
data.run(size=48)
Data code
- With data enhancement,
- During the training process, it is found that the image will treat some hands or vegetables as adult heads, which is really terrible. This is because the people's hands block their heads in celeba data, most of them have yellow skin, and some of them are dark. Therefore, color transformation is used to enhance contrast and color.
- During the training process, it is found that the side face is not easy to recognize, because image mirroring is used to flip the side face for many data sets, and the effect is good. solve the problem
# Create dataset
from torch.utils.data import Dataset
import os
import numpy as np
import torch
from PIL import Image
from torchvision import transforms
tf1 = transforms.Compose(
[transforms.ColorJitter(brightness=0.5),
transforms.RandomHorizontalFlip(p=0.5)
]
)
tf2 = transforms.Compose(
[transforms.ColorJitter(contrast=0.5),
transforms.RandomHorizontalFlip(p=0.5)
]
)
tf3 = transforms.Compose(
[transforms.ColorJitter(saturation=0.5),
transforms.RandomHorizontalFlip(p=0.5)
]
)
tf4 = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5)
])
tf = transforms.RandomChoice(
[
tf1,tf2,tf3,tf4
]
)
# data set
class FaceDataset(Dataset):
def __init__(self,path_1=r"D:\DataSet",path_2="D:\DataSet\wider",size=12,tf=tf):
super(FaceDataset, self).__init__()
self.dataset = []
self.size = size
for path in [path_1,path_2]:
self.base_path_1 = path
self.path = os.path.join(self.base_path_1,str(self.size))
for txt in ["positive.txt","negative.txt","part.txt"]:
with open(os.path.join(self.path,txt),"r") as f:
data = f.readlines()
for line in data:
line = line.strip().split()
img_path = os.path.join(self.path,line[0])
benkdata = " ".join(line[1:])
self.dataset.append([img_path,benkdata])
self.tf = tf
def __len__(self):
return len(self.dataset) # Data set length
def __getitem__(self, index): # get data
img_path,strs = self.dataset[index]
strs = strs.strip().split(" ") # Take a piece of data, remove the front and back strings, and then divide it by spaces
#Label: confidence + offset
cond = torch.Tensor([int(strs[0])]) # [] don't lose it, otherwise you specify shape
offset = torch.Tensor([float(strs[1]),float(strs[2]),float(strs[3]),float(strs[4])])
#Sample: img_data
# img_path = os.path.join(self.path,strs[0]) # Picture absolute path
img = Image.open(img_path)
img = self.tf(img)
# img.show()
img = np.array(img) / 255. - 0.5
img_data = torch.tensor(img,dtype=torch.float32) # Turn on -- > array -- > normalized de averaging -- > to tensor
img_data = img_data.permute(2,0,1) # CWH
# print(img_data.shape) # WHC
# a = img_data.permute(2,0,1) #Axis transformation
# print(a.shape) #[3, 48, 48]: CWH
return img_data,cond,offset
# test
if __name__ == '__main__':
dataset = FaceDataset(size=12)
print(dataset[0])
print(len(dataset))
###Network training
Training code
The training method of cosine annealing method is added, and smoothL1 regression coordinate points are used to classify the loss of BCELoss
p network training
# Create Trainer - to train three networks
import os
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
from torch.utils.data import DataLoader
import torch
from torch import nn
import torch.optim as optim
from sampling import FaceDataset # Import dataset
from models import models
from torch.utils.tensorboard import SummaryWriter
# Create trainer
class Trainer:
def __init__(self, net, save_path, dataset_size, isCuda=True,SummaryWriter_path=r"run"): # Network, parameter saving path, training data path, cuda acceleration is True
self.net = net
self.save_path = save_path
self.dataset_path = dataset_size
self.isCuda = isCuda
# print(self.net.name)
# self.net.name
summaryWriter_path = os.path.join(SummaryWriter_path,self.net.name)
if not os.path.exists(summaryWriter_path):
os.makedirs(summaryWriter_path)
length = len(os.listdir(summaryWriter_path))
path_name = os.path.join(summaryWriter_path, "exp" + str(length))
os.makedirs(path_name)
self.summaryWriter = SummaryWriter(path_name)
if self.isCuda: # By default, there is an else after it
self.net.cuda() # Speed up the network
# Create loss function
# Confidence loss
self.cls_loss_fn = nn.BCELoss() # ★ two class cross entropy loss function is a special case of multi class cross entropy loss; Before using BCELoss, you must activate with sigmoid, and before using CrossEntropyLoss, you must use the softmax function
# Offset loss
self.offset_loss_fn = nn.SmoothL1Loss()
# Create optimizer
self.optimizer = optim.SGD(self.net.parameters(),lr=0.0001,momentum=0.9)
# Resume network training - load model parameters and continue training
if os.path.exists(self.save_path): # If the file exists, continue training
net.load_state_dict(torch.load(self.save_path),strict=False)
# training method
def train(self,epochs=1000):
faceDataset = FaceDataset(size=self.dataset_path) # data set
dataloader = DataLoader(faceDataset, batch_size=256, shuffle=True, num_workers=4,drop_last=True) # Data Loader
#num_workers=4: there are 4 threads loading data (loading data takes time to prevent vacancy); drop_last: when it is True, it means to prevent error reporting due to insufficient batches.
scheduler = CosineAnnealingWarmRestarts(self.optimizer, T_0=5, T_mult=1)
self.best_loss = 1
for epoch in range(epochs):
for i, (img_data_, category_, offset_) in enumerate(dataloader): # Sample, confidence, offset
if self.isCuda: # cuda reads the data into the video memory (first through the memory); No cuda in memory, cuda in video memory
img_data_ = img_data_.cuda() # [512, 3, 12, 12]
category_ = category_.cuda() # 512, 1]
offset_ = offset_.cuda() # [512, 4]
# Network output
_output_category, _output_offset = self.net(img_data_) # Output confidence, offset
# print(_output_category.shape) # [512, 1, 1, 1]
# print(_output_offset.shape) # [512, 4, 1, 1]
output_category = _output_category.reshape(-1, 1) # [512,1]
output_offset = _output_offset.reshape(-1, 4) # [512,4]
# output_landmark = _output_landmark.view(-1, 10)
# Calculate the loss of classification - confidence
category_mask = torch.lt(category_, 2) # Mask the positive samples (1) and negative samples (0) with confidence less than 2; ★ some samples (2) do not participate in loss calculation; 1 is returned if it meets the conditions, and 0 is returned if it does not meet the conditions
category = torch.masked_select(category_, category_mask) # For the selection mask with confidence less than 2 in the label, return the qualified results
output_category = torch.masked_select(output_category, category_mask) # The predicted "tag" is masked to return qualified results
cls_loss = self.cls_loss_fn(output_category, category) # Loss of confidence
# Calculate the loss offset of bound regression
offset_mask = torch.gt(category_, 0) # Mask tags with confidence greater than 0; ★ negative samples do not participate in the calculation, and negative samples have no offset; [512,1]
offset_index = torch.nonzero(offset_mask)[:, 0] # Select the index of non negative samples; [244]
offset = offset_[offset_index] # Offset in label; [244,4]
output_offset = output_offset[offset_index] # Output offset; [244,4]
offset_loss = self.offset_loss_fn(output_offset, offset) # Offset loss
#Total loss
loss = cls_loss + offset_loss
# Back propagation, network optimization
self.optimizer.zero_grad() # Gradient before emptying
loss.backward() # Calculated gradient
self.optimizer.step() # Optimize network
#Output loss: loss -- > GPU -- > cup (variable) - > tensor -- > array
print("epoch=",epoch ,"loss:", loss.cpu().data.numpy(), " cls_loss:", cls_loss.cpu().data.numpy(), " offset_loss",
offset_loss.cpu().data.numpy())
self.summaryWriter.add_scalars("loss", {"loss": loss.cpu().data.numpy(),
"cls_loss": cls_loss.cpu().data.numpy(),
"offser_loss": offset_loss.cpu().data.numpy()},epoch)
# self.summaryWriter.add_histogram("pre_conv_layer1",self.net.pre_layer[0].weight,epoch)
# self.summaryWriter.add_histogram("pre_conv_layer2",self.net.pre_layer[3].weight,epoch)
# self.summaryWriter.add_histogram("pre_conv_layer3",self.net.pre_layer[5].weight,epoch)
# preservation
if i%5==0:
if i%500==0:
torch.save(self.net.state_dict(), self.save_path) # state_dict save network parameters, save_ The path parameter saves the path
print("save success") # Save once per round; It's best to make a judgment: save it once when the loss decreases
if loss.cpu().data.numpy()<self.best_loss:
self.best_loss = loss.cpu().data.numpy()
torch.save(self.net.state_dict(), self.save_path) # state_dict save network parameters, save_ The path parameter saves the path
print("save success")# Save once per round; It's best to make a judgment: save it once when the loss decreases
scheduler.step()
if __name__ == '__main__':
net = models.PNet()
trainer = Trainer(net, 'pnet.pt', dataset_size=12) # Network, save parameters and training data; Create trainer
trainer.train() # Call the train method in the trainer
# net = models.RNet()
# trainer = Trainer(net, 'rnet.pt', r"D:\DataSet\24") # Network, save parameters and training data; Create trainer
# trainer.train()
# net = models.ONet()
# trainer = Trainer(net, 'onet.pt', r"D:\DataSet\48") # Network, save parameters and training data; Create trainer
# trainer.train()
R network training
# Create Trainer - to train three networks
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
from torch.utils.data import DataLoader
import torch
from torch import nn
import torch.optim as optim
from sampling import FaceDataset # Import dataset
from models import models
from torch.utils.tensorboard import SummaryWriter
# Create trainer
class Trainer:
def __init__(self, net, save_path, dataset_path, isCuda=True,
SummaryWriter_path=r"run"): # Network, parameter saving path, training data path, cuda acceleration is True
self.net = net
self.save_path = save_path
self.dataset_path = dataset_path
self.isCuda = isCuda
# print(self.net.name)
# self.net.name
summaryWriter_path = os.path.join(SummaryWriter_path, self.net.name)
if not os.path.exists(summaryWriter_path):
os.makedirs(summaryWriter_path)
length = len(os.listdir(summaryWriter_path))
path_name = os.path.join(summaryWriter_path, "exp" + str(length))
os.makedirs(path_name)
self.summaryWriter = SummaryWriter(path_name)
if self.isCuda: # By default, there is an else after it
self.net.cuda() # Speed up the network
# Create loss function
# Confidence loss
self.cls_loss_fn = nn.BCELoss() # ★ two class cross entropy loss function is a special case of multi class cross entropy loss; Before using BCELoss, you must activate with sigmoid, and before using CrossEntropyLoss, you must use the softmax function
# Offset loss
self.offset_loss_fn = nn.SmoothL1Loss()
# Create optimizer
self.optimizer = optim.SGD(self.net.parameters(),lr=0.0001,momentum=0.8)
# Resume network training - load model parameters and continue training
if os.path.exists(self.save_path): # If the file exists, continue training
net.load_state_dict(torch.load(self.save_path),strict=False)
# training method
def train(self):
faceDataset = FaceDataset(size=self.dataset_path) # data set
dataloader = DataLoader(faceDataset, batch_size=128, shuffle=True, num_workers=2, drop_last=True) # Data Loader
# num_workers=4: there are 4 threads loading data (loading data takes time to prevent vacancy); drop_last: when it is True, it means to prevent error reporting due to insufficient batches.
self.best_loss = None
while True:
for i, (img_data_, category_, offset_) in enumerate(dataloader): # Sample, confidence, offset
if self.isCuda: # cuda reads the data into the video memory (first through the memory); No cuda in memory, cuda in video memory
img_data_ = img_data_.cuda() # [512, 3, 12, 12]
category_ = category_.cuda() # 512, 1]
offset_ = offset_.cuda() # [512, 4]
# Network output
_output_category, _output_offset = self.net(img_data_) # Output confidence, offset
# print(_output_category.shape) # [512, 1, 1, 1]
# print(_output_offset.shape) # [512, 4, 1, 1]
output_category = _output_category.view(-1, 1) # [512,1]
output_offset = _output_offset.view(-1, 4) # [512,4]
# output_landmark = _output_landmark.view(-1, 10)
# Calculate the loss of classification - confidence
category_mask = torch.lt(category_, 2) # Mask the positive samples (1) and negative samples (0) with confidence less than 2; ★ some samples (2) do not participate in loss calculation; 1 is returned if it meets the conditions, and 0 is returned if it does not meet the conditions
category = torch.masked_select(category_, category_mask) # For the selection mask with confidence less than 2 in the label, return the qualified results
output_category = torch.masked_select(output_category, category_mask) # The predicted "tag" is masked to return qualified results
cls_loss = self.cls_loss_fn(output_category, category) # Loss of confidence
# Calculate the loss offset of bound regression
offset_mask = torch.gt(category_, 0) # Mask tags with confidence greater than 0; ★ negative samples do not participate in the calculation, and negative samples have no offset; [512,1]
offset_index = torch.nonzero(offset_mask)[:, 0] # Select the index of non negative samples; [244]
offset = offset_[offset_index] # Offset in label; [244,4]
output_offset = output_offset[offset_index] # Output offset; [244,4]
offset_loss = self.offset_loss_fn(output_offset, offset) # Offset loss
# Total loss
loss = 0.5*cls_loss + offset_loss
if i == 0:
self.best_loss = loss.cpu().data.numpy()
# Back propagation, network optimization
self.optimizer.zero_grad() # Gradient before emptying
loss.backward() # Calculated gradient
self.optimizer.step() # Optimize network
# Output loss: loss -- > GPU -- > cup (variable) - > tensor -- > array
print("i=", i, "loss:", loss.cpu().data.numpy(), " cls_loss:", cls_loss.cpu().data.numpy(),
" offset_loss",
offset_loss.cpu().data.numpy())
self.summaryWriter.add_scalars("loss", {"loss": loss.cpu().data.numpy(),
"cls_loss": cls_loss.cpu().data.numpy(),
"offser_loss": offset_loss.cpu().data.numpy()},i)
# self.summaryWriter.add_histogram("pre_conv_layer1", self.net.pre_layer[0].weight,i)
# self.summaryWriter.add_histogram("pre_conv_layer2", self.net.pre_layer[3].weight,i)
# self.summaryWriter.add_histogram("pre_conv_layer3", self.net.pre_layer[6].weight,i)
# preservation
if (i + 1) % 100 == 0 or self.best_loss>loss.cpu().data.numpy():
self.best_loss = loss.cpu().data.numpy()
torch.save(self.net.state_dict(), self.save_path) # state_dict save network parameters, save_ The path parameter saves the path
print("save success") # Save once per round; It's best to make a judgment: save it once when the loss decreases
if __name__ == '__main__':
net = models.RNet()
trainer = Trainer(net, 'rnet.pt', 24) # Network, save parameters and training data; Create trainer
trainer.train()
O network training
# Create Trainer - to train three networks
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
from torch.utils.data import DataLoader
import torch
from torch import nn
import torch.optim as optim
from sampling import FaceDataset # Import dataset
from models import models
from torch.utils.tensorboard import SummaryWriter
# Create trainer
class Trainer:
def __init__(self, net, save_path, dataset_path, isCuda=True,
SummaryWriter_path=r"run"): # Network, parameter saving path, training data path, cuda acceleration is True
self.net = net
self.save_path = save_path
self.dataset_path = dataset_path
self.isCuda = isCuda
# print(self.net.name)
# self.net.name
summaryWriter_path = os.path.join(SummaryWriter_path, self.net.name)
if not os.path.exists(summaryWriter_path):
os.makedirs(summaryWriter_path)
length = len(os.listdir(summaryWriter_path))
path_name = os.path.join(summaryWriter_path, "exp" + str(length))
os.makedirs(path_name)
self.summaryWriter = SummaryWriter(path_name)
if self.isCuda: # By default, there is an else after it
self.net.cuda() # Speed up the network
# Create loss function
# Confidence loss
self.cls_loss_fn = nn.BCELoss() # ★ two class cross entropy loss function is a special case of multi class cross entropy loss; Before using BCELoss, you must activate with sigmoid, and before using CrossEntropyLoss, you must use the softmax function
# Offset loss
self.offset_loss_fn = nn.SmoothL1Loss()
# Create optimizer
self.optimizer = optim.SGD(self.net.parameters(),lr=0.0001,momentum=0.8)
# Resume network training - load model parameters and continue training
if os.path.exists(self.save_path): # If the file exists, continue training
net.load_state_dict(torch.load(self.save_path),strict=False)
# training method
def train(self):
faceDataset = FaceDataset(size=self.dataset_path) # data set
dataloader = DataLoader(faceDataset, batch_size=128, shuffle=True, num_workers=2, drop_last=True) # Data Loader
# num_workers=4: there are 4 threads loading data (loading data takes time to prevent vacancy); drop_last: when it is True, it means to prevent error reporting due to insufficient batches.
self.best_loss = None
while True:
for i, (img_data_, category_, offset_) in enumerate(dataloader): # Sample, confidence, offset
if self.isCuda: # cuda reads the data into the video memory (first through the memory); No cuda in memory, cuda in video memory
img_data_ = img_data_.cuda() # [512, 3, 12, 12]
category_ = category_.cuda() # 512, 1]
offset_ = offset_.cuda() # [512, 4]
# Network output
_output_category, _output_offset = self.net(img_data_) # Output confidence, offset
# print(_output_category.shape) # [512, 1, 1, 1]
# print(_output_offset.shape) # [512, 4, 1, 1]
output_category = _output_category.view(-1, 1) # [512,1]
output_offset = _output_offset.view(-1, 4) # [512,4]
# output_landmark = _output_landmark.view(-1, 10)
# Calculate the loss of classification - confidence
category_mask = torch.lt(category_, 2) # Mask the positive samples (1) and negative samples (0) with confidence less than 2; ★ some samples (2) do not participate in loss calculation; 1 is returned if it meets the conditions, and 0 is returned if it does not meet the conditions
category = torch.masked_select(category_, category_mask) # For the selection mask with confidence less than 2 in the label, return the qualified results
output_category = torch.masked_select(output_category, category_mask) # The predicted "tag" is masked to return qualified results
cls_loss = self.cls_loss_fn(output_category, category) # Loss of confidence
# Calculate the loss offset of bound regression
offset_mask = torch.gt(category_, 0) # Mask tags with confidence greater than 0; ★ negative samples do not participate in the calculation, and negative samples have no offset; [512,1]
offset_index = torch.nonzero(offset_mask)[:, 0] # Select the index of non negative samples; [244]
offset = offset_[offset_index] # Offset in label; [244,4]
output_offset = output_offset[offset_index] # Output offset; [244,4]
offset_loss = self.offset_loss_fn(output_offset, offset) # Offset loss
# Total loss
loss = 0.5*cls_loss + offset_loss
if i == 0:
self.best_loss = loss.cpu().data.numpy()
# Back propagation, network optimization
self.optimizer.zero_grad() # Gradient before emptying
loss.backward() # Calculated gradient
self.optimizer.step() # Optimize network
# Output loss: loss -- > GPU -- > cup (variable) - > tensor -- > array
print("i=", i, "loss:", loss.cpu().data.numpy(), " cls_loss:", cls_loss.cpu().data.numpy(),
" offset_loss",
offset_loss.cpu().data.numpy())
self.summaryWriter.add_scalars("loss", {"loss": loss.cpu().data.numpy(),
"cls_loss": cls_loss.cpu().data.numpy(),
"offser_loss": offset_loss.cpu().data.numpy()},i)
# self.summaryWriter.add_histogram("pre_conv_layer1", self.net.pre_layer[0].weight,i)
# self.summaryWriter.add_histogram("pre_conv_layer2", self.net.pre_layer[3].weight,i)
# self.summaryWriter.add_histogram("pre_conv_layer3", self.net.pre_layer[6].weight,i)
# preservation
if (i + 1) % 100 == 0 or self.best_loss>loss.cpu().data.numpy():
self.best_loss = loss.cpu().data.numpy()
torch.save(self.net.state_dict(), self.save_path) # state_dict save network parameters, save_ The path parameter saves the path
print("save success") # Save once per round; It's best to make a judgment: save it once when the loss decreases
if __name__ == '__main__':
net = models.RNet()
trainer = Trainer(net, 'rnet.pt', 24) # Network, save parameters and training data; Create trainer
trainer.train()
Detection code
- The reason why p network adopts full convolution method is that it can input pictures of different scales and use the output characteristic map for inverse calculation
import os
import time
import cv2
from tools import utils
import numpy as np
import torch
from PIL import Image, ImageDraw
from torchvision import transforms
from models import models
class Detector():
def __init__(self,
pnet_param="pnet.pt",
rnet_param="rnet.pt",
onet_param="onet.pt",
isCuda=True,
# Network tuning
p_cls=0.6, # Originally 0.6
p_nms=0.5, # Originally 0.5
r_cls=0.6, # Originally 0.6
r_nms=0.5, # Originally 0.5
# R network:
o_cls=0.99, # Originally 0.97
o_nms=0.6, # Originally 0.7
):
self.isCuda = isCuda
self.pnet = models.PNet() # Create instance variables to instantiate P network
self.rnet = models.RNet()
self.onet = models.ONet()
if self.isCuda:
self.pnet.cuda()
self.rnet.cuda()
self.onet.cuda()
self.pnet.load_state_dict(torch.load(pnet_param)) # Load the trained weight into the P-network
self.rnet.load_state_dict(torch.load(rnet_param))
self.onet.load_state_dict(torch.load(onet_param))
self.pnet.eval() # If there is BN (batch normalization) in the training network, the eval method should be called, and the BN and dropout methods should not be used
self.rnet.eval()
self.onet.eval()
self.p_cls = p_cls # Originally 0.6
self.p_nms = p_nms # Originally 0.5
self.r_cls = r_cls # Originally 0.6
self.r_nms = r_nms # Originally 0.5
# R network:
self.o_cls = o_cls # Originally 0.97
self.o_nms = o_nms # Originally 0.7
self.__image_transform = transforms.Compose(
[
transforms.ToTensor()
]
)
def detect(self, image):
# P network detection ----- 1st
start_time = time.time()
pnet_boxes = self.__pnet_detect(image) # Call__ pnet_detect function (defined later)
if pnet_boxes.shape[0]==0:
return np.array([])
end_time = time.time()
t_pnet = end_time - start_time # Time difference occupied by P network
# print(pnet_boxes.shape)
# return pnet_boxes # p network detected box
start_time = time.time()
rnet_boxes = self.__rnet_detect(image,pnet_boxes) # Call__ pnet_detect function (defined later)
if rnet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time()
t_rnet = end_time - start_time # r time difference occupied by the network
# return rnet_boxes # r network detected box
onet_boxes = self.__onet_detect(image,rnet_boxes) # Call__ pnet_detect function (defined later)
if rnet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time()
t_onet = end_time - start_time # Time difference occupied by P network
# return onet_boxes # p network detected box
# III. total time of network detection
t_sum = t_pnet + t_rnet + t_onet
print("total:{0} pnet:{1} rnet:{2} onet:{3}".format(t_sum, t_pnet, t_rnet, t_onet))
return onet_boxes
def __pnet_detect(self, image): # ★ p the network is all convolution, independent of the input picture size, and can output pictures of any shape
boxes = [] # Create an empty list and receive qualified suggestion boxes
img = image
w, h = img.size
min_side_len = min(w, h) # Gets the minimum side length of the picture
scale = 1 # Initial scaling (no scaling at 1): get pictures of different resolutions
while min_side_len > 12: # Stop until you zoom to 12 or less
img_data = self.__image_transform(img) # Convert image array to tensor
if self.isCuda:
img_data = img_data.cuda() # Send the picture tensor to cuda for acceleration
img_data.unsqueeze_(0) # Increase dimension in "batch" (more than one picture is transmitted during test)
# print("img_data:",img_data.shape) # [1, 3, 416, 500]: C=3,W=416,H=500
_cls, _offest = self.pnet(img_data) # ★★ return multiple confidence levels and offsets
# print("_cls",_cls.shape) # [1, 1, 203, 245]:NCWH: channel and size of characteristic graph of block convolution ★
# print("_offest", _offest.shape) # [1, 4, 203, 245]:NCWH
cls = _cls[0][0].cpu().data # [203, 245]: size of block convolution characteristic graph: W,H
offest = _offest[0].cpu().data # [4, 203, 245] # Channel and size of block convolution characteristic graph: C,W,H
idxs = torch.nonzero(torch.gt(cls, self.p_cls)) # ★ box index with confidence greater than 0.6; Output the P network to see if there is a face that is not framed. If there is no face framed, it means that the network is not well trained; Or the confidence is high or low
# print(idxs)
for idx in idxs: # Add qualified boxes according to the index; cls[idx[0], idx[1]] values in confidence: idx[0] row index, idx[1] column index
boxes.append(self.__box(idx, offest, cls[idx[0], idx[1]], scale)) # ★ call box inverse function_ Box (reverse the box on the feature map to the original map), and leave the box greater than 0.6;
scale *= 0.7 # Scaling pictures: loop control conditions
_w = int(w * scale) # New width
_h = int(h * scale)
img = img.resize((_w, _h)) # The picture is scaled according to the scaled width and height
min_side_len = min(_w, _h) # Regain minimum width and height
return utils.nms(np.array(boxes), self.p_nms) # Return to the box, and the original threshold is given to p_nms=0.5 (IOU is 0.5). Keep some boxes with IOU less than 0.5 as far as possible. If the network training is good, the value can be lower
# Feature inverse calculation: restore the regression quantity to the original graph, and inverse the calculated result to the original graph suggestion box according to the feature graph
def __box(self, start_index, offset, cls, scale, stride=2, side_len=12): # p the network pooling step is 2
_x1 = (start_index[1].float() * stride) / scale # The index is multiplied by the step size and divided by the scaling scale; ★ during feature reverse calculation, "row index, index exchange", originally [0]
_y1 = (start_index[0].float() * stride) / scale
_x2 = (start_index[1].float() * stride + side_len) / scale
_y2 = (start_index[0].float() * stride + side_len) / scale
ow = _x2 - _x1 # The width and height of the suggestion box in the area where the face is located
oh = _y2 - _y1
_offset = offset[:, start_index[0], start_index[1]] # Find the corresponding offset △ according to the idxs row index and column index δ: [x1,y1,x2,y2]
x1 = _x1 + ow * _offset[0] # Calculate the position of the actual frame according to the offset, x1=x1_+w*△ δ; For raw samples: △ δ= x1-x1_/w
y1 = _y1 + oh * _offset[1]
x2 = _x2 + ow * _offset[2]
y2 = _y2 + oh * _offset[3]
return [x1, y1, x2, y2, cls] # Formal box: returns 4 coordinate points and 1 offset
def __rnet_detect(self, image, pnet_boxes):
_img_dataset = [] # Create an empty list to store matting
_pnet_boxes = utils.convert_to_square(pnet_boxes) # ★ for the box output to the p network, find out the center point, expand it into a "square" along both sides of the maximum side length, and then cut the picture
for _box in _pnet_boxes: # ★ traverse each box, each box returns 4 coordinate points, matting, zooming, data type conversion and adding list
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
img = image.crop((_x1, _y1, _x2, _y2)) # Matting according to 4 coordinate points
img = img.resize((24, 24)) # Put and shrink in solid size
img_data = self.__image_transform(img) # Convert image array to tensor
_img_dataset.append(img_data)
img_dataset = torch.stack(_img_dataset) # Stack stack (0 axis by default). This is equivalent to data type conversion. See example 2 ★
if self.isCuda:
img_dataset = img_dataset.cuda() # cuda acceleration for image data
_cls, _offset = self.rnet(img_dataset) # ★★ send 24 * 24 pictures to the network for another screening
cls = _cls.cpu().data.numpy() # Put the data on the gpu on the cpu and convert it into a numpy array
offset = _offset.cpu().data.numpy()
# print("r_cls:",cls.shape) # (11, 1): the P network generates 11 boxes
# print("r_offset:", offset.shape) # (11, 4)
boxes = [] # The boxes to be left by the R network are saved in boxes
idxs, _ = np.where(
cls > self.r_cls) # The original confidence of 0.6 is low. Sometimes many boxes are useless (they can be printed out for observation), so they can be adjusted higher appropriately; Index with idxs confidence frame greater than 0.6; ★ return idxs: index on axis 0 [0,1],: The index [0,0] on axis 1 jointly determines the element position. See example 3
for idx in idxs: # Traverse the qualified boxes according to the index; The index on axis 1 is exactly the qualified confidence index (the index on axis 0 is not used here)
_box = _pnet_boxes[idx]
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
ow = _x2 - _x1 # Width of datum frame
oh = _y2 - _y1
x1 = _x1 + ow * offset[idx][0] # Coordinate point of actual frame
y1 = _y1 + oh * offset[idx][1]
x2 = _x2 + ow * offset[idx][2]
y2 = _y2 + oh * offset[idx][3]
boxes.append([x1, y1, x2, y2, cls[idx][0]]) # Return 4 coordinate points and confidence
return utils.nms(np.array(boxes), self.r_nms) # Original r_nms is 0.5 (0.5 to minor), and the above 0.6 to major; Boxes less than 0.5 are retained
# Create O network detection function
def __onet_detect(self, image, rnet_boxes):
_img_dataset = [] # Create a list to store matting r
_rnet_boxes = utils.convert_to_square(rnet_boxes) # For the output box of r network, find out the center point and expand it into a "square" along both sides of the maximum side length
for _box in _rnet_boxes: # Traverse the filtered box of R network, calculate coordinates, matting, scaling, data type conversion, add list and stack
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
img = image.crop((_x1, _y1, _x2, _y2)) # "Matting" according to coordinate points
img = img.resize((48, 48))
img_data = self.__image_transform(img) # Turn the extracted graph into a tensor
_img_dataset.append(img_data)
img_dataset = torch.stack(_img_dataset) # Stack, which is equivalent to data format conversion. See example 2
if self.isCuda:
img_dataset = img_dataset.cuda()
_cls, _offset = self.onet(img_dataset)
cls = _cls.cpu().data.numpy() # (1, 1)
offset = _offset.cpu().data.numpy() # (1, 4)
boxes = [] # Store o network calculation results
idxs, _ = np.where(
cls > self.o_cls) # Original o_cls of 0.97 is low. Finally, to reach the standard, the confidence level should reach 0.99999. Here, it can be written as 0.99998. In this way, it will be all faces; Leave a box with a confidence greater than 0.97; ★ return to index [0] on idxs:0 axis,: The index [0] on axis 1 jointly determines the element position, as shown in example 3
for idx in idxs: # Traverse the qualified boxes according to the index; The index on axis 1 is exactly the qualified confidence index (the index on axis 0 is not used here)
_box = _rnet_boxes[idx] # Take R network as the benchmark box
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
ow = _x2 - _x1 # The base width of the box. The box is "square", ow=oh
oh = _y2 - _y1
x1 = _x1 + ow * offset[idx][0] # O coordinates of the frame finally generated by the network; Raw sample, offset △ δ= x1-_x1/w*side_len
y1 = _y1 + oh * offset[idx][1]
x2 = _x2 + ow * offset[idx][2]
y2 = _y2 + oh * offset[idx][3]
boxes.append([x1, y1, x2, y2, cls[idx][0]]) # Returns 4 coordinate points and 1 confidence
return utils.nms(np.array(boxes), self.o_nms, isMin=True) # IOU with minimum area; Original o_ Boxes with NMS (IOU) less than 0.7 are retained
def detect(imgs_path="./test_images", save_path="./result_images",test_video=False):
if not os.path.exists(save_path):
os.makedirs(save_path)
if test_video:
# Multiple picture display
detector = Detector()
cap = cv2.VideoCapture('./test_video/Cai Xukun.mp4')
num = 0
while cap.isOpened():
ret,frame = cap.read()
if cv2.waitKey(25) & 0xFF == ord('q'):
break
image = Image.fromarray(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB))
print("-------------------")
boxes = detector.detect(image)
print("size:", image.size)
for box in boxes:
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
print(x1, y1, x2, y2)
print("conf:", box[4])
head = image.crop(image,[x1,y1,x2,y2])
head.save(f"./Cai Xukun photos/{num}.jpg")
num+=1
cv2.rectangle(frame, (x1, y1), (x2, y2), (0,0,255), 2)
cv2.imshow("res",frame)
cap.release()
cv2.destroyAllWindows()
else:
for img in os.listdir(imgs_path):
detector = Detector()
with Image.open(os.path.join(imgs_path, img)) as image:
print("-------------------")
boxes = detector.detect(image)
print("size:", image.size)
img_draw = ImageDraw.Draw(image)
for box in boxes:
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
print(x1, y1, x2, y2,"conf:", box[4])
# print("conf:", box[4])
img_draw.rectangle((x1, y1, x2, y2), outline="red")
image.show()
image.save(os.path.join(save_path, img))
if __name__ == '__main__':
detect()
summary
There are many problems in face detection:
-
In the first stage of MTCNN, the image pyramid will repeatedly call a very shallow P-NET network many times, resulting in data from memory COPY to video memory and from video memory COPY to memory. This COPY operation consumes a lot, even more time than the calculation itself.
-
The running speed of P network has a great impact on the whole model; R. O network matting file operation takes time; for loop serial time consuming; Hardware problems exacerbate the time-consuming model
Reason: image pyramid takes a lot of time, and Tensor and matrix are not used for inverse calculation; Matting is not completed with slices; Generally, the more advanced the language, the slower it will run.
Solution: adjust the zoom ratio according to the actual needs; Use tensor and matrix operation to optimize the code. -
When invoking the model, remember eval()
-
The best way to solve the problem is to add accurate data
-
Don't use ReLU here. The effect is not good. The loss of negative half axis will cause certain information loss.
Initial summary: if there are deficiencies, please ask for advice.
My direction target recognition, interested partners can communicate together
WX:
