Preface
Hashtable in JDK is a K-V container of thread-safe. Its principle of thread-safe is very simple. It adds synchronized keyword to all methods involved in the operation of the hash table for locking operation. This achieves thread safety, but is very inefficient.
//With synchronized acquisition of hashmap locks every time a method enters, contention conflicts occur in high concurrency situations. public synchronized V get(Object key) { Entry tab[] = table; int hash = hash(key); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null; }
Concurrent HashMap uses the design of segmented lock. Concurrent contention only exists on each segment. There is no competition between different segments, which improves the concurrent access efficiency of the hashmap. However, due to the segment design of Concurrent HashMap, some operations that need to scan all segments, such as size(), are more complex to implement, and can not guarantee strong consistency, which needs attention in some cases. Because the implementation of Concurrent HashMap is different in different JDK versions, this paper is based on jdk1.7 source code. We will analyze the implementation principle of Concurrent HashMap through its source code.
Composition of Concurrent HashMap
Looking at the source code, we can understand the basic composition of the data structure through the member variables of Concurrent HashMap.
final int segmentMask;//As a mask for finding segments, the first bit s are used to select segments final int segmentShift; final Segment<K,V>[] segments;//Each segment is a hashtable
Concurrent HashMap has an array of segments inside it, and each segment is a hashtable. Since Segments inherit from ReentrantLock, they are locks themselves. Locking each Segment is to call its own acquire() method. The basic components of Segment are as follows:
static final class Segment<K,V> extends ReentrantLock implements Serializable { transient volatile HashEntry<K,V>[] table;//The k-v data stored in Concurrent HashMap exists here transient int count;//HashEntry counts in this segment (such as put/remove/replace/clear) transient int modCount;//Number of modifications to this segment final float loadFactor;//Load factor of hashtable . . . . . . . . . }
HashEntry is the bottom data structure that ultimately stores each pair of k-v. Its structure is:
static final class HashEntry<K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; }
value is volatile and can be visible in a multi-threaded environment, so it can be read directly without locking.
The overall data structure of Concurrent HashMap is shown in the figure.
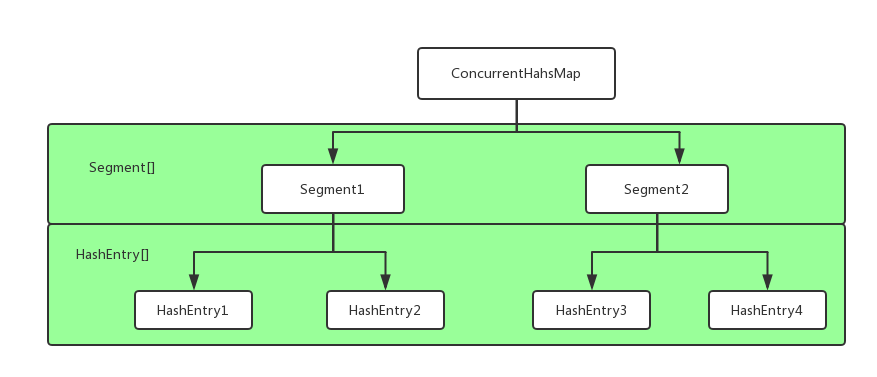
Concurrent HashMap Source Code Analysis
In the preface of this article, we said `Concurrent hashmap improves the concurrent access efficiency of hashmap through segmented lock technology'. Then we will illustrate how Concurrent hashmap achieves this under the condition of thread security through the methods of get/set/remove of Concurrent hashmap.
- Initialization of Concurrent HashMap
Conurrency Level is the estimated number of threads that will concurrently modify Concurrent HashMap. It can also be understood as the maximum number of threads that support concurrent access to Concurrent HashMap without contention for locks, i.e. the number of Segment s, i.e. the number of segmented locks, defaults to 16.//Load Factor is the load factor for each segment, concurrency Level is the estimated concurrent modification thread, defaulting to 16, so create 16 segments public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS;//Default 16 // Find power-of-two sizes best matching arguments int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } this.segmentShift = 32 - sshift; this.segmentMask = ssize - 1; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1; // create segments and segments[0] Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]);//Initialize a segment Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; } - Create segmented locks
For example, the initialization of Concurrent HashMap above, Concurrent HashMap uses the delayed initialization mode, first only a new Segment, and the rest of the Segment is initialized only when it is in use. Each put operation, after locating the Segment where the key is located, it will first determine whether the Segment is initialized or not. If not, a new Segment is created and the corresponding position of the Segment array is referenced by cyclic CAS.private Segment<K,V> ensureSegment(int k) { final Segment<K,V>[] ss = this.segments; long u = (k << SSHIFT) + SBASE; // raw offset Segment<K,V> seg; if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { Segment<K,V> proto = ss[0]; // use segment 0 as prototype int cap = proto.table.length; float lf = proto.loadFactor; int threshold = (int)(cap * lf); HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap]; if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck Segment<K,V> s = new Segment<K,V>(lf, threshold, tab); while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) break; } } } return seg; } - get()
The get method does not require a lock operation, because value in HashEntry is volatile, which guarantees visibility between threads. Because segments are non-volatile, the getObjectVolatile method of UNSAFE provides volatile reading semantics to traverse to obtain nodes on the corresponding list. However, unlocking may result in several modifications by other threads during traversal. val returned may be outdated data. This part is a reflection of the non-strong consistency of Concurrent HashMap. If there is a requirement for strong consistency, then only Hashtable or Collections. synchronized Map, which is the key through synchronization, can be used. Words are locked to provide a strongly consistent Map container. The containsKey operation is the same as get.public V get(Object key) { Segment<K,V> s; // manually integrate access methods to reduce overhead HashEntry<K,V>[] tab; int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;//u is the subscript of the key in the segments array, and you can locate which Segment the key is. if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { //(tab. length - 1) & h) Locate the subscript of key in the HashEntry array of Segment //Traverse the HashEntry list to find HashEntry elements that are consistent with the hash values of keys and keys for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; } - put/putIfAbsent/putAll operation
Data insertion operation, we can see here that Concurrent HashMap improves the processing capacity and throughput of Concurrent HashMap in high concurrent environment based on segment lock.//This method is the core of all put operations in Concurrent HashMap final V put(K key, int hash, V value, boolean onlyIfAbsent) { //First, try to lock (call the tryLock method of ReentrantLock to lock the current Segment instance) and find the same Node as the Key if it does not succeed, or a new one if it does not. The lock must be acquired on return. HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table;// int index = (tab.length - 1) & hash;//The insertion point of the current Node HashEntry<K,V> first = entryAt(tab, index);//Get the index element in tbale //Traversing the comparison node on the list with the same key modifies the corresponding value, but not at the end of the list. for (HashEntry<K,V> e = first;;) { if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) {//value is set only if key does not exist e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; //rehash when the number of elements in the current segment exceeds the threshold if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node);//Expansion beyond threshold else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; } } - size()/containsValue()
If the sum of modCount and count of all Segments is equal, and the number of HashEntry of Concurrent HashMap remains unchanged during this period, the value of count summation is returned directly, which is the size of Concurrent HashMap. If the sum of two modCounts is equal and always unequal, this attempt will be repeated. The default is two, and more than two times it is assumed that intensive operations (which affect the size of the Concurrent HashMap) are currently being performed on the Concurrent HashMap, so each Segment is forced to be locked, and then the previous counting operation is repeated, eventually returning the calculated Concurrent HashMap size. Therefore, the size of Concurrent HashMap returned by this implementation in multi-threaded environment is approximate and inaccurate, which requires trade-offs when using Concurrent HashMap. containsValue is similar to size operation principle.public int size() { // Try a few times to get accurate count. On failure due to // continuous async changes in table, resort to locking. final Segment<K,V>[] segments = this.segments; int size; boolean overflow; // true if size overflows 32 bits long sum; // sum of modCounts long last = 0L; // previous sum int retries = -1; // first iteration isn't retry try { for (;;) { if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } sum = 0L; size = 0; overflow = false; for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0) overflow = true; } } if (sum == last)//Modified Count and Equality before and after Judgment break; last = sum; } } finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; }summary
This is the source code implementation analysis of the important operation of Concurrent HashMap in jdk1.7. We can make the following judgment on Concurrent HashMap: - Through the design of segmented locks, the contention conflict of locks between different segments is reduced. Each segment is an independent hash table. This design improves the throughput of Concurrent HashMap and the concurrent access efficiency of hashmap.
- Value in HashEntry is volatile type, which makes the get method of Concurrent HashMap obtain value without lock operation and improves the efficiency of get. However, it should be noted that this also leads to the weak consistency problem of Concurrent HashMap. In the case of strong consistency requirement for get operation, other containers supporting strong consistency of map must be selected.
- The return value of operations such as size in multi-threaded environment is inaccurate and can only be approximated. It is suggested that size() should not be relied on in multi-threaded environment.
Reference resources
- Art of Java Concurrent Programming
- Concurrent HashMap Summary