Step 1: Cluster Planning

Step 2: set hosts
Step3: turn off the firewall
Step 4: turn off Selinux
Step5: Keyless login
Step 6: install jdk
#decompression tar -xvf jdk-8u131-linux-x64.tar.gz mv jdk1.8.0_131 /usr/local/jdk1.8 #Setting environment variables vim /etc/profile JAVA_HOME=/usr/local/jdk1.8/ JAVA_BIN=/usr/local/jdk1.8/bin JRE_HOME=/usr/local/jdk1.8/jre PATH=$PATH:/usr/local/jdk1.8/bin:/usr/local/jdk1.8/jre/bin CLASSPATH=/usr/local/jdk1.8/jre/lib:/usr/local/jdk1.8/lib:/usr/local/jdk1.8/jre/lib/charsets.jar
Step 7: install zookeeper
#download [root@sl-opencron src]# wget http://www-eu.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz #decompression [root@sl-opencron src]# tar -xvf zookeeper-3.4.10.tar.gz #The extracted directory mv to / usr/local / [root@sl-opencron src]# mv zookeeper-3.4.10 /usr/local/zookeeper
Step 7.1: configure zookeeper
cd /usr/local/zookeeper/conf/ #Name zoo ABCD sample.cfg (template configuration file) zoo.cfg mv zoo_sample.cfg zoo.cfg #Modify profile [root@sl-opencron conf]# vim zoo.cfg *********** *********** #Path customizable dataDir=/data/zookeeper server.1=139.162.53.29:2888:3888 server.2=139.162.53.146:2888:3888 server.3=139.162.8.37:2888:3888
Step 7.2: generate myid file
mkdir /data/zookeeper cd /data/zookeeper touch myid echo "1" >> myid //Note: cdh-1 myid is 1 cdh-2 myid is 2 cdh-3 myid is 3
Step 7.3: start the zookeeper cluster
Note: in CDH-1, cdh-2, cdh-3 respectively
cd /usr/local/zookeeper/bin ./zkServer.sh start
Step 8: install hadoop
#download wget http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz #decompression tar -xvf hadoop-2.7.6.tar.gz #The extracted directory is moved to / usr/local/ mv hadoop-2.7.6 /usr/local/hadoop #Enter hadoop directory cd /usr/local/hadoop #Create several directories [root@hadooop-master hadoop]# mkdir tmp dfs dfs/data dfs/name
Step 8.1: configure hadoop
vim core-site.xml <configuration> <!-- Appoint hdfs Of nameservice by ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1/</value> </property> <!-- Appoint hadoop Temporary folder --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <!--Appoint zookeeper address--> <property> <name>ha.zookeeper.quorum</name> <value>cdh-1:2181,cdh-2:2181,cdh-3:2181</value> </property> </configuration>
vim hdfs-site.xml <configuration> <!--Appoint hdfs Of nameservice by ns1,Need and core-site.xml Consistent in --> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <!-- ns1 Here are two NameNode,Each is nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <!-- nn1 Of RPC Mailing address --> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>cdh-4:9000</value> </property> <!-- nn1 Of http Mailing address --> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>cdh-4:50070</value> </property> <!-- nn2 Of RPC Mailing address --> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>cdh-5:9000</value> </property> <!-- nn2 Of http Mailing address --> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>cdh-5:50070</value> </property> <!-- Appoint NameNode The metadata of JournalNode Storage location on --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://cdh-1:8485;cdh-2:8485;cdh-3:8485/ns1</value> </property> <!-- Appoint JournalNode Where to store data on the local disk --> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/hadoop/dfs/data</value> </property> <!-- open NameNode Fail to switch actively --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- Fail to configure, switch the implementation mode actively --> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- Configure the isolation mechanism method. Multiple mechanisms are cut by line breaking, i.e. each mechanism temporarily uses one line--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- Use sshfence Isolation mechanism ssh No landfall --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- To configure sshfence Isolation mechanism timeout --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
vim yarn.site.xml <configuration> <!-- Site specific YARN configuration properties --> <!-- open RM High availability --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- Appoint RM Of cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster-rm</value> </property> <!-- Appoint RM Name --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- Assign separately RM Address --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>cdh-4</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>cdh-5</value> </property> <!-- Appoint zookeeper Cluster address --> <property> <name>yarn.resourcemanager.zk-address</name> <value>cdh-1:2181,cdh-2:2181,cdh-3:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
vim mapred-site.xml <configuration> <!-- Appoint mr The framework is yarn mode --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
vim slaves cdh-1 cdh-2 cdh-3
Step 8.2: synchronize to each server
rsync -av /usr/local/hadoop/etc/ cdh-1:/usr/local/hadoop/etc/ rsync -av /usr/local/hadoop/etc/ cdh-2:/usr/local/hadoop/etc/ rsync -av /usr/local/hadoop/etc/ cdh-3:/usr/local/hadoop/etc/ rsync -av /usr/local/hadoop/etc/ cdh-4:/usr/local/hadoop/etc/ rsync -av /usr/local/hadoop/etc/ cdh-5:/usr/local/hadoop/etc/
Step 9: start the journal node
Note: it is started in cdh-1, cdh-2 and cdh-3 respectively
cd /usr/local/hadoop/sbin/ ./hadoop-daemon.sh start journalnode
Step10: format HDFS
Note: operation in cdh-4
cd /usr/local/hadoop/bin/ ./hdfs namenode -format #Note: after formatting, you need to copy the tmp folder to cdh-5 (otherwise, the namenode of cdh-5 will not work) cd /usr/local/hadoop/ scp -r tmp/ cdh-5:/usr/local/hadoop/ VERSION 100% 207 222.7KB/s 00:00 fsimage_0000000000000000000.md5 100% 62 11.3KB/s 00:00 fsimage_0000000000000000000 100% 321 327.3KB/s 00:00 seen_txid 100% 2 1.4KB/s 00:00
Step11: format ZKFC
Note: operation in cdh-4
cd /usr/local/hadoop/bin/ ./hdfs zkfc -formatZK
Step 12: start yarn
Note: operation in cdh-4
cd /usr/local/hadoop/sbin/ ./start-yarn.sh
Step13: resource manager of cdh-5 needs to be started manually and separately
cd /usr/local/hadoop/sbin/ ./yarn-daemon.sh start resourcemanager
Step 14: view the cluster process
[root@cdh-1 ~]# jps 26754 QuorumPeerMain 22387 JournalNode 5286 Jps 4824 NodeManager 25752 DataNode [root@cdh-2 ~]# jps 4640 JournalNode 29520 QuorumPeerMain 5799 Jps 4839 DataNode 5642 NodeManager [root@cdh-3 ~]# jps 28738 JournalNode 28898 DataNode 29363 NodeManager 20836 QuorumPeerMain 29515 Jps [root@cdh-4 ~]# jps 21491 Jps 21334 NameNode 20167 DFSZKFailoverController 21033 ResourceManager [root@cdh-5 ~]# jps 20403 ResourceManager 20280 NameNode 20523 Jps 19693 DFSZKFailoverController
Step 15: testing highly available clusters
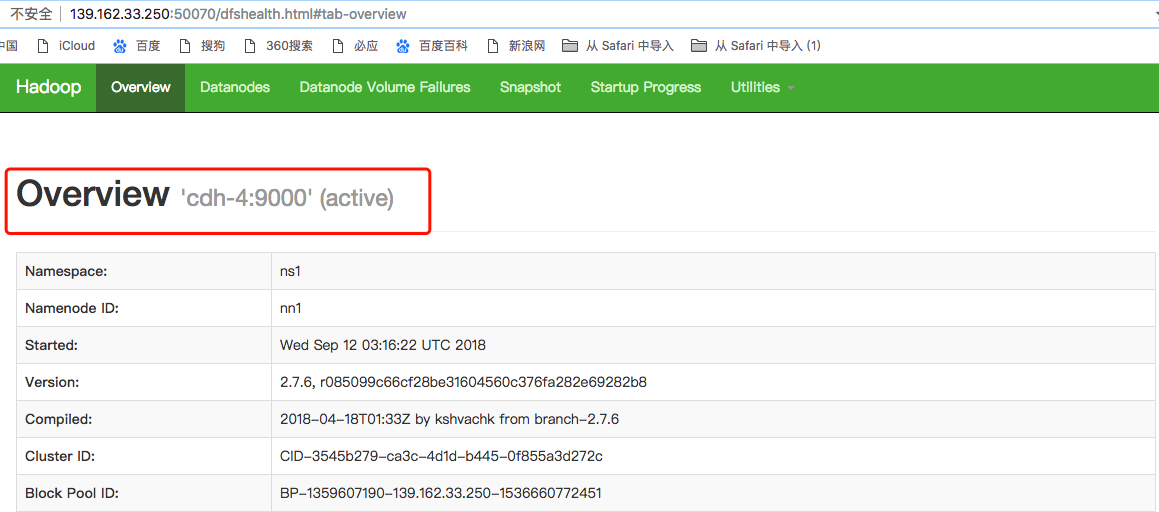
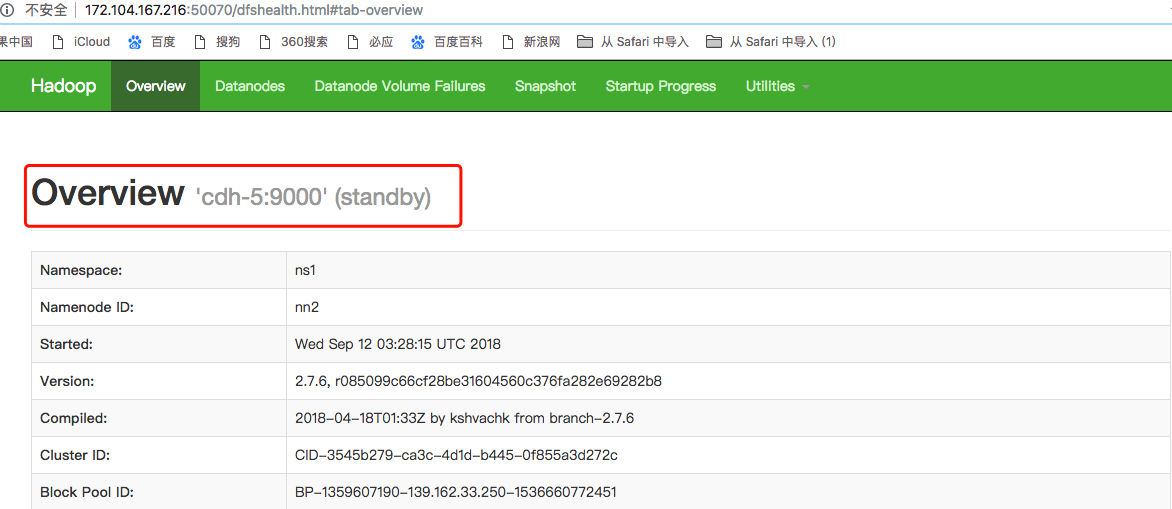
Note: as shown in the figure, the status of cdh-5 is active, and the status of cdh-4 is standby
Step 15.1: stop cdh-5 namenode
[root@cdh-5 hadoop]# cd /usr/local/hadoop/sbin/ [root@cdh-5 sbin]# ./hadoop-daemon.sh stop namenode stopping namenode [root@cdh-5 sbin]# ./hadoop-daemon.sh start namenode
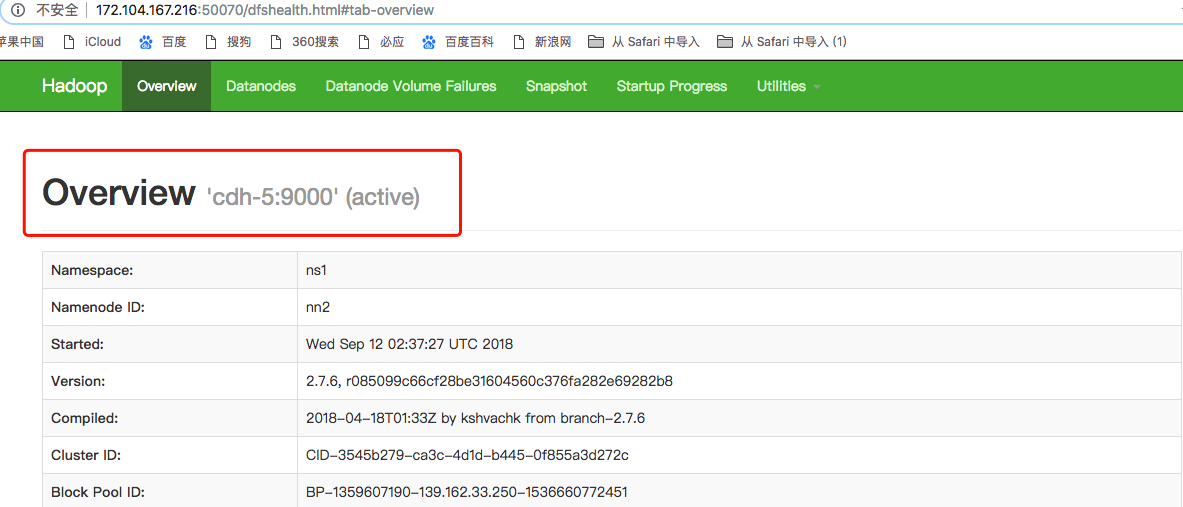
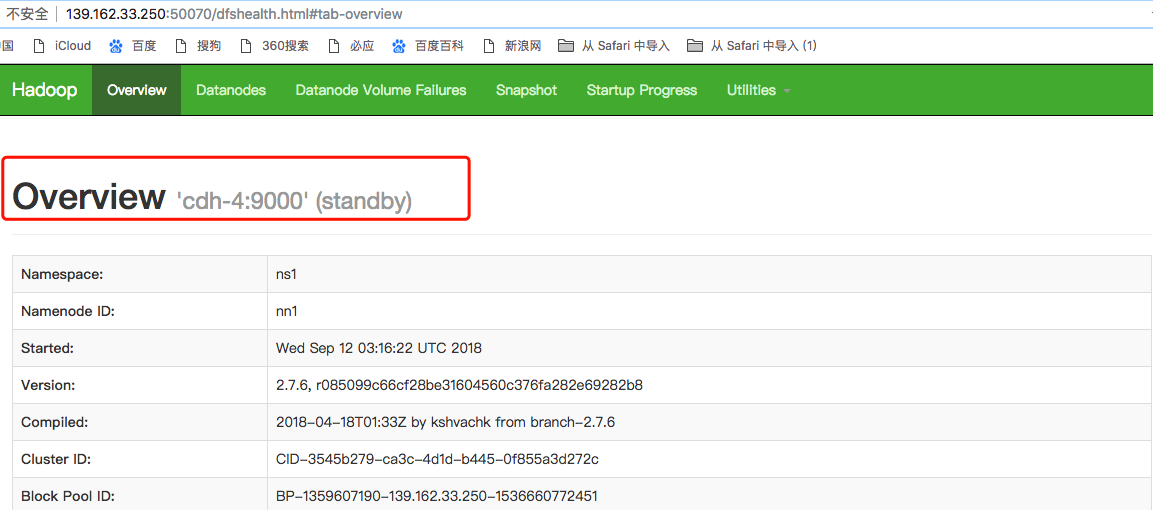
Note: after the cdh-5 namenode is stopped and the cdh-4 is refreshed, we can see that the current status of cdh-4 is active and the status of cdh-5 is standby