catalogue
3. Working mechanism of Zookeeper
5. Data structure of zookeeper
2, Application scenario of Zookeeper
3, Zookeeper's election mechanism
1. The electoral mechanism was launched for the first time
2. It is not the first time to start the electoral mechanism
1. Why message queuing (MQ) is required
2. Benefits of using message queue
④ Flexibility & peak processing power
7, Kafka architecture in depth
1.Kafka workflow and file storage mechanism
1, About zookeeper
. 1 overview of zookeeper
ZooKeeper is a distributed, open-source distributed application coordination service. It is an open-source implementation of Chubby of Google and an important component of Hadoop and Hbase. It is a software that provides consistency services for distributed applications. Its functions include configuration maintenance, domain name service, distributed synchronization, group service, etc.
The goal of ZooKeeper is to encapsulate complex and error prone key services and provide users with simple and easy-to-use interfaces and systems with efficient performance and stable functions.
ZooKeeper contains a simple set of primitives that provide Java and C interfaces.
In the code version of ZooKeeper, interfaces for distributed exclusive locks, elections and queues are provided. The code is in $zookeeper_home\src\recipes. There are two versions of distributed locks and queues: Java and C, and there is only java version for election.
2. Definition of Zookeeper
Zookeeper is an open source distributed Apache project that provides coordination services for distributed frameworks.
3. Working mechanism of Zookeeper
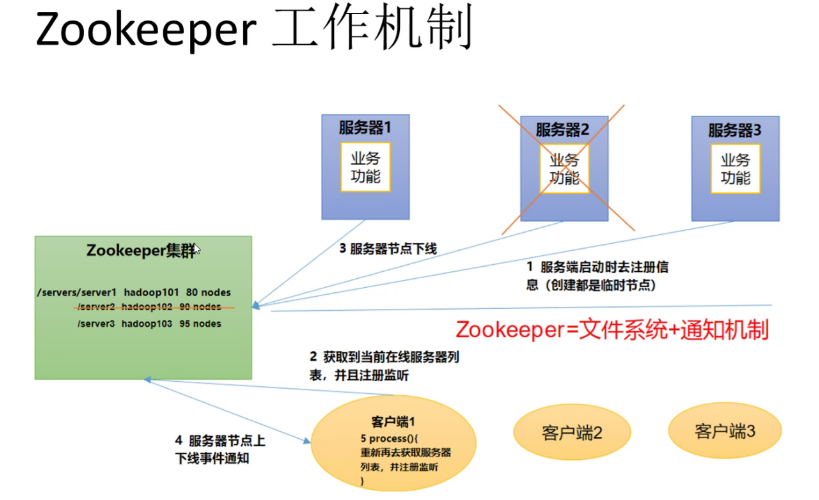
- Zookeeper understands it from the perspective of design pattern: it is a distributed service management framework designed based on observer pattern. It is responsible for storing and managing data that everyone cares about, and then accepting the registration of observers. Once the status of these data changes, zookeeper will be responsible for notifying those observers who have registered on zookeeper to respond accordingly.
- That is, Zookeeper = file system + notification mechanism.
4. Features of Zookeeper
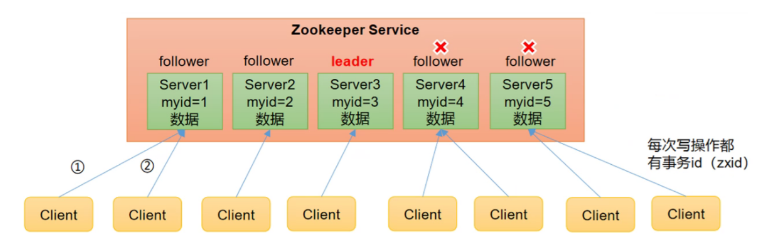
- Zookeeper: a cluster composed of one leader and multiple followers.
- As long as more than half of the nodes in the Zookeeper cluster survive, the Zookeeper cluster can serve normally. Therefore, Zookeeper is suitable for installing an odd number of servers.
- Global data consistency: each Server saves a copy of the same data. No matter which Server the Client connects to, the data is consistent.
- Update requests are executed in sequence. Update requests from the same Client are executed in sequence according to their sending order, that is, first in first out.
- Data update is atomic. A data update either succeeds or fails.
- Real time. Within a certain time range, the Client can read the latest data.
5. Data structure of zookeeper
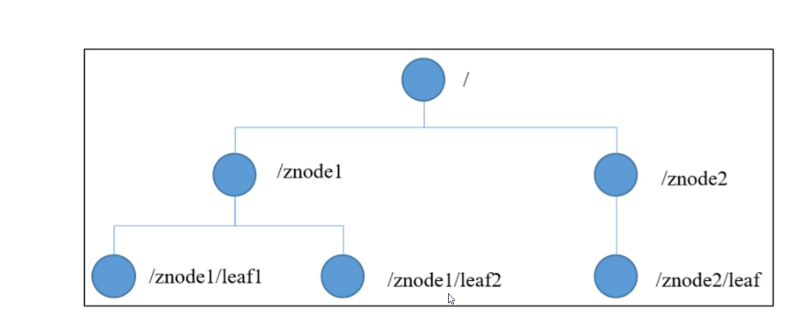
The structure of ZooKeeper data model is very similar to that of Linux file system. On the whole, it can be regarded as a tree, and each node is called - ZNode.
Each ZNode can store 1MB of data by default, and each ZNode can be uniquely identified through its path.
2, Application scenario of Zookeeper
The services provided include: unified naming service, unified configuration management, unified cluster management, dynamic uplink and downlink of server nodes, soft load balancing, etc.
1. Unified naming service
- In the distributed environment, it is often necessary to uniformly name applications / services for easy identification. For example, IP is not easy to remember, while domain name is easy to remember.
2. Unified configuration management
- In distributed environment, profile synchronization is very common. Generally, the configuration information of all nodes in a cluster is consistent, such as Kafka cluster. After modifying the configuration file, you want to be able to quickly synchronize to each node.
- Configuration management can be implemented by ZooKeeper. Configuration information can be written to a - Znode on ZooKeeper. Each client server listens to this Znode. Once the data in Znode is modified, ZooKeeper will notify each client server.
3. Unified cluster management
- In distributed environment, it is necessary to master the state of each node in real time. Some adjustments can be made according to the real-time status of the node.
- ZooKeeper can monitor node status changes in real time. Node information can be written to a - ZNode on ZooKeeper. Monitoring this ZNode can obtain its real-time state changes.
4. Server dynamic online and offline
- The client can have real-time insight into the changes on and off the server.
5. Soft load balancing
- Record the number of accesses of each server in Zookeeper, and let the server with the least number of accesses handle the latest client requests.
3, Zookeeper's election mechanism
1. The electoral mechanism was launched for the first time
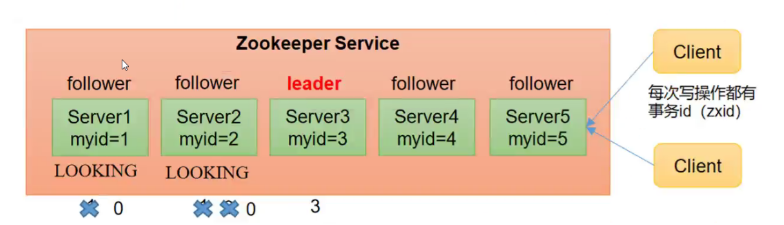
- Server 1 starts and initiates an election. Server 1 voted for itself. At this time, server 1 has one vote, less than half (3 votes), the election cannot be completed, and the state of server 1 remains LO0KING;
-
Server 2 starts and initiates another election. Servers 1 and 2 vote for themselves and exchange vote information: at this time, server 1 finds that the myid of server 2 is larger than that of their current vote (server 1), and changes the vote to recommend server 2. At this time, there are 0 votes for server 1 and 2 votes for server 2. Without more than half of the results, the election cannot be completed, and the status of server 1 and 2 remains LOOKING
-
Server 3 starts and initiates an election. Servers 1 and 2 change to server 3. The voting results: 0 votes for server 1, 0 votes for server 2 and 3 votes for server 3. At this time, server 3 has more than half of the votes, and server 3 is elected Leader. The status of server 1 and 2 is changed to FOLLOWING, and the status of server 3 is changed to LEADING;
-
Server 4 starts and initiates an election. At this time, servers 1, 2 and 3 are no longer in L00KING status, and the ballot information will not be changed. Results of exchange of ballot information: server 3 has 3 votes and server 4 has 1 vote. At this time, server 4 obeys the majority, changes the vote information to server 3, and changes the status to FOLLOWING;
-
The server 5 starts, the same as 4 obeys the majority, changes the vote information to server 3, and changes the status to FOLLOWING;
2. It is not the first time to start the electoral mechanism
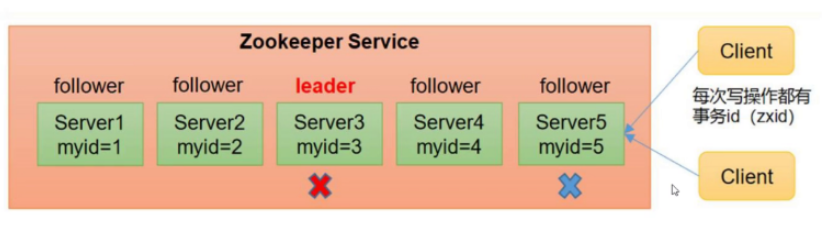
- When one of the following two situations occurs to a server in the ZooKeeper cluster, it will start to enter the Leader election;
- Server initialization start
- Unable to maintain connection with the Leader while the server is running.
- When a machine enters the Leader election process, the current cluster may also be in the following two states:
- A Leader already exists in the cluster
- When the machine attempts to elect a Leader when there is already a Leader, it will be informed of the Leader information of the current server. For the machine, it only needs to establish a connection with the Leader machine and synchronize the status.
- The Leader does not exist in the cluster
- Suppose ZooKeeper is composed of five servers with SID of 1, 2, 3, 4 and 5, ZXID of 8, 8, 8, 7 and 7, and the server with SID of 3 is the Leader. At some point, the 3 and 5 servers failed, so the Leader election began.
- Election Leader rules:
- EPOCH big wins directly.
- The same as EPOCH, the one with a large transaction id wins.
- If the transaction id is the same and the server id is larger, the winner will be selected.
SID: server ID. It is used to uniquely identify the machines in a ZooKeeper cluster. Each machine cannot be duplicated and is consistent with myid.
ZXID: transaction ID. ZXID is - a transaction ID that identifies a change in server status. At a certain - time, the ZXID value of each machine in the cluster may not be exactly the same, which is related to the processing logic speed of ZooKeeper server for client "update request".
Epoch: the code of each Leader's tenure. When there is no Leader, the logical clock value in the same round of voting is the same. This figure increases with each vote
4, Deploy Zookeeper cluster
1.Preparation before installation
//Turn off firewall
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
//Install JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
//Download installation package
Official download address: https://archive.apache.org/dist/zookeeperl
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
2.install Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
//Modify profile
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000
#Communication heartbeat time, heartbeat time between Zookeeper server and client, unit: ms
initLimit=10
#The maximum number of heartbeats that the Leader and Follower can tolerate during initial connection (the number of ticktimes), expressed here as 10*2s
syncLimit=5
#The timeout of synchronous communication between Leader and Follower, which means that if it exceeds 5*2s, Leader thinks Follower is dead and deletes Follower from the server list
dataDir=/usr/local/zookeeper-3.5.7/data ●Modify, specify save Zookeeper The directory of data in. The directory needs to be created separately
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●Add and specify the directory for storing logs. The directory needs to be created separately
clientPort=2181
#Client connection port
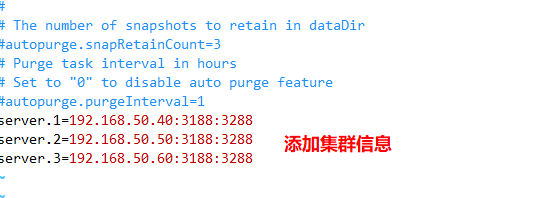
#Add cluster information
server.1=192.168.50.40:3188:3288
server.2=192.168.50.50:3188:3288
server.3=192.168.50.60:3188:3288
---------------------------------------------------------------
server.A=B:C:D
●A Is a number indicating the server number. In cluster mode, you need to zoo.cfg in dataDir Create a file in the specified directory myid,There is a data in this file A The value of, Zookeeper Read this file at startup and get the data and zoo.cfg Compare the configuration information inside to determine which one it is server
●B Is the address of this server
●c This is the server Follower With in the cluster Leader The port on which the server exchanges information
●D It's in the cluster Leader The server is down. You need a port to re elect and choose a new one Leader,This port is used to communicate with each other during the election
---------------------------------------------------------------
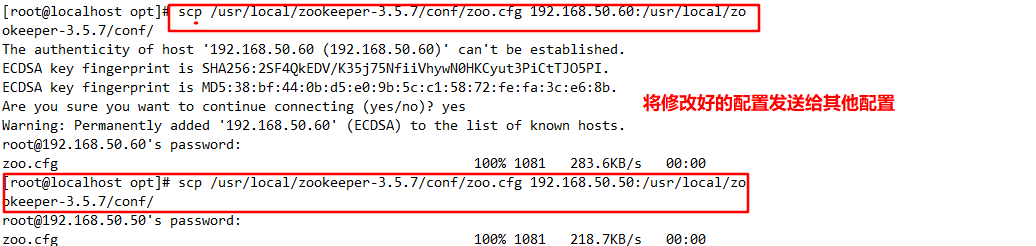
//Copy the configured Zookeeper configuration file to other machines
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.50.11:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.50.12:/usr/local/zookeeper-3.5.7/conf/
//Create a data directory and a log directory on each node
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/1ocal/zookeeper-3.5.7/1ogs
//Create a myid file in the directory specified by dataDir of each node
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid
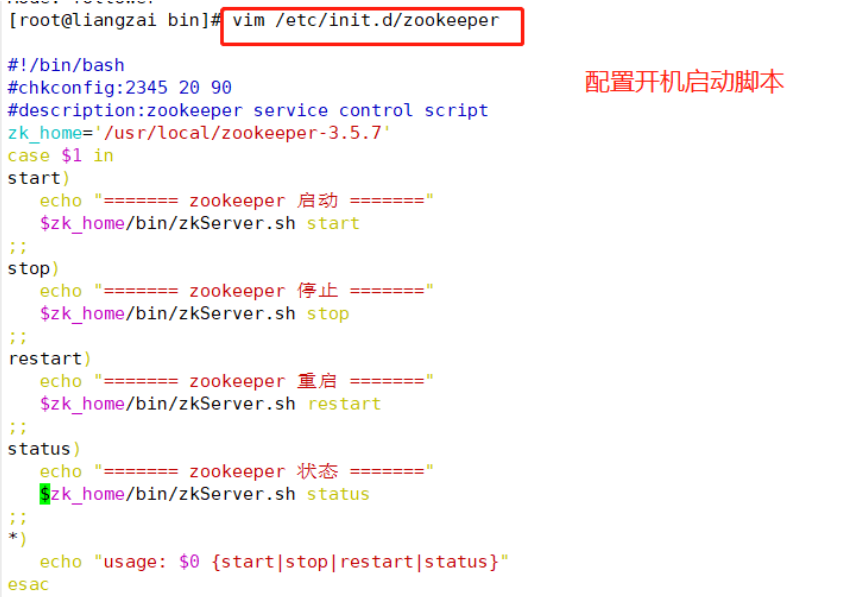
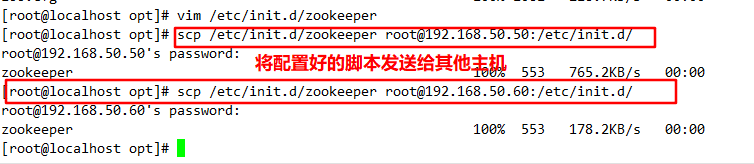
//Configure Zookeeper startup script
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description: Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "-----zookeeper start-up-----"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "----zookeeper stop it-------"
$ZK_HOME/bin/ zkServer.sh stop
;;
restart)
echo "----zookeeper restart-------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "-----zookeeper state------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
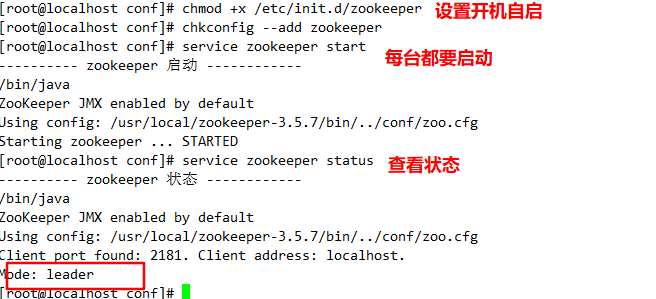
//Set startup and self startup
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
//Start Zookeeper separately
service zookeeper start
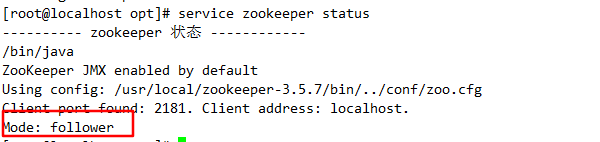
//View current status
service zookeeper status 





5, Kafka overview
1. Why message queuing (MQ) is required
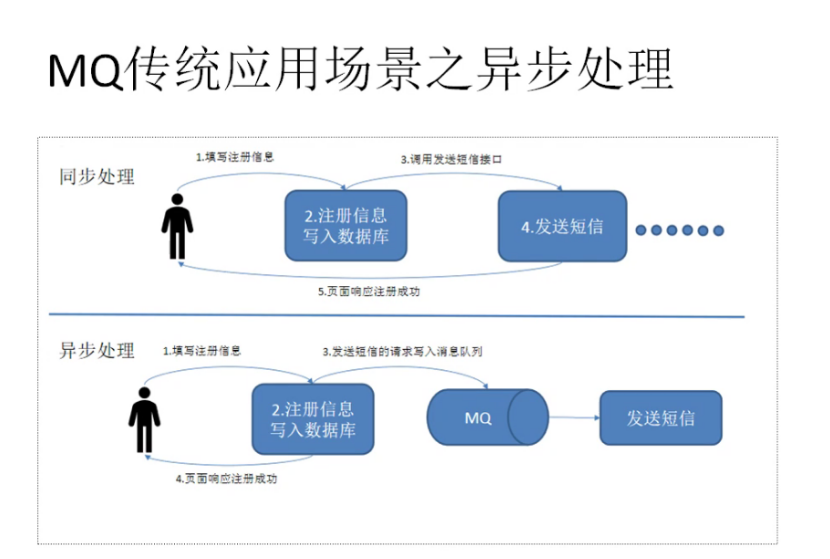
- The main reason is that in the high concurrency environment, the synchronization request is too late to be processed, and the request is often blocked. For example, a large number of requests access the database concurrently, resulting in row locks and table locks. Finally, too many request threads will accumulate, triggering a too many connection error and causing an avalanche effect.
- We use message queuing to process requests asynchronously, so as to relieve the pressure of the system. Message queuing is often used in asynchronous processing, traffic peak shaving, application decoupling, message communication and other scenarios.
- At present, the common MQ middleware include ActiveMQ, RabbitMQ, RocketMQ, Kafka, etc
2. Benefits of using message queue
① Decoupling
- It allows you to extend or modify the processes on both sides independently, as long as you ensure that they comply with the same interface constraints.
② Recoverability
- Failure of some components of the system will not affect the whole system. Message queuing reduces the coupling between processes, so even if a process processing messages hangs, the messages added to the queue can still be processed after the system recovers.
③ Buffer
- It helps to control and optimize the speed of data flow through the system and solve the inconsistency between the processing speed of production messages and consumption messages.
④ Flexibility & peak processing power
- In the case of a sharp increase in traffic, applications still need to continue to play a role, but such burst traffic is not common. It would be a huge waste to put resources on standby to handle such peak visits. Using message queuing can make key components withstand the sudden access pressure without completely crashing due to sudden overloaded requests.
⑤ Asynchronous communication
- Many times, users do not want or need to process messages immediately. Message queuing provides an asynchronous processing mechanism that allows users to put a message on the queue without processing it immediately. Put as many messages into the queue as you want, and then process them when needed.
3. Two modes of message queue
① Point to point mode (one-to-one, consumers actively pull data, and the message is cleared after receiving the message)
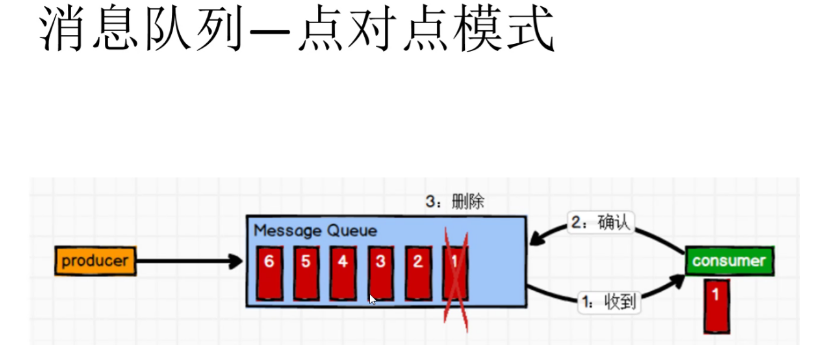
- The message producer sends the message to the message queue, and then the message consumer takes it out of the message queue and consumes the message. After the message is consumed, there is no storage in the message queue, so it is impossible for the message consumer to consume the consumed message. Message queuing supports the existence of multiple consumers, but for a message, only one consumer can consume
② Publish / subscribe mode (one to many, also known as observer mode. Messages will not be cleared after consumer consumption data)
- The message producer (publisher) publishes the message to the topic, and multiple message consumers (subscribers) consume the message at the same time. Unlike the peer-to-peer method, messages published to topic will be consumed by all subscribers.
- Publish / subscribe mode defines a one to many dependency between objects, so that whenever the state of an object (target object) changes, all objects (observer object) that depend on it will be notified and updated automatically
4.Kafka definition
- Kafka is a distributed Message Queue (MQ) based on publish / subscribe mode, which is mainly used in the field of big data real-time processing
5. Introduction to Kafka
Originally developed by Linkedin, afka is a distributed, partition supported, multi replica, Zookeeper coordinated distributed message middleware system. Its biggest feature is that it can process a large amount of data in real time to meet various demand scenarios, such as hadoop based batch processing system Low latency real-time system Spark/Flink streaming engine, nginx access log, message service, etc. are written in scala language. Linkedin contributed to the Apache foundation and became a top open source project in 2010
6. Characteristics of Kafka
High throughput, low latency
- Kafka can process hundreds of thousands of messages per second, and its latency is as low as a few milliseconds. Each topic can be divided into multiple partitions. The Consumer Group can consume partitions to improve load balancing and consumption capacity.
Scalability
- kafka cluster supports hot expansion
Persistence and reliability
- Messages are persisted to local disk, and data backup is supported to prevent data loss
Fault tolerance
- Allow node failures in the cluster (in the case of multiple replicas, if the number of replicas is n, n-1 nodes are allowed to fail)
High concurrency
- Support thousands of clients to read and write at the same time
7.Kafka system architecture
Broker
- A kafka server is a broker. A cluster consists of multiple brokers. A broker can accommodate multiple topic s.
Topic
- It can be understood as a queue, and both producers and consumers are oriented to one topic.
- Similar to the database table name or ES index
- Physically, messages of different topic s are stored separately
Partition
- In order to achieve scalability, a very large topic can be distributed to multiple broker s (i.e. servers). A topic can be divided into one or more partitions, and each partition is an ordered queue. Kafka only guarantees that the records in the partition are in order, not the order of different partitions in the topic.
- Each topic has at least one partition. When the producer generates data, it will select the partition according to the allocation policy, and then append the message to the end of the queue of the specified partition.
-
Partation data routing rules:
- If the partition is specified, it is used directly;
- If you do not specify a partition but specify a key (equivalent to an attribute in the message), select a partition by hash ing the value of the key;
- Neither the partition nor the key is specified. Use polling to select a partition.
- Each message will have a self increasing number, which is used to identify the offset of the message. The identification sequence starts from 0.
- The data in each partition is stored using multiple segment files.
- If the topic has multiple partitions, the order of data cannot be guaranteed when consuming data. In the scenario of strictly ensuring the consumption order of messages (such as commodity spike and red envelope grabbing), the number of partitions needs to be set to 1.
The broker stores the data of topic. If a topic has N partitions and the cluster has N brokers, each broker stores a partition of the topic.
If a topic has N partitions and the cluster has (N+M) brokers, N brokers store one partition of the topic, and the remaining M brokers do not store the partition data of the topic.
If a topic has n partitions and the number of brokers in the cluster is less than N, a broker stores one or more partitions of the topic. In the actual production environment, try to avoid this situation, which is easy to lead to the imbalance of Kafka cluster data.
-
Reason for partition
- It is convenient to expand in the cluster. Each Partition can be adjusted to adapt to its machine, and a topic can be composed of multiple partitions. Therefore, the whole cluster can adapt to data of any size;
- Concurrency can be improved because you can read and write in Partition units
Leader
- Each partition has multiple copies, including one and only one Leader, which is the partition currently responsible for reading and writing data.
Follower
- The follower follows the Leader. All write requests are routed through the Leader. Data changes will be broadcast to all followers. The follower keeps data synchronization with the Leader. Follower is only responsible for backup, not data reading and writing.
- If the Leader fails, select a new Leader from the Follower.
- When the Follower hangs, gets stuck, or the synchronization is too slow, the Leader will delete the Follower from the ISR (a Follower set maintained by the Leader and synchronized with the Leader) list and recreate a Follower.
Replica
- Replica: in order to ensure that the partition data on a node in the cluster will not be lost when it fails, and kafka can still continue to work, kafka provides a replica mechanism. Each partition of a topic has several replicas, one leader and several follower s.
Producer
- The producer is the publisher of data. This role publishes messages to Kafka's topic.
- After the broker receives the message sent by the producer, the broker appends the message to the segment file currently used to append data.
- The messages sent by the producer are stored in a partition. The producer can also specify the partition of the data store.
Consumer
- Consumers can read data from the broker. Consumers can consume data in multiple topic s.
Consumer Group(CG)
- consumer group, consisting of multiple consumers.
- All consumers belong to a certain consumer group, that is, the consumer group is a logical subscriber. You can specify a group name for each consumer. If you do not specify a group name, it belongs to the default group.
- Bringing multiple consumers together to process the data of a Topic can quickly improve the data consumption power.
- Each consumer in the consumer group is responsible for consuming data in different partitions. A partition can only be consumed by consumers in one group to prevent data from being read repeatedly.
- Consumer groups do not affect each other.
Offset offset
- A message can be uniquely identified.
- The offset determines the location of the data to be read. There is no thread safety problem. Consumers use the offset to determine the message to be read next time (i.e. the consumption location).
- Messages are not deleted immediately after consumption, so that multiple businesses can reuse Kafka messages.
- A service can also read the message again by modifying the offset, which is controlled by the user.
- Messages will eventually be deleted. The default life cycle is 1 week (7 * 24 hours).
Zookeeper
- Kafka stores the meta information of the cluster through Zookeeper.
- Because consumers may have power failure, downtime and other failures during consumption, consumers need to continue to consume from the position before the failure after recovery, so consumers need to record the offset they consume in real time, so that they can continue to consume after recovery.
- Before Kafka version 0.9, consumer saved offset in Zookeeper by default; Starting from version 0.9, the consumer saves offset in a built-in topic in Kafka by default, which is__ consumer_offsets.
6, Deploy kafka cluster
Note: Based on the previous zookeeper Environment do
1.Download installation package
Official download address: http://kafka.apache.org/downloads.html
cd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz
2.install Kafka
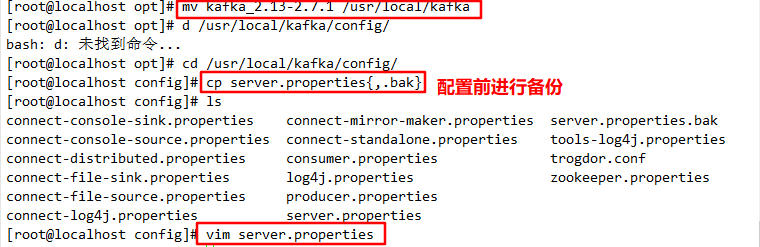
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
//Modify profile
cd /usr/local/kafka/config/
cp server.properties{,.bak}
vim server.properties
broker.id=0 ●21 that 's ok, broker Globally unique number of each broker It cannot be repeated, so it should be configured on other machines broker.id=1,broker.id=2
listeners=PLAINTEXT://192.168.80.10:9092 line 31 specifies the IP and port to listen to. If the IP of each broker needs to be modified separately, the default configuration can be maintained without modification
num.network.threads=3 #Line 42, the number of threads that the broker processes network requests. Generally, it does not need to be modified
num.io.threads=8 #Line 45, the number of threads used to process disk IO. The value should be greater than the number of hard disks
socket.send.buffer.bytes=102400 #Line 48, buffer size of send socket
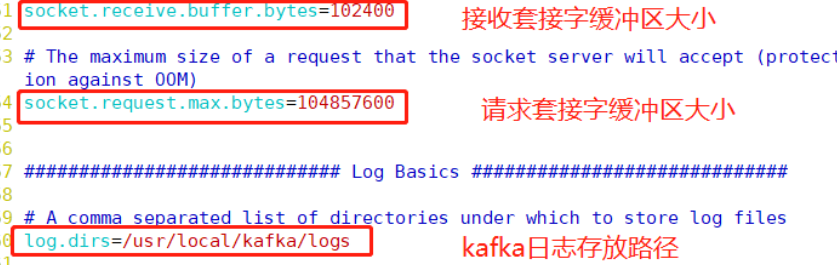
socket.receive.buffer.bytes=102400 #Line 51, buffer size of receive socket
socket.request.max.bytes=104857600 #Line 54, the buffer size of the request socket
log.dirs=/usr/local/kafka/logs #Line 60: the path where kafka operation logs are stored is also the path where data is stored
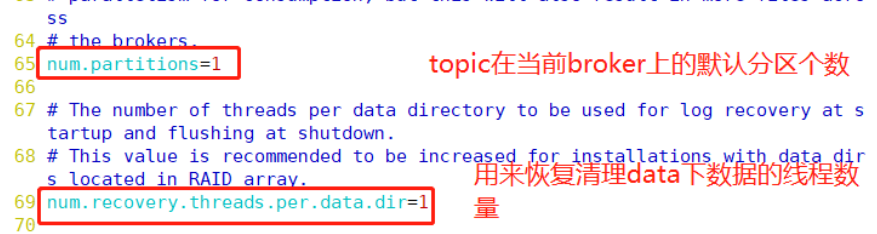
num.partitions=1 #In line 65, the default number of partitions of topic on the current broker will be overwritten by the specified parameters when topic is created
num.recovery.threads.per.data.dir=1 #69 lines, the number of threads used to recover and clean data
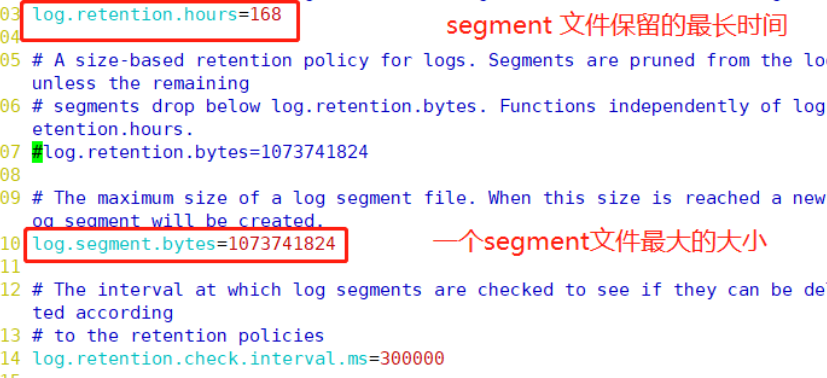
log.retention.hours=168 #In line 103, the maximum retention time of segment file (data file), in hours, defaults to 7 days, and the timeout will be deleted
log.segment.bytes=1073741824 #110 lines. The maximum size of a segment file is 1G by default. If it exceeds, a new segment file will be created
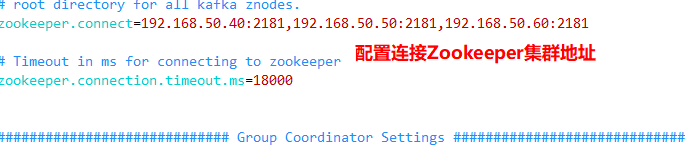
zookeeper.connect=192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 ●123 Rows, configuring connections Zookeeper Cluster address
//Modify environment variables
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
//Configure Zookeeper startup script
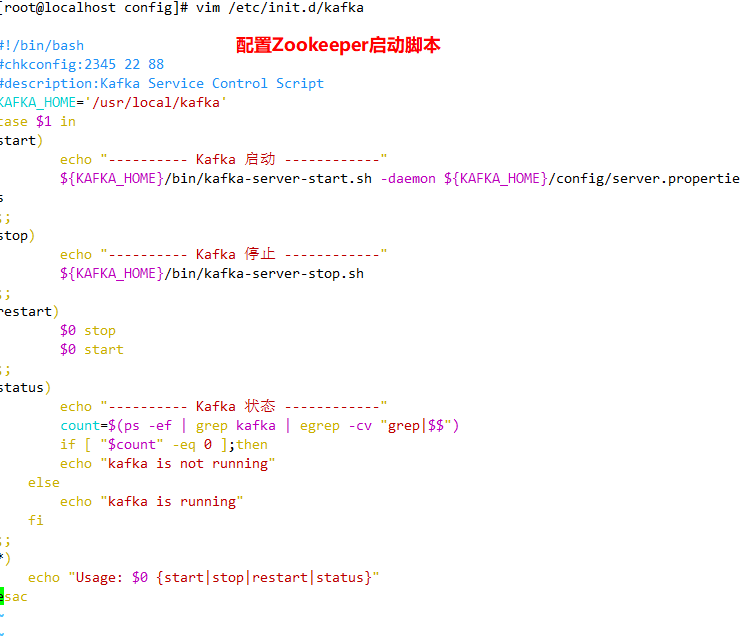
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka start-up ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka stop it ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka state ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
//Set startup and self startup
chmod +x /etc/init.d/kafka
chkconfig --add kafka
//Start Kafka separately
service kafka start
3.Kafka Command line operation
//Create topic
kafka-topics.sh --create --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --replication-factor 2 --partitions 3 --topic test
-------------------------------------------------------------------------------------
--zookeeper: definition zookeeper Cluster server address, if there are multiple IP Addresses are separated by commas, usually one IP that will do
--replication-factor: Define the number of partition replicas. 1 represents a single replica, and 2 is recommended
--partitions: Define number of partitions
--topic: definition topic name
-------------------------------------------------------------------------------------
//View all topic s in the current server
kafka-topics.sh --list --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181
//View the details of a topic
kafka-topics.sh --describe --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181
//Release news
kafka-console-producer.sh --broker-list 192.168.80.10:9092,192.168.80.11:9092,192.168.80.12:9092 --topic test
//Consumption news
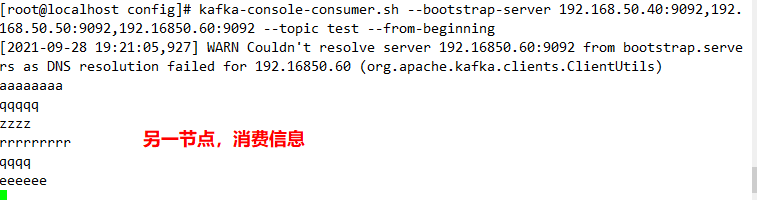
kafka-console-consumer.sh --bootstrap-server 192.168.80.10:9092,192.168.80.11:9092,192.168.80.12:9092 --topic test --from-beginning
-------------------------------------------------------------------------------------
--from-beginning: All previous data in the topic will be read out
-------------------------------------------------------------------------------------
//Modify the number of partitions
kafka-topics.sh --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --alter --topic test --partitions 6
//Delete topic
kafka-topics.sh --delete --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --topic test








7, Kafka architecture in depth
1.Kafka workflow and file storage mechanism
- Messages in Kafka are classified by topic. Producer production messages and consumer consumption messages are all topic oriented.
- topic is a logical concept, while partition is a physical concept. Each partition corresponds to a log file, which stores the data produced by Producer. The data produced by Producer will be continuously appended to the end of the log file, and each data has its own offset. Each consumer in the consumer group will record the offset to which they consumed in real time, so that they can continue to consume from the last position when the error is recovered.
- Because the messages produced by the producer will continue to be appended to the end of the log file, Kafka adopts the fragmentation and indexing mechanism to divide each partition into multiple segments in order to prevent the low efficiency of data positioning caused by the large log file. Each segment corresponds to two files:. index file and ". Log" file. These files are located in a folder. The naming rule of the folder is: topic name + partition serial number. For example, if the topic test has three partitions, the corresponding folders are test-0, test-1 and test-2.
- The index and log files are named after the offset of the first message of the current segment.
- The ". Index" file stores a large amount of index information, and the ". log" file stores a large amount of data. The metadata in the index file points to the physical offset address of message in the corresponding data file.
2. Data reliability assurance
- In order to ensure that the data sent by the producer can be reliably sent to the specified topic, after each partition of the topic receives the data sent by the producer, it needs to send an ack to the producer (ack nowledge confirmation). If the producer receives an ack, it will send it to the next round, otherwise it will send the data again.
3. Data consistency
- LEO: refers to the maximum offset of each copy;
- HW: refers to the largest offset that consumers can see and the smallest LEO in all copies.
(1) follower failure
- After a follower fails, it will be temporarily kicked out of the ISR (a follower set maintained by the Leader and synchronized with the Leader). After the follower is restored, the follower will read the last HW recorded on the local disk, intercept the part of the log file higher than HW, and synchronize with the Leader from HW. When the LEO of the follower is greater than or equal to the HW of the Partition, that is, the follower can rejoin the ISR after catching up with the Leader.
(2) leader failure
- After the leader fails, a new leader will be selected from the ISR. Then, in order to ensure the data consistency among multiple replicas, the remaining follower s will first cut off the parts of their log files higher than HW, and then synchronize the data from the new leader.
Note: this can only ensure the data consistency between replicas, and does not guarantee that the data will not be lost or repeated
4.ack response mechanism
- For some unimportant data, the requirements for data reliability are not very high, and a small amount of data loss can be tolerated, so it is not necessary to wait for all follower s in ISR to receive successfully. Therefore, Kafka provides users with three levels of reliability, and users choose according to the requirements of reliability and delay.
When the producer sends data to the leader, you can set the level of data reliability through the request.required.acks parameter:
- 0: this means that the producer does not need to wait for confirmation from the broker to continue sending the next batch of messages. In this case, the data transmission efficiency is the highest, but the data reliability is the lowest. When the broker fails, data may be lost.
- 1 (default configuration): this means that the leader of producer in ISR has successfully received the data and sent the next message after confirmation. If the leader fails before the follower synchronization succeeds, data will be lost.
- -1 (or all): the producer needs to wait for all followers in the ISR to confirm the receipt of data before completing the transmission at one time, with the highest reliability. However, if the leader fails after the follower synchronization is completed and before the broker sends an ack, data duplication will occur.
The performance of the three mechanisms decreases in turn, and the data reliability increases in turn.
Note: Kafka before version 0.11 can do nothing about this. It can only ensure that the data is not lost, and then do global de duplication for the data in the downstream consumers. In 0.11 and later versions of Kafka, an important feature is introduced: idempotency. The so-called idempotency means that no matter how many times the Producer sends duplicate data to the Server, the Server side will persist only one.
8, Deploy Filebeat+Kafka+ELK
1.deploy Zookeeper+Kafka colony
2.deploy Filebeat
cd /usr/local/filebeat
vim filebeat.yml
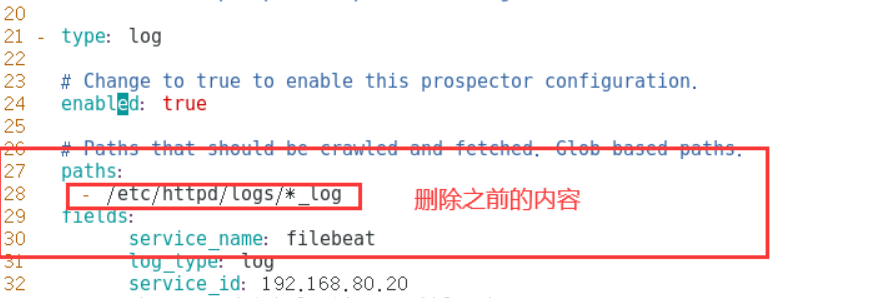
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/*.log
......
#Add configuration output to Kafka
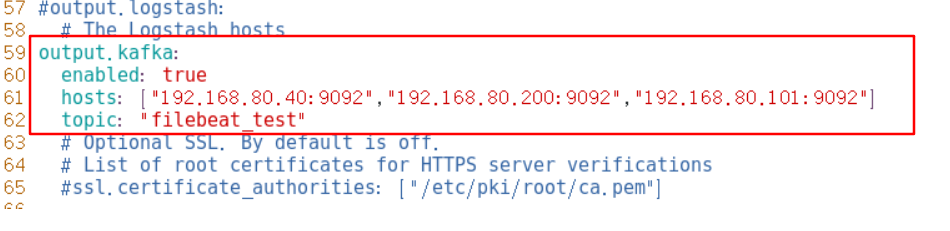
output.kafka:
enabled: true
hosts: ["192.168.80.10:9092","192.168.80.11:9092","192.168.80.12:9092"] #Specify Kafka cluster configuration
topic: "filebeat_test" #Specify topic for Kafka
#Start filebeat
./filebeat -e -c filebeat.yml
3.deploy ELK,stay Logstash Create a new one on the node where the component is located Logstash configuration file
cd /etc/logstash/conf.d/
vim filebeat.conf
input {
kafka {
bootstrap_servers => "192.168.80.10:9092,192.168.80.11:9092,192.168.80.12:9092"
topics => "filebeat_test"
group_id => "test123"
auto_offset_reset => "earliest"
}
}
output {
elasticsearch {
hosts => ["192.168.80.30:9200"]
index => "filebeat-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
#Start logstash
logstash -f filebeat.conf
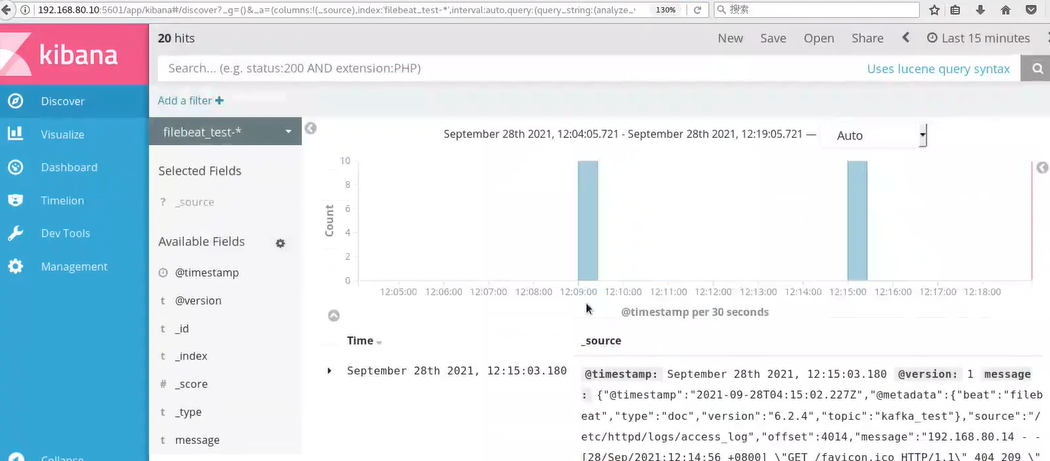
4.Browser access http://192.168.80.30:5601 log in to Kibana, click the "Create Index Pattern" button to add the index "filebeat - *", click the "create" button to create, and click the "Discover" button to view the chart information and log information.After installing the httpd service, collect the Apache access logs of node1.
Start httpd service
Modify log collection path
Start filebeat

Modify profile