Preface
as we all know, in the distributed global unique ID generator scheme, SnowFlake algorithm, which is open-source by Twitter, is compared with the transponder algorithm that needs to be deployed represented by meituan Leaf. Because of its advantages such as high performance, simple code, no dependence on third-party services, no independent deployment of services, etc., it can meet the needs of most systems in general. Native SnowFlake, Baidu uidgenera The algorithm of tor based on the principle of dividing namespace has accumulated a large number of users.
Q Q Only 2 ^ 53 = 900719925474992 algorithm generates 18 digits which are over standard.
Transform SnowFlake
Namespace partition (reduce bit length and change to Unix second timestamps)
The default structure of native SnowFlake is as follows:
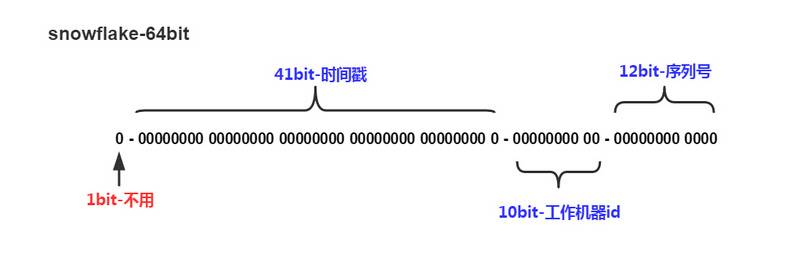
Space division in native SnowFlake: 1. High bit fixed 0 indicates positive number 2. 41 bit millisecond time stamp 3. 10bit machine number, up to 1024 nodes 4. 12bit auto increasing sequence, single node can support 4096 IDS / MS at most
As can be seen from the above native algorithm structure, the most influential factor in the final ID generation is the millisecond timestamp, which takes up a full 41 bit and is replaced by 10 base, which takes up 13 digits. If the final digit is not reduced, it will not go down; considering that most companies do not have such a high database concurrency or 1024 machine clusters;
The time stamp is changed from millisecond to 32 bit, the machine code is shortened to 5 bit, and the remaining 16 bit is used as auto increment sequence.
The machine number can also be reduced, and the final result is as follows ↓

Space partition after shortening algorithm 1. The high-order 32bit is used as the second level time stamp. The time stamp minus the fixed value (2019 time stamp) can support up to 2106 (1970 + 2 ^ 32 / 3600 / 24 / 365 ≈ 2106) 2, 5 bit as machine identification, up to 32 machines can be deployed 3. The last 16bit is used as an auto increment sequence, and the maximum ID per second of a single node is 2 ^ 16 = 65536. PS: if you need to deploy more nodes, you can adjust the bit length of machine bit and auto increment sequence appropriately, such as machine bit 7 bit, auto increment sequence 14 bit, so that it can support 2 ^ 7 = 128 nodes, and single node can support 2 ^ 14 = 16384 auto increment sequences per second.
Clock callback problem (halve available nodes and set backup nodes)
The trend self increasing depends on the high-level timestamp. If the clock callback is caused by the synchronous time and other operations of the server, it may generate duplicate IDs. My solution is to split 32 node IDs again, 0-15 as the primary node ID, 16-31 as the backup node ID. when the primary node detects the clock callback, enable the corresponding backup node to continue to provide services. If it's not a coincidence When using the backup node, 65536 sequences are consumed in one second, then the unused sequences of the next second are seconded until the clock of the primary node is recovered.
The backup node can take over and continue to provide services when the sequence of the primary node is exhausted within seconds, or take over services when the clock is dialed back. As a result, there are only 16 machines with the largest support. Although there are fewer, they are enough to meet the needs of ordinary small enterprises and improve the reliability of services.
Relationship between the primary node and the backup node: when the primary node is 0, the corresponding backup node is 0 + 16 = 16; when the primary node is 1, the corresponding backup node is 1 + 16 = 17; when the primary node is 2, the corresponding backup node is 2 + 16 = 18...

The specific code is as follows: when the node ID is 5bit, back "worker" Id "begin is the minimum value of the backup node id = 16, and the primary node + 16 gets the backup node.
((WORKER_ID ^ BACK_WORKER_ID_BEGIN) << WORKER_SHIFT_BITS)
The problem of running out of self increasing sequences in seconds
In extreme cases, when the concurrency is more than 65536 per second, there will be no assignable ID in that second. To solve this problem, you can enable the backup node when the sequence is exhausted in seconds, and the ID of this node can be doubled every second. When the backup node is also insufficient, you can consider that the backup node can directly enable the next second's unassigned sequence to continue to provide services. In theory, we can get a second allocable ID with infinite capacity (as long as the performance of the machine can keep up with that of the next second, until one second later, the recovery time difference of the master node will continue to provide services by the master node, so as to generate endless services.)
if (0L == (++sequence & SEQUENCE_MAX)) { // The above auto increment sequence has been auto incremented by 1. Roll back the auto increment operation to ensure that the next entry will still trigger the condition. sequence--; // Run out of sequence in seconds, use backup node to continue service return nextIdBackup(timestamp); }
code implementation
In order to make the code logic clear and simple, the primary node and the backup node generate direct replication as two methods with similar structure.
/** * Snowflake algorithm distributed unique ID generator < br > * Each machine number supports a maximum of 65535 sequences per second. When the second sequence is insufficient, the backup machine number is enabled. If the backup machine is also insufficient, the next second available sequence of the backup machine is borrowed < br > * 53 bits The structure of trend auto increment ID is as follows: * * |00000000|00011111|11111111|11111111|11111111|11111111|11111111|11111111| * |-----------|##########32bit Second timestamps##########|-----|-----------------| * |--------------------------------------5bit Machine bit | xxxxx|-----------------| * |-----------------------------------------16bit Auto increasing sequence| * * @author: yangzc * @date: 2019-10-19 **/ @Slf4j public class SequenceUtils { /** Initial offset timestamp */ private static final long OFFSET = 1546300800L; /** Machine ID (0-15 keep 16-31 as backup machine) */ private static final long WORKER_ID; /** Number of machine id digits (5bit, support the maximum number of machines 2 ^ 5 = 32)*/ private static final long WORKER_ID_BITS = 5L; /** The number of bits occupied by the auto increasing sequence (16bit, max. 2 ^ 16 = 65536 per second) */ private static final long SEQUENCE_ID_BITS = 16L; /** Machine id offset bits */ private static final long WORKER_SHIFT_BITS = SEQUENCE_ID_BITS; /** Offset digit of auto increasing sequence */ private static final long OFFSET_SHIFT_BITS = SEQUENCE_ID_BITS + WORKER_ID_BITS; /** Machine ID max (2 ^ 5 / 2 - 1 = 15) */ private static final long WORKER_ID_MAX = ((1 << WORKER_ID_BITS) - 1) >> 1; /** Backup machine ID start location (2 ^ 5 / 2 = 16) */ private static final long BACK_WORKER_ID_BEGIN = (1 << WORKER_ID_BITS) >> 1; /** Maximum value of auto increasing sequence (2 ^ 16 - 1 = 65535) */ private static final long SEQUENCE_MAX = (1 << SEQUENCE_ID_BITS) - 1; /** Maximum callback time tolerated when time callback occurs (seconds) */ private static final long BACK_TIME_MAX = 1L; /** Timestamp of last generated ID (seconds) */ private static long lastTimestamp = 0L; /** Current second series (2 ^ 16)*/ private static long sequence = 0L; /** Timestamp of the last ID generated by the backup machine (seconds) */ private static long lastTimestampBak = 0L; /** Back up the current second sequence of the machine (2 ^ 16)*/ private static long sequenceBak = 0L; static { // Initialize machine ID // Pseudo code: get node ID from your profile long workerId = your configured worker id; if (workerId < 0 || workerId > WORKER_ID_MAX) { throw new IllegalArgumentException(String.format("cmallshop.workerId Range: 0 ~ %d at present: %d", WORKER_ID_MAX, workerId)); } WORKER_ID = workerId; } /** Private constructor forbids external access */ private SequenceUtils() {} /** * Get auto increasing sequence * @return long */ public static long nextId() { return nextId(SystemClock.now() / 1000); } /** * Main machine auto increment sequence * @param timestamp Current Unix timestamp * @return long */ private static synchronized long nextId(long timestamp) { // Clock callback check if (timestamp < lastTimestamp) { // Clock callback occurs log.warn("Clock callback, Enable backup machine ID: now: [{}] last: [{}]", timestamp, lastTimestamp); return nextIdBackup(timestamp); } // Start next second if (timestamp != lastTimestamp) { lastTimestamp = timestamp; sequence = 0L; } if (0L == (++sequence & SEQUENCE_MAX)) { // Run out of sequence in seconds // log.warn("run out of [{}] sequence in seconds, enable backup machine ID sequence", timestamp); sequence--; return nextIdBackup(timestamp); } return ((timestamp - OFFSET) << OFFSET_SHIFT_BITS) | (WORKER_ID << WORKER_SHIFT_BITS) | sequence; } /** * Backup machine auto increment sequence * @param timestamp timestamp Current Unix timestamp * @return long */ private static long nextIdBackup(long timestamp) { if (timestamp < lastTimestampBak) { if (lastTimestampBak - SystemClock.now() / 1000 <= BACK_TIME_MAX) { timestamp = lastTimestampBak; } else { throw new RuntimeException(String.format("Clock callback: now: [%d] last: [%d]", timestamp, lastTimestampBak)); } } if (timestamp != lastTimestampBak) { lastTimestampBak = timestamp; sequenceBak = 0L; } if (0L == (++sequenceBak & SEQUENCE_MAX)) { // Run out of sequence in seconds // logger.warn("run out of [{}] sequence in seconds, backup machine ID borrows next second sequence", timestamp); return nextIdBackup(timestamp + 1); } return ((timestamp - OFFSET) << OFFSET_SHIFT_BITS) | ((WORKER_ID ^ BACK_WORKER_ID_BEGIN) << WORKER_SHIFT_BITS) | sequenceBak; } }
Performance problems of System.currentTimeMillis() under Linux
copy the ID generation algorithm above, you will find that SystemClock.now() cannot be found because it is not a class of JDK. The reason for using this tool class to generate timestamps is that it is found that Linux environment is high and the API System.currentTimeMillis() has a performance gap of nearly 100 times compared with Windows Environment.
Reason analysis blog: Slow System.currentTimeMillis();
Baidu simple search found that there are many solutions, the simplest and most direct is to start a thread to maintain a millisecond time stamp to cover JDK's System.currentTimeMillis(), although this will cause some time accuracy problems, but our ID generation algorithm is a second level Unix time stamp, and it doesn't care about the error of tens of microseconds, in exchange for a hundred times performance improvement. This is a well worth expenditure;
The code is as follows:
import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicLong; /** * Cache timestamps solve the performance problem of System.currentTimeMillis() high and send < br > * Root cause analysis: http://pzemtsov.github.io/2017/07/23/the-slow-currenttimemillis.html * * @author: yangzc * @date: 2019-10-19 **/ public class SystemClock { private final long period; private final AtomicLong now; private SystemClock(long period) { this.period = period; this.now = new AtomicLong(System.currentTimeMillis()); scheduleClockUpdating(); } /** * Try to enumerate single examples */ private enum SystemClockEnum { SYSTEM_CLOCK; private SystemClock systemClock; SystemClockEnum() { systemClock = new SystemClock(1); } public SystemClock getInstance() { return systemClock; } } /** * Get singleton object * @return com.cmallshop.module.core.commons.util.sequence.SystemClock */ private static SystemClock getInstance() { return SystemClockEnum.SYSTEM_CLOCK.getInstance(); } /** * Get the current millisecond timestamp * @return long */ public static long now() { return getInstance().now.get(); } /** * Start a thread to refresh the time stamp regularly */ private void scheduleClockUpdating() { ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(runnable -> { Thread thread = new Thread(runnable, "System Clock"); thread.setDaemon(true); return thread; }); scheduler.scheduleAtFixedRate(() -> now.set(System.currentTimeMillis()), period, period, TimeUnit.MILLISECONDS); } }
Epilogue
Q Insufficient, if has the mistake please many instruction, take this to cultivate own blog habit slowly, for the money, flushes the duck!
