1, Foreword
The most important and fundamental aspect of Redis is its rich data structure. The reason why Redis stands out is that it has rich data structure and can support a variety of scenarios. Moreover, Redis's data structure implementation and application scenarios are quite common in the interview. Next, let's talk about Redis's data structure.
Redis has five data structures: string, list, hash, set and sorted set. However, redis also has more advanced data structures, such as HyperLogLog, Geo and BloomFilter. Let's talk about these data structures of redis.
2, String
Basic concept: String is the simplest and most commonly used data structure in Redis and the only data structure in Memcached. In normal development, String can be said to be the most frequently used.
Underlying implementation:
- If a string object stores an integer value and the integer value can be represented by long, the string object will save the integer value in the ptr attribute of the string object structure (convert void * to long) and set the encoding of the string object to int.
- If the string object saves a string value and the length of the string value is greater than 39 bytes, the string object will use a simple dynamic string (SDS) to save the string value and set the encoding of the object to raw.
- If the string object stores a string value and the length of the string value is less than or equal to 39 bytes, the string object will use embstr encoding to save the string value.
use:
> redis_cli # Start redis cli client > set hello world # Set the value of the hello key to world OK # OK will be returned after the set command succeeds > get hello # Get the value with the key hello through the get command "world" # Obtained value > del hello # Delete the value whose key is hello (integer) 1 # The number of deleted items is returned > mset a 10 b 20 c 30 # Batch settings OK > mget a b c # Return value of batch 1)"10" 2)"20" 3)"30" > exists hello # Does the key exist (integer) 1 # 1 indicates existence, 0 indicates nonexistence > expire hello 10 # Set expiration time for hello in seconds (integer) 1 # Returning 1 means success, and 0 means that the key does not exist or the expiration time cannot be set > pexpire hello 10 # Set expiration time for hello in milliseconds (integer) 1 # Returning 1 means success, and 0 means that the key does not exist or the expiration time cannot be set
Next, I will focus on a series of commands set key value [EX seconds] [PX milliseconds] [NX|XX]. This is still very important and easy to be confused.
reids clears the TLL value every time it overwrites the previous value. (TTL is the expiration time)
- EX second: set the expiration time of the key to second seconds. SET key value EX second has the same effect as set key
second value . - PX millisecond: set the expiration time of the key to millisecond. The SET key value PX millisecond effect is equivalent to PSETEX key millisecond value.
- Nx: set the key only when the key does not exist. SET key value NX effect is equivalent to SETNX key value.
- 20: Set the key only when it already exists.
# Use EX option > set key1 hello EX 1000 # Set expiration time 1000s OK > ttl hello # Get the expiration time of hello (integer) 1000 # Use PX option > set key1 hello PX 1000 # Set expiration time 1000ms OK > ttl hello # Get the expiration time of hello (integer) 1000 # Use NX options > set hello world NX OK # Key does not exist, set successfully > get hello "value" > set hello world NX (nil) # Key already exists, setting failed > get hello "world" # Keep the original value unchanged # Use XX option > exists hello # Make sure hello doesn't exist (integer) 0 > set hello world XX (nil) # Setting failed because the key does not exist > set hello wolrd # Set a value for hello first OK > set hello newWolrd XX OK # The setup succeeded this time > get hello "newWorld" # NX or XX can be used in combination with EX or PX > set hello world EX 1000 NX OK > get hello "world" > ttl hello (integer)1000 > set hello wolrd PX 30000 NX OK > pttl hello (integer)30000 # In practice, this value must be less than 30000. This time it is written for the effect # EX and PX can appear at the same time, but the options given later will override the options given earlier > set hello wolrd EX 1000 PX 30000 OK > ttl hello (integer)30 # This is the parameter set by PX, > pttl hello (integer)30000 > set number 1 OK > incr number # Auto increment number (integer) 2
In the development process, it is a common operation to implement locks with redis. Combined with NX and EX.
> set hello world NX EX 10 # Successfully locked. The expiration time is 10s OK > set hello wolrd NX EX 10 # Executing this command within 10s returns an error because the last lock has not been released (nil) > del hello # The lock was released OK > set hello world NX EX 10 # Successfully locked. The expiration time is 10s OK > setnx hello world # You can also write that > setex hello 10 wolrd
Locks can be released by setting expiration time and manual del deletion.
string commands are commonly used, so I'll introduce them more. I'll focus on the following commands.
Application scenario:
- Caching function: string is the most commonly used caching function. It will cache some data that are not updated frequently but queried frequently, so as to reduce the pressure on DB.
- Counter: it can be used to count through incr operations, such as statistics of website visits, article visits, etc.
3, List
Basic concept: List is an ordered and repeatable List, which is similar to Java List. It has fast query speed and can be queried through index; Insertion and deletion are slow.
Underlying implementation:
- The encoding of the list object can be ziplist or linkedlist. >- The len gt h of all string elements saved by the list object is less than 64 bytes, and the number of saved elements is less than 512. Zip list encoding is used; Otherwise, use linkedlist;
use:
> lpush mylist a # Insert data from left (ineteger)1 > lpush mylist b (integer)1 > rpush mylist c # Insert data from the right (integer)1 > lrange mylist 0 -1 # To retrieve data, lrange needs two indexes, closed on the left and closed on the right; 0 is from 0, - 1 is the last to last, - 2 is the last to last... And so on 1)"b" 2)"a" 3)"c" > lrange mylist 0 -2 # 0 to penultimate 1)"b" 2)"a" > lpush mylist a b c # Batch insert (integer)3 > lpop mylist # Pop up element from left "b" > rpop mylist # Pop up element from right "c" > rpop mylist # Returns null when there are no elements in the list (nil) > brpoop mylist 5 # Pop up elements from the right. If there are no elements in the list, it will be blocked. If there are still no elements after 5 s, it will return 1)"mylist" # List name 2)"b" # Pop up element > del mylist # Delete list (integer)1
Usage scenario:
- Message queue: Redis's list is an ordered list structure, which can block the queue in a left in right out manner. Lpush is used to produce data inserted from the left, Brpop is used for consumption, and it is used to block consumption data from the right.
- Paging display of data: the lrange command requires two indexes to obtain data, which can be used to realize paging. You can calculate two index values in the code, and then retrieve data from redis.
- It can be used to realize functions such as fan list and ranking of the latest news.
4, Hash
Introduction: Redis hash can store mappings between multiple key value pairs. Like a string, the value stored in the hash can be either a string or a numeric value, and the user can also perform self increment or self decrement on the numeric value stored in the hash. This is very similar to the Java HashMap. Each HashMap has its own name and can store multiple k/v pairs at the same time.
Underlying implementation:
- The encoding of the hash object can be ziplost or hashtable >
- The string length of keys and values of all key value pairs saved by the hash object is less than 64 bytes, and the number of key value pairs saved is less than 512, which is encoded by ziplist; Otherwise, use hashtable;
use:
> hset student name Zhang San # It can be understood as forgetting to add kv key value pairs to the map named student (integer)1 # Returning 1 means that the key does not exist and is added successfully > hset student sex male (integer)1 > hset student name Zhang San (integer)0 # Return 0 because the key already exists > hgetall student 1)"name" 2)"Zhang San" 3)"sex" 4)"male" > hdel student name #Delete this key (integer)1 # Returning 1 also means that the entire key exists and is deleted successfully > hdel student name (integer)0 # 0 is returned because the key no longer exists
Application scenario:
- Hash is more suitable for storing structured data, such as objects in Java; In fact, objects in Java can also be stored in strings. You only need to serialize the objects into json strings. However, if a property of the object is updated frequently, you need to serialize and store the whole object again each time, which consumes a lot of overhead. If you use hash to store each attribute of an object, you only need to update the attribute to be updated each time.
- Shopping cart scenario: you can take the user's id as the key, the commodity id as the stored field, and the commodity quantity as the value of the key value pair, which constitutes the three elements of the shopping cart.
5, Set
Basic concept: both set and list of Redis can store multiple strings. The difference between them is that list is orderly and repeatable, while set is unordered and non repeatable.
Underlying implementation:
- The code of the collection object can be intset or hashtable. >- All elements saved by the collection object are integer values, and the number of saved elements does not exceed 512. Intset encoding is used; Otherwise, use hashtable;
use:
> sadd family mother # Try adding mother to the family collection (integer)1 # Returning 1 indicates that the addition is successful, and 0 indicates that the element already exists in the collection > sadd family father (integer)1 > sadd family father (intger)0 > smembers family # Gets all the elements in the collection 1)"mother" 2)"father" > sismember family father # Determine whether the father is in the family set (integer)1 # 1 exist; 0 does not exist > sismber family son (integer)0 > srem family son # Remove the element son from the family collection (integer)1 # 1 indicates existence and successful removal; 0 indicates that the element exists > srem family som (integer)0 > sadd family1 mother (integer)1 > smembers family 1)"mother" 2)"father" > smember family1 1)"mother" > sinter family family1 # Gets the intersection of family and family1 1)"mother" > sadd family1 son (integer)1 > sunion family family1 # Gets the union of family and family1 1)"mother" 2)"father" > sdiff family family1 # Get the difference set between family and family1 (that is, the elements that family has but family1 does not) 1)"father"
Application scenario:
- Tags: you can store the tags of each person in the blog site with a set collection, and then merge users according to each tag.
- Store friends / fans: set has the function of de duplication; You can also use the set union function to get functions such as common friends.
6, Sorted Set
Basic concept: like hash, an ordered set is used to store key value pairs: each key of an ordered set is called a member and is unique, while each value of an ordered set is called a score and must be a floating point number. It can be sorted according to scores. The ordered set is the only one in Redis. It can access elements according to members (this is the same as hashing), and access the structure of elements according to scores and the order of scores. Like other Redis structures, users can add, remove, and obtain ordered collections.
Underlying implementation:
- The encoding of an ordered set can be ziplist or skiplist
- The number of elements saved in the ordered collection is less than 128, and the length of all element members saved is less than 64 bytes. Use zip list encoding; Otherwise, use skiplist;
use:
> zadd class 100 member1 # Add the member1 element and its score value of 100 to the ordered collection class (integer)1 > zadd class 90 member2 80 member3 # Batch add (integer)2 > zrange class 0 -1 withscores # Get the values and scores in the ordered collection and sort by score 1)"member3" 2)"80" 3)"member2" 4)"90" 5)"member1" 6)"100" > zrem class member1 # Delete member1 in class (integer)1
Application scenario:
- Ranking list: the most commonly used scenes of ordered collection. For example, news websites sort hot news, such as according to the number of hits, likes, etc.
- Message queue with weight: important messages have a larger score and ordinary messages have a smaller score. Tasks with high priority can be executed first.
7, Hyperlog
Basic concepts:
Redis added the hyperlog structure in version 2.8.9.
-
Redis HyperLogLog is an algorithm for cardinality statistics, HyperLogLog
The advantage is that when the number or volume of input elements is very, very large, the space required to calculate the cardinality is always fixed and small. -
In Redis, each hyperlog key only needs 12 KB of memory to calculate the base of nearly 2 ^ 64 different elements
Number. This is in sharp contrast to a collection where the more elements consume more memory when calculating the cardinality. -
However, because HyperLogLog only calculates the cardinality based on the input element and does not store the input element itself, HyperLogLog
You cannot return input elements like a collection.
use:
Here is an example of how many users logged in on a statistical website on May 23, 2021
> pfadd user_login_20210523 tom # user_login_20210523 is the key; tom is the logged in user (integer)1 > pfadd user_login_20210523 tom jack lilei User (integer)1 > pfcount user_login_20210523 # Get the number of key corresponding values. The same user can log in multiple times only once (integer) 3 > pfadd user_login_20210522 sira (integer)1 > pfcount user_login_20210523 user_login_20210522 # Count the number of login users on the 22nd and 23rd (integer)4 >pfmerge user_login_20210522_23 user_login_20210522 user_login_20210523 # Merge multiple key contents "OK" > pfcount user_login_20210522_23 (integer)4
Application scenario:
- It can be used to count the number of visitors to the website and other indicators
8, GEO
Basic concepts:
In redis version 3.2, a new data structure called geo is added, which is mainly used to store geographic location information and operate the stored information.
use:
geoadd is used to store the specified geospatial location. You can add one or more longitude, latitude and location name (member) to the specified key.
> GEOADD beijing 116.405285 39.912835 "Mushrooms can't sleep" (integer)2
geopos is used to return the positions (longitude and latitude) of all specified members from a given key, and nil if it does not exist.
> GEOPOS beijing "Mushrooms can't sleep" "the Imperial Palace" 1) 1)116.405285 2)39.912835 2)(nil)
geodist is used to return the distance between two given locations.
Unit parameters:
- m: Meter, default unit.
- km: kilometers.
- mi: miles.
- ft: feet.
> GEOADD beijing 116.403681 39.921156 "the Imperial Palace" (integer)1 > GEODIST beijing "Mushrooms can't sleep" "the Imperial Palace" km "0.936"
Application scenario:
-
A scene used to store and manipulate geographic information.
-
A little knowledge of Geography:
Longitude range: - 180 - 180. Calculated from the 0 ° longitude, it is divided into 180 ° to the East and 180 ° to the West. The 180 ° to the East belongs to the east longitude, and it is customary to use "E" as the code. The 180 ° to the West belongs to the west longitude, and it is customary to use "W" as the code. 0 ° position: the meridian at the center of the meridian at Greenwich Observatory is the primary meridian.
Latitude range: - 90 - 90. The latitude of the point north of the equator is called north latitude, which is recorded as N; The latitude of the point south of the equator is called south latitude and is recorded as S. For the convenience of studying problems, people divide latitude into low latitude
Middle and high latitudes. 0 ° ~ 30 ° is low latitude, 30 ° ~ 60 ° is middle latitude and 60 ~ 90 ° is high latitude**
9, BloomFilter
Basic concepts:
A data structure is composed of a long string of binary vectors, which can be regarded as a binary array. Since it is binary, it stores either 0 or 1, but the initial default value is 0. His main function is to judge whether an element is in a set. For example, I want to judge whether there is a number among the 2 billion numbers. If I plug in DB directly, the data volume is too large and the time will be very slow; If you put 2 billion data into the cache, the cache will not fit. At this time, the bloom filter is most suitable. The principle of the bloom filter is:
- Add element when we want to add an element key to the bloom filter, we calculate a value through multiple hash functions, and then set the square where the value is located to 1.
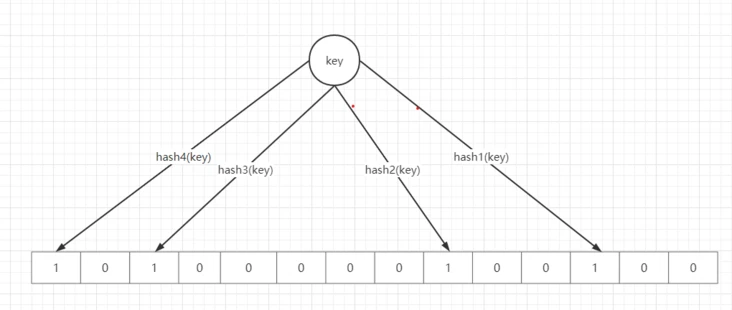 >- determine whether the element exists:
>- determine whether the element exists:
To judge whether an element exists, first calculate the element through multiple hash functions to multiple subscript values, and then judge whether the element values corresponding to these subscripts are all 1. If they exist, they are not 1
, then the element must not be in the set; If it's all
1. If the element probability is in the set, it is not 100% certain that the element exists in the set. Because the results calculated by multiple different data through the hash function will be repeated, there will be a position where other data is set to 1 through the hash function. In general, the bloom filter can judge that a certain data must not exist, but it cannot judge that it must exist. - Advantages and disadvantages of Bloom filter:
- Advantages: the advantages are obvious. The binary array occupies very little memory, and the insertion and query speed are fast enough.
- Disadvantages: with the increase of data, the misjudgment rate will increase; Also, it is impossible to judge that the data must exist; Another important disadvantage is that data cannot be deleted.
use:
RedisBloom, a plug-in of Bloom filter, can be used after redis 4.0. The command is as follows:
bf.add Add element to bloom filter bf.exists Determine whether the element is in the bloom filter bf.madd Add multiple elements to the bloom filter, bf.add Only one can be added bf.mexists Determine whether multiple elements are in the bloom filter > bf.add boomFilter tc01 (integer) 1 # 1: Existence; 0: does not exist > bf.add boomFilter tc02 (integer) 1 > bf.add boomFilter tc03 (integer) 1 > bf.exists boomFilter tc01 (integer) 1 > bf.exists boomFilter tc02 (integer) 1 > bf.exists boomFilter tc03 (integer) 1 > bf.exists boomFilter tc04 (integer) 0 > bf.madd boomFilter tc05 tc06 tc07 1) (integer) 1 2) (integer) 1 3) (integer) 1 > bf.mexists boomFilter tc05 tc06 tc07 tc08 1) (integer) 1 2) (integer) 1 3) (integer) 1 4) (integer) 0
- Redisson uses Bloom filters:
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.15.105:6379");
config.useSingleServer().setPassword("password123");
//Construct Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("userPhones");
//Initialize bloom filter: the estimated element is 500000000L, and the error rate is 3%
bloomFilter.tryInit(500000000L,0.03);
//Insert the number 10086 into the bloom filter
bloomFilter.add("18846014678");
//Determine whether the following numbers are in the bloom filter
System.out.println(bloomFilter.contains("18846014678")); //true
System.out.println(bloomFilter.contains("1111111222")); //false
}
- Guava uses a bloom filter:
//Guava is a Java toolkit provided by Google, which is very powerful
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), 500000, 0.01);
bloomFilter.put("18846047789");
System.out.println(bloomFilter.mightContain("18846047789")); // true
System.out.println(bloomFilter.mightContain("1122222")); //false
}
}
Application scenario:
- Solve the cache penetration problem: in general, the query scenario is to query the cache first. If there is no cache, then query the DB. If it is found, it will be stored in the cache first and then returned to the caller. If it cannot be found, it returns null. In this case, if someone frequently requests no data in the cache, such as data with id = -1, it will cause great pressure on the DB. In this case, the redis bloom filter can be used. The possible IDS can be stored in the bloom filter first. When the query comes, go to the Bloom filter first. If it cannot be found, it will be returned directly, and the cache and DB will not be requested, If present
In the bloom filter, the data is fetched from the cache. - Blacklist verification: you can put the ip in the blacklist into the bloom filter, so you don't have to query the db every time you come.