background
In the high concurrency scenario of the Internet, there will be a lot of requests, but the database connection pool is relatively small, or the CPU pressure and processing logic need to be reduced. It is necessary to change a single query to batch query multiple and return. For example, in Alipay, query "personal information", users will only trigger a request to query their own information, but many individuals at the same time will produce multiple database connections. In order to reduce the connection, it is necessary to make a merge request on the JAVA server, merge multiple "personal information" query interfaces into batch query multiple "personal information" interfaces, and then use the id of personal information in the database as the Key to return to the upstream system or page URL and other callers.
objective
- Reduce access to databases
- Multiple requests in unit time are combined into one request. Let the business logic layer change the single query sql to batch query sql. Or redis needs to be called in logic, and redis pipeline can be used in batch logic.
- This time, we need to use the JDK native method to implement the request merging. Because you don't necessarily have Hystrix, we need to use the native method to implement it and analyze how it is implemented in Hystrix collapser.
Let's look at the official account: the idea of "underground Tibet" to share with you the design and architecture of the Internet scenario. Nuggets: Kelvin https://juejin.im/user/5d67da8d6fb9a06aff5e85f7
Main solutions
- Custom HystrixCollapse and HystrixCommand of Hystrix of spring cloud
- Hystrix annotation of spring cloud.
- When there is no service governance framework, JDK queue and timed task thread pool are used for processing.
In the previous chapter, I have already mentioned the first two. Since some students don't have spring cloud, I use the third one to do request merging and analyze the principle of request merging together.
It is suggested to read the first chapter first, and the second chapter is equivalent to the description of the internal principle of hystrix collapser High concurrency scenario - Request merging (I) Hystrix request merging in spring cloud
Interaction process
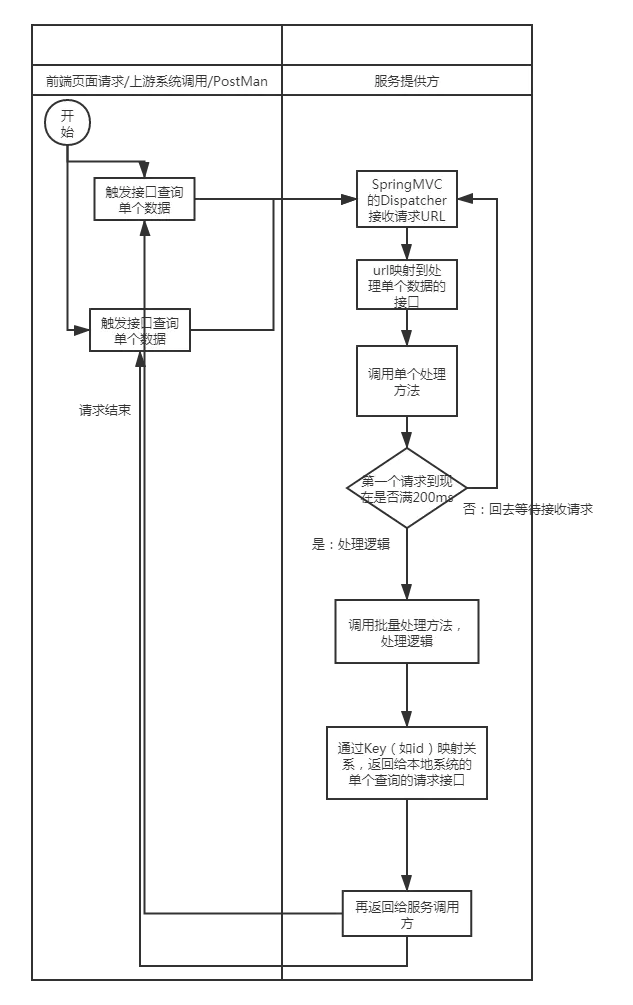
Development
This chapter is developed by using JDK native package, so there are not so many things to configure as spring cloud. There is only one class to write code.
1. Create request layer
Only the interface of a single query needs to be exposed, and the logic of request merging needs to be done in the business logic layer.
@RestController public class UserController { @Autowired private UserBatchWithFutureServiceImpl userBatchWithFutureServiceImpl; @RequestMapping(method = RequestMethod.GET,value = "/userbyMergeWithFuture/{id}") public User userbyMergeWithFuture(@PathVariable Long id) throws InterruptedException, ExecutionException { User user = this.userBatchWithFutureServiceImpl.getUserById(id); return user; } }
2. Request to merge logic layer
- Create request merge logical entry
- Create a blocking queue to accumulate multiple request parameters
- Create the completabilfuture class. In order to block this thread, asynchronously obtain the User result information corresponding to the current id after batch query processing.
- Execute the completabilefuture.get method to wait for asynchronous result notification.
@Component public class UserBatchWithFutureServiceImpl { /** Blocking queue for accumulating requests */ private LinkedBlockingDeque<UserQueryDto> requestQueue = new LinkedBlockingDeque<>(); public User getUserById(Long id) throws InterruptedException, ExecutionException { UserQueryDto userQueryDto = new UserQueryDto(); userQueryDto.setId(id); CompletableFuture<User> completedFuture = new CompletableFuture<>(); userQueryDto.setCompletedFuture(completedFuture); requestQueue.add(userQueryDto); User user = completedFuture.get(); return user; }
HystrixCollapser also uses this method to make asynchronous notification, and let the main thread of the request interface block and wait before getting the real result.
3. Scheduled tasks
Create a timing task under the same class, use @ PostConstruct to execute the method after the Bean of the current class is constructed, and generate a 5-second timing task. You can set the timing time. I used 5 seconds for the convenience of testing.
/** Number of thread pools */ private int threadNum = 1; /** Time interval */ private long period = 5000; @PostConstruct public void init() { ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(createDeviceMergeNum); // Every 5 seconds scheduledExecutorService.scheduleAtFixedRate(new UserBatchThread(), 0, createDeviceMergePeriod, TimeUnit.MILLISECONDS); }
The HystrixCollapser processes the execution of a single method to batch method every n milliseconds, which is also implemented by this type of method.
4. Create an internal class under the UserBatchWithFutureServiceImpl class
Internal classes are created to perform this logic for scheduled tasks, and for code neatness, generous block code is not written when creating thread pools.
In the internal class, the main logic is:
- Get all members from the requestQueue queue where the request interface parameters are stored, and put them into the local variable of the trigger task logic
- And take the key request parameter id and put it into the local variable List.
- As long as the variables are retrieved, batch query is performed
- Finally, we use CompletedFuture to asynchronously notify and wake up the thread waiting for getUserById method.
public class UserBatchThread implements Runnable { @Override public void run() { List<UserQueryDto> requestQueueTmp = new ArrayList<>(); // Store the input parameters of batch query List<Long> requestId = new ArrayList<>(); // Take out the elements of the message queue put in the request layer int size = requestQueue.size(); for (int i = 0; i < size; i++) { UserQueryDto request = requestQueue.poll(); if (Objects.nonNull(request)) { requestQueueTmp.add(request); requestId.add(request.getId()); } } if (!requestId.isEmpty()) { try { List<User> response = getUserBatchById(requestId); Map<Long, User> collect = response.stream().collect( Collectors.toMap(detail -> detail.getId(), Function.identity(), (key1, key2) -> key2)); // Thread of notification request for (UserQueryDto request : requestQueueTmp) { request.getCompletedFuture().complete(collect.get(request.getId())); } } catch (Exception e) { // Thread of notification request - exception requestQueueTmp.forEach(request -> request.getCompletedFuture().obtrudeException(e)); } } } } public List<User> getUserBatchById(List<Long> ids) { System.out.println("Enter batch processing method" + ids); List<User> ps = new ArrayList<>(); for (Long id : ids) { User p = new User(); p.setId(id); p.setUsername("dizang" + id); ps.add(p); } return ps; }
The elements put into the queue in the request interface will be taken out from here. HystrixCollasper also uses this poll method to obtain the elements in the queue atomically, which will not be repeatedly triggered by the scheduled tasks. As long as at least one of them is satisfied, a batch query will be done. When the HystrixCollasper merges the requests, even if there is only one request in n milliseconds, it will process it.
Test verification
- Trigger the swagger UI page as in the previous chapter
- Request two different parameters
- The result is as shown in the figure below. The console log has output the requested input parameters twice

summary
I believe that everyone has completed the merge request. This time, we do not rely on the framework. Based on the original approach, we use the queue to store and query the required input parameters, and then use the thread pool to obtain the input parameters of the queue at a fixed time, and then batch process them, and use the Future of the thread to do asynchronous return results. In this way, we understand the internal process of hystrix collapser of spring cloud. I hope to be able to help students in the case of projects without framework or unsuitable technology stack of the company.
This article Demo
It's all in my spring cloud demo. Look at the content under the project provider hystrix request merge. It's in the UserBatchWithFutureServiceImpl class.
https://gitee.com/kelvin-cai/spring-cloud-demo
Welcome to the official account. The article is a step faster.
My official account: the thought of Tibetan

Nuggets: Kelvin
Jianshu: Kelvin
My Gitee: Kelvin https://gitee.com/kelvin-cai