Differences between Hashtable, Collections.SynchronizedMap, and Concurrent HashMap thread security implementation principles and performance testing
These three Map s are important collection classes in Java, and although the first two are less common, their comparison has become a high-frequency test point for Java interviews because of their multithreaded nature.First of all, it should be noted that each of them alone is sufficient to support a long technical article, so this paper focuses on the comparison of thread security implementation principles and performance testing of the three collection classes, other details are not discussed in depth.
1. Thread Security Principles Comparison
1. Hashtable
First of all, you have to spit out this kind of name. As an official tool class, it doesn't conform to the rules of hump naming. No wonder it was abandoned. The main reason is poor performance. Why is the poor performance of Hashtable? Just look at its source code and see the following are some of the more important methods in Hashtable:
public synchronized V put(K key, V value) {...} public synchronized V get(Object key) {...} public synchronized int size() {...} public synchronized boolean remove(Object key, Object value) {...} public synchronized boolean contains(Object value) {...} ... ...
Looking at the source code, you can see that Hashtable's principle of thread security is fairly straightforward, using the synchronized keyword directly on the method declaration.This way, no matter which method the thread executes, even if it reads data only, the entire Hashtable object needs to be locked, and its concurrency performance is unlikely to be good.
2. Collections.SynchronizedMap
SynchronizedMap is a private static internal class of the Collections collection class, which is defined and constructed as follows:
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable { private static final long serialVersionUID = 1978198479659022715L; // Used to receive incoming Map objects as well as class method operations private final Map<K,V> m; // Lock Object final Object mutex; // Here are two construction methods for SynchronizedMap SynchronizedMap(Map<K,V> m) { this.m = Objects.requireNonNull(m); mutex = this; } SynchronizedMap(Map<K,V> m, Object mutex) { this.m = m; this.mutex = mutex; } }
- SynchronizedMap has three member variables, the serialized ID aside, and the other two are Map type instance variables m, which receive Map parameters passed in from the construction method and Object type instance variables mutex, which are used as lock objects.
- Looking at the construction methods, SynchronizedMap has two construction methods.The first construction method needs to pass in a Map-type parameter, which is passed to the member variable M. Next, all SynchronizedMap methods operate on M. It is important to note that this parameter cannot be empty, otherwise a null pointer exception will be thrown by the requireNonNull() method of the Objects class, and then the current SynchronizedMap object this willMutex is passed as the lock object; the second construction method has two parameters, the first Map type parameter is passed to the member variable m, and the second Object type parameter is passed to mutex as the lock object.
-
Finally, take a look at the main methods of SynchronizedMap (only a few selected):
public int size() { synchronized (mutex) {return m.size();} } public boolean isEmpty() { synchronized (mutex) {return m.isEmpty();} } public boolean containsKey(Object key) { synchronized (mutex) {return m.containsKey(key);} } public V get(Object key) { synchronized (mutex) {return m.get(key);} } public V put(K key, V value) { synchronized (mutex) {return m.put(key, value);} } public V remove(Object key) { synchronized (mutex) {return m.remove(key);} }
From the source code, it can be seen that SynchronizedMap's method of thread security is also simpler, all of which are to lock the mutex of the lock object first, then directly call the related method of the member variable m of the Map type.This way, when a thread executes a method, it can only operate on m if it first acquires a mutex lock.Therefore, like Hashtable, only one thread can operate on a SynchronizedMap object at the same time, which guarantees thread security but results in poor performance.So, even Hashtable has been deprecated, what is the need for SynchronizedMap, which has the same low performance?Don't forget that the latter constructs by passing in a Map-type parameter, that is, it can turn a non-thread-safe Map into a thread-safe Map, which makes sense. Here's an example of how SynchronizedMap can be used (multithreaded operations are not demonstrated here):
Map<String, Integer> map = new HashMap<>(); //Non-threaded safe operation map.put("one", 1); Integer one = map.get("one"); Map<String, Integer> synchronizedMap = Collections.synchronizedMap(map); //Thread-safe operation one = synchronizedMap.get("one"); synchronizedMap.put("two", 2); Integer two = synchronizedMap.get("two");
3. ConcurrentHashMap
Next comes ConcurrentHashMap, which has the most complex data structure and thread security principles.First of all, you have to exclamate the complexity of this class's structure (including 53 internal classes) and the sophistication of its design (I don't know how to describe it, but it's sophisticated anyway). It's amazing.To be honest, it takes quite a solid foundation and a lot of effort to fully understand the details of ConcurrentHashMap.Unfortunately, my strength is limited, so this paper's analysis of the principles of ConcurrentHashMap is just a taste, but it should be more than enough for an interview.Students who want to have a better understanding can go to the portal at the end of the article.In addition, this article highlights ConcurrentHashMap for JDK version 1.8, but gives a brief review of JDK version 1.7.
3.1 JDK 1.7 ConcurrentHashMap Lock Implementation Principle Review
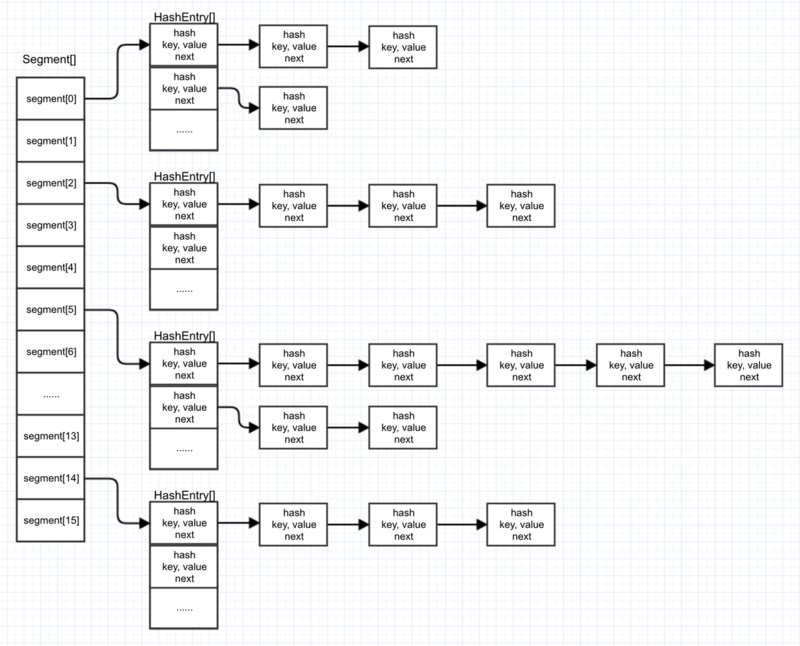
Java7 ConcurrentHashMap structure diagram
If you have a foundation, you should know the concept of segmented locks.Yes, this is the primary thread security tool for Concurrent HashMap JDK version 1.7, specifically Segment + HashEntry + ReentrantLock.Simply put, ConcurrentHashMap is an array of Segments (the default length is 16), and each Segment contains an array of HashEntry, so it can be seen as a HashMap. Segments lock by inheriting ReentrantLock, so each operation that needs to be locked locks a Segment, so as long as each Segment is thread safe.Global thread security is implemented.
3.2 JDK 1.8 ConcurrentHashMap Thread Security Principles Detailed

Java8 ConcurrentHashMap structure diagram
JDK version 1.8 abandoned the heavier Segment Lock design in previous versions and replaced it with the Node Array + CAS + synchronized + volatile new design.As a result, ConcurrentHashMap not only simplifies the data structure (similar to the HashMap of JDK 1.8), but also reduces the granularity of locks, changing the units of locks from Segments to buckets in Node arrays (science: buckets are data collections at a subscript position in an exponential group, which may be a chain table or a red-black tree).When it comes to red-black trees, it must be mentioned that in HashMap and Concurrent HashMap of JDK 1.8, if the chain table length at an array location is too long (greater than or equal to 8), it will be converted to a red-black tree to improve query efficiency, but this is not the focus of this article.The following is a detailed description of the thread security principles of ConcurrentHashMap:
3.2.1 get operation process
You can find that there is no lock at all in the source code, and the reason will be explained later
- First calculate the hash value, navigate to the table index position, and return if the first node matches
- If you encounter an expansion, the find method flagged ForwardingNode is being expanded, find the node, and match returns
-
If none of the above is true, iterate down the node and the match will return, otherwise null will be returned in the end
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); //Calculate hash if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) {//Read Node Element of Head Node if ((eh = e.hash) == h) { //Return if the node is the first node if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //A negative hash value indicates expansion, and this time the find method of ForwardingNode is checked to locate the nextTable //EH stands for the hash value of the header node, eh=-1, indicating that the node is a ForwardingNode and is migrating. At this time, call the find method of ForwardingNode to look in the nextTable. //eh=-2, indicating that the node is a TreeBin, at which point the Find method of TreeBin is called to traverse the red-black tree. Since the red-black tree may be rotating and discoloring, there will be read-write locks in the find. //Eh>=0, indicating that there is a chain table hanging under this node, which can be traversed directly. else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) {//Neither the first node nor ForwardingNode, traverse down if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }
Some students may ask: Why doesn't the get operation need to be locked?Well, you also need to look at the source code:
/** * The array of bins. Lazily initialized upon first insertion. * Size is always a power of two. Accessed directly by iterators. * This is a member variable of ConcurrentHashMap, a volatile-modified ode array that guarantees visibility to other threads as the array expands * It is also important to note that this array is delayed and will be initialized at the first put element, which will be used later. */ transient volatile Node<K,V>[] table; /** * This is the definition of the ConcurrentHashMap static internal class Node, whose member variables val and next are decorated with volatile to ensure that * Thread A is visible to thread B when it modifies the val ue of a node or adds a node in a multithreaded environment */ static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; }
Using the volatile keyword is sufficient to ensure that threads do not read dirty data when reading data, so there is no need to lock it.
3.2.2 put operation process
- The first put element initializes the Node array (initTable)
- put operations are also divided into insertion in the presence of a key (hash collision) and insertion in the absence of a key.
- put operation may cause array expansion (tryPresize) and treeifyBin
- Extensions use the data migration method (transfer)
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); // Get hash value int hash = spread(key.hashCode()); // Used to record the length of the corresponding chain table int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // Initialize the array if it is empty if (tab == null || (n = tab.length) == 0) // Initialization of tables, not expanded here, the core idea is to use sizeCtl variables and CAS operations to control, to ensure that arrays are expanded // No extra tables will be created tab = initTable(); // Find the array subscript corresponding to the hash value to get the first node f else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // If this position of the array is empty, you can put this new value into it with a CAS operation, and the put operation is almost complete // If CAS fails, there are concurrent operations, just go to the next loop (loop means that CAS will //retry after execution fails) if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) // Help with data migration, tab = helpTransfer(tab, f); else { // So here, f is the head node of that location, and it's not empty V oldVal = null; // Gets the header node lock object at this location of the array synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { // The hash value of the header node is greater than 0, indicating that it is a chain table // For accumulation, record the length of the chain table binCount = 1; // Traversing a list of chains for (Node<K,V> e = f;; ++binCount) { K ek; // If an "equal" key is found, determine if a value override is required, and then break is possible if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } // To the end of the list, put this new value at the end of the list Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { // red-black tree Node<K,V> p; binCount = 2; // Call the interpolation method of the red-black tree to insert a new node if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { // To determine if a chain table is to be converted to a red-black tree, the critical value is 8, just like HashMap if (binCount >= TREEIFY_THRESHOLD) // This method differs slightly from HashMap in that it does not necessarily perform a red-black tree conversion. // If the length of the current array is less than 64, then you will choose to expand the array instead of converting it to a red-black tree treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }
The above is the source code and analysis of put method. Other methods involved, such as initTable, helpTransfer, treeifyBin and tryPresize, are no longer expanded one by one. Interested students can go to the end portal to see the detailed analysis.
3.2.3 CAS Operation Brief Introduction
The CAS operation is the essence of the new ConcurrentHashMap thread security implementation. If volatile is the sole thread security mechanism for reading shared variables, then in addition to using a small number of synchronized keywords, the storage and modification process relies primarily on CAS operations for thread security.Students who don't know CAS operation see here Deep Analysis of JAVA CAS Principle
// Providers of CAS operations private static final sun.misc.Unsafe U; // The following is a snippet of code that uses CAS operations in the put method else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; } // The tabAt method obtains elements on the corresponding index of the array by Unsafe.getObjectVolatile(), which acts on pairs // The corresponding memory offset is volatile memory semantics. static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); } // If the fetch is empty, try CAS to create a new Node on the specified index of the array. static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) { return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v); }
In ConcurrentHashMap, processes such as array initialization, insertion and deletion of elements, expansion, data migration, and conversion of chained lists and red and black trees all involve thread security issues. The idea of thread security in related methods is consistent: synchronized keywords are used when adding or modifying data in buckets, that is, to get the head node at that location.Object lock, which ensures thread safety, also uses a large number of CAS operations.This is a brief introduction to the threading security principles of these three Maps.
2. Performance testing
Direct Up Code
public class MapPerformanceTest { private static final int THREAD_POOL_SIZE = 5; private static Map<String, Integer> hashtableObject = null; private static Map<String, Integer> concurrentHashMapObject = null; private static Map<String, Integer> synchronizedMap = null; private static void performanceTest(final Map<String, Integer> map) throws InterruptedException { System.out.println(map.getClass().getSimpleName() + "Performance testing started... ..."); long totalTime = 0; // Perform five performance tests, five threads at a time, 50,000 query and 50,000 insert operations on a map per thread for (int i = 0; i < 5; i++) { long startTime = System.nanoTime(); ExecutorService service = Executors.newFixedThreadPool(THREAD_POOL_SIZE); for (int j = 0; j < THREAD_POOL_SIZE; j++) { service.execute(() -> { for (int k = 0; k < 500000; k++) { Integer randomNumber = (int)Math.ceil(Math.random() * 500000); // Find data from map, find results will not be used, return value cannot be received with int here, because Integer may be // Null, assigning an int causes a null pointer exception Integer value = map.get(String.valueOf(randomNumber)); //Add elements to map map.put(String.valueOf(randomNumber), randomNumber); } }); } //Close Thread Pool service.shutdown(); service.awaitTermination(Long.MAX_VALUE, TimeUnit.DAYS); long endTime = System.nanoTime(); // Single Execution Time long singleTime = (endTime - startTime) / 1000000; System.out.println("No." + (i + 1) + "Time-consuming second test" + singleTime + "ms..."); totalTime += singleTime; } System.out.println("Time per request" + totalTime / 5 + "ms..."); } public static void main(String[] args) throws InterruptedException { //Hashtable Performance Test hashtableObject = new Hashtable<>(); performanceTest(hashtableObject); //SynchronizedMap Performance Test Map<String, Integer> map = new HashMap<>(500000); synchronizedMap = Collections.synchronizedMap(map); performanceTest(synchronizedMap); //ConcurrentHashMap Performance Test concurrentHashMapObject = new ConcurrentHashMap<>(5000000); performanceTest(concurrentHashMapObject); } }
Here's a point to illustrate that the results of this code will vary in different environments, but the magnitude comparison of the results should be consistent. Here's what happens on my machine:
Map Performance Test Results
The results show that Hashtable and SynchronizedMap perform almost identically on 2.5 million data access levels because their lock implementations are very similar, while ConcurrentHashMap has a large performance advantage and takes only a little more than a third of the time.Hmm... when asked a question later in the interview, you can just throw the data away to the interviewer...
3. Conclusion
Okay, that's all for this article. Finish sprinkling.The first time I wrote a blog, I was really nagging so much. What's more, I would like you to look at the old officials and give them your advice.In addition, those who want to learn more about the principles of ConcurrentHashMap can see the following two articles, which I have read in more detail.
Understand how ConcurrentHashMap ensures thread security in Java8
Full Resolution of HashMap and Concurrent HashMap in Java 7/8