I believe everyone has read a lot of articles about thread pools, which are also necessary for interviews. If you still know a little after reading a lot of articles, I hope this article can really help you master Java thread pools.
A major focus of this article is source code parsing, with a small amount of space to introduce thread pool design ideas and some clever uses in the author's implementation of Doug Lea.This article will also analyze one line of key code, in order to let those students who do not understand the source code can be referred to.
Thread pools are an important tool, and if you want to be a good engineer or have a good grasp of them, many of the online problems are caused by not using them well.Even if you make a living, you need to know that this is essentially a question that must be asked during an interview, and it is easy for an interviewer to capture the interviewee's technical level from the interviewee's answers.
This is a slightly longer article and suggests reading on the pc, flipping through the source while reading the article (Java7 and Java8 are the same), suggesting that readers who want to take a good look take at least 30 minutes to read it.Of course, if the reader is only preparing for the interview, he or she can slide directly to the final summary.
Overview
Start with some nonsense.The following is an inheritance structure of several related classes of the java thread pool:
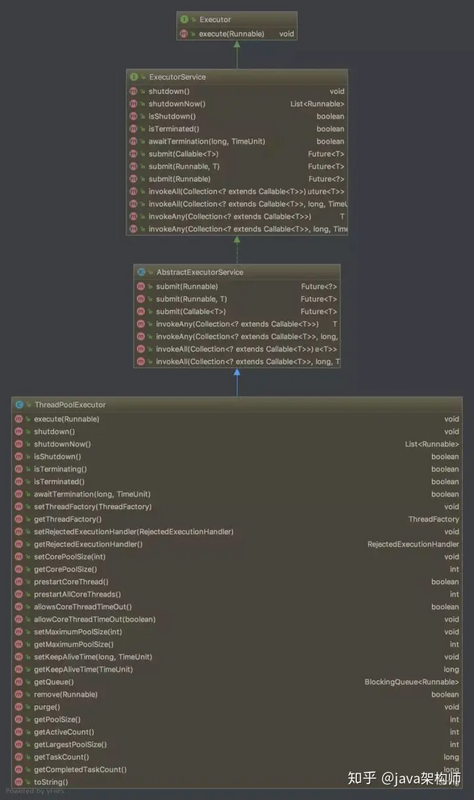
To start with this inheritance structure, Executor is at the top and simplest level, defined by an execute(Runnable runnable) interface method.
ExecutorService is also an interface. There are many interface methods added to the Executor interface, so we generally use this interface.
The next level is AbstractExecutorService, which, as we know by name, is an abstract class, which implements some very useful methods for direct use by subclasses, and we'll go into detail later.
Then we came to our main section, the ThreadPoolExecutor class, which provides a very rich set of functionality for thread pools.
In addition, we'll cover these classes in the following figure:

As with the Executors class in the concurrent package, with the letter s in the class name, we guess this is a tool class, where methods are static, such as the following which we most commonly use to generate instances of ThreadPoolExecutor:
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); } public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
In addition, since thread pooling supports getting the results of thread execution, the Future interface is introduced, from which RunnableFuture inherits, and then the most important thing we need to worry about is its implementation class FutureTask.At this point, keep in mind the concept that during the use of thread pools, we submit tasks to the thread pool. As anyone who has used thread pools knows, each task we submit implements the Runnable interface by wrapping Runnable tasks into FutureTasks before submitting them to the thread pool.This makes it easier for readers to remember the FutureTask class name: it starts with a task (Task), then has the semantics of the Future interface, which can be executed in the future.
Of course, BlockingQueue in the thread pool is also a very important concept. If the number of threads reaches corePoolSize, each of our tasks is submitted to the waiting queue, waiting for the threads in the thread pool to fetch and execute the task.Here, BlockingQueue is usually used by its implementation classes LinkedBlockingQueue, ArrayBlockingQueue, and SynchronousQueue, each of which has different characteristics and is slowly analyzed after using the scenario.For readers who want to know more about each BlockingQueue, you can refer to my previous article that analyzed the implementation classes of BlockingQueue in detail.
Complete the story: In addition to the classes mentioned above, there is also an important class, ScheduledThreadPoolExecutor, which is a timed task implementation class inherited from ThreadPoolExecutor, which is the focus of this article and is used to implement timed execution.However, this article won't cover its implementation, and I'm sure it will make it easier for readers to understand its source code after reading this article.
That's what this article is about. Say nothing and start to enter the text.
Executor interface
/* * @since 1.5 * @author Doug Lea */ public interface Executor { void execute(Runnable command); }
We can see that the Executor interface is very simple, submitting a task on behalf of a void execute(Runnable command) method.In order to let you understand the entire design of the java thread pool, I will follow the design ideas of Doug Lea to say more about it.
We often start a thread like this:
new Thread(new Runnable(){ // do something }).start();
With the thread pool Executor, you can use it as follows:
Executor executor = anExecutor; executor.execute(new RunnableTask1()); executor.execute(new RunnableTask2());Copy Code
If we want the thread pool to perform each task synchronously, we can implement this interface as follows:
class DirectExecutor implements Executor { public void execute(Runnable r) { r.run();// This is not new Thread(r).start(), which means that no new thread has been started. } }
We want to start a new thread to perform this task once each task has been submitted. We can do this:
class ThreadPerTaskExecutor implements Executor { public void execute(Runnable r) { new Thread(r).start(); // Each task is executed with a new thread } }
Let's see how to combine the two Executors. The next implementation is to add all the tasks to a queue, take them from the queue, and hand them over to the real Executor, where synchronized concurrency control is used:
class SerialExecutor implements Executor { // Task Queue final Queue<Runnable> tasks = new ArrayDeque<Runnable>(); // This is the real executor final Executor executor; // Tasks currently in progress Runnable active; // When initializing, specify the executor SerialExecutor(Executor executor) { this.executor = executor; } // Add Task to Thread Pool: Add Task to Task Queue, scheduleNext Triggers Executor to Task Queue to Retrieve Task public synchronized void execute(final Runnable r) { tasks.offer(new Runnable() { public void run() { try { r.run(); } finally { scheduleNext(); } } }); if (active == null) { scheduleNext(); } } protected synchronized void scheduleNext() { if ((active = tasks.poll()) != null) { // The specific execution is transferred to the real executor executor.execute(active); } } }
Of course, the Executor interface only has the ability to submit tasks, which is too simple. We want richer functionality, such as the result of execution, how many threads are alive in the current thread pool, how many tasks have been completed, and so on. These are the shortcomings of this interface.Next, we will introduce the ExecutorService interface, which inherits from the Executor interface, which provides rich functionality and is the interface we use most often.
ExecutorService
Typically, when we define a thread pool, we use this interface:
ExecutorService executor = Executors.newFixedThreadPool(args...); ExecutorService executor = Executors.newCachedThreadPool(args...);
Because a series of methods defined in this interface can already meet our needs in most cases.
So let's take a brief look at all the methods in this interface:
public interface ExecutorService extends Executor { // Close the thread pool, the submitted tasks continue to execute, and do not accept the continued submission of new tasks void shutdown(); // Close the thread pool, try to stop all tasks being performed, do not accept to continue submitting new tasks // It adds the word "now" in comparison to the previous method, except that it stops the task currently in progress List<Runnable> shutdownNow(); // Is the thread pool closed boolean isShutdown(); // Returns true if all tasks are finished after calling shutdown() or shutdownNow() methods // This method must be called after the shutdown or shutdownNow method is called to return true boolean isTerminated(); // Wait for all tasks to complete and set timeout // As we understand, in practice, you call shutdown or shutdownNow first. // Then call this method again to wait for all threads to actually complete, and the return value means that there is no timeout boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException; // Submit a Callable task <T> Future<T> submit(Callable<T> task); // Submit a Runnable task, and the second parameter will be placed in Future as a return value. // Because Runnable's run method itself does not return anything <T> Future<T> submit(Runnable task, T result); // Submit a Runnable task Future<?> submit(Runnable task); // Execute all tasks and return a list of Future types <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException; // It does all the work, but it sets a timeout here <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException; // Only if one of these tasks is finished, you can go back and return the result of the task you completed <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; // As with the previous method, if only one of the tasks is finished, you can go back and return the result of that task. // However, this band timed out beyond the specified time, throwing a TimeoutException exception <T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; }
These methods are well understood, and a simple thread pool is mainly these functions, which can submit tasks, get results, and close the thread pool, which is why we often use this interface.
FutureTask
Before moving on to the implementation classes of ExecutorService, let's talk about the related class FutureTask.
Future Runnable
\ /
\ /
RunnableFuture
|
|
FutureTask
FutureTask implements the Runnable interface indirectly through RunnableFuture.
So each Runnable is usually packaged as a FutureTask first.
Then call executor.execute(Runnable command) to submit it to the thread poolWe know that the void run() method of Runnable does not return a value, so in general, if we need to, we specify a second parameter as the return value in submit:
<T> Future<T> submit(Runnable task, T result);Copy Code
In fact, these two parameters will wrap it as Callable.It differs from Runnable in that run() does not return a value, while Callable's call() method has a return value, and if an exception occurs in the run, the call() method throws an exception.
public interface Callable<V> { V call() throws Exception; }
Let's not expand on the FutureTask class here, because it's already big enough, so here we need to know how to use it.
Next, let's look at the abstract implementation of ExecutorService, AbstractExecutorService.
AbstractExecutorService
The AbstractExecutorService abstract class derives from the ExecutorService interface and then implements several useful methods that are provided to subclasses for invocation.
This abstract class implements the invokeAny and invokeAll methods, where the two newTaskFor s methods are also useful for wrapping tasks into FutureTasks.The void execute(Runnable command) defined in the top-level interface Executor will not be wrapped in FutureTask because it does not require a result.
You need to get a result (FutureTask), use the submit method, you don't need to get a result, you can use the execute method.
Next, I will analyze this class line by line, and follow the source code to see its implementation:
Tips: The invokeAny and invokeAll methods account for the vast majority of this category, and the reader can choose to skip them as they may be used less frequently in your practice, and they do not have a continuing effect, and there is no need to worry about what might be missing to make the code behind impossible to read.
public abstract class AbstractExecutorService implements ExecutorService { // RunnableFuture is used to get execution results, and we often use its subclass FutureTask // The following two newTaskFor methods are used to wrap our tasks as FutureTask s and submit them to the thread pool for execution protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) { return new FutureTask<T>(runnable, value); } protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) { return new FutureTask<T>(callable); } // Submit Tasks public Future<?> submit(Runnable task) { if (task == null) throw new NullPointerException(); // 1. Package tasks as FutureTask s RunnableFuture<Void> ftask = newTaskFor(task, null); // 2. Deliver to the executor, and the execute method is implemented by a specific subclass // As mentioned earlier, FutureTask implements the Runnable interface indirectly. execute(ftask); return ftask; } public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); // 1. Package tasks as FutureTask s RunnableFuture<T> ftask = newTaskFor(task, result); // 2. Deliver to Executor for Execution execute(ftask); return ftask; } public <T> Future<T> submit(Callable<T> task) { if (task == null) throw new NullPointerException(); // 1. Package tasks as FutureTask s RunnableFuture<T> ftask = newTaskFor(task); // 2. Deliver to Executor for Execution execute(ftask); return ftask; } // The purpose of this method is to submit tasks from the tasks collection to the thread pool for execution, and any thread can finish execution before it is finished // The second parameter, timed, denotes whether a timeout mechanism is set. The timeout is the third parameter. // If timed is true and no thread has returned the result after the timeout, throw the TimeoutException exception private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks, boolean timed, long nanos) throws InterruptedException, ExecutionException, TimeoutException { if (tasks == null) throw new NullPointerException(); // Number of tasks int ntasks = tasks.size(); if (ntasks == 0) throw new IllegalArgumentException(); // List<Future<T>> futures= new ArrayList<Future<T>>(ntasks); // ExecutorCompletionService is not a real executor, parameter this is the real executor // It wraps the executor and saves the results to an internal completionQueue queue after each task ends // That's why there is a Completion in the name of this class. ExecutorCompletionService<T> ecs = new ExecutorCompletionService<T>(this); try { // To save exception information, if this method does not produce any valid results, then we can throw the last exception we get ExecutionException ee = null; long lastTime = timed ? System.nanoTime() : 0; Iterator<? extends Callable<T>> it = tasks.iterator(); // First submit a task, then submit the following tasks one by one in the for loop below futures.add(ecs.submit(it.next())); // A task was submitted, so the number of tasks is reduced by 1 --ntasks; // Number of tasks being performed (submitted + 1, end of task - 1) int active = 1; for (;;) { // ecs, as mentioned above, has a completionQueue inside it to hold the results of execution completion // BlockingQueue's poll method is not blocked and returns null to represent an empty queue Future<T> f = ecs.poll(); // For null, the first thread just submitted has not finished executing // Submitting a task before, together with a check here, also improves performance if (f == null) { if (ntasks > 0) { --ntasks; futures.add(ecs.submit(it.next())); ++active; } // This is else if, not if.There are no tasks, and the active is 0. // The tasks have been executed.Actually, I don't understand why I do a break here? // Because I think that if the active is 0, I must return from f.get() below // 2018-02-23 Thanks to reader newmicro comment, // Here active == 0 means that all tasks fail to execute, so here is the for loop exit else if (active == 0) break; // This is also else if.What's said here is that there are no more tasks, but a timeout is set, and this is where we check for timeouts else if (timed) { // poll method with waiting f = ecs.poll(nanos, TimeUnit.NANOSECONDS); // If the TimeoutException exception is thrown, the whole method is over if (f == null) throw new TimeoutException(); long now = System.nanoTime(); nanos -= now - lastTime; lastTime = now; } // Here is else.Note that there are no tasks to commit, but the tasks in the pool are not completed and have not yet timed out (if timeout is set) // The take() method will block until an element returns, indicating that the task is finished else f = ecs.take(); } /* * I don't think the above paragraph is very understandable, let's put it briefly here. * 1. First, in a for loop, we imagine that each task doesn't end so fast. * Then, each time, you go to the first branch and commit the task until all the tasks are committed * 2. When a task has been submitted, if a timeout is set, the for loop actually goes into "Always check for timeouts" On this matter * 3. If no timeout mechanism is set, then it is unnecessary to detect timeouts, which can block the ecs.take() method. Waiting to get the first execution result * 4. If all tasks fail to execute, that is, future returns, But if f.get() throws an exception, branch out from active == 0 (thanks to newmicro s) // Of course, this needs to look at the if branch below. */ // Tasks ended if (f != null) { --active; try { // Returns the execution result, wrapped as ExecutionException if there are exceptions return f.get(); } catch (ExecutionException eex) { ee = eex; } catch (RuntimeException rex) { ee = new ExecutionException(rex); } } }// Notice the range of the for loop until here if (ee == null) ee = new ExecutionException(); throw ee; } finally { // Cancel other tasks before method exits for (Future<T> f : futures) f.cancel(true); } } public <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException { try { return doInvokeAny(tasks, false, 0); } catch (TimeoutException cannotHappen) { assert false; return null; } } public <T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { return doInvokeAny(tasks, true, unit.toNanos(timeout)); } // Execute all tasks and return task results. // Let's not look at this first. Let's think about it. In fact, we submit our own tasks to the thread pool, and we also want the thread pool to perform all the tasks. // It's just that we submit one task at a time, submitting a collection as a parameter here public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException { if (tasks == null) throw new NullPointerException(); List<Future<T>> futures = new ArrayList<Future<T>>(tasks.size()); boolean done = false; try { // This is simple for (Callable<T> t : tasks) { // Package as FutureTask RunnableFuture<T> f = newTaskFor(t); futures.add(f); // Submit Tasks execute(f); } for (Future<T> f : futures) { if (!f.isDone()) { try { // This is a blocking method until a value is obtained or an exception is thrown // Here's a little detail about how the get method signature throws InterruptedException // But it's not handled here, it's thrown out.This exception occurred when tasks that had not been completed were cancelled f.get(); } catch (CancellationException ignore) { } catch (ExecutionException ignore) { } } } done = true; // This method returns, unlike other scenarios, List <Future>, but the results have not yet been implemented // This method return is a real return, the task is over return futures; } finally { // Why this?That's the exception above if (!done) for (Future<T> f : futures) f.cancel(true); } } // With timeout invokeAll, let's make a difference public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException { if (tasks == null || unit == null) throw new NullPointerException(); long nanos = unit.toNanos(timeout); List<Future<T>> futures = new ArrayList<Future<T>>(tasks.size()); boolean done = false; try { for (Callable<T> t : tasks) futures.add(newTaskFor(t)); long lastTime = System.nanoTime(); Iterator<Future<T>> it = futures.iterator(); // Check for timeouts every time a task is submitted while (it.hasNext()) { execute((Runnable)(it.next())); long now = System.nanoTime(); nanos -= now - lastTime; lastTime = now; // overtime if (nanos <= 0) return futures; } for (Future<T> f : futures) { if (!f.isDone()) { if (nanos <= 0) return futures; try { // Call the get method with a timeout, where the parameter nanos is the time remaining. // Because it's actually used up some time f.get(nanos, TimeUnit.NANOSECONDS); } catch (CancellationException ignore) { } catch (ExecutionException ignore) { } catch (TimeoutException toe) { return futures; } long now = System.nanoTime(); nanos -= now - lastTime; lastTime = now; } } done = true; return futures; } finally { if (!done) for (Future<T> f : futures) f.cancel(true); } } }
Here, we find that this abstract class wraps some basic methods, but methods like submit, invokeAny, invokeAll, and so on, they don't really open threads to perform tasks. They just call the execute method inside the method, so the most important execute(Runnable runnable) method hasn't appeared yet and needs to wait for a specific executor to implement the most important one.The important part here is the ThreadPoolExecutor class.
Given the length of this article, I think there should not be many readers here. Everyone is accustomed to the fast food culture.Each article I write is designed to give readers a thorough understanding of the content through one of my articles, so it's a bit longer.
ThreadPoolExecutor
ThreadPoolExecutor is a thread pool implementation in JDK. This class implements each method required by a thread pool, which implements methods such as task submission, thread management, monitoring, and so on.
We can base our business on it to extend to other functions we need, such as ScheduledThreadPoolExecutor, a class that implements timed tasks, which inherits from ThreadPoolExecutor.Of course, this is not the focus of this article, so let's do the source analysis now.
First, let's look at several concepts and processes in the thread pool implementation.
Let's review a few ways to submit a task:
public Future<?> submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null); execute(ftask); return ftask; } public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; } public <T> Future<T> submit(Callable<T> task) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task); execute(ftask); return ftask; }
One of the most basic concepts is that in the submit method, the parameter is of the Runnable type (and also of the Callable type), which is not used in the new Thread(runnable).start(). This parameter is not used to start a thread. It refers to a task, which does what is defined in the run() method or in the call() method in Callable.
Beginners often get confused about this because Runnables always appear everywhere and often pack one Runnable into another.Think of it as having a Task interface with a run() method inside it.
As we looked back and went on, I drew a simple diagram describing some of the main components in the thread pool:

Of course, the above figure does not consider whether the queue is bounded or not. What if the queue is full when submitting a task?When will a new thread be created?What if the thread pool is full when submitting tasks?How do idle threads shut down?These problems will be solved one by one below.
We often use Executors as a tool class to quickly construct a thread pool. For beginners, this tool class is useful. Developers don't need to pay much attention to details. As long as they know they need a thread pool, they can simply provide the necessary parameters. The other parameters follow the default values provided by the author.
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
Not to mention the difference here, they will ultimately lead to this construction method:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); // These parameters are required if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
Basically, the attributes that we need to care about most are listed in the above construction methods, and the attributes that appear in the following construction methods are described one by one:
- corePoolSize
Number of core threads, don't cut corners, just remember this property first. - maximumPoolSize
Maximum number of threads, maximum number of threads allowed to be created by the thread pool. - workQueue
Task queue, an implementation of the BlockingQueue interface (often using ArrayBlockingQueue and LinkedBlockingQueue). - keepAliveTime
The lifetime of an idle thread can be shut down if no task is given to it to do more than that.Note that this value does not work for all threads. If the number of threads in the thread pool is less than or equal to the number of core threads, corePoolSize, these threads will not be shut down because they have been idle for too long. Of course, threads within the number of core threads can also be recycled by calling allowCoreThreadTimeOut(true). - threadFactory
For generating threads, we can use the default.Typically, we can set the name of our thread to be more readable by it, such as Message-Thread-1 and Message-Thread-2. - handler:
This specifies what strategy to take when the thread pool is full but new tasks are submitted.There are several options, such as throwing an exception, rejecting it directly and returning, or implementing your own logic with the appropriate interface.
In addition to the above attributes, let's look at other important attributes.
Doug Lea uses a 32-bit integer to store the state of the thread pool and the number of threads in the current pool. The top three bits are used to store the state of the thread pool, while the lower 29 bits are used to represent the number of threads (even if there are only 29 bits, that's no small number, about 500 million, and no machine can start so many threads now).We know that the java language is uniform in integer encoding and is in the form of complements. The following are simple shift and Boolean operations, which are quite simple.
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); // Here COUNT_BITS is set to 29 (32-3), meaning that the first three bits hold the thread state and the last 29 bits hold the number of threads // Many beginners like to write a lot of 29 numbers in their code, or a special string, and then spread it around. That's terrible private static final int COUNT_BITS = Integer.SIZE - 3; // 000 11111111111111111111111111111 // Here you get 291, which means the maximum number of threads in the thread pool is 2^29-1=536870911 // With the actual situation of our computers, this is still enough private static final int CAPACITY = (1 << COUNT_BITS) - 1; // As we said, the state of the thread pool is stored in high 3 bits // The result is 111 versus 29 0:111 00000000000000000000000000 private static final int RUNNING = -1 << COUNT_BITS; // 000 00000000000000000000000000000 private static final int SHUTDOWN = 0 << COUNT_BITS; // 001 00000000000000000000000000000 private static final int STOP = 1 << COUNT_BITS; // 010 00000000000000000000000000000 private static final int TIDYING = 2 << COUNT_BITS; // 011 00000000000000000000000000000 private static final int TERMINATED = 3 << COUNT_BITS; // Modify the lower 29 bits of integer c to zero to get the state of the thread pool private static int runStateOf(int c) { return c & ~CAPACITY; } // Modifying the high 3 of integer c to zero gives the number of threads in the thread pool private static int workerCountOf(int c) { return c & CAPACITY; } private static int ctlOf(int rs, int wc) { return rs | wc; } /* * Bit field accessors that don't require unpacking ctl. * These depend on the bit layout and on workerCount being never negative. */ private static boolean runStateLessThan(int c, int s) { return c < s; } private static boolean runStateAtLeast(int c, int s) { return c >= s; } private static boolean isRunning(int c) { return c < SHUTDOWN; }
The above is a simple bitwise operation on an integer. Several methods will always appear in the source code, so it is best for readers to remember the name of the method and the function it represents so that they don't have to flip back and forth when looking at the source code.
Here, we describe the transition process for each state and state change in the thread pool:
- RUNNING: There's nothing to say about this, it's the most normal state: accept new tasks, handle tasks in the waiting queue
- SHUTDOWN: Do not accept new task submissions, but continue processing tasks that are waiting on the queue
- STOP: Do not accept new task submissions, no longer process tasks waiting in the queue, interrupt threads executing tasks
- TIDYING: All tasks are destroyed, workCount is 0.When the state of the thread pool is converted to TIDYING state, the hook method terminated() is executed.
- When the TERMINATED:terminated() method ends, the state of the thread pool becomes this
RUNNING is defined as -1, SHUTDOWN is defined as 0, the others are larger than 0, so tasks cannot be submitted when equal to 0, and tasks that are being executed need to be interrupted if greater than 0.
Looking at the introduction of these states, the reader can also guess that in almost eighty-nine cases the states have changed. There are several processes of changing each state:
- RUNNING -> SHUTDOWN: This state transition occurs when shutdown() is called, which is also the most important
- (RUNNING or SHUTDOWN) -> STOP: This state transition occurs when shutdownNow () is called, so make sure the difference between shutDown() and shutDownNow ()
- SHUTDOWN -> TIDYING: When the task queue and thread pool are empty, the SHUTDOWN is converted to TIDYING
- STOP -> TIDYING: This conversion occurs when the task queue is empty
- TIDYING -> TERMINATED: As mentioned earlier, when the terminated() method ends
Just remember the core of the above, especially the first and second.
In addition, we'll look at an internal class Worker, because Doug Lea wraps threads in a thread pool into one worker, translating them into workers, which are the threads doing tasks in the thread pool.So here, we know that the task is Runnable (the internal variable is called task or command), and the thread is Worker.
Worker uses the abstract class AbstractQueuedSynchronizer here.Off-topic, AQS is really ubiquitous in concurrency and very easy to use. Write a small amount of code to achieve the synchronization you need (Readers interested in AQS source can refer to my previous articles).
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{ private static final long serialVersionUID = 6138294804551838833L; // This is a real thread. It's up to you final Thread thread; // As mentioned earlier, Runnable is a task here.Why is firstTask?Because when you create a thread, if you specify both // The first task that this thread needs to perform when it gets up, then the first task is stored here (threads can perform more than this task) // Of course, it can also be null, so the threads get up and go to the task queue (the getTask method) themselves. Runnable firstTask; // To store the number of tasks completed by this thread, note that volatile is used here to ensure visibility volatile long completedTasks; // Worker has only one constructor, passing in firstTask or null Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; // Call ThreadFactory to create a new thread this.thread = getThreadFactory().newThread(this); } // The runWorker method of the external class is called here public void run() { runWorker(this); } ...// The other few methods don't look good: they use AQS operations to get execution from this thread, using exclusive locks }
Verbose, but simple.With these foundations in mind, we can finally see ThreadPoolExecutor's execute method, which, as we mentioned earlier in the source analysis, ultimately relies on the execute method:
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); // The previous integer represents "thread pool state" and "number of threads" int c = ctl.get(); // If the current number of threads is less than the number of core threads, add a worker directly to perform the task. // Create a new thread with the current task command as its first task (firstTask) if (workerCountOf(c) < corePoolSize) { // If the add task succeeds, it is over.Submit the task, the thread pool has already accepted the task, and this method can be returned // As for the results of execution, they will then be packaged in FutureTask. // Returning false means that the thread pool does not allow task submission if (addWorker(command, true)) return; c = ctl.get(); } // This means either the current number of threads is greater than or equal to the number of core threads, or addWorker just failed // If the thread pool is in RUNNING state, add this task to the task queue workQueue if (isRunning(c) && workQueue.offer(command)) { /* What this says is, if a task enters a workQueue, do we need to start a new thread * Because the number of threads in [0, corePoolSize] is unconditionally opening new threads * If the number of threads is greater than or equal to corePoolSize, add the task to the queue and enter here */ int recheck = ctl.get(); // If the thread pool is no longer in RUNNING state, remove the queued task and execute the rejection policy if (! isRunning(recheck) && remove(command)) reject(command); // If the thread pool is RUNNING and the number of threads is 0, start a new thread // At this point, we know that the real purpose of this code is to worry about the task being submitted to the queue, but the threads are all closed else if (workerCountOf(recheck) == 0) addWorker(null, false); } // If the workQueue queue is full, enter this branch // Create a new worker bounded by maximumPoolSize, // If it fails, the current number of threads has reached maximumPoolSize, executing the rejection policy else if (!addWorker(command, false)) reject(command); }
Wrong understanding of creating threads: If the number of threads is less than corePoolSize, create a thread, if the number of threads is between [corePoolSize, maximumPoolSize], create a thread or reuse idle threads, keep AliveTime is valid for threads in this interval.
From the above branches, we can see that the above paragraph is wrong.
It won't be possible to digest all of these for a while. Let's go on and look back a few times.
This method is very important for the addWorker(Runnable firstTask, boolean core) method, so let's see how it creates new threads:
// The first parameter is the task that is ready to be committed to this thread for execution and, as mentioned earlier, can be null // The second parameter, true, represents the use of the number of core threads, corePoolSize, as the boundaries for creating threads, that is, when this thread is created. // If the total number of threads in the thread pool has reached corePoolSize, you cannot respond to this request to create a thread // If false, the maximum number of threads, maximumPoolSize, is used as the bound private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); // This is very incomprehensible // If the thread pool is closed and meets one of the following conditions, no new worker is created: // 1. Thread pool state is greater than SHUTDOWN, which is actually STOP, TIDYING, or TERMINATED // 2. firstTask != null // 3. workQueue.isEmpty() // For a simple analysis: // It's also a state control problem, where submitting tasks is not allowed when the thread pool is in SHUTDOWN, but existing tasks continue to execute // When the status is greater than SHUTDOWN, the task is not allowed to be submitted and the task being executed is interrupted // Say one more thing: If the thread pool is in SHUTDOWN, but firstTask is null and workQueue is not empty, then worker creation is allowed // This is because the semantics of SHUTDOWN: new tasks are not allowed to be submitted, but tasks that have already entered the workQueue are allowed to be executed, so new workers are allowed to be created on the basis of meeting the criteria if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false; for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; // If successful, then all the conditional checks before creating the thread are met and ready to create the thread to execute the task // If this fails, other threads are also trying to create threads into the thread pool if (compareAndIncrementWorkerCount(c)) break retry; // Read the ctl again due to concurrency c = ctl.get(); // Normally if CAS fails, go to the next for loop // However, if the state of the thread pool has changed due to the operation of another thread, such as if another thread closed the thread pool // So you need to go back to the outer for loop if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } } /* * At this point, we think it's time to start creating threads to perform tasks. * Because the checks are all checked, as to what will happen in the future, it will happen in the future, at least at present, if the conditions are met. */ // Is worker started boolean workerStarted = false; // Has this worker been added to the workers HashSet boolean workerAdded = false; Worker w = null; try { final ReentrantLock mainLock = this.mainLock; // Construction method for passing firstTask to worker w = new Worker(firstTask); // Get the thread object in the Worker, and as mentioned earlier, the constructor of the Worker calls ThreadFactory to create a new thread final Thread t = w.thread; if (t != null) { // This is a global lock for the entire thread pool. Holding this lock "makes sense" for the following operations. // Because closing a thread pool requires this lock, the thread pool will not be closed for at least the time I hold the lock mainLock.lock(); try { int c = ctl.get(); int rs = runStateOf(c); // Less than SHUTTDOWN is RUNNING, which is unnecessarily the most normal situation // If it is equal to SHUTDOWN, as mentioned earlier, new tasks will not be accepted, but tasks in the waiting queue will continue to be executed if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { // Can't thread s inside a worker be started if (t.isAlive()) throw new IllegalThreadStateException(); // Add to the workers HashSet workers.add(w); int s = workers.size(); // largestPoolSize is used to record the maximum number of workers // Because workers are increasing and decreasing, this value tells you the maximum size a thread pool has ever reached if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } // Start this thread if the addition succeeds if (workerAdded) { // Start Thread t.start(); workerStarted = true; } } } finally { // If the thread does not start, you need to do some cleanup, such as adding 1 to the previous workCount and reducing it if (! workerStarted) addWorkerFailed(w); } // Returns whether the thread started successfully return workerStarted; }
A quick look at addWorkFailed's handling:
// Remove the corresponding worker from the workers // workCount minus 1 private void addWorkerFailed(Worker w) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { if (w != null) workers.remove(w); decrementWorkerCount(); // rechecks for termination, in case the existence of this worker was holding up termination tryTerminate(); } finally { mainLock.unlock(); } }
Turn back and move on.We know that when a thread in a worker start s, its run method calls the runWorker method:
// run() method of Worker class public void run() { runWorker(this); }
Continue to look at the runWorker method:
// This method is called after the worker thread has started, where a while loop is used to continuously get tasks from the waiting queue and execute them // As mentioned earlier, when a worker initializes, it can specify firstTask so that the first task does not need to be retrieved from the queue final void runWorker(Worker w) { // Thread wt = Thread.currentThread(); // The first task of the thread, if any Runnable task = w.firstTask; w.firstTask = null; w.unlock(); // allow interrupts boolean completedAbruptly = true; try { // Loop call getTask to get task while (task != null || (task = getTask()) != null) { w.lock(); // If the thread pool state is greater than or equal to STOP, then that means the thread is also interrupted if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { // This is a hook method that is left to the desired subclass implementation beforeExecute(wt, task); Throwable thrown = null; try { // At last you can do your job here task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { // Throwable is not allowed to be thrown here, so convert to Error thrown = x; throw new Error(x); } finally { // It is also a hook method that takes task and exceptions as parameters and leaves them to the desired subclass implementation afterExecute(task, thrown); } } finally { // Empty task, prepare getTask for next task task = null; // Cumulative number of tasks completed w.completedTasks++; // Release the worker's exclusive lock w.unlock(); } } completedAbruptly = false; } finally { // If you get here, you need to close the execution thread: // 1. Indicates that getTask returns null, that is, there are no tasks left in the queue to execute and execution is closed // 2. An exception occurred during task execution // In the first case, you've subtracted the workCount by 1 in code processing, which you'll see in the getTask method analysis // In the second case, workCount is not handled, so it needs to be handled in processWorkerExit // I am not going to analyze this method for space. Interested readers should analyze the source code themselves. processWorkerExit(w, completedAbruptly); } }
Let's see how getTask() gets the task. It's a really good way to write it. Every line is simple, but when combined, everything looks good:
// There are three possibilities for this approach: // 1. Block until the task returns.We know that threads within the default corePoolSize are not recycled. // They will always wait for the task // 2. Exit after timeout.When keepAliveTime works, that is, if there are no tasks for so much time, then shutdown should be performed // 3. This method must return null if the following conditions occur: // -There are more than maximumPoolSize workers in the pool (set by calling setMaximumPoolSize) // -The thread pool is in SHUTDOWN and the workQueue is empty, which no longer accepts new tasks as mentioned earlier // -Thread pool in STOP, not only does it not accept new threads, but it also does not execute threads in workQueue private Runnable getTask() { boolean timedOut = false; // Did the last poll() time out? retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Two possibilities // 1. rs == SHUTDOWN && workQueue.isEmpty() // 2. rs >= STOP if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) { // CAS operations, reducing the number of worker threads decrementWorkerCount(); return null; } boolean timed; // Are workers subject to culling? for (;;) { int wc = workerCountOf(c); // Timeout shutdown may occur if thread recycling is allowed within the number of core threads or if the current number of threads exceeds the number of core threads timed = allowCoreThreadTimeOut || wc > corePoolSize; // This break is for the purpose of not executing the next if (compareAndDecrementWorkerCount(c)) // Look at it together: if the current number of threads WC > maximumPoolSize, or timeout, both return null // So the question here is WC > maximumPoolSize, why return null? // In other words, returning null means closing the thread. // That's because it's possible that the developer called setMaximumPoolSize() to make the maximumPoolSize of the thread pool smaller, so the extra Worker s need to be shut down if (wc <= maximumPoolSize && ! (timedOut && timed)) break; if (compareAndDecrementWorkerCount(c)) return null; c = ctl.get(); // Re-read ctl // compareAndDecrementWorkerCount(c) failed and the number of threads in the thread pool changed if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } // WC <= maximumPoolSize without timeout try { // Get Tasks in WorQueue Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null) return r; timedOut = true; } catch (InterruptedException retry) { // If this worker is interrupted, the solution is to retry // To explain why interruptions occur, this reader looks at the setMaximumPoolSize method. // If the developer reduces maximumPoolSize to less than the current number of workers, // That means that some of the threads that are exceeded will be closed.Re-enter the for loop and some threads will naturally return null timedOut = false; } } }
Now that you've basically finished the whole process, it's time for the reader to go back to the execute(Runnable command) method and look at the branches. I'll paste the code in here:
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); // The previous integer represents "thread pool state" and "number of threads" int c = ctl.get(); // If the current number of threads is less than the number of core threads, add a worker directly to perform the task. // Create a new thread with the current task command as its first task (firstTask) if (workerCountOf(c) < corePoolSize) { // If the add task succeeds, it is over.Submit the task, the thread pool has already accepted the task, and this method can be returned // As for the results of execution, they will then be packaged in FutureTask. // Returning false means that the thread pool does not allow task submission if (addWorker(command, true)) return; c = ctl.get(); } // This means either the current number of threads is greater than or equal to the number of core threads, or addWorker just failed // If the thread pool is in RUNNING state, add this task to the task queue workQueue if (isRunning(c) && workQueue.offer(command)) { /* What this says is, if a task enters a workQueue, do we need to start a new thread * Because the number of threads in [0, corePoolSize] is unconditionally opening new threads * If the number of threads is greater than or equal to corePoolSize, add the task to the queue and enter here */ int recheck = ctl.get(); // If the thread pool is no longer in RUNNING state, remove the queued task and execute the rejection policy if (! isRunning(recheck) && remove(command)) reject(command); // If the thread pool is RUNNING and the number of threads is 0, start a new thread // At this point, we know that the real purpose of this code is to worry about the task being submitted to the queue, but the threads are all closed else if (workerCountOf(recheck) == 0) addWorker(null, false); } // If the workQueue queue is full, enter this branch // Create a new worker bounded by maximumPoolSize, // If it fails, the current number of threads has reached maximumPoolSize, executing the rejection policy else if (!addWorker(command, false)) reject(command); }
In each of the branches above, reject(command) is called in two cases to handle the task because, following the normal process, the thread pool cannot accept the task at this time, so we need to execute our rejection policy.Next, let's talk about the rejection policy in ThreadPoolExecutor.
final void reject(Runnable command) { // Execute Rejection Policy handler.rejectedExecution(command, this); }
The handler here we need to pass in this parameter when we construct the thread pool, which is an instance of the RejectedExecutionHandler.
RejectedExecutionHandler has four implementation classes defined in ThreadPoolExecutor that we can use directly. Of course, we can implement our own strategy, but it's generally not necessary.
// As long as the thread pool is not closed, the thread submitting the task executes the task itself. public static class CallerRunsPolicy implements RejectedExecutionHandler { public CallerRunsPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { r.run(); } } } // In any case, throw the RejectedExecutionException exception directly // This is the default policy, and if we construct a thread pool without passing the handler, then this is specified public static class AbortPolicy implements RejectedExecutionHandler { public AbortPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString()); } } // Ignore this task without doing anything public static class DiscardPolicy implements RejectedExecutionHandler { public DiscardPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { } } // This is a bit more domineering, if the thread pool is not closed, // Drop the task at the head of the queue (that is, the one that waits the longest) and submit the task to the waiting queue public static class DiscardOldestPolicy implements RejectedExecutionHandler { public DiscardOldestPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { e.getQueue().poll(); e.execute(r); } } }
At this point, ThreadPoolExecutor's source code is the end of the analysis.ThreadPoolExecutor's source code is relatively simple in terms of the ease of the source code alone, but we just need to calm down and have a good look.
Executors
This section is not really an analysis of the Executors class, because it is just a tool class, and all its methods are static.
- Generate a fixed-size thread pool:
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
The maximum number of threads is set to equal the number of core threads, and keepAliveTime is set to 0 (because it is useless here, even if it is not 0, the thread pool will not recycle threads within corePoolSize by default), and the task queue uses LinkedBlockingQueue, an unbounded queue.
Process analysis: At first, a worker is created for each task submitted. When the number of workers reaches nThreads, no new threads are created. Instead, tasks are submitted to LinkedBlockingQueue, and the number of threads is always nThreads.
- Generating a pool of fixed threads with only one thread is simpler, as above, as long as the number of threads is set to 1:
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
- Create a new thread when needed, while reusing the thread pool that was previously created if the thread currently has no tasks:
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
The number of core threads is 0, the maximum number of threads is Integer.MAX_VALUE, keepAliveTime is 60 seconds, and the task queue uses SynchronousQueue.
This thread pool has better performance when tasks can be completed relatively quickly.If a thread is idle for 60 seconds and has no tasks, it will be closed and removed from the thread pool.So it's okay if the thread pool is idle for a long time, because as all threads are shut down, the entire thread pool won't consume any system resources.
Process analysis: I paste the body of the execute method to make it easier for you to see.Since corePoolSize is 0, when you submit a task, you submit it it directly to the queue. Since SynchronousQueue is used, the offer method will certainly return false if the first task is submitted, because no worker receives the task at this time, it will move to the last branch to create the first worker.Submitting the task later depends on whether there are idle threads to receive it, and if there are, it will go into the second if statement block, otherwise it will go into the last else branch to create a new thread, just like the first task.
int c = ctl.get(); // corePoolSize is 0, so it won't enter this if branch if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } // offer returns true if an idle thread happens to be able to receive the task, otherwise returns false if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command);
SynchronousQueue is a special BlockingQueue that does not store any elements. It has a virtual queue (or virtual stack) with either read or write operations. If the current queue stores threads in the same mode as the current operation, the current operation also enters the queue and waits. If the opposite mode is used, the pairing succeeds and is fetched from the current queue.Queue head node.For more information, see my other article on BlockingQueue.
summary
I have never liked to write a summary because I have put all the expressions I need in the body. Writing a small summary does not really make my words clear. The summary of this article is written for the readers who are preparing for the interview. I hope it will help the interviewer or the readers who do not have enough time to read the full text.
- What are the key properties of a java thread pool?
corePoolSize,maximumPoolSize,workQueue,keepAliveTime,rejectedExecutionHandler
Threads between corePoolSize and maximumPoolSize are recycled, although corePoolSize threads can also be recycled by setting (allowCoreThreadTimeOut(true).
WorQueue is used to hold tasks. When adding tasks, if the current number of threads exceeds corePoolSize, then insert tasks into the queue and the threads in the thread pool will be responsible for pulling tasks out of the queue.
keepAliveTime is used to set idle time, and if the number of threads exceeds corePoolSize, and some threads are idle longer than this value, the operation to close these threads is performed
The rejectedExecutionHandler handles situations where the thread pool cannot perform this task. By default, four strategies are throwing the RejectedExecutionException exception, ignoring the task, performing the task using the thread submitting the task, and deleting the task that is queued for the longest time, then submitting the task. The default is throwing the exception. - Tell me about when threads are created in the thread pool?
*Note: If you set the queue to an unbound queue, the number of threads will not actually increase after reaching corePoolSize.The maximumPoolSize parameter doesn't make sense at this point because the next task is simply going to be queued. - If the current number of threads is less than corePoolSize, a new thread is created when the task is submitted and executed by that thread.
- If the current number of threads has reached corePoolSize, add the submitted tasks to the queue and wait for the threads in the thread pool to get the tasks in the queue.
- If the queue is full, create a new thread to perform the task, ensuring that the number of threads in the pool does not exceed maximumPoolSize, and if the number of threads exceeds maximumPoolSize at this time, execute the rejection policy.
- Executors.newFixedThreadPool(...) What is the difference between the thread pool constructed by Executors.newCachedThreadPool()?
It's too long to go in detail. Slide up a little and describe it in detail in the Executors section. - What to do if an exception occurs during task execution?
If a task executes with an exception, the thread executing the task is shut down instead of continuing to receive other tasks.A new thread is then started to replace it. - When will the rejection policy be implemented?
- The number of workers reached corePoolSize (the task needs to be queued at this time). The task was successfully queued. At the same time, the thread pool was closed, and closing the thread pool did not queue the task, then the rejection policy was executed.This is a very boundary issue, queuing and closing thread pools for concurrent execution, and the reader takes a closer look at how the execute method gets into the first reject(command).
- If the number of workers is greater than or equal to corePoolSize, the task is added to the task queue, but the queue is full and the task fails to enter the queue, then you are ready to start a new thread, but the number of threads has reached maximum PoolSize, then execute the rejection policy.
Because this article is really too long, I did not say how the execution results were obtained, nor did I say to close the thread pool-related section, leaving it to the reader.
This article is a bit long. If the reader finds something wrong or has something to add, please don't hesitate to mention it. Thank you.
(full text complete)
More exciting articles, pay attention to [ToBeTopJavaer], and tens of thousands of excellent course resources for free!!!
