Articles Catalogue
I. Introduction
The previous article mentioned that with the growth of business, the single architecture has developed into a distributed architecture, which greatly improves the processing capacity of business, but also brings many problems that do not exist in the single architecture, such as:
- The abnormal network communication between nodes and the brain fissure problem (network partition) caused by it.
- The "three states" are introduced. In monolithic architecture, there are only two results: success or failure. However, in distributed architecture, due to network anomalies, there will be "unknown" results, i.e. loss of requests or responses, which will lead to client timeouts.
- Each node will fail.
- Distributed transactions and data consistency.
- Configuration and address maintenance of each node. A machine can be easily managed, but there are many machines working together in a distributed environment, which can no longer be maintained manually.
This article focuses on data consistency solutions and the basic concepts of Zookeeper, a service coordination and governance tool.
From ACID to CAP/BASE
ACID features of transactions have been well validated and practiced in the single architecture, but in the distributed architecture, a complete distributed transaction is composed of multiple independent transactions. We can not implement a set of distributed transactions strictly following ACID, because the consistency of data and the availability of the system are conflicting, No. There is a perfect solution. However, due to the demand and promotion of business, classical theories such as CAP and BASE have gradually emerged. Based on these theories, we can construct a distributed system which roughly takes both into account.
- CAP theory means that a distributed system can not satisfy both Consistency, Availability and Partition Tolerance, but can only satisfy two of them at the same time. In the distributed system, P must be satisfied, otherwise there will be no distribution. So we need to balance C and A.
- Basically Available (Basic Available), Soft state (Soft state) and Eventually consistent (Ultimate Consistency) are abbreviated as BASE theory, which is an improvement of CAP theory and weighs its usability and consistency. Its core idea is that even if strong consistency cannot be achieved, each business can adopt appropriate ways to achieve final consistency according to its own characteristics. Because for customers, it's better to get outdated data than web pages can't be opened, as long as the final data can be guaranteed to be correct within an acceptable time.
3. Distributed Consistency Protocol
Because of the need to weigh availability and data consistency repeatedly according to business when designing distributed architecture, a series of consistency protocol algorithms are produced, among which the most famous are two-stage commit (2PC), three-stage commit (3PC) and Pax OS algorithm.
1.2PC and 3PC
In distributed architecture, each node can clearly know its own transaction execution results, but can not directly obtain the transaction execution results of other nodes. How do you ensure consistency in transaction execution? We can introduce a coordinator to uniformly schedule all the nodes, which are called participants. Like an army divided into many sub-units, it is unified by the general's distribution and dispatch. If there is no "general" such as a "dominator", then the army is a scattered sand and can not cooperate at all. The same is true of distributed architecture, where the coordinator is responsible for scheduling participants'behavior and ultimately deciding whether to actually commit the transaction. In this way, 2PC and 3PC protocols are derived.
2PC
2PC divides transaction commit into two phases: initiating transaction request and transaction commit/rollback
Initiate transaction requests
- First, the coordinator sends the transaction content to each participant, asks if the transaction submission can be executed, and waits for the participant's feedback.
- Each participant then proceeds to execute the transaction and records the transaction log information.
- Finally, each participant feedback to the coordinator the results of transaction execution, success or failure.
Transaction commit/rollback
In this stage, the coordinator decides whether to actually commit the transaction based on the participant's feedback. As long as one participant's feedback is "failed" or waiting for the feedback to expire, the coordinator will notify each participant to roll back the previous transaction operation; otherwise, the participant will be notified to commit the transaction. Participants will feedback an ACK to the coordinator after the completion of the execution, and the coordinator will complete the transaction submission or interruption after receiving all participants'ACK.
The above is the implementation process of 2PC, in which one stage can be regarded as a voting process and the second stage is the result of voting. 2PC is a highly consistent protocol algorithm because it needs to wait for participants to "pass by all votes".
The principle of 2PC is simple and easy to implement, but there are also many problems:
- Synchronized blocking: During the whole two-stage commit process, participants are in synchronous blocking before releasing occupied resources (commit or abort completion), unable to handle any other operations, greatly affecting the performance of the system.
- Single point of failure: As we can see from the above, the coordinator is very important in the whole process. Once there is a problem, the whole protocol will not work.
- Data inconsistency: In the second stage, when the coordinator is making a submission request, when the network fails or the coordinator itself collapses, only a part of the participants receive the submission request, the data will be inconsistent.
- Too conservative: In the transaction inquiry phase, if any participant fails before the feedback coordinator and the coordinator can not receive feedback, the coordinator will always be blocked and can only judge whether to interrupt the transaction by its own timeout mechanism.
3PC
3PC is an improvement of 2PC. It divides the initiating transaction request phase into two phases, so it includes three phases: canCommit, preCommit and doCommit.
canCommit
- The coordinator sends a query request containing transaction content to all participants, waiting for feedback from participants.
- After receiving the request, participants return YES or NO according to their own situation.
preCommit
The coordinator notifies participants of pre-committing or interrupting transactions based on feedback from participants:
- Precommit transaction: The coordinator receives "YES" feedback, and notifies the participants to pre-commit the transaction, and records the transaction log. After the participants complete the pre-commit, the results are fed back to the coordinator.
- Interrupt transaction: If any participant in a phase feedback is "NO" or the coordinator waits for feedback to expire, then the coordinator will issue a request for suspension. At this time, whether the participant receives the request for suspension or waits for the request to expire, the participant will interrupt the transaction.
doCommit
The coordinator notifies the participants to submit or roll back the transaction based on feedback from the two-stage participants:
- Submit transaction: If all participants in the second stage submit the transaction successfully in advance, then the transaction is actually committed at this stage.
- Rollback transactions: If any participant in the second stage fails to pre-commit the transaction, the transaction is rolled back according to the transaction log at this stage.
It should be noted that at this stage, the following faults may occur:
- Coordinator malfunction
- Communication failure between coordinator and participant
Either failure results in participants being unable to receive requests from the coordinator. In response to this situation, participants will continue to commit transactions after waiting for the request to expire (no rollback, because the coordinator may have committed transactions, and data inconsistency will result if participants roll back transactions).
Through the above process, we can find the advantages of 3PC over 2PC:
- Reducing the scope of blocking, 3PC will not blocked until Phase 2, while 2PC will blocked during the entire submission process.
- Data consistency can be guaranteed after single point failure in phase three
But at the same time, the optimization of blocking problem brings new problems. When participants receive preCommit requests and network partitions occur, disconnected participants will continue to submit transactions, while coordinators will send requests for interruption of transactions to participants who maintain connections because they do not receive "YES" feedback from all participants. Inconsistence of data.
Therefore, we can see that neither 2PC nor 3PC can completely solve the problem of data consistency, and the whole transaction submission process is too conservative, resulting in poor performance. So Paxos arithmetic appears.
2. Paxos
Paxos algorithm is considered to be the only consistency algorithm, while other protocol algorithms are incomplete versions of it. The complexity of Paxos algorithm is generally recognized. Therefore, it does not take too much time to express Paxos algorithm here. Interested readers can understand its birth background and original paper. <Paxos Made Simple> . (Note: The history of Paxos development is interesting. This paper was published because the author's first paper was too obscure and almost unintelligible to understand and had to be redefined in plain and understandable language.)
3. ZAB protocol
Zookeeper Atmoic Broadcast (ZAB, Zookeeper's Atomic Message Broadcast Protocol), a protocol based on Paxos algorithm, is not exactly the same as Paxos, which is the core algorithm of Zookeeper to ensure data consistency. Here is just an enumeration, which will be elaborated later.
IV. A Preliminary Study of Zookeeper
1. Introduction
Zookeeper is an open source distributed coordination service component created by Yahoo. Distributed applications can implement functions such as data publishing/subscribing, load balancing, naming services, distributed coordination/notification, cluster management, distributed locks and queues. It guarantees the following distributed consistency features:
- Sequence consistency: Transaction requests from the same client are processed in a "first in, first out" manner, which ensures the order of transaction execution.
- Atomicity: In the case of cluster, it is guaranteed that transactions are either executed by all machines or not, and that no partial execution is executed.
- Ultimate consistency: The data acquired by the client from the server is not necessarily real-time and up-to-date, but it can ensure the final consistency of the server data within a certain period of time, that is, the client can finally obtain the latest data.
- Shared View: No matter which server the client connects to, the data is the same and there is no special case.
- Reliability: Once a transaction has been successfully executed and returned to the client correctly, the transaction result will persist and be shared with all server nodes unless a new transaction changes the result of the transaction.
2. Design objectives of Zookeeper
Zookeeper is committed to providing a distributed coordination service with high performance, high availability and strict sequential access control capabilities. Its design objectives are mainly four:
Simple data model
Zookeeper uses a shared, tree-structured data model to store data and is based on key-value pairs, each of which is a ZNode. The key storage format must be similar to the folder path, such as: / service/1, / service/2 (you can see that two service nodes 1 and 2 are stored under the service node); value can store arbitrary values (generally useless).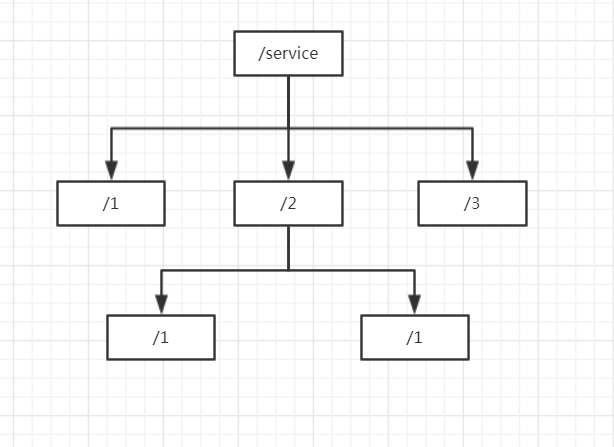
As shown above, each level of node key is unique, and multiple clients can only create the same node successfully, based on which we can achieve a distributed lock.
Clusters can be built
Since it is a coordinating component of distributed applications, it is necessary to naturally support cluster building and expansion, otherwise there will be a single point of failure, resulting in the collapse of the entire distributed application. At the same time, the question to be considered is whether any machine in the cluster fails and the whole cluster is unavailable. Certainly not. Otherwise, what's the difference between a single point and a single point? So we need to consider how to determine the minimum number of machines available in the cluster. In Zookeeper, we need to ensure that the number of surviving servers is at least n/2+1 of the total number of clusters. That is, more than half of the surviving machines can provide services to the outside world. As for why, we can think about it first (hint: related to voting). .
Sequential access
The main purpose is to ensure the sequential execution of transaction requests (add, delete, change). For each transaction request, Zookeeper will control the order of transaction requests by assigning a global incremental number.
High Performance
Zookeeper stores all data in memory, so it responds very quickly to read requests.
3. Basic concepts
Before we get to know Zookeeper practically and thoroughly, it's necessary to understand its core concepts first.
Cluster role
In distributed systems, machines that form clusters have their own roles, usually in Master/Slave (master/standby) mode. In this mode, the machine that can handle the write operation is usually called Master machine, while the machine that acquires the latest data through asynchronous replication and processes the read operation is called Slave machine. However, Zookeeper does not use this model, but uses Leader, Follower, Observer three roles.
Zookeeper chooses a machine as the Leader through the Leader election algorithm to provide transaction request processing services to the outside world, while the other machines provide non-transaction request processing services as Follower and Observer (which role is determined by configuration). Follower participates in Leader's voting. Observer only processes non-transactional requests and does not participate in voting (nor in "more than half" statistics). Therefore, when the query performance reaches the bottleneck, Observer servers are often added to improve query performance without affecting the performance of transaction requests.
Conversation
The bottom layer of Zookeeper is to maintain the client session through a long TCP connection through which the client can perform heartbeat detection, initiate requests, receive responses and receive Watch events from the server. A timeout session Timeout can be set when a session is created. When the client disconnects for some reason, the session created before is still valid after reconnecting to any server within that time.
Data Node
As mentioned above, Zookeeper's data model is a tree structure composed of a series of ZNode s and is divided into persistent nodes and temporary nodes. Persistent nodes refer to the nodes that will always exist until they are created unless they are deleted actively, while temporary nodes are bound to the session, and the session fails, and all temporary nodes will be deleted automatically. In addition, Zookeeper can also specify whether the nodes are ordered, and when ordered nodes are created, they automatically append incremental integers after the node name.
Edition
For each ZNode, Zookeeper maintains a Stat data structure, which records three data versions of the node: version (current node version), cversion (current node version), aversion (ACL version of the current node).
Watcher mechanism
Zookeeper can specify specific Watcher event listeners for each node and trigger events automatically when the listened node changes accordingly.
ACL
Zookeeper uses the Access Control Lists policy to control permissions, and defines the following permissions:
- CREATE: Permission to create subnodes
- READ: Access to node data and list of child nodes
- WRITE: Permission to update node data
- DELETE: Delete the privileges of child nodes
- ADMIN: Privileges for Privilege Settings
4. Zookeeper Conformance Protocol ZAB
Zookeeper is not fully Paxos-based in ensuring data consistency, but uses its specific ZAB atomic broadcasting protocol to support crash recovery and message broadcasting. Now let's look at the implementation principle of ZAB.
Realization Principle
ZAB protocol is a 2PC-like protocol, which is also submitted in two steps. It contains two modes: message broadcasting and crash recovery.
Message Broadcasting
When the Zookeeper cluster starts, it elects a Leader server to process transaction requests. When the client initiates a transaction request, if the server that receives the request is not Leader, it forwards the request to the Leader server, which creates a transaction Proposal and broadcasts it to all Follower servers. Zookeeper is a long connection based on TCP and naturally has FIFO features. At the same time, the Leader server assigns a globally incremental unique ID(ZXID) to each Proposal and creates a separate queue for each Follower server. Then the Proposals are sequenced according to ZXID. Put it in the queue and wait for the Follower server to process.) Then collect the voting information of each server. When more than half of the servers feedback the "affirmative" vote, the Leader server broadcasts a commit request to commit the transaction, and at the same time submits the transaction itself. This is the message broadcasting mode.
This process seems to be no different from the 2PC mentioned above, but in fact, Zookeeper's message broadcasting removes the interrupt logic in the two-stage commit, which means that the Leader server no longer has to wait for feedback from all other servers in the cluster, as long as half of the servers give normal feedback.( This is why the cluster needs to ensure that the number of surviving servers is more than half to provide services to the outside world. Broadcast commit requests; in contrast, Follower servers only need to give normal feedback or discard the Proposal directly. In this way, the problem of synchronous blocking is solved and the processing is simpler, but the problem of inconsistent data caused by the collapse exit of the Leader server cannot be solved. Therefore, the collapse recovery mode is needed to solve this problem.
Collapse recovery
Message broadcasting mode works well when the Leader server is running normally, but it has just been said that once the Leader server crashes or the network partition causes the Leader server to lose more than half of the server's support, the cluster will enter the crash recovery mode and re-elect the Leader. To re-elect Leader, two characteristics need to be guaranteed:
- Transactions already committed on the Leader server ultimately require all servers to commit. It's understandable that when more than half of the servers give feedback, the Leader server submits its its own transactions and broadcasts commit requests to all servers, but before the Leader server hangs up, data inconsistencies will inevitably occur if this feature is not satisfied.
- You need to ensure that you discard transactions that are proposed only on the Leader server. When the Leader server proposes that Proposal has not been sent to other servers, the server hangs up, and then when the server returns to join the cluster normally, the transaction must be discarded in order to achieve data consistency.
Only when these two characteristics are satisfied can the data be finally consistent. But how do we do that? This requires the use of the ZXID mentioned above. So what is ZXID? It is a 64-bit number, divided into high 32-bit and low 32-bit. The higher 32 digits are the dynasty number, which increases by 1 for each round of Leader elections; the lower 32 digits are the number of data updates of the current dynasty, which increases by 1 for each generation of a Proposal, and the number will be reset to 0 for "more dynasties".
With this number, when the Leader server hangs up and the remaining servers re-elect the Leader, only the server with the largest ZXID number needs to be used as the new Leader server to ensure data consistency. It's not hard to understand that if the Leader server hangs up after broadcasting commit, then there must be a server that has the latest roposal, the largest ZXID, then the server as the Leader, other servers only need to synchronize the data on the server to achieve data consistency; if the Leader server creates Pr If oposal hangs up without broadcasting, then the remaining servers will not own the ZXID of Proposal. When the hang-up server is restored, there is a new Leader in the cluster, that is, the ZXID of the unpublished Proosal will certainly not be larger than the ZXID owned by the current Leader, so it can be discarded directly.
5. Leader Election Details
Zookeeper Election Leader is divided into start-up election and service-run election. Before looking down, you need to know several states of the server:
- LOOKING: Watch-and-see status. Leader has not been elected yet.
- LEADING: The server is Leader
- FOLLOWING: The server is Follower
- OBSERVING: This server is Observer
When building a Zookeeper cluster, the minimum number of servers is 2, but the best number of servers is odd (because more than half of the servers are needed to support voting and decision-making. If there are 6 servers, it is allowed to hang up 2 servers and survive 4 to make voting decisions; if there are 5 servers, it is allowed to hang up at most. There are also two, but only three are voting. Therefore, in comparison, odd servers have higher fault tolerance rate and lower network communication burden. Therefore, three servers are used here, namely server1, server2 and server3.
Initial election
Start the server. Before the election is completed, all servers are in LOOKING state. When server1 is started (assuming its myid is 1, myid is the server id, you need to configure it yourself, as you will see later in the actual operation), one server cannot complete the election because more than half of the servers are needed; then server2 is started (assuming myid is 2), then the two servers start to communicate and enter the election process to run for Le. Ader.
- First, each server sends its own myid and ZXID as votes to other servers. Because this is the first round of voting, assuming ZXID will be 0, then server 1 will vote (1, 0) and server 2 will vote (2, 0).
- The server receives votes from other servers and checks whether the votes are valid, including whether the votes are for the same round and whether they are from the LOOKING server.
- After passing the test, each server compares its own votes with the votes it receives. First of all, compare ZXID, choose the largest and update their new round of voting, where ZXID is the same, so continue to compare myid, also choose the largest as their new round of voting. Therefore, here server1 will update its votes to (2,0), while server2 will vote again.
- At the end of each round of voting, the server counts the voting information to see if the server has been supported by more than half of the servers. If so, it will be used as a Leader server, and the status will be changed to LEADING, while the other servers will be changed to FOLLOWING. This is where server2 becomes Leader and the election is over.
When server3 starts up, it finds that there is already a Leader in the cluster, so it only needs to be entered as a Follower server, and there is no need to re-elect unless the Leader server hangs up.
Elections during service operation
Leader elections during service operation are actually mentioned in the section on crash recovery, which is described in more detail here.
- When server2 server crashes, the remaining servers will update their status to LOOKING and enter the Leader election process because they cannot find the Leader. At this time, the service is not available.
- Survival servers generate voting information because the service has been running for some time, so ZXID may be different. Let's assume that server 1 votes for (1,10) and server 3 votes for (3,11). The subsequent process will start with the same election, except that server1 only needs to compare ZXID after receiving (3, 11) votes. So server3 was finally identified as the new LEADER.
Leader Election Source Code Analysis
We learned the core principles of Leader elections from the above, but how does the code level work? This can only be understood by analyzing its source code.
First we need to find an entry class, QuorumPeerMain, the main class started by Zookeeper cluster:
public static void main(String[] args) { QuorumPeerMain main = new QuorumPeerMain(); main.initializeAndRun(args); } protected void initializeAndRun(String[] args) throws ConfigException, IOException { // Loading Configured Classes QuorumPeerConfig config = new QuorumPeerConfig(); if (args.length == 1) { // Load configuration from configuration file into memory config.parse(args[0]); } if (args.length == 1 && config.servers.size() > 0) { // Configuration Cluster runFromConfig(config); } else { // there is only server in the quorum -- run as standalone ZooKeeperServerMain.main(args); } } public void runFromConfig(QuorumPeerConfig config) throws IOException { try { ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory(); cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns()); // Setting configuration information to QuorumPeer class quorumPeer = new QuorumPeer(); quorumPeer.setClientPortAddress(config.getClientPortAddress()); quorumPeer.setTxnFactory(new FileTxnSnapLog( new File(config.getDataLogDir()), new File(config.getDataDir()))); quorumPeer.setQuorumPeers(config.getServers()); quorumPeer.setElectionType(config.getElectionAlg()); quorumPeer.setMyid(config.getServerId()); quorumPeer.setTickTime(config.getTickTime()); quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout()); quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout()); quorumPeer.setInitLimit(config.getInitLimit()); quorumPeer.setSyncLimit(config.getSyncLimit()); quorumPeer.setQuorumVerifier(config.getQuorumVerifier()); quorumPeer.setCnxnFactory(cnxnFactory); quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory())); quorumPeer.setLearnerType(config.getPeerType()); quorumPeer.setSyncEnabled(config.getSyncEnabled()); quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs()); quorumPeer.start(); // Open sub-threads to load db information and start elections quorumPeer.join(); // The main thread waits for the sub-thread to complete } catch (InterruptedException e) { // warn, but generally this is ok LOG.warn("Quorum Peer interrupted", e); } }
The main logic is in the QuorumPeer class, which inherits from the Thread class:
public synchronized void start() { loadDataBase(); // Here is the recovery of DB information, such as epoch and ZXID, etc. cnxnFactory.start(); startLeaderElection(); //Initiation of the electoral process super.start(); // Start threads } synchronized public void startLeaderElection() { try { // Vote for yourself currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch()); } catch(IOException e) { RuntimeException re = new RuntimeException(e.getMessage()); re.setStackTrace(e.getStackTrace()); throw re; } // Create an election algorithm, using FastLeaderElection by default this.electionAlg = createElectionAlgorithm(electionType); } protected Election createElectionAlgorithm(int electionAlgorithm){ Election le=null; //TODO: use a factory rather than a switch switch (electionAlgorithm) { case 0: le = new LeaderElection(this); break; case 1: le = new AuthFastLeaderElection(this); break; case 2: le = new AuthFastLeaderElection(this, true); break; case 3: qcm = new QuorumCnxManager(this); QuorumCnxManager.Listener listener = qcm.listener; if(listener != null){ listener.start(); // By default, it will be here and can be configured in the zoo.cfg configuration file le = new FastLeaderElection(this, qcm); } else { LOG.error("Null listener when initializing cnx manager"); } break; default: assert false; } return le; }
From the above code, we can see QuorumPeer's process of creating an election algorithm. By default, the FastLeaderElection class is used (earlier versions include LeaderElection, UDP version of FastLeaderElection and TCP version of FastLeaderElection. Since version 3.4.0, only TCP version of FastLeaderElection has been retained, and so have we. You can implement an election algorithm by yourself and configure it in zoo.cfg configuration file. After selecting the election algorithm, we call the start method of the thread, so we only need to find the run method.
public void run() { try { while (running) { // According to the server status into the corresponding process, because it is the election process, so it is LOOKING state, other processes can be ignored for the time being. switch (getPeerState()) { case LOOKING: if (Boolean.getBoolean("readonlymode.enabled")) { // The current server is a read-only server, independent of our process final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer( logFactory, this, new ZooKeeperServer.BasicDataTreeBuilder(), this.zkDb); Thread roZkMgr = new Thread() { public void run() { try { // lower-bound grace period to 2 secs sleep(Math.max(2000, tickTime)); if (ServerState.LOOKING.equals(getPeerState())) { roZk.startup(); } } catch (InterruptedException e) { LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started"); } catch (Exception e) { LOG.error("FAILED to start ReadOnlyZooKeeperServer", e); } } }; try { roZkMgr.start(); setBCVote(null); setCurrentVote(makeLEStrategy().lookForLeader()); } catch (Exception e) { LOG.warn("Unexpected exception",e); setPeerState(ServerState.LOOKING); } finally { // If the thread is in the the grace period, interrupt // to come out of waiting. roZkMgr.interrupt(); roZk.shutdown(); } } else { try { setBCVote(null); // Choose the leader setCurrentVote(makeLEStrategy().lookForLeader()); } catch (Exception e) { LOG.warn("Unexpected exception", e); setPeerState(ServerState.LOOKING); } } break; } } } finally { LOG.warn("QuorumPeer main thread exited"); try { MBeanRegistry.getInstance().unregisterAll(); } catch (Exception e) { LOG.warn("Failed to unregister with JMX", e); } jmxQuorumBean = null; jmxLocalPeerBean = null; } }
The details of the Leader election are mainly in the FastLeaderElection.lookForLeader() (makeLEStrategy().lookForLeader():
// Send and receive ballot queues LinkedBlockingQueue<ToSend> sendqueue; LinkedBlockingQueue<Notification> recvqueue; public Vote lookForLeader() throws InterruptedException { try { // Store the voting information received HashMap<Long, Vote> recvset = new HashMap<Long, Vote>(); // Store voting information for the current server HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>(); int notTimeout = finalizeWait; // Vote for yourself for the first time synchronized(this){ logicalclock++; updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch()); } // Send your own voting information sendNotifications(); // Loop until the Leader is selected while ((self.getPeerState() == ServerState.LOOKING) && (!stop)){ // Take votes out of the queue in order Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS); if(n == null){ // No voting information was received. if(manager.haveDelivered()){ // If the sending queue is idle, it will continue to send its own voting information. sendNotifications(); } else { // The sending queue is not null. It may be that other servers have not started yet and try to reconnect. manager.connectAll(); } } else if(self.getVotingView().containsKey(n.sid)) { // Does the message belong to the current cluster? switch (n.state) { // Determine the status of the node receiving the message case LOOKING: // Judging whether it is a new round of elections if (n.electionEpoch > logicalclock) { logicalclock = n.electionEpoch; // Update logicalclock recvset.clear(); // Clear up the voting information received in the previous round // Compare epoch, myid and zxid, and update your votes to the winning node if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) { updateProposal(n.leader, n.zxid, n.peerEpoch); } else { updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch()); } // Send out new votes sendNotifications(); } else if (n.electionEpoch < logicalclock) { // Voting information received has expired and is ignored directly break; } else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) { // Direct comparison of myid and zxid in the same round of voting updateProposal(n.leader, n.zxid, n.peerEpoch); sendNotifications(); } recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch)); // To judge whether the election is over, the default algorithm is more than half of the consent. if (termPredicate(recvset, new Vote(proposedLeader, proposedZxid, logicalclock, proposedEpoch))) { // Wait for all notification s to be processed until they expire while((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null){ if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)){ recvqueue.put(n); break; } } // leader has been identified if (n == null) { // Modify the status to leader or follower self.setPeerState((proposedLeader == self.getId()) ? ServerState.LEADING: learningState()); Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock, proposedEpoch); leaveInstance(endVote); return endVote; } } break; case OBSERVING: // observer does not vote LOG.debug("Notification from observer: " + n.sid); break; // Both follower and leader will vote. case FOLLOWING: case LEADING: /* * Consider all notifications from the same epoch * together. */ if(n.electionEpoch == logicalclock){ recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch)); if(ooePredicate(recvset, outofelection, n)) { self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING: learningState()); Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch); leaveInstance(endVote); return endVote; } } /* * Before joining an established ensemble, verify * a majority is following the same leader. */ outofelection.put(n.sid, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state)); if(ooePredicate(outofelection, outofelection, n)) { synchronized(this){ logicalclock = n.electionEpoch; self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING: learningState()); } Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch); leaveInstance(endVote); return endVote; } break; default: LOG.warn("Notification state unrecognized: {} (n.state), {} (n.sid)", n.state, n.sid); break; } } else { LOG.warn("Ignoring notification from non-cluster member " + n.sid); } } return null; } finally { try { if(self.jmxLeaderElectionBean != null){ MBeanRegistry.getInstance().unregister( self.jmxLeaderElectionBean); } } catch (Exception e) { LOG.warn("Failed to unregister with JMX", e); } self.jmxLeaderElectionBean = null; } }
So far, the Leader election process is over, but there's still a question, how does the message broadcast? The sendNotifications method:
private void sendNotifications() { for (QuorumServer server : self.getVotingView().values()) { long sid = server.id; ToSend notmsg = new ToSend(ToSend.mType.notification, proposedLeader, proposedZxid, logicalclock, QuorumPeer.ServerState.LOOKING, sid, proposedEpoch); if(LOG.isDebugEnabled()){ LOG.debug("Sending Notification: " + proposedLeader + " (n.leader), 0x" + Long.toHexString(proposedZxid) + " (n.zxid), 0x" + Long.toHexString(logicalclock) + " (n.round), " + sid + " (recipient), " + self.getId() + " (myid), 0x" + Long.toHexString(proposedEpoch) + " (n.peerEpoch)"); } sendqueue.offer(notmsg); } }
This method is mainly to encapsulate a ToSend object and add it to the sending queue. Who consumes this queue? Browse the FastLeaderElection class structure, and we will see two classes, WorkerSender and WorkerReceiver. Needless to say, one is receiving and the other is sending. We are broadcasting messages here, and that must be the WorkerSender class (both of which inherit from the Thread class). Let's look directly at the run method:
public void run() { while (!stop) { try { ToSend m = sendqueue.poll(3000, TimeUnit.MILLISECONDS); if(m == null) continue; process(m); // Send ToSend } catch (InterruptedException e) { break; } } }
Eventually, the toSend method of Quorum CnxManager is invoked:
public void toSend(Long sid, ByteBuffer b) { if (self.getId() == sid) { // Send it to oneself without network communication, and put it directly in the receiving queue. b.position(0); addToRecvQueue(new Message(b.duplicate(), sid)); } else { // To send it to other nodes, you need to determine whether it has been sent before. if (!queueSendMap.containsKey(sid)) { // If not, a new send queue is created, SEND_CAPACITY is 1, indicating that only one message is sent at a time. ArrayBlockingQueue<ByteBuffer> bq = new ArrayBlockingQueue<ByteBuffer>( SEND_CAPACITY); queueSendMap.put(sid, bq); addToSendQueue(bq, b); } else { // If the previous message has not been sent, it will be sent again. ArrayBlockingQueue<ByteBuffer> bq = queueSendMap.get(sid); if(bq != null){ addToSendQueue(bq, b); } else { LOG.error("No queue for server " + sid); } } connectOne(sid); // Real underlying transport logic } }
So far, Leader's electoral analysis has been completed, and the following categories are involved.
- QuorumPeerMain: Start Class
- QuorumPeer: Cluster Environment Assisted Initialization Class
- FastLeaderElection: The implementation of the election algorithm, which contains the following internal classes:
- Notification: Represents the voting information received
- ToSend: Represents voting information sent to other servers
- Messager: Contains the WorkerSender sending class and WorkerReceiver receiving class, through which voting information is sent and received.
summary
This article is the beginning of Zookeeper series, focusing on the distributed consistency protocol and the basic concepts of Zookeeper and the Leader election process. Understanding the principles will enable us to better understand the use of technology scenarios and processing issues, and to make more reasonable trade-offs in architecture design.
PS: This article summarizes and refers to "From Paxos to Zookeeper: Principles and Practices of Distributed Consistency". Due to the length of the book, it has a lot of details. Readers can search the book for further understanding and learning.