The 2.4.1 version of ES used in the old cluster has been running well and has not moved. Recently, the data ES5.X has been stable and its performance has been greatly improved, which makes my heart itchy. However, to maintain the high availability of business, I have to think of a smooth upgrade scheme. Finally, I think of a method of excessive instances. The 5.X version describes the configuration changes greatly on the Internet, and is ready to step on the pit. Once you've made sure you want to upgrade, do it immediately.
I. Corresponding Upgrading and Reconstruction Scheme
Install and configure new ES5.2.1 instances using ports 9220 and 9330 --> Turn off logstash and restart ES2.4.1 instance stack (kafka keeps three hours of logs so it won't be lost) --> Start ES5.2.1 and open logstash to ES5.2.1 --> Install new kibana instances to point to the old data. http://host/old Access - > ES5.2.1 configuration tuning.
2. Unified supervisord-monitor management after upgrading
github: https://github.com/mlazarov/supervisord-monitor
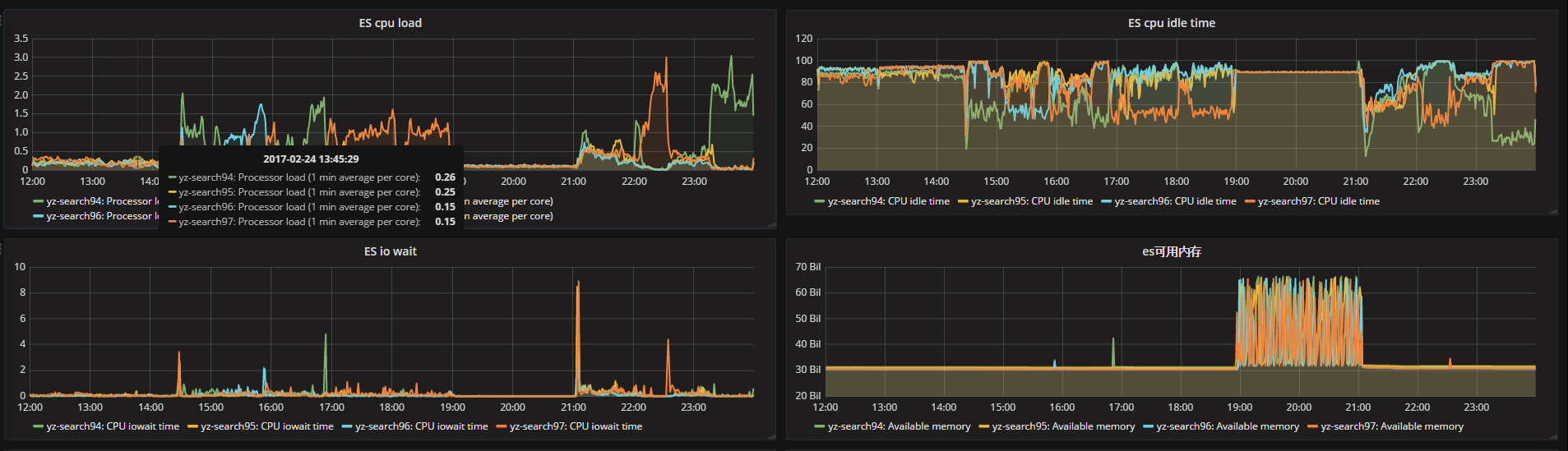
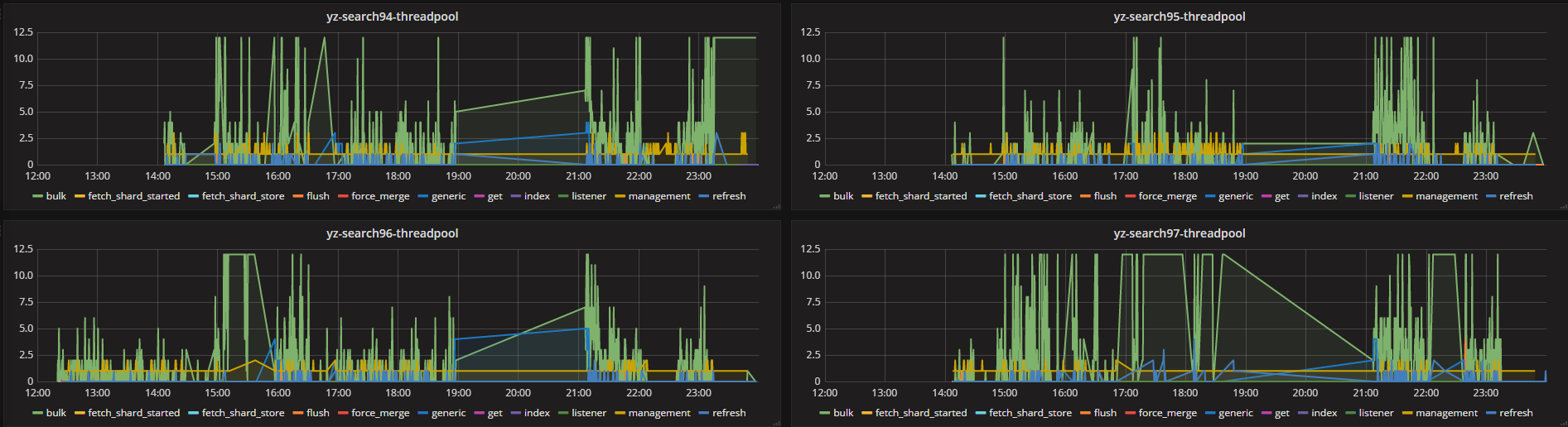
3. The monitoring data of cpu, IO and thread_pool of ES before and after optimization are as follows
Before optimization:
After optimization:
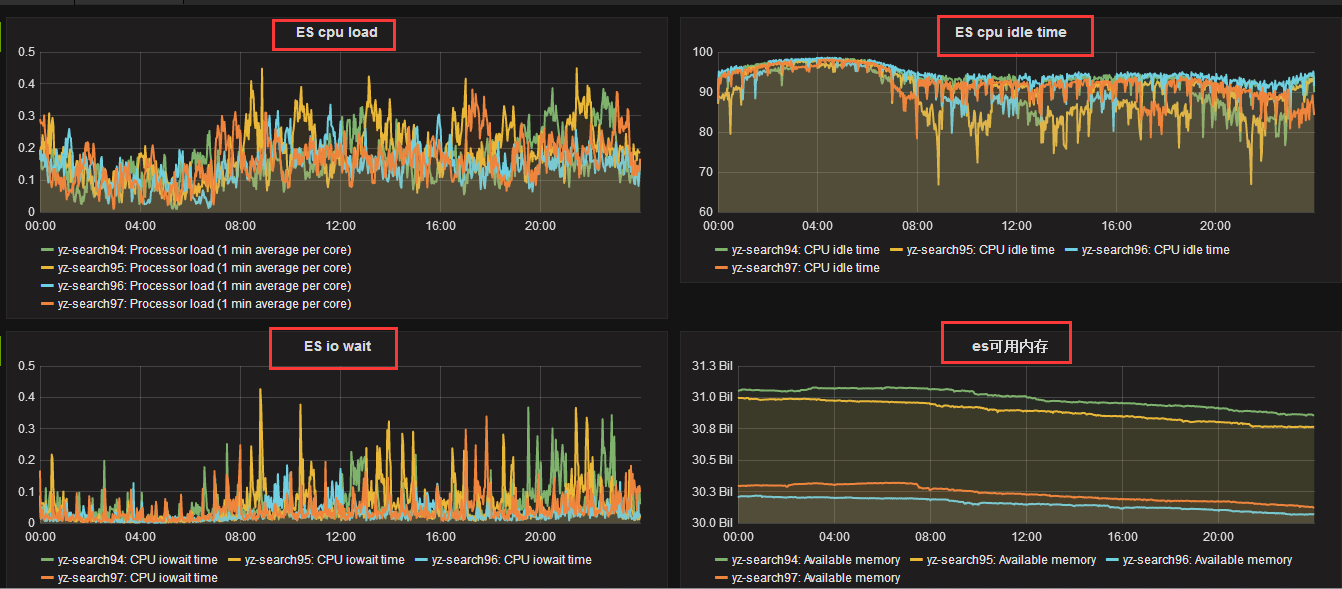
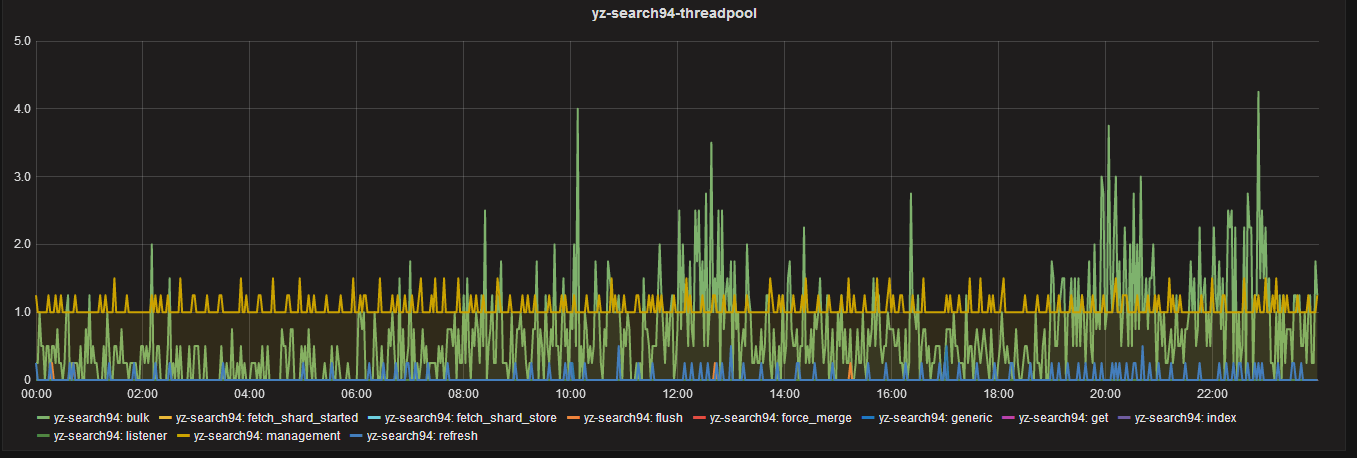
From the monitoring data, the highest number of active processes is bulk batch processing operation, if not tuned, it will block directly.
IV. Upgrade process - Write the installation script of ES5.2.1 as follows
Before using rpm package, consider installing directly with tar package. For the tuning operation that needs to be done by the system, write the automated installation script directly. After configuring all system parameters with one key, build the environment.
#/bin/sh id elasticsearch || useradd elasticsearch -s /sbin/nologin #Add user grep "* - nofile 512000" /etc/security/limits.conf || echo "* - nofile 512000" >> /etc/security/limits.conf #Modify the number of file descriptors grep "elasticsearch - nproc unlimited" /etc/security/limits.conf || echo "elasticsearch - nproc unlimited" >> /etc/security/limits.conf #Modify the maximum number of open processes grep "fs.file-max = 1024000" /etc/sysctl.conf || echo "fs.file-max = 1024000" >> /etc/sysctl.conf #Modify the System File Descriptor grep "vm.max_map_count = 262144" /etc/sysctl.conf || echo "vm.max_map_count = 262144" >> /etc/sysctl.conf #Modifying vm for maximum program management sysctl -p cd /usr/local/src [ ! -f /usr/local/src/elasticsearch-5.2.1.zip ] && wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.1.zip [ ! -d /usr/local/src/elasticsearch-5.2.1 ] && unzip elasticsearch-5.2.1.zip mv elasticsearch-5.2.1 /usr/local/ chown -R elasticsearch:elasticsearch /usr/local/elasticsearch-5.2.1 #Modify Owner Ownership Groups sed -i 's/-XX:+UseConcMarkSweepGC/-XX:+UseG1GC/' /usr/local/elasticsearch-5.2.1/config/jvm.options #Modify GC mode to G1 sed -i 's/-XX:CMSInitiatingOccupancyFraction=75/-XX:MaxGCPauseMillis=200/' /usr/local/elasticsearch-5.2.1/config/jvm.options sed -i 's/-XX:+UseCMSInitiatingOccupancyOnly/#-XX:+UseCMSInitiatingOccupancyOnly/' /usr/local/elasticsearch-5.2.1/config/jvm.options
5. Upgrade process - configuration file, index-related update tuning
During the upgrade period, I stepped on many pits, the old version of ES index configuration can be written directly into the configuration file, the new version is not feasible, we must use the api to set up, and ES2.X version of the process number tuning, in ES5.X I found that the adjustment has no effect. The configuration file is as follows:
cluster.name: yz-5search path.data: /data1/LogData5/ path.logs: /data1/LogData5/logs bootstrap.memory_lock: false #centos6 kernel is not supported and must be turned off bootstrap.system_call_filter: false network.host: 10.39.40.94 http.port: 9220 transport.tcp.port: 9330 discovery.zen.ping.unicast.hosts: ["10.39.40.94:9330","10.39.40.95:9330","10.39.40.96:9330","10.39.40.97:9330"] discovery.zen.minimum_master_nodes: 2 http.cors.enabled: true http.cors.allow-origin: "*"
In order to speed up the index efficiency, we write the template configuration of index (the index configuration is not allowed to be written to the configuration file), put the parameters into es, of course, the template can also be specified by the front-end logstash (it is troublesome to change logtash). The template script is as follows:
#/bin/sh #index template curl -XPUT 'http://10.39.40.94:9220/_template/cms_logs?pretty' -d '{ "order": 6, #priority "template": "logstash-cms*", #Regular Matching Index "settings": { "index.refresh_interval" : "60s", #Index refresh time "index.number_of_replicas" : "0", #Set the number of copies to 0 "index.number_of_shards" : "8", #Set the number of fragments to 8, a total of 4 servers "index.translog.flush_threshold_size" : "768m", #The threshold of translog triggering flush "index.store.throttle.max_bytes_per_sec" : "500m", #Storage threshold "index.translog.durability": "async", #Set translog asynchronous refresh to hard disk, pay more attention to performance "index.merge.scheduler.max_thread_count": "1", #Mechanical disc set to 1 "index.routing.allocation.total_shards_per_node": "2" #Two slices on each node } }'
Prepare: If it is changed, change PUT to POST
The log is kept for 7 days, and the script cleared is as follows, written to the scheduled task:
#!/bin/bash DATE=`date +%Y.%m.%d.%I` DATA2=`date +%Y.%m.%d -d'-7 day'` curl -XDELETE "http://10.39.40.97:9220/logstash-*-${DATA2}*?pretty"
Since a single index reaches 35G or even 40G, the number of indexes built is modified at the logstash level. Twelve indexes per day are changed to 24 indexes per day:

The modifications to logstash are as follows:
index => "logstash-cms-front-nginx-%{+YYYY.MM.dd.hh}" Modified to index => "logstash-cms-front-nginx-%{+YYYY.MM.dd.HH}"
Note: Installation of supervisor
easy_install meld3 eays_install pip easy_install supervisor