Elasticsearch interview questions
Article catalog
- Elasticsearch interview questions
- 1. How does Elasticsearch implement master election?
- 2. Describe in detail the process of Elasticsearch indexing documents.
- 3. Describe in detail the process of updating and deleting documents in Elasticsearch.
- 4. Describe the Elasticsearch search process in detail?
- 5. How does Elasticsearch realize the aggregation of large amounts of data (hundreds of millions of magnitude)?
- 6. In the case of concurrency, if Elasticsearch ensures consistent reading and writing?
- 7. What are the clusters, nodes, indexes, documents and types in ElasticSearch?
- 8. What is the inverted index of Elasticsearch?
- 9. What is the analyzer in ElasticSearch?
- 10. What is the purpose of enabling properties, indexing and storage?
- 11. What do you know about Elasticsearch? Tell me about your company es's cluster architecture, index data size, number of partitions, and some tuning methods.
- 12. What should I do if there is too much Elasticsearch index data, how to optimize and deploy it?
- 13. What should I pay attention to when using Elasticsearch?
- 14. What types of queries does Elasticsearch support?
- 15. Can you list the main available field data types related to Elasticsearch?
- 16. How to monitor Elasticsearch cluster status?
- 17. Have you learned about Elasticsearch's sexual search scheme?
- 18. Do you know the dictionary tree?
- 19. Does ElasticSearch have a schema?
- 20. Why use Elasticsearch?
1. How does Elasticsearch implement master election?
1,For all that can be master Node based on nodeId Sorting: each node will rank the nodes they know in order each time, and then select the first (No. 0) node, which is considered to be master Node. 2,If the number of votes for a node reaches a certain value (it can become master Number of nodes n/2+1)And the node itself elects itself, so this node is master. Otherwise, re-election. 3,about brain split Problem, need to put the candidate master The node minimum value is set to be master Number of nodes n/2+1(quorum )
2. Describe in detail the process of Elasticsearch indexing documents.
1,When the node where the partition is located receives the request from the coordination node, it will write the request to MemoryBuffer,Then, it is written regularly (every 1 second by default) to Filesystem Cache,This from MomeryBuffer reach Filesystem Cache The process is called refresh; 2,Of course, in some cases, there are Momery Buffer and Filesystem Cache Your data may be lost, ES Yes translog The implementation mechanism is that after receiving the request, it will also be written to translog When Filesystem cache The data in is cleared only when it is written to the disk. This process is called flush; 3,stay flush In the process, the buffer in memory will be cleared and the content will be written to a new segment fsync A new commit point will be created and the content will be refreshed to disk, the old one translog Will be deleted and a new one will start translog. 4,flush The trigger timing is timed (default 30 minutes) or translog Becomes too large (512 by default) M)Time;
3. Describe in detail the process of updating and deleting documents in Elasticsearch.
1,Delete and update are also write operations, but Elasticsearch The document in is immutable, so it cannot be deleted or changed to show its changes. 2,Each segment on the disk has a corresponding.del File. When the delete request is sent, the document is not really deleted, but in the.del The file is marked for deletion. The document can still match the query, but will be filtered out in the results. When segments are merged, in.del Documents marked for deletion in the file will not be written to the new segment. 3,When a new document is created, Elasticsearch A version number will be assigned to the document. When the update is performed, the old version of the document will be displayed in the.del The file is marked for deletion, and the new version of the document is indexed to a new segment. The old version of the document can still match the query, but will be filtered out in the results.
4. Describe the Elasticsearch search process in detail?
1,Search is performed as a two-stage process, which we call Query Then Fetch; 2,During the initial query phase, the query will be broadcast to each shard copy (Master shard or replica shard) in the index. Each shard performs a search locally and constructs a matching document with a size of from + size Priority queue. Note: when searching, you will query Filesystem Cache Yes, but some data are still there MemoryBuffer,So the search is near real time. 3,Each fragment returns the of all documents in its own priority queue ID And sorting values to the coordination node, which combines these values into its own priority queue to produce a global sorted result list. 4,The next step is the retrieval phase. The coordination node identifies which documents need to be retrieved and submits multiple documents to the relevant fragments GET Request. Each fragment loads and enriches the document, and then returns the document to the coordination node if necessary. Once all the documents are retrieved, the coordination node returns the result to the client. 5,Supplement: Query Then Fetch The search type of refers to the data of this segment when scoring the relevance of documents, which may not be accurate when the number of documents is small, DFS Query Then Fetch Added a pre query processing, query Term and Document frequency,This score is more accurate, but the performance will be worse.
5. How does Elasticsearch realize the aggregation of large amounts of data (hundreds of millions of magnitude)?
Elasticsearch The first approximate aggregation provided is cardinality Measure. It provides the cardinality of a field, that is, the cardinality of the field distinct perhaps unique Number of values. It is based on HLL Algorithmic. HLL We will hash our input first, and then according to the results of the hash operation bits It is characterized by configurable accuracy, which is used to control the use of memory (more accurate) = More memory); the accuracy of small data sets is very high; we can configure parameters to set the fixed memory usage required for de duplication. Whether thousands or billions of unique values, the memory usage is only related to the accuracy of your configuration.
6. In the case of concurrency, if Elasticsearch ensures consistent reading and writing?
1,Optimistic concurrency control can be used through the version number to ensure that the new version will not be overwritten by the old version, and the application layer will handle specific conflicts; 2,In addition, for write operations, the consistency level supports quorum/one/all,Default to quorum,That is, write operations are allowed only when most of the fragments are available. However, even if most of the fragments are available, writing to the replica may fail due to network and other reasons. In this way, the replica is considered to be faulty, and the fragments will be rebuilt on a different node. 3,For read operations, you can set replication by sync(default),This allows the operation to return only after both the master shard and the replica shard are completed; if set replication by async You can also set the search request parameters_preference by primary To query the main partition to ensure that the document is the latest version.
7. What are the clusters, nodes, indexes, documents and types in ElasticSearch?
Cluster: a collection of one or more nodes (servers) that collectively store your entire data and provide federated indexing and search across all nodes. The cluster is identified by a unique name, which is by default“ elasticsearch". This name is important because a node can only be part of a cluster if it is set to join the cluster by name. Node: a single server that is part of a cluster. It stores data and participates in cluster indexing and search functions. Index: just like the "database" in relational database, it has a mapping that defines multiple types. An index is a logical namespace, mapped to one or more primary partitions, and can have zero or more replica partitions. eg: MySQL =>database ElasticSearch =>Indexes Document: similar to a row in a relational database. The difference is that each document in the index can have a different structure (field), but it should have the same data type for common fields. MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>Documents with properties Type: is the logical category of the index/Partition, whose semantics depends entirely on the user.
8. What is the inverted index of Elasticsearch?
1,Inverted index is the core of search engine. The main goal of search engine is to provide fast search when finding documents with search conditions. Inverted index is a hash chart like data structure, which can guide users from words to documents or web pages. It is the core of search engine. Its main goal is to quickly search and find data from millions of files. 2,Traditionally, our retrieval is to find the position of the corresponding keyword through the article one by one, while the inverted index is to form the mapping relationship table between the word and the article through the word segmentation strategy+The mapping table is the inverted index. With the inverted index, it can be realized o(1)The efficiency of time complexity has greatly improved the retrieval efficiency. Academic solutions: Inverted index, on the contrary to which words an article contains, starts from words and records which documents the word has appeared in. It consists of two parts - dictionary and inverted table. Bonus item: the underlying implementation of inverted index is based on: FST(Finite State Transducer)Data structure. lucene From 4+The data structures that have been widely used since the version are FST. FST There are two advantages: 1)The storage space is compressed by reusing word prefixes and suffixes in the dictionary; 2)Fast query speed. O(len(str))Query time complexity.
9. What is the analyzer in ElasticSearch?
1,stay ElasticSearch When indexing data in, the data is defined by the for the index Analyzer Convert internally. The parser consists of a Tokenizer And zero or more TokenFilter The compiler can be composed in one or more CharFilter Previously, the analysis module allows you to register analyzers under logical names, which can then be defined in a map or some API Reference them in. 2,Elasticsearch There are many pre built analyzers that can be used at any time. Alternatively, you can combine the built-in character filter, compiler and filter to create a custom analyzer.
10. What is the purpose of enabling properties, indexing and storage?
1,Enabled Attributes apply to all types of ElasticSearch given/Create domains, such as index and size. The user supplied field does not have the enabled property. Storage means that the data is stored by Lucene Storage, which will be returned if asked. 2,Storage fields are not necessarily searchable. By default, fields are not stored, but the source file is complete. Because you want to use the default values(This makes sense),So don't set store Property this index property is used for searching. 3,Index properties can only be used for search. Only index fields can be searched. The reason for the difference is that the index fields were converted during analysis, so you cannot retrieve the original data if necessary.
11. What do you know about Elasticsearch? Tell me about your company es's cluster architecture, index data size, number of partitions, and some tuning methods.
For example: ES The cluster architecture consists of 13 nodes, with 20 indexes according to different channels+Index, incremented by 20 per day based on date+,Index: 10 pieces, increasing by 100 million every day+Data, daily index size control for each channel: 150 GB Within. Index level tuning only: 1.1,Design phase tuning 1)According to the business increment requirements, the index is created based on the date template roll over API Rolling index; 2)Index management using alias; 3)The index is regularly updated every morning force_merge Operation to free up space; 4)The cold and heat separation mechanism is adopted, and the heat data is stored in the SSD,Improve the retrieval efficiency; the cold data is carried out regularly shrink Operation to reduce storage; 5)take curator Life cycle management of index; 6)Only for the fields requiring word segmentation, set the word splitter reasonably; 7)Mapping The stage fully combines the attributes of each field, whether it needs to be retrieved, whether it needs to be stored, etc 1.2,Write tuning 1)Set the number of copies before writing to 0; 2)Close before writing refresh_interval Set to-1,Disable the refresh mechanism; 3)During writing: bulk Batch write; 4)Number of copies recovered after writing and refresh interval; 5)Try to use automatically generated id. 1.3,Query tuning 1)Disable wildcard; 2)Disable batch terms(Hundreds of scenes); 3)Making full use of inverted index mechanism can keyword Type as far as possible keyword; 4)When the amount of data is large, the index can be finalized based on time before retrieval; 5)Set up a reasonable routing mechanism. 1.4,Other tuning Deployment optimization, business optimization, etc.
12. What should I do if there is too much Elasticsearch index data, how to optimize and deploy it?
1 Dynamic index level Template based+time+rollover api Rolling index creation, for example: design phase definition: blog The template format of the index is: blog_index_In the form of timestamp, the data is incremented every day. The advantage of this is that the data volume of a single index will not increase sharply, which is close to the 32nd power of online 2-1,Index store reached TB+Even larger. Once a single index is large, various risks such as storage will follow, so it should be considered in advance+Avoid early. 2 Storage level The cold and hot data are stored separately. The hot data (such as the data of the last 3 days or a week) and the rest are cold data. For the cold data, new data will not be written again, and periodic storage can be considered force_merge plus shrink Compression operation saves storage space and retrieval efficiency. 3 Deployment level Once there is no previous planning, it belongs to the combination of emergency strategies ES It supports dynamic expansion. The way of dynamically adding machines can relieve the pressure on the cluster. Note: if the previous master node planning is reasonable, the dynamic addition can be completed without restarting the cluster.
13. What should I pay attention to when using Elasticsearch?
Since ES is written in Java, all attention is paid to GC
1,The index of inverted dictionary needs resident memory and cannot be GC,Need monitoring data node upper segmentmemory Growth trend. 2,Various caches, field cache, filter cache, indexing cache, bulk queue Wait, set a reasonable size and look at the worst case heap Is it enough, that is, when all kinds of caches are full, and heap Can space be allocated to other tasks? Avoid using clear cache And other "self deception" to free up memory. 3,Avoid searches and aggregations that return a large number of result sets. For scenarios that really need to pull a large amount of data, you can use scan & scroll api To achieve. 4,cluster stats The resident memory cannot be expanded horizontally. Super large clusters can be divided into multiple clusters tribe node connect 5,wonder heap Whether it is enough or not, it must be combined with the actual application scenario and the cluster heap Continuous monitoring of usage.
14. What types of queries does Elasticsearch support?
Query is mainly divided into two types: exact matching and full-text retrieval matching. Exact match, e.g term,exists,term set, range,prefix, ids, wildcard,regexp, fuzzy Wait. Full text search, for example match,match_phrase,multi_match,match_phrase_prefix,query_string etc.
15. Can you list the main available field data types related to Elasticsearch?
1,String data types, including those that support full-text retrieval text Type and precisely matched keyword Type. 2,Numeric data types, such as bytes, short integers, long integers, floating point numbers, doubles, half_float,scaled_float. 3,Date type, date nanosecond Date nanoseconds,Boolean, binary( Base64 Encoded string), etc. 4,Range (integer range) integer_range,Long range long_range,Double precision range double_range,Floating range float_range,Date range date_range). 5,Complex data types containing objects, nested ,Object. 6,GEO Geographic location related types. 7,Specific types, such as: array (the values in the array should have the same data type)
16. How to monitor Elasticsearch cluster status?
Marvel So you can easily pass Kibana monitor Elasticsearch. You can view the health status and performance of your cluster in real time, and analyze the past cluster, index and node indicators.
17. Have you learned about Elasticsearch's sexual search scheme?
be based on word2vec and Elasticsearch Realize personalized search (1)be based on word2vec,Elasticsearch And custom script plug-ins, we have realized a personalized search service. Compared with the original implementation, the click through rate and conversion rate of the new version have been greatly improved; (2)be based on word2vec The commodity vector can also be used to recommend similar commodities; (3)use word2vec To realize personalized search or personalized recommendation has certain limitations, because it can only deal with time series data such as user click history, but can not comprehensively consider user preferences, which still has a lot of room for improvement and promotion;
18. Do you know the dictionary tree?
data structure | Advantages and disadvantages |
|---|---|
Array/List | Use dichotomy to find imbalance |
HashMap/TreeMap | High performance, large memory consumption, almost three times the original data |
Skip List | Jump table, which can quickly find words, is implemented in Lucene, redis and HBase |
Trie | Suitable for English dictionaries, if there are a large number of strings in the system and these strings basically have no public prefix |
Double Array Trie | It is suitable for making Chinese dictionaries with small memory consumption. Many word segmentation tools use this algorithm |
Ternary Search Tree | A stateful transfer machine, Lucene 4 has an open source implementation and is widely used |
The core idea of Trie is to exchange space for time, and use the public prefix of string to reduce the overhead of query time
Achieve the purpose of improving efficiency. It has three basic properties:
1. The root node does not contain characters. Except for the root node, each node contains only one character.
2. From the root node to a node, the characters passing through the path are connected to the corresponding string of the node.
3. All child nodes of each node contain different characters.
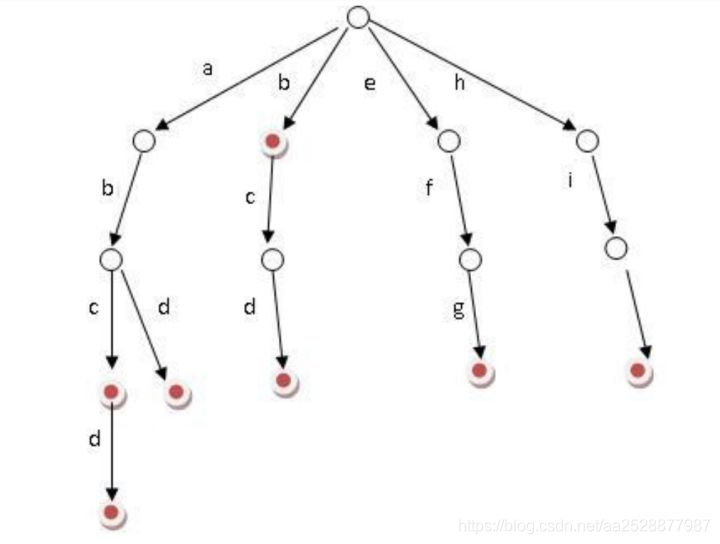
1. It can be seen that the number of nodes in each layer of the trie tree is 26^i. therefore, in order to save space, we You can also use dynamic linked lists or arrays to simulate dynamic, and the cost of space will not exceed the number of words × single Word length. 2. Implementation: open an array of alphabet size for each node, hang a linked list for each node, and record the tree using the representation of left son and right brother; 3. For the Chinese dictionary tree, the child nodes of each node are stored in a hash table, so there is no waste of space, and the hash complexity O(1) can be preserved in the query speed.
19. Does ElasticSearch have a schema?
1,ElasticSearch You can have a schema. A schema is a description of one or more fields that describe the type of document and how to process the different fields of the document. Elasticsearch The schema in is a mapping that describes JSON The fields in the document and their data types, and how they should be Lucene Index in the index. Therefore, in Elasticsearch In terminology, we often refer to this pattern as "mapping". 2,Elasticsearch It has the ability of flexible architecture, which means that documents can be indexed without explicitly providing a schema. If no mapping is specified, by default, Elasticsearch A mapping is generated dynamically when new fields in the document are detected during indexing.
20. Why use Elasticsearch?
Because there will be a lot of data in our mall in the future, the previous fuzzy query and fuzzy query pre configuration will give up the index, resulting in the full table scanning of commodity query. In the million level database, the efficiency is very low, and we use it ES To do a full-text index, we will often query some fields of commodities, such as commodity name, description, price and so on id We put these fields into our index database, which can improve the query speed.