Yarn capacity scheduler multi queue submission case
There is only one default queue by default, which cannot meet the production requirements. Queues are generally created according to business modules such as login registration and shopping cart.
demand
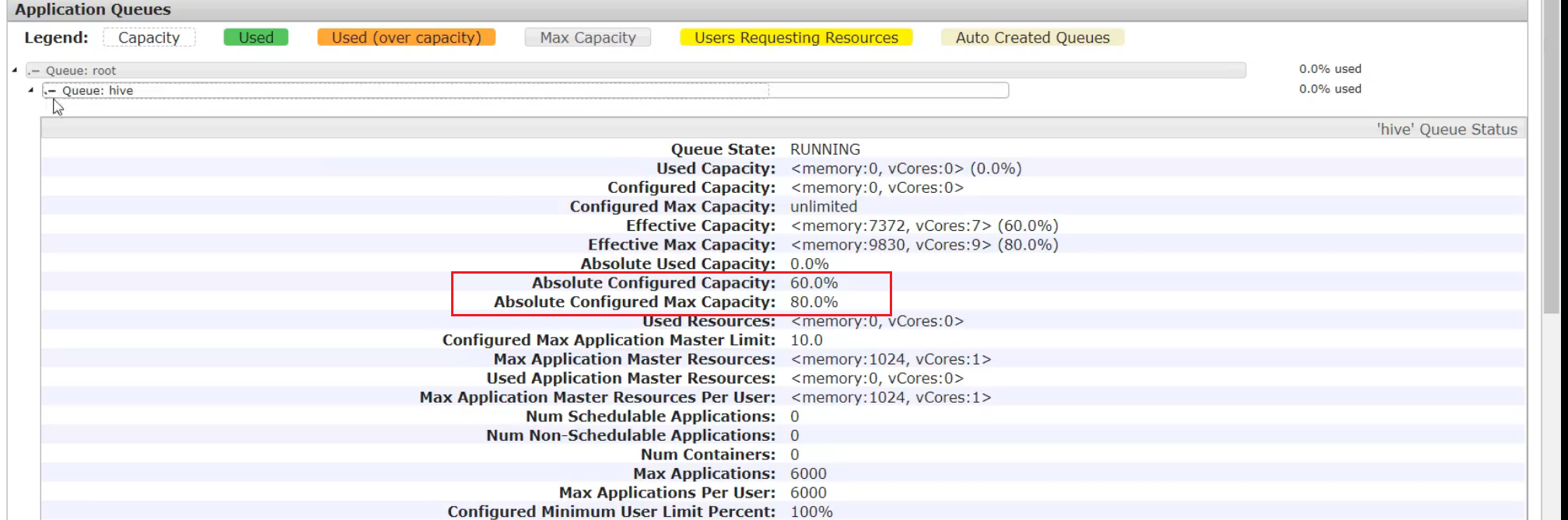
Requirement 1: the default queue accounts for 40% of the total memory, the maximum resource capacity accounts for 60% of the total resources (it accounts for 40% and can be borrowed for 20%), the hive queue accounts for 60% of the total memory, and the maximum resource capacity accounts for 80% of the total resources
Requirement 2: configure queue priority
Configure capacity scheduler for multiple queues
Configure in capacity-scheduler.xml under / opt/module/hadoop-3.1.3/etc/hadoop
1. Modify the following configuration
The direct configuration is not good. Let's download it first
[ranan@hadoop102 hadoop]$ sz capacity-scheduler.xml
Modify the following configuration
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<!--increase hive queue -->
<value>default,hive</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<!--default Queues account for 40% of total memory%-->
<value>40</value>
<description>Default queue target capacity.</description>
</property>
<!--increase hive to configure-->
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<!--hive Queues account for 40% of total memory% -->
<value>60</value>
<description>Default queue target capacity.</description>
</property>
<!--newly added hive Configuration, which can be used when users submit tasks hive What is the total resources of the queue? 1 indicates that it can hive All resources in the queue are exhausted-->
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
<description>
hive queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<!--default Maximum can occupy root 60% of resources%,It has 40%,You can borrow up to 20%,Maximum resource capacity-->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<!--newly added-->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
<description>
The maximum capacity of the hive queue.
</description>
</property>
<!--New. The queue is started by default-->
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
<description>
The state of the hive queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<!--Add to configure which users can submit tasks to the queue * Represents all users-->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the hive queue.
</description>
</property>
<!--Add and configure which users can operate on the queue(administrators)-->
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the hive queue.
</description>
</property>
<!--New, which users can set the priority of the queue-->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
<description>
The ACL of who can submit applications with configured priority.
For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}]
</description>
</property>
<!-- Timeout setting for task: yarn application -appId appId -updateLifetime Timeout(Timeout Set yourself) When the time comes, the task will be deleted kill-->
<!-- newly added Timeout It cannot be specified arbitrarily and cannot exceed the time configured by the following parameters.-->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime
</name>
<value>-1</value>
<description>
Maximum lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
This will be a hard time limit for all applications in this
queue. If positive value is configured then any application submitted
to this queue will be killed after exceeds the configured lifetime.
User can also specify lifetime per application basis in
application submission context. But user lifetime will be
overridden if it exceeds queue maximum lifetime. It is point-in-time
configuration.
Note : Configuring too low value will result in killing application
sooner. This feature is applicable only for leaf queue.
</description>
</property>
<!--Add if application If no timeout is specified, use default-application-lifetime As default -1 It means unlimited execution as long as you want-->
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime
</name>
<value>-1</value>
<description>
Default lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
If the user has not submitted application with lifetime value then this
value will be taken. It is point-in-time configuration.
Note : Default lifetime can't exceed maximum lifetime. This feature is
applicable only for leaf queue.
</description>
</property>
Supplement:
Does the capacity scheduler start all queues from the root directory?

Upload and download of SecureCRT
SecureCRT download sz(send)
Download a file: sz filename
Download multiple files: sz filename1 filename2
Download all files in dir directory, excluding the folder under dir: sz dir/*
rz(received) upload
2 upload to the cluster and distribute
[ranan@hadoop102 hadoop]$ rz [ranan@hadoop102 hadoop]$ xsync capacity-scheduler.xml
3 restart Yarn or yarn rmadmin -refreshQueues
Restart yarn or execute yarn rmadmin -refreshQueues to update the configuration of yarn queues
[ranan@hadoop102 hadoop]$ yarn rmadmin -refreshQueues
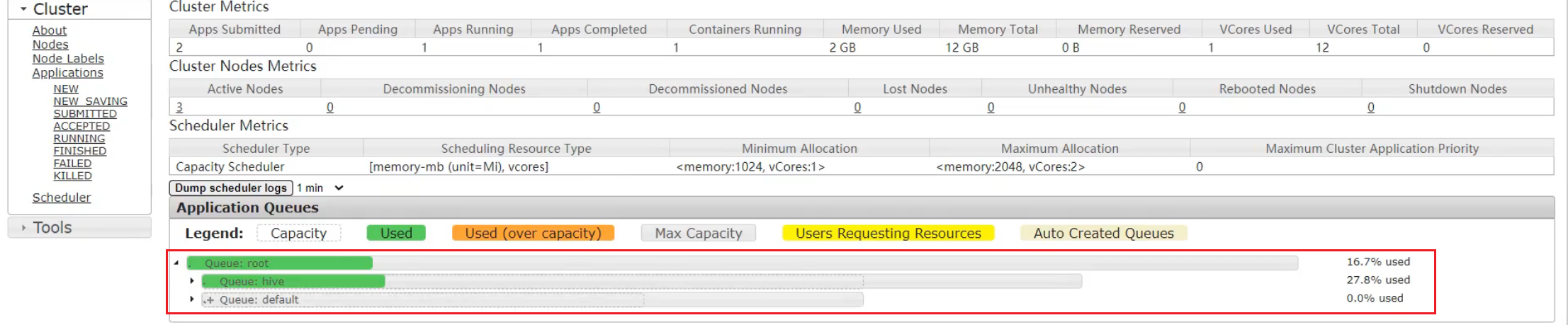
4 submit tasks to Hive queue
Knowledge points: - D means changing parameter values at runtime
-D mapreduce.job.queuename=hive
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -D mapreduce.job.queuename=hive /input /output
It is submitted to the hive queue, which is the default queue by default
Submission method - jar package
If you write your own program, you can declare which queue to submit in the packaged configuration information Driver
public class WcDrvier {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.job.queuename","hive");
//1. Get a Job instance
Job job = Job.getInstance(conf);
....
//6. Submit Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
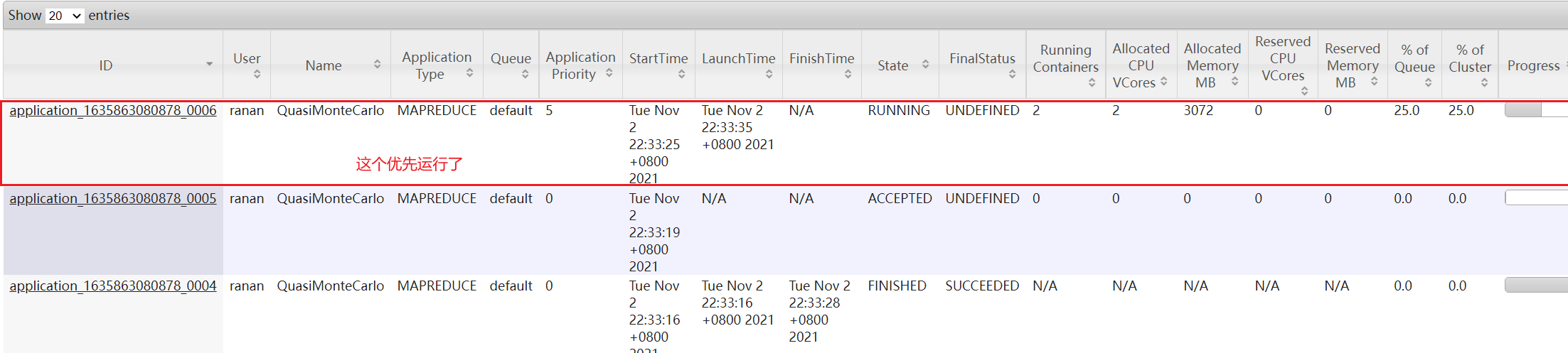
Task priority
Capacity scheduler, when resources are tight, tasks with high priority will get resources first.
By default, the priority of all tasks is 0. If you need to use task priority, you need to make relevant configuration.
Use of task priority
Configure it in yarn-site.xml under / opt/module/hadoop-3.1.3/etc/hadoop
1. Modify the yarn-site.xml file and add the following parameters
<property> <name>yarn.cluster.max-application-priority</name> <!--There are 5 priority levels set, 0 is the lowest and 5 is the highest--> <value>5</value> </property>
2. Distribute the configuration and restart Yan
[ranan@hadoop102 hadoop]$ xsync yarn-site.xml //Restart Yarn only [ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-yarn.sh [ranan@hadoop102 hadoop-3.1.3]$ sbin/start-yarn.sh
3. Simulate the resource tight environment, and the following tasks can be submitted continuously until the newly submitted task application fails to find resources.
//The pi was executed 2000000 times [ranan@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 5 2000000
4. Resubmit the task with high priority again to make the task with high priority restrictive
-D mapreduce.job.priority=5
[ranan@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -D mapreduce.job.priority=5 5 2000000
5. If the task with high priority has been submitted to the cluster, you can also modify the priority of the task being executed through the following command.
Yarn application - appid < applicationid > - updatepriority priority
[ranan@hadoop102 hadoop-3.1.3]$ yarn application -appID application_1611133087930_0009 -updatePriority 5