Reference materials: Bird brother's Linux private dishes: Basic Edition, Liu Chao's interesting talk about Linux operating system, UNIX/Linux system management technical manual, 4th Edition, in-depth understanding of Linux kernel, 3rd Edition, advanced programming in UNIX environment, 3rd Edition, Linux kernel source code scenario analysis Cyc2018 / CS notes: necessary basic knowledge for technical interview, Leetcode, computer operating system, computer network and system design (github.com)
Title citation opening
What are the scheduling strategies?
scheduling strategy
Divide processes by CPU requirements
- Real time process: you need to return results as soon as possible
- Normal process:
Real time processes have different scheduling strategies from ordinary processes.
scheduling strategy
- Real time scheduling strategy
- General scheduling strategy
In task_ In struct, there is a member variable, which we call scheduling policy.
unsigned int policy;
It has the following definitions:
#define SCHED_NORMAL 0 #define SCHED_FIFO 1 #define SCHED_RR 2 #define SCHED_BATCH 3 #define SCHED_IDLE 5 #define SCHED_DEADLINE 6 //Including SCHED_FIFO,SCHED_RR,SCHED_DEADLINE is a scheduling policy for real-time processes. //SCHED_NORMAL,SCHED_BATCH,SCHED_IDLE is the scheduling policy of ordinary processes
With the scheduling strategy, the priority we just mentioned is also in the task_struct.
int prio, static_prio, normal_prio; unsigned int rt_priority;//rt realtime
- For real-time processes, the priority range is 0 ~ 99
- For ordinary processes, the priority range is 100 ~ 139
The lower the value, the higher the priority. It can be seen that all real-time processes have higher priority than ordinary processes.
Real time scheduling strategy
- SCHED_FIFO: first in first out
- SCHED_RR: polling
- SCHED_DEADLINE: deadline
General scheduling strategy
- SCHED_NORMAL: normal process
- SCHED_BATCH: background process
- SCHED_IDLE: Idle Process
The Linux system is ordinary at most, and the scheduling strategy used by ordinary processes is fair_sched_class, let's have a look.
Fully fair scheduling algorithm
In Linux, a scheduling algorithm based on CFS is implemented. The full name of CFS is complete fair scheduling, which is called complete fair scheduling.
Algorithm principle
First, you need to record the running time of the process. The CPU will provide a clock and trigger a clock interrupt after a period of time.
CFS will schedule a virtual runtime vruntime for each process. If a process is running, the vruntime of the process will increase with time. The vruntime of processes not executed remains unchanged.
Obviously, those with less vruntime have been treated unfairly and need to be supplemented, so they will give priority to running such processes.
You might say, don't you have priorities? How to give more time to high priority processes? This logic can be seen when updating the statistics of process operation.
Priority + CFS
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
......
delta_exec = now - curr->exec_start;
......
curr->exec_start = now;
......
curr->sum_exec_runtime += delta_exec;
......
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
......
}
/*
* delta /= w,w Is the weight
*/
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
/* delta_exec * weight / lw.weight */
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
Here you can get the current time and the start time of this time slice. Subtracting the two is the running time delta_exec, but the time obtained is actually the actual running time. It needs to be transformed to be the virtual running time vruntime. The conversion method is as follows:
Virtual runtime vruntime += Actual running time delta_exec * NICE_0_LOAD/ weight
That is to say, for the same actual running time, there are fewer high weight ones and more low weight ones, but when the next running process is selected, it is still based on the minimum vruntime, so the high weight ones will naturally get more actual running time.
Scheduling queue and scheduling entity
Data structure of CFS
It seems that CFS needs a data structure to sort vruntime and find the smallest one. This sortable data structure not only needs to be able to quickly find the smallest when querying, but also needs to be able to quickly adjust the sorting when updating. You know that vruntime is often changing. If you insert this data structure, you need to reorder.
The tree that can balance the query and update speed is the red black tree.
The nodes of red black tree should include vruntime, which is called scheduling entity.
In task_ There are such member variables in struct:
struct sched_entity se;//Fully fair algorithm scheduling entity sched_entity struct sched_rt_entity rt;//Real time scheduling entity struct sched_dl_entity dl;//Deadline scheduling entity
It seems that not only CFS scheduling strategies need such a data structure for sorting, but other scheduling strategies also have their own data structure for sorting, because when scheduling any strategy, it is necessary to distinguish who runs first and who runs later.
According to whether the process is real-time or ordinary, the process hangs itself in a data structure through this member variable, sorts with other processes, and waits to be scheduled. If the process is a normal process, it is through sched_entity, hang yourself on this red and black tree.
The following figure is an example of a red black tree.
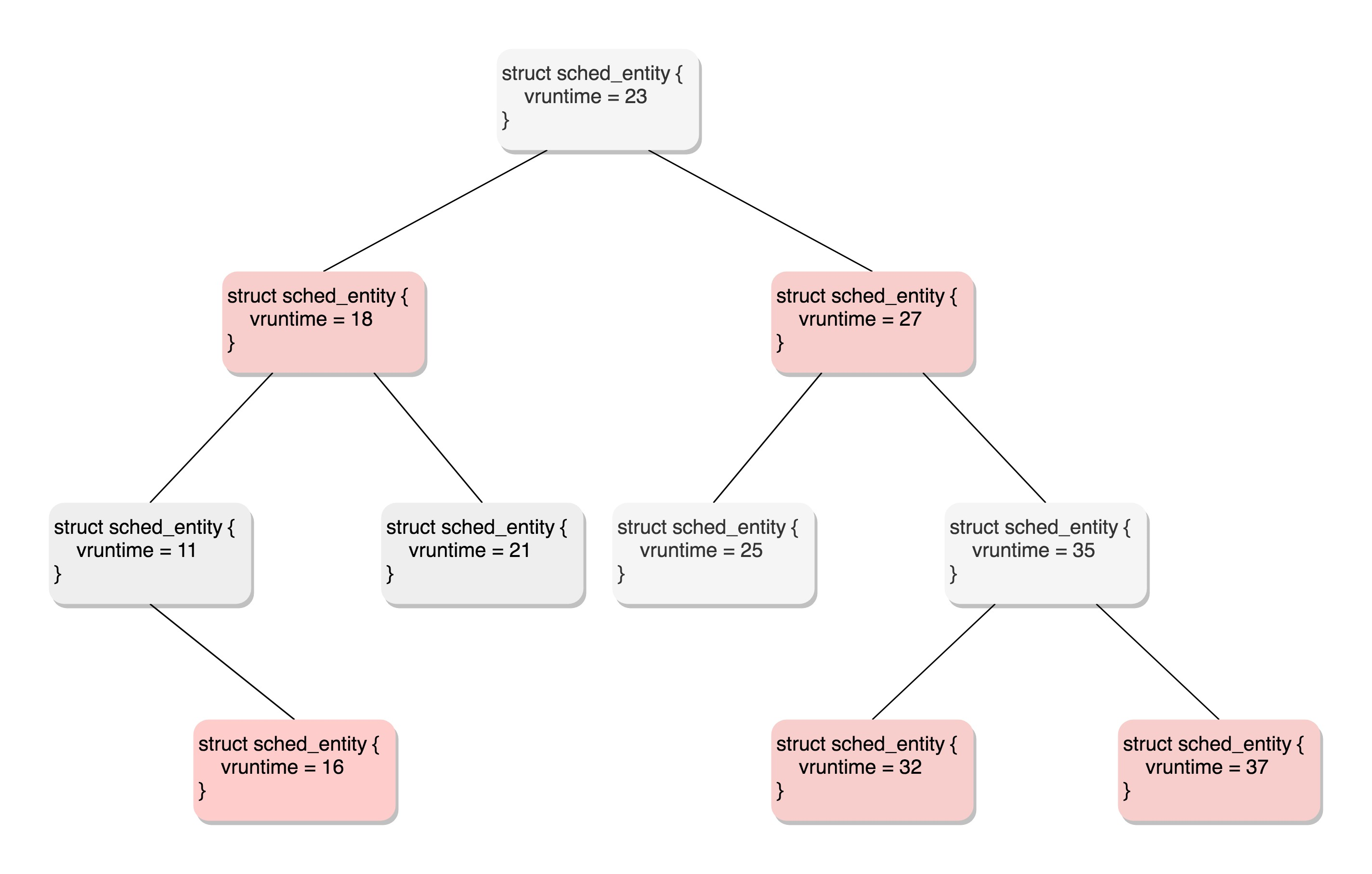
All runnable processes are finally stored in the red black tree in chronological order through continuous insertion. The smallest vruntime is on the left side of the tree and the largest vruntime is on the right side of the tree. The CFS scheduling strategy will select the leftmost leaf node of the red black tree as the next task that will get the cpu.
Scheduling entity of ordinary process
The scheduling entity for ordinary processes is defined as follows, which includes vruntime and load weight_ Weight, and statistics of running time.
struct sched_entity {
struct load_weight load;//weight
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;//statistic
u64 prev_sum_exec_runtime;//Running time
u64 nr_migrations;
struct sched_statistics statistics;
......
};
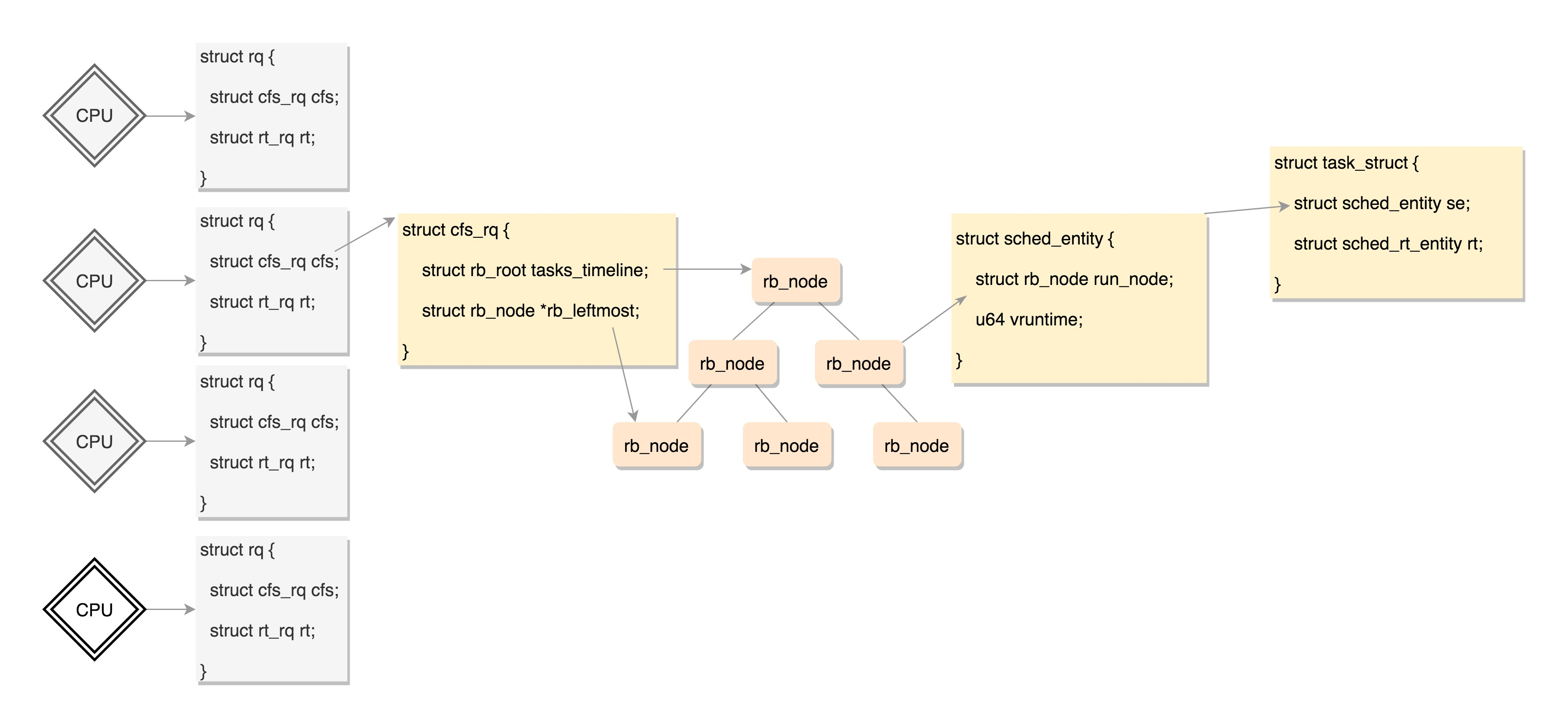
CPU struct rq
Each CPU has its own struct rq (runqueue) structure, which is used to describe all processes running on this CPU, including:
- A real-time process queue rt_rq
- A CFS run queue cfs_rq
During scheduling, the scheduler will first go to the real-time process queue to find out whether there are real-time processes to run. If not, it will go to the CFS run queue to find out whether there are real-time processes to run.
//CPU run queue
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
unsigned int nr_running;
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
......
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs; // CFS run queue
struct rt_rq rt; //Real time process queue
struct dl_rq dl;
......
struct task_struct *curr, *idle, *stop;
......
};
Fair queue CFS for normal processes_ RQ, as defined below:
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running, h_nr_running;
u64 exec_clock;
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root tasks_timeline;// rb_root points to the root node of the red black tree
struct rb_node *rb_leftmost;//rb_leftmost points to the leftmost node
struct sched_entity *curr, *next, *last, *skip;
......
};
The red black tree looks like a queue on the CPU, constantly removing a process that should run.
Data structure relationship of CFS
Scheduling class
The execution logic of scheduling policy is encapsulated in this scheduling class.
Definition of scheduling class
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task, int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq)
This structure defines many methods for operating tasks on queues. Please note that the first member variable is a pointer to the next scheduling class.
Scheduling related functions
Scheduling class sched_class defines 6 scheduling related functions:
- enqueue_task adds a process to the ready queue. When a process enters the runnable state, this function is called;
- dequeue_task deletes a process from the ready queue;
- pick_next_task select the process to run next;
- put_prev_task replaces the currently running process with another process;
- set_curr_task is used to modify the scheduling policy;
- task_ Every time the periodic clock arrives, this function is called, which may trigger scheduling.
sched_class implementation
Scheduling class sched_class has five main implementations:
- stop_sched_class: the task with the highest priority will use this strategy, which will interrupt all other threads and will not be interrupted by other tasks;
- dl_sched_class: corresponds to the deadline scheduling policy above;
- rt_sched_class: the scheduling strategy corresponding to RR algorithm or FIFO algorithm. The specific scheduling strategy is determined by the task of the process_ Specify struct - > policy;
- fair_sched_class: it is the scheduling strategy of ordinary processes;
- idle_sched_class: it is the scheduling policy of idle processes.
Working process of scheduling class
The scheduling class is actually placed on a linked list. Here we take the most common operation of scheduling and pick the next task_ next_ Take task as an example to analyze it.
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
......
//Call the methods of each scheduling class in the above order.
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
}
This shows that the scheduling is performed from the scheduling class with the highest priority to the scheduling class with the lowest priority. For each scheduling class, it has its own implementation. For example, CFS has fair_sched_class.
fair_sched_class
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
};
For the same pick_next_task selects the next task to run. Different scheduling classes have their own implementations. fair_ sched_ The implementation of class is pick_next_task_fair,rt_ sched_ The implementation of class is pick_next_task_rt.
pick_next_task_rt and pick_next_task_fair
We will find that these two functions operate on different queues, pick_ next_ task_ The RT operation is rt_rq,pick_next_task_fair operates on cfs_rq.
static struct task_struct *
pick_next_task_rt(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct task_struct *p;
struct rt_rq *rt_rq = &rq->rt;//The operation is rt_rq
......
}
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;//The operation is cfs_rq
struct sched_entity *se;
struct task_struct *p;
......
}
In this way, the whole running scenario is concatenated. There is a queue rq on each CPU, which contains multiple sub queues, such as rt_rq and cfs_rq, different queues have different implementation methods, cfs_rq is implemented with red black tree.
One day, when a CPU needs to find the next task to execute, it will call the scheduling class according to the priority. Different scheduling classes operate different queues. Of course_ sched_ Class is called first, and it will be called in RT_ Find the next task on RQ. Only when you can't find it, it's Fair's turn_ sched_ Class is called, and it will be in CFS_ Find the next task on RQ. This ensures that the priority of real-time tasks is always higher than that of ordinary tasks.
__pick_first_entity
In this, we focus on fair_sched_class for pick_ next_ Implementation of task pick_next_task_fair, get the next process. The call path is as follows: pick_next_task_fair->pick_ next_ entity->__ pick_ first_ entity.
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = rb_first_cached(&cfs_rq->tasks_timeline);
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
It can be seen from the implementation of this function that the leftmost node is taken from the red black tree.
Active scheduling
Two typical scenarios:
- Write block device gives up CPU: writing takes time, so give up CPU
- Give up CPU for network equipment: it needs to wait for data input, so give up CPU when it is idle
Related contents involved:
- schedule function: giving up the CPU is actually calling this function.
- __ Schedule function: the main implementation logic of the schedule() function.
- pick_next_task function: get the next ready process.
schedule() function
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);//Main logic__ schedule function
sched_preempt_enable_no_resched();
} while (need_resched());
}
The main logic of this code is__ Implemented in the schedule function.
__ schedule function
This function is complex. We will explain it in several parts.
- Take out the task queue rq
- Get next task
- Context switching
Take out the task queue rq
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);//1. Take out the task queue rq
prev = rq->curr;//prev points to the curr of the running process on the CPU's task queue
......
Get next task
Next, the code is as follows:
next = pick_next_task(rq, prev, &rf);//2. Get the next task, task_struct *next points to the next task, which is succession clear_tsk_need_resched(prev); clear_preempt_need_resched();
Context switching
Third, if the elected successor is different from the predecessor, it is necessary to switch the context and officially put the successor process into operation.
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
......
rq = context_switch(rq, prev, next, &rf);
pick_next_task
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can call that function directly, but only if the @prev task wasn't of a higher scheduling class, because otherwise those loose the opportunity to pull in more work from other CPUs.
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
again:
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
}
Let's look at again, which is the scheduling class called in turn in the previous section. However, there is an optimization here. Because most processes are ordinary processes, the above logic will be called in most cases, and fair will be called_ sched_ class.pick_ next_ task.
According to the previous section for fair_sched_class, which calls pick_next_task_fair.
pick_next_task_fair
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
For the CFS scheduling class, fetch the corresponding queue cfs_rq, this is the red black tree we talked about in the last section.
struct sched_entity *curr = cfs_rq->curr;
if (curr) {
if (curr->on_rq)
update_curr(cfs_rq);
else
curr = NULL;
......
}
se = pick_next_entity(cfs_rq, curr);
Take out the curr of the currently running task. If it is still in the runnable state, that is, in the process ready state, call update_curr updates vruntime. update_ We saw curr in the last section. It will calculate vruntime according to the actual running time.
Then pick_next_entity takes the leftmost node from the red black tree. We also talked about the implementation of this function in the previous section.
p = task_of(se);
if (prev != p) {
struct sched_entity *pse = &prev->se;
......
put_prev_entity(cfs_rq, pse);
set_next_entity(cfs_rq, se);
}
return p
task_of gets the task corresponding to the next scheduling entity_ Struct, if it is found that the successor is different from the predecessor, it indicates that there is a process that needs to be run more, and the red black tree needs to be updated. The previous predecessor's vruntime has been updated, put_ prev_ Put entity back into the red black tree, find the corresponding location, and then set_next_entity sets the successor as the current task.
Process context switching
Context switching mainly does two things:
- Switch process space, that is, virtual memory
- Switch register and CPU context
Related contents involved:
- Function context_switch: function for context switching
- Function switch_to: switch between register and stack, and call__ switch_to_asm
- Functions__ switch_to_asm: assembly code, switch the stack, and jump to__ switch_to
- Functions__ switch_to: there's a TSS in it_ Struct structure, which is used to save the values of all registers during process switching
- task_ The member variable thread in struct: saves all registers during process switching
context_switch
Let's look at context first_ Implementation of switch.
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
......
mm = next->mm;
oldmm = prev->active_mm;
......
//1. The first is the switching of memory space
switch_mm_irqs_off(oldmm, mm, next);
......
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
switch_to
Next, let's look at switch_to. It is the switch between register and stack. It calls__ switch_to_asm. This is an assembly code, mainly used for stack switching.
__switch_to_asm
For 64 bit operating systems, the stack top pointer rsp is switched.
/* * %rdi: prev task * %rsi: next task */ ENTRY(__switch_to_asm) ...... /* switch stack */ movq %rsp, TASK_threadsp(%rdi) movq TASK_threadsp(%rsi), %rsp ...... jmp __switch_to END(__switch_to_asm)
Finally, they all returned__ switch_to this function.
__switch_to
Although this function has different implementations for 32-bit and 64 bit operating systems, it does the same thing. So I'm just listing what 64 bit operating systems do.
__visible __notrace_funcgraph struct task_struct *
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread;
struct thread_struct *next = &next_p->thread;
......
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(cpu_tss, cpu);//Task State Segment
......
load_TLS(next, cpu);
......
this_cpu_write(current_task, next_p);
/* Reload esp0 and ss1. This changes current_thread_info(). */
load_sp0(tss, next);
......
return prev_p;
}
TSS
In the x86 architecture, a mode of process switching in the form of hardware is provided. For each process, x86 wants to maintain a TSS (Task State Segment) structure in memory. There are all the registers in it.
In addition, there is a special register tr (Task Register), which points to the TSS of a process. Changing the value of TR will trigger the hardware to save the values of all registers of the CPU to the TSS of the current process, and then read out all register values from the TSS of the new process and load them into the corresponding registers of the CPU.
Use of TSS in Linux
But this has a disadvantage. When we do process switching, it is not necessary to switch every register. In this way, each process has a TSS, which requires full saving and full switching. The action is too large.
So the Linux operating system came up with a way. Remember that when the system is initialized, the CPU will be called_ Init? Each CPU will be associated with a TSS, and then the TR will point to the TSS. Then, during the operation of the operating system, the TR will not switch and always point to the TSS.
cpu_init and tss_struct
void cpu_init(void)
{
int cpu = smp_processor_id();
struct task_struct *curr = current;
struct tss_struct *t = &per_cpu(cpu_tss, cpu);//TSS
......
load_sp0(t, thread);
set_tss_desc(cpu, t);
load_TR_desc();
......
}
struct tss_struct {
/*
* The hardware state:
*/
struct x86_hw_tss x86_tss;
unsigned long io_bitmap[IO_BITMAP_LONGS + 1];
}
In Linux, there are few registers that really participate in process switching, mainly the top of the stack register.
task_struct
So, in the task_ In struct, there is also a member variable thread that we didn't pay attention to. This keeps the registers that need to be modified when switching processes.
/* CPU-specific state of this task: */ struct thread_struct thread;
Summary
The so-called process switching is to change the thread of a process_ The value of the register in struct is written to the TSS pointed to by the TR of the CPU_ Struct, for the CPU, this is the completion of the switch.
For example__ switch_ Load in to_ sp0 is the thread of the next process_ The value of sp0 of struct is loaded into tss_struct.
Save and restore of instruction pointer
Switch from process A to process B. do you want to switch the user stack? Of course, it has already been switched, just when switching memory space. The user stack of each process is independent and is in the memory space.
What about the kernel stack? Already in__ switch_to is switched, that is, current_task points to the current task_struct. The void *stack pointer inside points to the current kernel stack.
What about the top pointer of the kernel stack? In__ switch_to_asm has switched the stack top pointer and set the stack top pointer to__ switch_to is loaded into the TSS.
What about the top pointer of the user stack? If it is currently in the kernel, it is of course at the top of the kernel stack_ Inside the regs structure. When returning to user mode from the kernel, pt_regs contains all the context information running in user mode, and you can start running.
The only thing that is not easy to understand is the instruction pointer register. It should point to the next instruction. How does it switch?
Switching of instruction pointer register
Let me make it clear that the scheduling of processes will eventually be called to__ schedule function. For your convenience, I'll name it "the first law of process scheduling". We will use this law many times later. You must remember it.
We use the first example to analyze this process carefully. Originally, A process A needs to write A file in the user state. The operation of writing A file cannot be completed in the user state, so it needs to reach the internal core state through system call. In this switching process, the instruction pointer register in user state is saved in Pt_ In regs, when it comes to the kernel state, it starts to execute step by step along the logic of writing files. As A result, it is found that it needs to wait, so it is called__ schedule function.
At this time, the instruction pointer of process A in kernel state points to__ schedule. Remember here that the kernel stack of process A holds this__ schedule call, and know that this is from Btrfs_ wait_ for_ no_ snapshoting_ In the write function.
__ After the above layers of calls in the schedule, the context is reached_ The last three lines of instructions of switch (the barrier statement is a compiler instruction, which is used to ensure that the execution order of switch_to and finish_task_switch will not be changed due to the optimization of the compilation stage, which can be ignored here).
switch_to(prev, next, prev); barrier(); return finish_task_switch(prev);
When process A executes switch in the kernel_ To, the kernel state instruction pointer also points to this line. But in switch_to, switch the register and stack to process B. the only thing that hasn't changed is the instruction pointer register. When switch_ When to returns, the instruction pointer register points to the next statement finish_task_switch.
But this time the finish_task_switch is no longer the finish of process A_ task_ Switch, but finish of process B_ task_ Switch.
Is that reasonable? How do you know where process B was executed when it was switched? Must be here when resuming the execution of process B? At this time, we will use our "first law of process scheduling".
When the B process was switched by others, it was also called__ schedule is also called to switch_to is switched to process C, so the next instruction of process B in that year is also finish_task_switch, which means that there is nothing wrong with the instruction pointer pointing here.
Next, we'll start with finish_ task_ After the switch is completed, return to__ schedule was called. Back to where? According to the principle of function return, of course, it is to find it from the kernel stack and return it to btrfs_wait_for_no_snapshoting_writes? Of course not, because btrfs_wait_for_no_snapshoting_writes is in the kernel stack of process A. it has been switched away for A long time. It should be found in the kernel stack of process B.
Suppose that B is the first example in which tap is called_ do_ Read the process of reading the network card. It was called that year__ The time of schedule is from tap_ do_ The read function is called in.
Of course, tap is placed in the kernel stack of process B_ do_ read. So, from__ After the schedule returns, of course, the next step is tap_do_read runs, and then returns to the user state after the kernel runs. At this time, the PT of the B process kernel stack_ Regs also saves the instruction pointer register in user mode, and then the next instruction in user mode starts running.
Suppose we have only one CPU, switching from B to C and from C to A. When C switches to A, the C process will still call according to the "first law of process scheduling"__ schedule arrival switch_to, switch to the kernel stack of A, and then run finish_task_switch.
Run finish at this time_ task_ Switch is the finish of process A_ task_ switch. Run complete from__ When the schedule returns, we only know from the kernel stack that it was from Btrfs in the past_ wait_ for_ no_ snapshoting_ Writes is called in, so Btrfs should be returned_ wait_ for_ no_ snapshoting_ Writes continues to execute. Finally, the kernel returns to the user state after execution, and Pt is also restored_ Regs, recover the instruction pointer register in user state, and then run from user state.
Here, do you understand why switch_to has three parameters? Why are there two prev s? In fact, we can see from the definition.
#define switch_to(prev, next, last)
do {
prepare_switch_to(prev, next);
((last) = __switch_to_asm((prev), (next)));
} while (0)
In the above example, when A switches to B, it runs to__ switch_ to_ The ASM line runs on the kernel stack of A, prev is A, and next is B. However, A is finished__ switch_to_asm is then switched away. When C switches to A again, it runs to__ switch_to_asm is run from the C kernel stack. At this time, prev is C and next is A, but__ switch_to_asm switches to A's kernel stack at that time.
Remember the scene "prev is A and next is B"__ switch_ to_ When ASM returns prev, before return, prev still puts C in the variable, so it will put C in the return result. However, once returned, the kernel stack of A will pop up. At this time, the prev variable becomes A and the next variable becomes B. This restores the scene of that year. Fortunately, the last in the return value is still C.
Switch through three variables_ To (prev = A, next = B, last = C), process A understands that when I was switched, I switched to B. this time, I switched back from C.
preemptive scheduling
Preemptive scheduling occurs
- A process took too long to execute
- A process is awakened
A process took too long to execute
Contents involved:
- Clock: trigger clock interrupt, call clock interrupt function, and the clock interrupt function will call scheduler_tick
- Function scheduler_tick: call the task of the scheduling class_ The tick function handles clock events
- Function task_tick_fair: clock event processing function of ordinary process scheduling class, according to the task of the current process_ Struct and find the corresponding scheduling entity sched_entity and cfs_rq queue, calling entity_tick
- Function entity_tick: call update_curr updates the vruntime of the current process, then calls check_. preempt_ tick
- Function check_preempt_tick: check if it's time to be preempted
- Function resched_curr: call set_tsk_need_resched marks the process as preempted
- Function set_tsk_need_resched: mark the process as preempted
How do you measure the running time of a process? There is a clock in the computer. It will trigger a clock interrupt after a period of time to notify the operating system. Another clock cycle has passed. This is a good way to check whether it is the time point that needs to be preempted.
The clock interrupt handler function calls scheduler_tick()
scheduler_tick()
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
......
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
......
}
This function first takes out the running queue of the cpu, and then gets the task of the currently running process on the queue_ Struct, and then call this task_. Task of struct scheduling class_ Tick function, as the name suggests, is used to handle clock events.
If the currently running process is an ordinary process, the scheduling class is fair_sched_class, the function called to process the clock is task_tick_fair.
task_tick_fair
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
......
}
According to the task of the current process_ Struct and find the corresponding scheduling entity sched_entity and cfs_rq queue, calling entity_tick.
entity_tick
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
update_curr(cfs_rq);
update_load_avg(curr, UPDATE_TG);
update_cfs_shares(curr);
.....
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
In entity_ In tick, we see the familiar update again_ curr. It updates the vruntime of the current process, and then calls check_. preempt_ tick. As the name suggests, check whether it's time to be preempted.
check_preempt_tick
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
return;
}
......
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
- ideal_runtime: is the actual time that the process should run in a scheduling cycle, by calling sched_slice function.
- sum_exec_runtime: refers to the actual total execution time of the process
- prev_sum_exec_runtime: refers to the actual time occupied by the process when it was scheduled last time
Each time a new process is scheduled, its se - > prev is set_ sum_ exec_ runtime = se->sum_ exec_ Runtime, so sum_exec_runtime-prev_sum_exec_runtime is the actual time occupied by this scheduling. If this time is greater than ideal_runtime, it should be preempted.
In addition to this condition, it will pass__ pick_first_entity retrieves the smallest process in the red black tree. If the vruntime of the current process is greater than the vruntime of the smallest process in the red black tree and the difference is greater than ideal_ The runtime should also be preempted.
When you find that the current process should be preempted, you can't kick it down directly, but mark it as preempted. Why? Because the first law of process scheduling, you must wait for the running process to call__ schedule is OK, so you can only mark it here first.
resched_curr
Mark that a process should be preempted, all of which call resched_curr, which calls set_ tsk_ need_ The marked process should be preempted.
set_tsk_need_resched
But at this moment, it is not really preemptive, but labeled TIF_NEED_RESCHED.
static inline void set_tsk_need_resched(struct task_struct *tsk)
{
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
A process is awakened
As we said earlier, when a process is waiting for an I/O, it will actively give up the CPU. But when I/O comes, the process is often awakened.
This is a good time. Preemption is triggered when the priority of the awakened process is higher than the current process on the CPU.
Related contents involved:
- Function try_to_wake_up: call ttwu_queue adds the wakeup task to the queue
- Function ttwu_queue: call ttwu_do_activate activates the task
- Function ttwu_do_activate: call ttwu_do_wakeup
- Call ttwu_do_wakeup: check called_ preempt_ curr
- Function check_preempt_curr: check whether preemption should occur. If preemption should occur, it does not directly kick the process, but also marks the current process as preempted.
static void ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags,
struct rq_flags *rf)
{
check_preempt_curr(rq, p, wake_flags);
p->state = TASK_RUNNING;
trace_sched_wakeup(p);
Here, you will find that the preemption problem is only half done. It indicates that the currently running process should be preempted, but the real preemption action did not occur.
Seize the opportunity
The real preemption also needs an opportunity, that is, a time to give the running process a chance to call it__ schedule.
You can imagine that it is impossible for a process code to run and suddenly call it__ schedule, it is impossible to write this in the code, so we must plan several opportunities, which are divided into user mode and kernel mode.
Preemptive opportunity of user status
- For user state processes, the moment when they return from the system call is a preemptive opportunity.
- For the user state process, the moment when it returns from the interrupt is also an opportunity to be preempted.
The time returned in the system call
In the previous system call, the link of 64 bit system call is do_ syscall_ 64->syscall_ return_ slowpath->prepare_ exit_ to_ usermode->exit_to_usermode_loop, we didn't pay attention to exit at that time_ to_ usermode_ Loop function, now let's take a look.
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
/* We have work to do. */
local_irq_enable();
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
......
}
}
Now we see in exit_ to_ usermode_ In the loop function, the above mark works. If it is marked_ TIF_ NEED_ schedule is called for scheduling. The calling process is the same as that in the previous section. A process will be selected to give up the CPU for context switching.
The moment when the interrupt returns
In arch/x86/entry/entry_64.S has interrupt processing. It's another piece of assembly language code. Just focus on understanding its meaning. Don't worry about understanding every line.
common_interrupt:
ASM_CLAC
addq $-0x80, (%rsp)
interrupt do_IRQ
ret_from_intr:
popq %rsp
testb $3, CS(%rsp)
jz retint_kernel
/* Interrupt came from user space */
GLOBAL(retint_user)
mov %rsp,%rdi
call prepare_exit_to_usermode
TRACE_IRQS_IRETQ
SWAPGS
jmp restore_regs_and_iret
/* Returning to kernel space */
retint_kernel:
#ifdef CONFIG_PREEMPT
bt $9, EFLAGS(%rsp)
jnc 1f
0: cmpl $0, PER_CPU_VAR(__preempt_count)
jnz 1f
call preempt_schedule_irq
jmp 0b
Interrupt handling calls do_ The IRQ function can be divided into two cases after the interrupt. One is to return to the user state and the other is to return to the kernel state. This can also be seen from the notes.
Let's first look at the part of returning to the user state, regardless of the part of the code returning to the kernel state, retint_user will call prepare_exit_to_usermode, and finally call exit_to_usermode_loop, the same as the above logic, calls schedule() when a tag is found.
Kernel preemption timing
In the execution of kernel state, the preemption time generally occurs in preempt_ In enable().
In kernel mode execution, some operations cannot be interrupted, so preempt is always called before these operations_ Disable () turns off preemption. When it is turned on again, it is an opportunity for kernel state code to be preempted.
As shown in the following code, preempt_enable() calls preempt_count_dec_and_test() to judge preempt_count and TIF_NEED_RESCHED to see if it can be preempted. If you can, call preempt_ schedule->preempt_ schedule_ common->__ Schedule. It still satisfies the first law of process scheduling.
#define preempt_enable()
do {
if (unlikely(preempt_count_dec_and_test()))
__preempt_schedule();
} while (0)
#define preempt_count_dec_and_test()
({ preempt_count_sub(1); should_resched(0); })
static __always_inline bool should_resched(int preempt_offset)
{
return unlikely(preempt_count() == preempt_offset &&
tif_need_resched());
}
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
static void __sched notrace preempt_schedule_common(void)
{
do {
......
__schedule(true);
......
} while (need_resched())
Interrupts are also encountered in the kernel state. When interrupts return, they still return the kernel state. This time is also a time to execute preemption. Now let's go back to the part of the code returning to the kernel in the interrupt return code above, calling preempt_schedule_irq.
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
......
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
......
}
preempt_schedule_irq call__ Schedule. It still satisfies the first law of process scheduling.
Summary moment
Well, in this section, we talked about the data structure related to scheduling, which is still relatively complex. There is a queue on a CPU. The queue of CFS is a red black tree, and each node of the tree is a sched_entity, each sched_ All entities belong to one task_struct,task_ There is a pointer in struct to which scheduling class this process belongs.
When scheduling, call the functions of the scheduling class in turn to get the next process from the CPU queue.
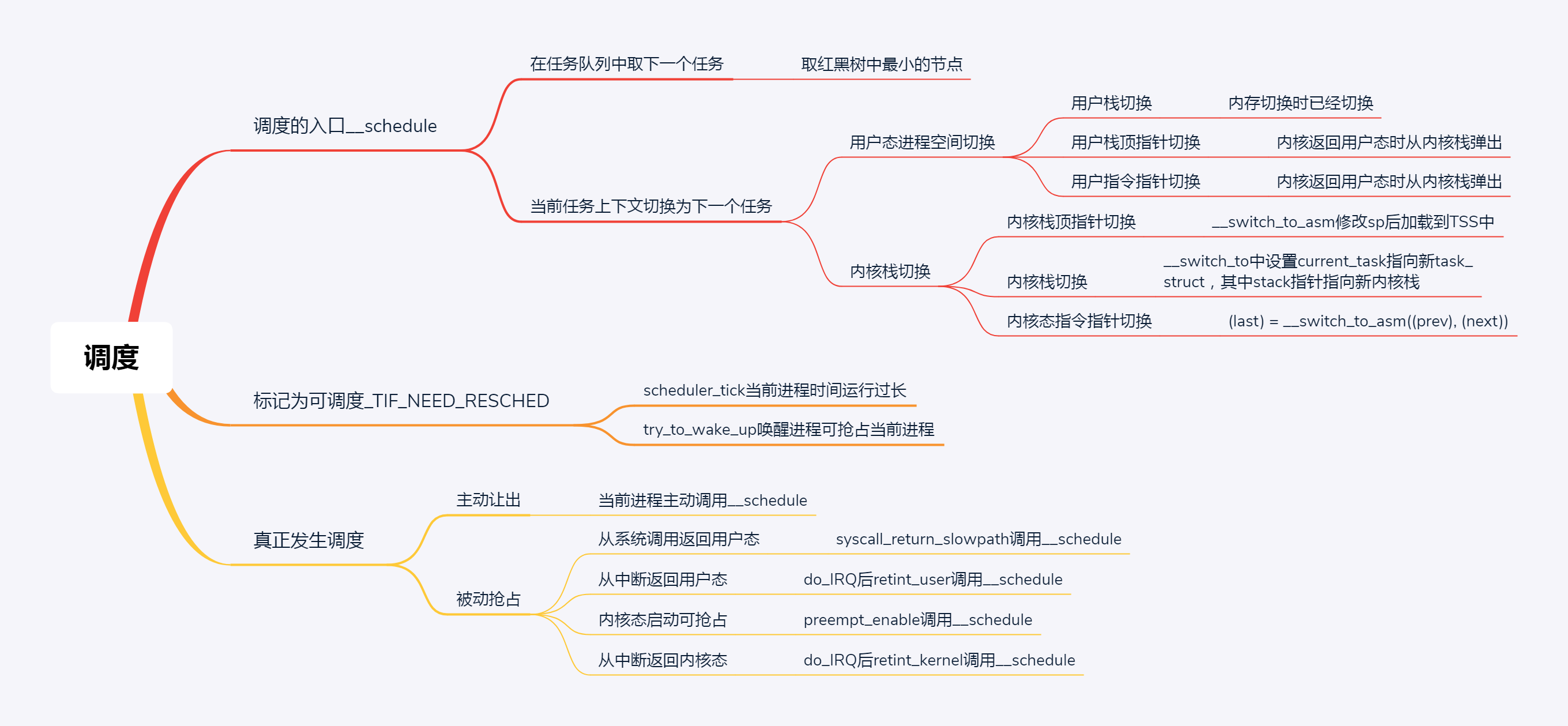
In this section, we talk about the process of active scheduling, that is, a running process actively calls schedule to give up the CPU. Two things will be done in the schedule. The first is to select the next process, and the second is to switch the context. Context switching can be divided into user state process space switching and kernel state switching.
The first item in this brain map summarizes the core function of the first law of process scheduling__ The execution process of schedule is described in the previous section. Because there are many things to switch, you need to know how to switch each part in detail.
The second summarizes the scenarios marked as preemptable. The third is the timing of all preemptions. Here is the real verification of the first law of process scheduling.