Many programmers who have known to write code for more than 10 years often find their code messy. How can you write code that makes your colleagues feel less messy?
1. Why should I write this article?
Explain why you want to write this article before you start?In the Java world, MVC software architecture pattern is absolutely classical (PS: MVC is a kind of software architecture and not just Java). If you enter the Java programming world around the last decade, you will find that you have never escaped the cage of MVC architecture pattern in these years, but have used different MVC framework instead, such as earlier Struts1, Struts2 toAnd now almost all Spring MVC (except a few companies that self-encapsulate the MVC framework).
With the development of Internet technology, especially rich client technology such as Ajax, the front-end technology has gradually formed a system, and gradually separated from the back-end code (such as JSP), which has formed the prevalent front-end and back-end separation mode (which is why there has been a large demand for front-end engineers for a period of time), and this is also the traditional MVC.The pattern has changed slightly, because very few Java-based back-end services now have a large amount of code to handle complex interface logic, so the V (View) layer in MVC has been gradually replaced by various front-end technologies, such as Angular JS, React, and so on.
So the Java service side is mostly just dealing with the logic of M (Model) +C (C ontroller). Conceptually, it seems that Model represents a data model, while C is a control-level logic, so many people (even those who have written Java code for many years) are sometimes confused by this concept and wobble between the Model and C ontroller layers.Definitely, here we need to make sure that M in MVC mode not only represents the data model, but also includes all the business logic-related code within the data model. C is lighter, and it is given the function of only handling input/output parameters and controlling the logical flow of the request if your code is overly intruded into the Controller layer.To know this is not in compliance with MVC architecture specifications!
In the definition of M VC architecture, since M represents all the code related to business logic, M is to focus on design and specification. The structure and specification of the code directly determine the maintainability and quality of the software. Essentially, it is how to use the combination of "code structure + software design principles + design patterns".Of course, the above is just a sentence, but its connotation is a very test of programming level.The content of Software Design Principles + Design Modes is very rich and needs time + experience!Code structure can be agreed upon through some specifications, and with the Spring MVC framework at least we can write code with the same hierarchy as possible!
2. What about application hierarchy?
In fact, different companies have slightly different specifications on how Java is standardized for development, but as the most widely used Java language company in China, Alibaba's "Alibaba Java Development Manual" has made a reasonable division of the hierarchical structure of the application!The author here does not want to be novel, but on the basis of more detailed explanations and explanations, so that students using the Spring MVC framework can better clarify their hierarchical correspondence.
Hierarchical structure
The following hierarchical structure is based on the Spring MVC framework and is generally consistent with the application hierarchy of Alibaba Development Manual. The hierarchical structure diagram is as follows:
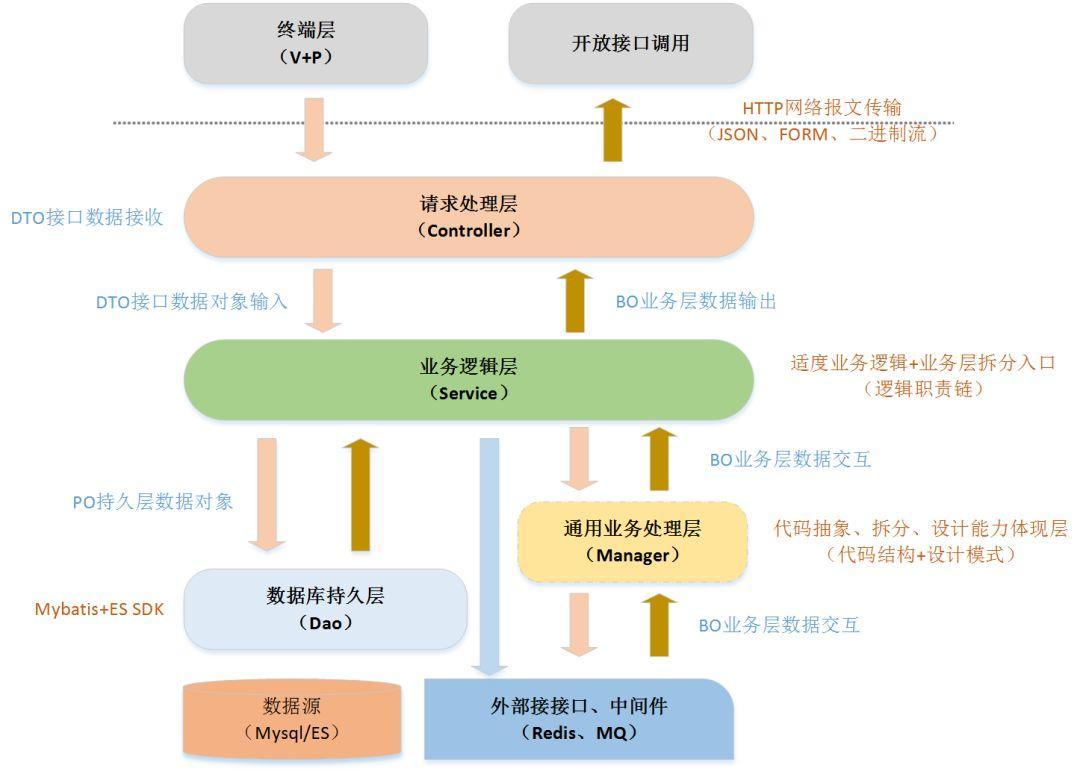
In the development based on the Spring MVC framework, the Controller layer, as the entrance of services, mainly receives and transforms network requests sent by the terminal layer or other services, converts them into Java data objects, and then checks the validity of parameters (such as field length, type, validity of values, etc.) on the data objects.Then, if the business logic is not complex (the complexity criteria can be determined by the number of lines of method code, the complexity of conditional logic, and whether maintenance is easy to see from the standpoint of the bystanders), the business logic can be completed directly by operating the database persistence layer through the Controller dependency injection corresponding service interface and making business logic layer method calls.If the Service-tier method writes very many discoveries, has more logical conditions, and each condition requires more than a certain amount of code to be processed, then you need to consider whether you need to optimize the method.
Optimized methods can be split at different levels depending on the complexity of the logic, for example, a simple point can split a private method to process a part of the logic in the method, thereby reducing the amount of code in the primary business method.If the business-tier approach is followed by a large amount of logic, for example, in a transaction payment system, the Controller layer defines an entry service for payment, and after entering the Service layer approach, a large number of different logic processes are required according to different business access parties, different payment methods and payment channels, then these different scenarios need to be considered.Business logic splits at the class level, such as processing class logic by splitting different payment channels through a factory model, while public processing logic can be abstracted by defining abstract methods through abstract classes.Example private method splitter code:
@Override
public SearchCouponNameBO searchCouponNameList(SearchCouponNameDTO searchCouponNameDTO) {
SearchCouponNameBO searchCouponNameBO = SearchCouponNameBO.builder().total(0).build();
SearchResult searchResult;
try {
BoolQueryCondition boolQueryCondition = searchCouponNameListConditionBuild(searchCouponNameDTO);
SearchBuilderConstructor searchBuilderConstructor = new SearchBuilderConstructor(boolQueryCondition);
searchBuilderConstructor.addFieldSort("id", SortOrderEnum.DESC);
searchBuilderConstructor.setFrom(searchCouponNameDTO.getOffset());
searchBuilderConstructor.setSize(searchCouponNameDTO.getLimit());
searchResult = salesCouponEsMapper.selectCouponNameByCondition(searchBuilderConstructor);
} catch (Exception e) {
throw new SalesCouponNameException(SalesCouponNameErrorCode.COUPON_NAME_ES_QUERY_ERROR.getCode(),
SalesCouponNameErrorCode.COUPON_NAME_ES_QUERY_ERROR.getMessage(),
searchCouponNameDTO);
}
if (searchResult != null && searchResult.getHits().getHits().length > 0) {
List<Integer> idList = getIdListFromEsSearchResult(searchResult);
List<SalesCouponNamePO> salesCouponNamePOList = salesCouponNameMapper.selectByIdList(idList);
List<SalesCouponNameBO> couponNameBOList = SalesCouponNameConvert.INSTANCE
.convertCouponNameBOList(salesCouponNamePOList);
searchCouponNameBO.setList(couponNameBOList);
searchCouponNameBO.setTotal((int) searchResult.getTotalHits());
}
return searchCouponNameBO;
}In this Service entry method, data needs to be retrieved in real MySQL based on the paging IDs from the ES query (the ES data is not fully stored, just to optimize performance to put paging logic into ES), while in the processing of ES data, the list of IDs needs to be abstracted from the ES data result set. For this part of the logic, we abstract a Service layer private for code sake.Methods such as:
private List<Integer> getIdListFromEsSearchResult(SearchResult searchResult) {
SearchHit[] searchHits = searchResult.getHits().getHits();
List<Integer> idList = Arrays.asList(searchHits).stream().map(SearchHit::getSourceAsMap)
.map(o -> Integer.parseInt(String.valueOf(o.get("id"))))
.collect(Collectors.toList());
return idList;
}The code example above is essentially the simplest method abstraction (called a function in another language), which is most commonly used when the amount of code is slightly larger but the logic itself is not very complex!It's also a very effective way to make your code less difficult to maintain if you don't know how to split it up.
Factories + responsibility chains are also common means of business tier splitting. At this time, the code structure needs to be split twice based on the Service tier business entry method. In the hierarchical structure, this part of the code between the Service tier and the Dao tier is called the General Business Processing Layer (Manager).It's hard to have a standard answer to this part because it has a lot of room to play, but as a good programmer, you need to always have an abstract mind, at least not to overweight your code, whether it's split up reasonably or not!Here we define the service layer breakdown hierarchy as three levels:
- Level 1: Private method split;
- Level 2: Factory + Responsibility Chain Application (Effective Class Split);
- Level 3: Advanced design mode (elegant splitting of classes);
Hierarchical domain model conventions
After talking about hierarchical structure, let's talk about the conventions of the hierarchical domain data model. Note that the hierarchical domain here does not refer to the DDD (Domain Driven Design) pattern, but to the definition conventions of the interactive data objects between the layers in the hierarchical structure above.The scope of use of DTO, BO, PO has been identified in the above hierarchical diagram (this specification only covers three domain objects, which is in fact sufficient and does not require too much complexity).Specifically as follows:
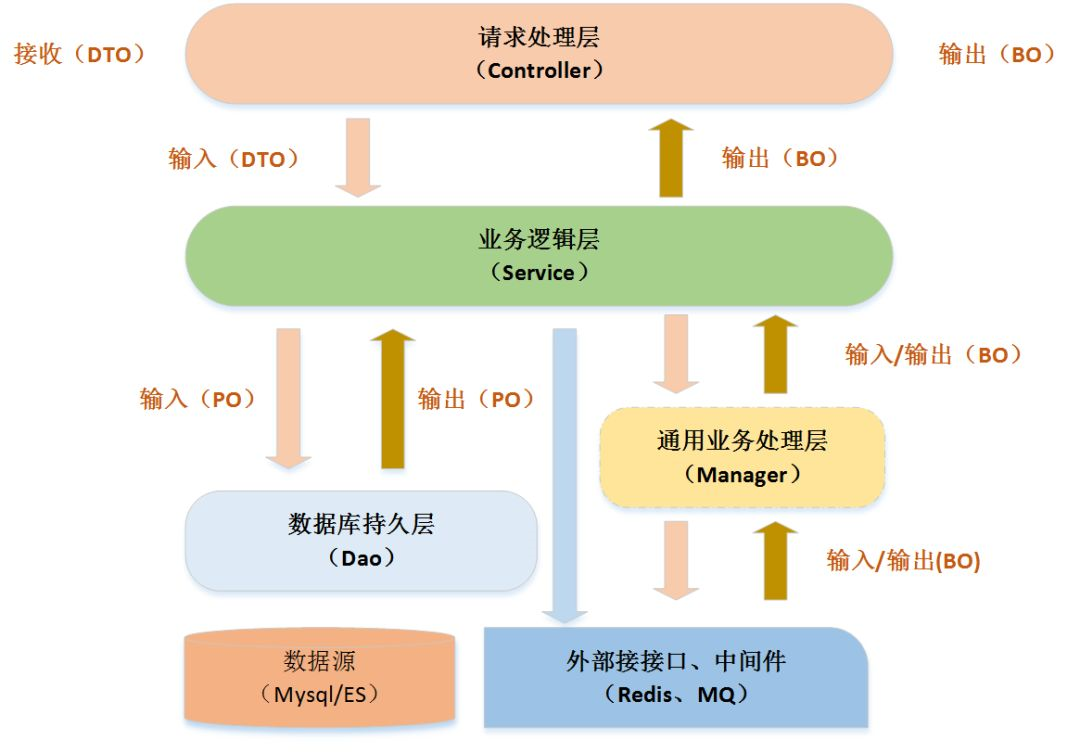
After the Controller layer receives network request data, since the Controller layer does not need to process additional logic, in most cases it directly transfers DTO objects to the Service layer; while in the Service layer, if the logic is not complex and only requires database operations based on DTO data, the DTO is converted to PO as needed at this time, and since in most scenarios, the Service is converted to PO as needed.There are differences between the output parameters of the Service layer and the input DTO objects, so we uniformly define the output data objects of the Service layer as BO to distinguish them.
When the Service layer is split, the input/output objects to the Manager layer methods are unified as BO, including the data object transformation of the third-party data interface that the Manager layer operates on.There are no special mandatory conventions for the above partitions, and it doesn't make sense to speculate too much about what they mean in essence, just to follow a convention together so that the code style looks more uniform.
3. How to keep the code simple
As a programmer with a passion for code, you should never be verbose with fewer lines of code. Java's rich open source ecosystem also gives us such laziness and convenience, so there are many tools to help save code in programming.Here are three ways to introduce you:
MapStruct
In the hierarchical structure described earlier, whether DTO to BO, BO to PO or BO to BO, there will be a lot of logic for data object conversion. The traditional method needs to be done through a bunch of Setter methods, while the @Builder annotation provided by the more advanced lombok package also requires you to write a bunch of'.build()'to complete the data conversion, which is obvious when writing code to the Service layer.A lot of lines of code are wasted, and MapStruct is a more elegant tool for doing this, using the following:
Introduce dependencies in project pom.xml:
<!--MapStruct Java Entity Mapping Tool Dependency-->
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-jdk8</artifactId>
<version>1.3.1.Final</version>
</dependency>
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.3.1.Final</version>
</dependency>You also need to introduce a Maven plug-in in pom.xml:
<!--provide for MapStruct Use -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
</plugin>Then write the data object mapping transformation interface:
package com.mafengwo.sales.sp.coupon.convert;
import com.mafengwo.sales.sp.coupon.client.bo.SalesCouponChannelBO;
import com.mafengwo.sales.sp.coupon.client.dto.SalesCouponChannelsDTO;
import com.mafengwo.sales.sp.coupon.dao.model.SalesCouponChannelsPO;
import java.util.List;
import org.mapstruct.Mapper;
import org.mapstruct.Mapping;
import org.mapstruct.Mappings;
import org.mapstruct.factory.Mappers;
/**
* @author qiaojiang
*/
@Mapper
public interface SalesCouponChannelsConvert {
SalesCouponChannelsConvert INSTANCE = Mappers.getMapper(SalesCouponChannelsConvert.class);
@Mappings({
@Mapping(target = "flag", expression = "java(java.lang.Integer.valueOf(\"0\"))"),
@Mapping(target = "ctime", expression = "java(com.mafengwo.sales.sp.coupon.util.DateUtils.getCurrentTimestamp())"),
@Mapping(target = "mtime", expression = "java(com.mafengwo.sales.sp.coupon.util.DateUtils.getCurrentTimestamp())")
})
SalesCouponChannelsPO convertSalesCouponChannelsPO(SalesCouponChannelsDTO salesCouponChannelsDTO);
@Mappings({})
List<SalesCouponChannelBO> convertCouponChannelBOList(List<SalesCouponChannelsPO> salesCouponChannelsPO);
}The input of the above method is the source data object, and the return object is the target data object. If the field names of the two objects are identical, no separate mapping is required, simply @Mappings({}); if there are differences in field names between the mapped objects, it can be indicated by @Mappings ({@Mapping (target = ctime, source = createTime)})Fixed mapping.The business-tier approach operates as follows:
//Entity Data Conversion
SalesCouponChannelsPO salesCouponChannelsPO = SalesCouponChannelsConvert.INSTANCE
.convertSalesCouponChannelsPO(salesCouponChannelsDTO);This makes it easy to copy between object data, and at least between data objects is no longer a hassle at some level, no matter how the code hierarchy is wrapped around!
lambada expression
lambada expressions are available in Java 8, and if you manipulate List-related data structures in Java 8, you can save code by using lambada expressions, for example:
private List<Integer> getIdListFromEsSearchResult(SearchResult searchResult) {
SearchHit[] searchHits = searchResult.getHits().getHits();
List<Integer> idList = Arrays.asList(searchHits).stream().map(SearchHit::getSourceAsMap)
.map(o -> Integer.parseInt(String.valueOf(o.get("id"))))
.collect(Collectors.toList());
return idList;
}For more usage of lambada expressions, you may have time to look more at the relevant grammar, which will not be repeated here!
tk.mybatis
When using the Mybatis framework as a database development framework, Mybatis is more flexible than Hibernate or other JPA frameworks because of its strong support for native SQL.However, in most Internet systems, database operations are mostly single-table operations, in which case using Mybatis also requires writing a large amount of SQL in Mapper code and mapping.xml files, which are essentially identical and completely universal.
So many projects in the Mybatis field use the mybatis-generator plug-in to generate a complete mapping code in order to reduce the amount of development, but this also adds a lot of useless code, which doesn't seem so simple.tk.mybatis takes this into account, allowing for the convenience of single-table operations (no additional code is required), the flexibility of joint queries with multiple tables, and the simplicity of the code.The specific usage is as follows:
Project pom.xml file introduces related dependencies:
<!--Mybatis currency Mapper Integrate-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>2.1.3</version>
<exclusions>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
</exclusion>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>4.1.3</version>
</dependency>Replace the main @MapperScan annotation with tk.mybatis:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.actuate.autoconfigure.elasticsearch.ElasticSearchRestHealthIndicatorAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.web.servlet.ServletComponentScan;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import org.springframework.web.servlet.config.annotation.EnableWebMvc;
//Do not use the native Mybatis comment, use tk.mybatis's
import tk.mybatis.spring.annotation.MapperScan;
import java.util.Date;
@SpringBootApplication(exclude = {ElasticSearchRestHealthIndicatorAutoConfiguration.class})
@ServletComponentScan
@EnableDiscoveryClient
@EnableWebMvc
@MonitorEnableAutoConfiguration
@MapperScan("com.mafengwo.sales.sp.coupon.dao.mapper")
@EnableTransactionManagement
public class SpCouponApplication {
public static void main(String[] args) {
SpringApplication.run(SpCouponApplication.class, args);
}
}Write a mapping interface, instead of requiring additional definition of the operation method and mapping SQL code for a single table operation, you can directly use the generic method provided by tk.mybatis, as follows:
import com.mafengwo.sales.sp.coupon.dao.model.CouponNameScopeRelationPO;
import org.springframework.stereotype.Repository;
import tk.mybatis.mapper.common.Mapper;
@Repository
public interface CouponNameScopeRelationMapper extends Mapper<CouponNameScopeRelationPO> {
}In Mybatis SQL mapping file*.xml, a single table simply needs to define a simple field mapping instead of a full SQL code, as follows:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.mafengwo.sales.sp.coupon.dao.mapper.SalesCouponChannelsMapper">
<resultMap id="BaseResultMap" type="com.mafengwo.sales.sp.coupon.dao.model.SalesCouponChannelsPO">
<id column="ID" property="id" jdbcType="INTEGER"/>
<result column="NAME" property="name" jdbcType="VARCHAR"/>
<result column="DESC" property="desc" jdbcType="VARCHAR"/>
<result column="ADMIN_UID" property="adminUid" jdbcType="INTEGER"/>
<result column="FLAG" property="flag" jdbcType="INTEGER"/>
<result column="CTIME" property="ctime" jdbcType="TIMESTAMP"/>
<result column="MTIME" property="mtime" jdbcType="TIMESTAMP"/>
<result column="SCENEID" property="sceneId" jdbcType="INTEGER"/>
</resultMap>
</mapper>In addition to the above tools, there are many open source or custom components that can make code written more concise in the actual development process, so you can keep exploring!
4. Java Programming Principles and Design Patterns
Building complex software systems requires that certain design principles be followed and appropriate design patterns be applied so that the code does not get lost in complex logic.The topic about design principles and design patterns is a practice that requires time to polish and practice, so here is just a simple display for you, some of the principles you should follow in Java programming and the design principles you can use, so you can have a sword in your mind!
Design Principles
Single responsibility (one radish and one pit), Richter replacement (inheritance and reuse), dependency inversion (interface-oriented programming), interface isolation (high cohesion, low coupling), Dimitt's rule (reduced class-to-class coupling), and on-off principle (extended development, closed to modification).
Design Mode
In the Java world, there are about 23 design patterns:
- Creative mode: single case mode, abstract factory mode, builder mode, factory mode, prototype mode
- Structural mode: Adapter mode, Bridge mode, Decoration mode, Combination mode, Appearance mode, Enjoyment mode, Agent mode
- Behavioral mode: Template method mode, Command mode, Iterator mode, Observer mode, Intermediator mode, Memo mode, Interpreter mode, Status mode, Policy mode
These modes are more or less seen or heard in our daily programming, but they are not often used. Many reasons are that the current Java development framework such as Spring has made a lot of restrictions for us, and in most Internet systems, the programming mode is very fixed.In most cases, the use of factory mode can solve most business programming scenarios, so many modes are only used more in many basic software such as middleware systems.By listing the above design modes, we do not want everyone to use the design modes for design purposes, but to strive to advance towards the goal of "having hills in mind and eyebrows as mountains and rivers"!Only in this way can you avoid losing yourself and direction in your day-to-day code brick career!
Postnote
As time passes, more and more programmers enter middle age, more and more people write code for more than 10 years, while the development of the industry is on the downhill, various factors make more and more people feel anxious!Personally, as a programmer, our core competence still lies in the code, so it is critical to continuously refine our code competence throughout your day-to-day code brick career!Otherwise, younger people may despise it!